






转载自:机器之心 | 编辑:蛋酱
给 Crop-CLIP 一个口令,就能自动搜图,还能帮忙裁剪出图片中的关键部分。
经常找图的人都知道,根据检索关键词组寻找理想中的照片是件很麻烦的事情。
打开搜索引擎或无版权图片网站,输入关键词,如果幸运的话,可能会在第一页或前 N 个检索结果中找到想要的图像。这种搜索方式仍然是基于图片标签进行的。
自从 2021 年 1 月,OpenAI 推出了名为 CLIP 的神经网络,找图就进入了语义搜索时代。CLIP 建立在零样本迁移、自然语言监督、多模态学习的大量工作基础之上,因此它可以从自然语言监督中有效地学习视觉概念。
语义搜索不会试图为输入短语中的单词找到精确匹配,而是捕获上下文和单词之间的更广泛的关系,然后检索与搜索查询的上下文密切相关的结果。
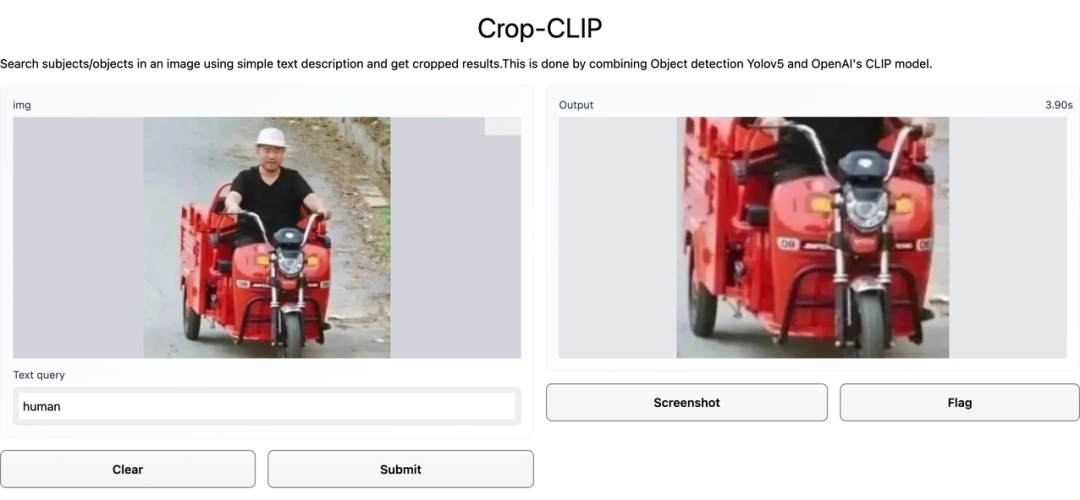
近日,一位开发者将 YOLOv5 和 CLIP 结合起来,在使用关键词检索图片内容的同时,直接精确裁剪出包含检索主题的那一部分。

在这张图中,检索的关键词是「Whats the time」。
项目地址:https://github.com/vijishmadhavan/Crop-CLIP
在线试用地址:https://huggingface.co/spaces/Vijish/Crop-CLIP
先看几个示例,比如你输入关键词「卫衣男」,效果如下图:
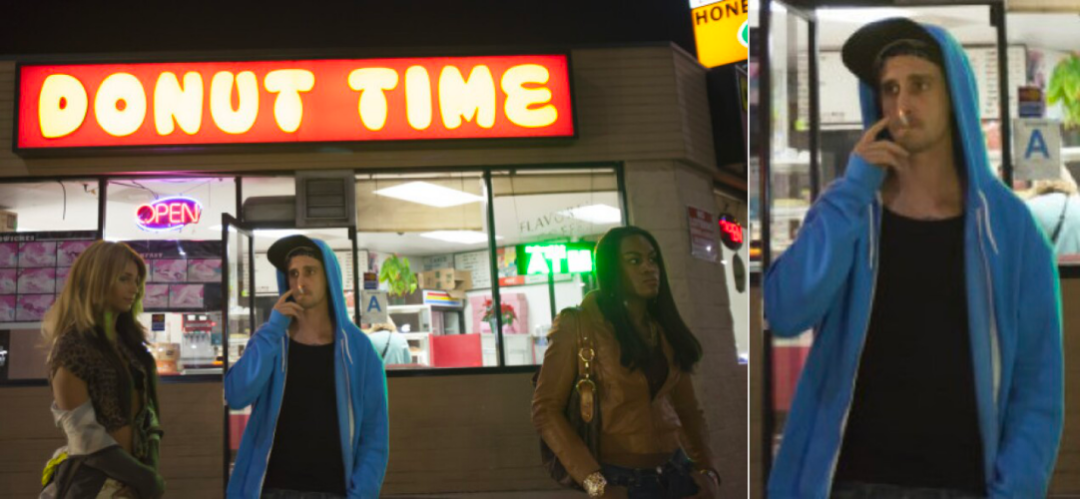
关键词「威士忌酒瓶」:

