






URL
https://arxiv.org/pdf/2306.17154
TD;DR
2023 年 6 月 Wisconsin 的文章。围绕 ip 保持做的扩展任务,核心目标是对指定 ip 可以生成任意大小的(指定 ip)、任意背景的图片,同时可以通过 bbox 控制物体位置和多物体生成。主页

标题中的:
- anything = ip 保持
- anywhere = 任意位置、任意大小
- any scene = 任意背景
Model & Method
整体没有太多的方法创新,偏向于一个缝合怪的文章。ip 保持能力使用的是 dreambooth,位置控制的模型是 GLIGEN。
- dreambooth 不赘述
- GLIGEN 通过把位置、关键点等控制信息,通过一个额外的 attn 注入 SD。即下图的 g(ip 文本和控制信息,经过 mlp 得到)。gamma 是一个可学习的参数,作为一个 gate 开关来控制应该保留原模型信息的权重。TS 表示 token selection 操作,用来提取 visual token(剔除无用背景信息?)

当然,如果直接组合会出现如下图所示的问题,即生成的位置需要符合 dreambooth 训练数据的分布,如果出现在非训练数据的去他位置(或者其他比例)则会导致生成失败。
文章解释为 dreambooth 不仅学到了 ip 物体的语义信息,同样也会学物体的位置、大小等几何信息。所以在 dreambooth 推理的时候就会过拟合这部分学到的知识(不仅是 dreambooth,大部分需要 finetune 的方法比如 lora 都会有这个问题)


针对这个问题,作者给出的解法是做一些形状和位置的增广,包括:
- 原图的随机 resize
- 在一张灰色的画布上随机放置,只计算原图区域的 loss
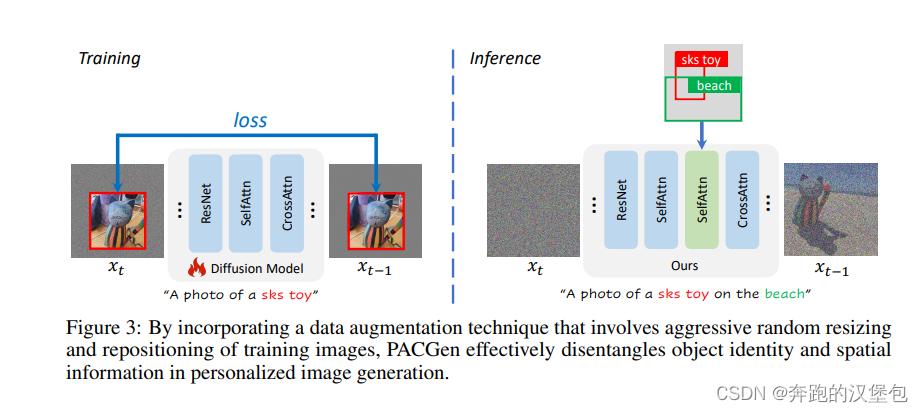
按照上面的思路训练完之后,又出现了一些额外的问题,如下图,包括:
- 图像拼接问题
- 多物体问题
- 灰色背景问题

作者认为问题 1 和问题 2 来源于训练时候只计算物体区域的 loss,而在 unet 中,随着深度逐渐增大,物体区域和物体边缘信息会发生融合。解法如下图。
思路就是加了 ip 对应的 rare token 作为非 bbox 区域内的 neg prompt、加了一些特定的 pos prompt(如 high quality、colorful image)

Dataset & Result
一些结果展示

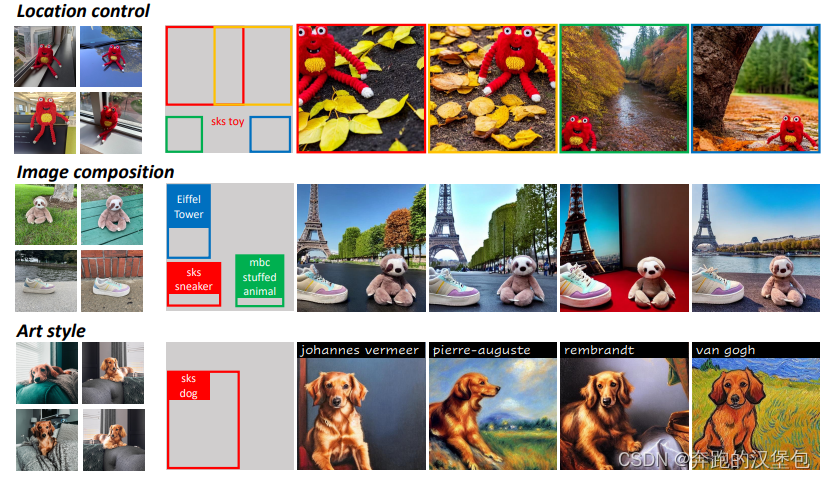

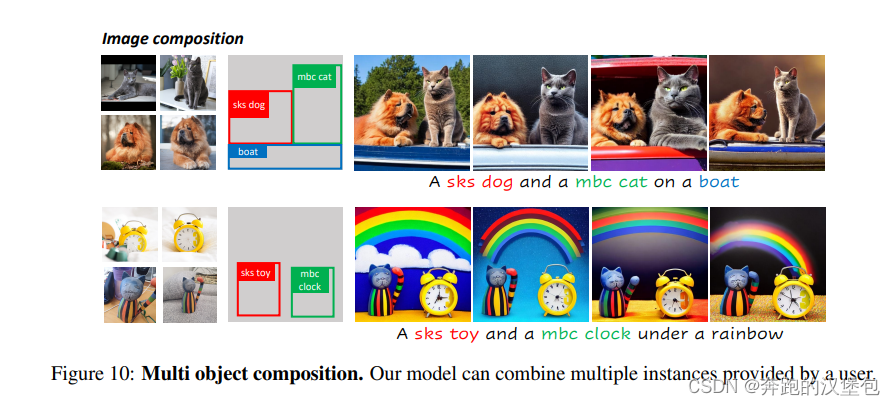
Thoughts
- 多物体的结果中没有太多的复杂交互
- 文章里面的非物体区域采用单独的 neg prompt 生成策略可以留意一下。PS:分块 prompt 机制















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