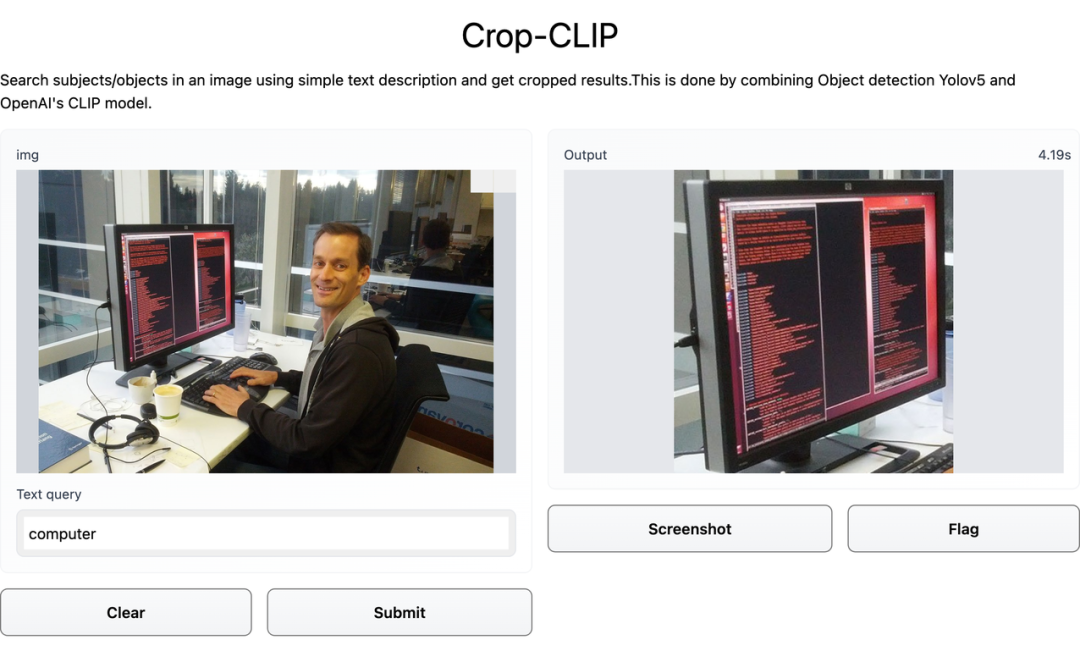
输入关键词「计算机」,就不会包含水杯和耳机:
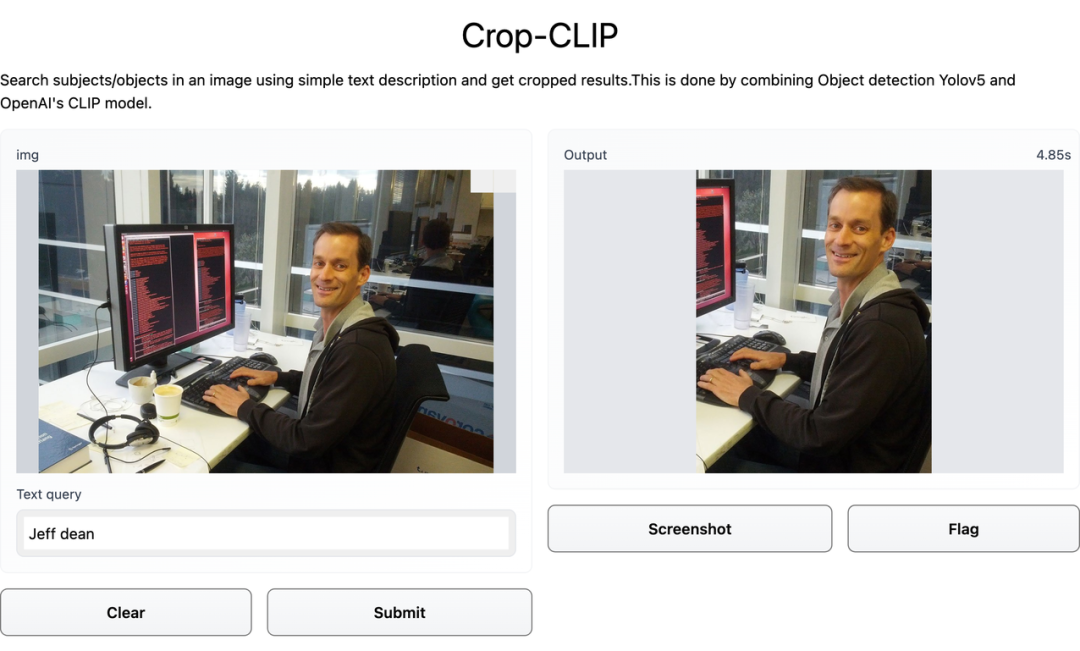
惊喜的是,它也能认出「Jeff Dean」:
怎么实现的?
CLIP 是用大量带有对应标题的图像进行训练的,因此它学会了理解哪个标题与哪个图片相匹配。
用户可以给出一个随机图像,并在向量空间中找到该图像的余弦相似度,其中包含两个短语向量:「这是狗的照片吗?」、「这是猫的照片吗?」。模型会查看哪一个具有最高的相似度,然后找到图像的类别。某种程度上说,CLIP 具有像 GPT-2 和 GPT-3 一样的零样本分类能力。
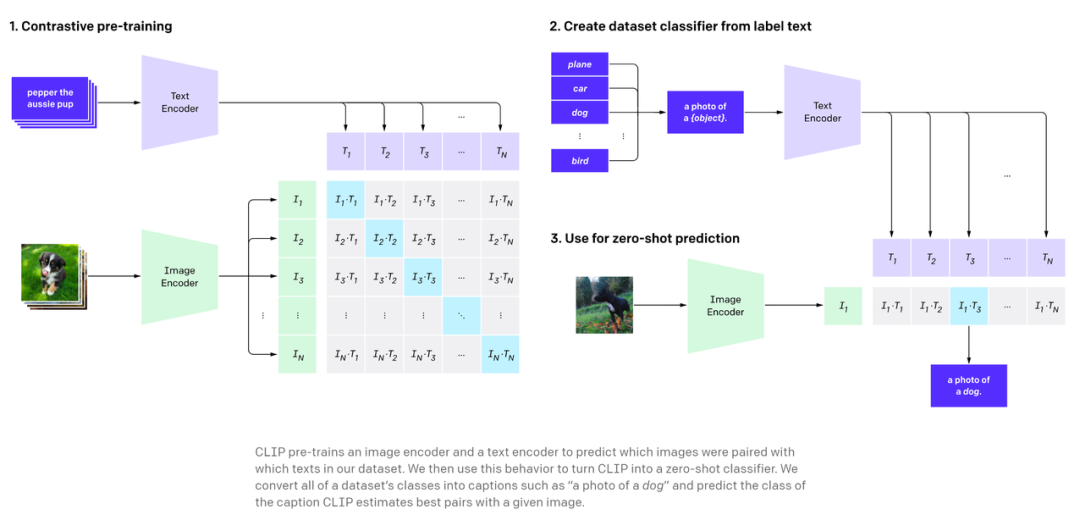
图源:OpenAI CLIP 博客。
和目标检测器 YOLOv5 相结合之后,CLIP 在语义搜索图像的基础上增加了裁剪能力,变身 Crop-CLIP。
检测和裁剪对象 (yolov5s)
使用 CLIP 对裁剪后的图像进行编码
使用 CLIP 编码搜索查询
找到最佳匹配部分
Crop-CLIP 也可用于创建数据集,需要在代码中进行一些更改,进行批量搜索查询。如下图所示,Jack Daniels 威士忌酒瓶的图像已被裁剪并保存。
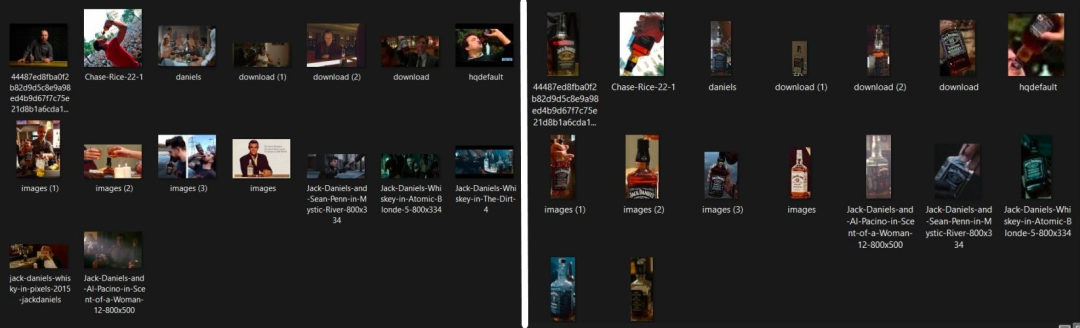
项目作者 Vijish Madhavan 是一位自由开发者,现居英国,是利物浦约翰摩尔斯大学的硕士生。

但作者也提到了一点「限制」,Crop-CLIP 严重依赖目标检测器 YOLOv5,鉴于 YOLOv5 是在 COCO 数据集上进行预训练的目标检测架构和模型,因此 Crop-CLIP 检测过程中的类别会依赖于 COCO 中的类别。
所以在机器之心编辑部的试用过程中,也会出现不同程度的翻车事故。
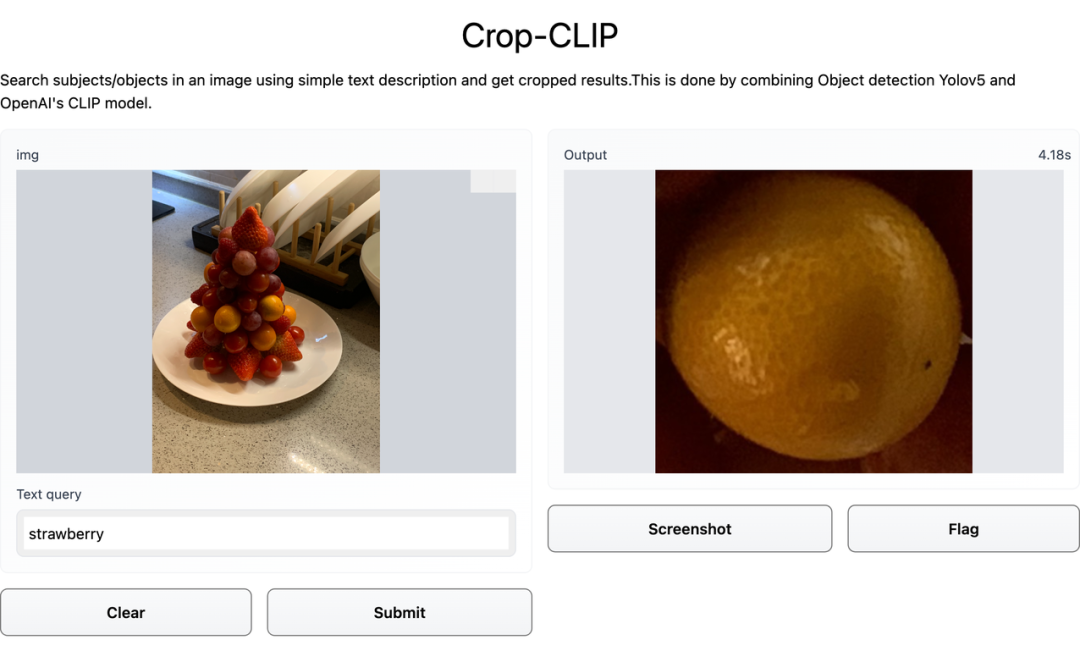
想要草莓,结果却是金桔:
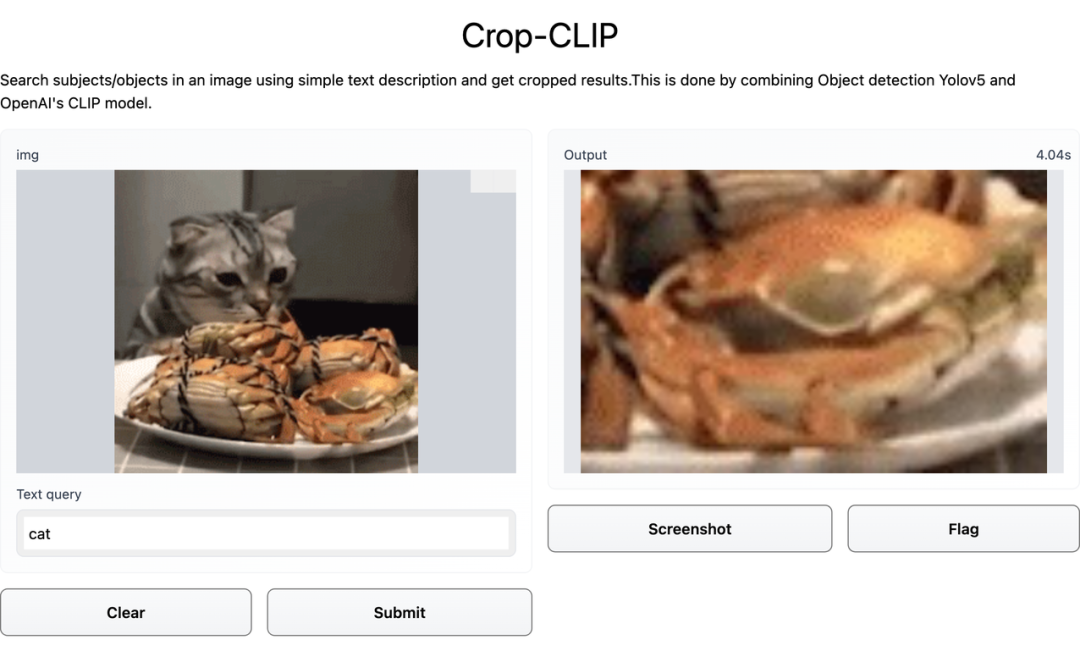
想要猫咪,结果却是螃蟹:
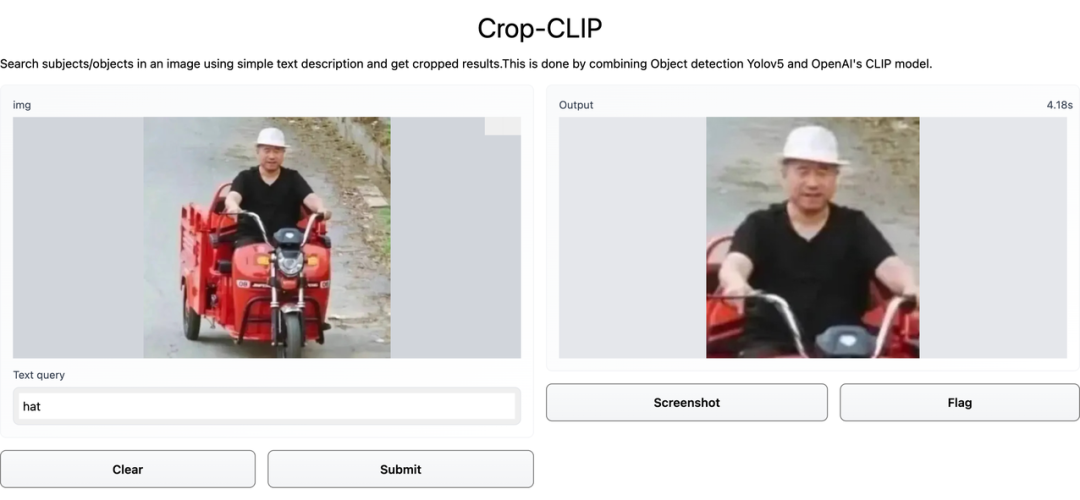
这两张输出结果,刘能看了也要叹气:
至少,这个项目是一种有趣的创新,在后续的优化中,相信作者也会对数据集等方面进行改进,实现更好的搜图效果。
本文仅做学术分享,如有侵权,请联系删文。
重磅!计算机视觉工坊-学习交流群已成立
扫码添加小助手微信,可申请加入3D视觉工坊-学术论文写作与投稿 微信交流群,旨在交流顶会、顶刊、SCI、EI等写作与投稿事宜。
同时也可申请加入我们的细分方向交流群,目前主要有ORB-SLAM系列源码学习、3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、CV入门、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、视觉竞赛、车牌识别、硬件选型、深度估计、学术交流、求职交流等微信群,请扫描下面微信号加群,备注:”研究方向+学校/公司+昵称“,例如:”3D视觉 + 上海交大 + 静静“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进去相关微信群。原创投稿也请联系。

▲长按加微信群或投稿

▲长按关注公众号
3D视觉从入门到精通知识星球:针对3D视觉领域的视频课程(三维重建系列、三维点云系列、结构光系列、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答五个方面进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业为一体的铁杆粉丝聚集区,近4000星球成员为创造更好的AI世界共同进步,知识星球入口:
学习3D视觉核心技术,扫描查看介绍,3天内无条件退款

圈里有高质量教程资料、可答疑解惑、助你高效解决问题
觉得有用,麻烦给个赞和在看~

















 3381
3381

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









