






URL
https://arxiv.org/pdf/2312.10899
TD;DR
港科大 + 华南理工大的文章,要解决的任务是非典型比例的图片(比如长画卷、漫画书等)生成。利用文本、语义、位置等不同的控制方法,来生成想要的图片大小,以及精准控制每一部分的图片内容。
一些结果展示:
-
浮城旁,英雄遇瀑布美人

-
城市里,警方遇到了怪兽,蜘蛛侠前来迎战

-
在未来的异世界,一名战士踏上了他的旅程

Model & Method
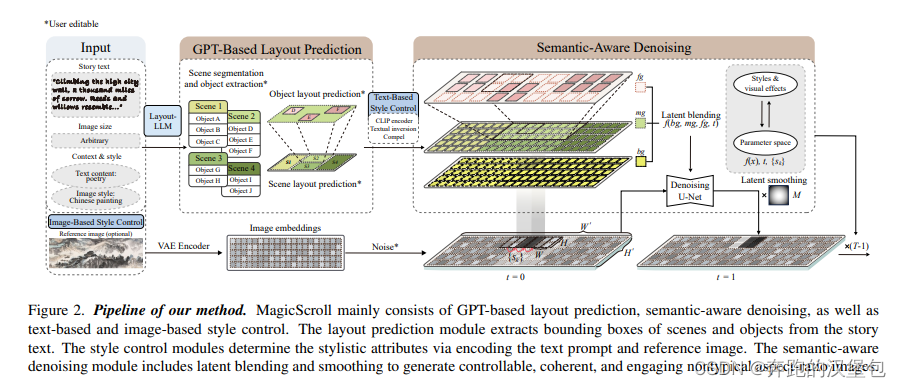
方法的 ppl 如下图,共分为三个部分:
- 第一部分是 gpt 的 prompt 生成。在这一步, gpt 会给出一段 story text,描述了整体的场景,以及场景内细分每一个子场景描述和主体。同时还通过 visual instruction tuning 的方式让 gpt 生成每个主体的 bbox 位置(这一步感觉可以直接用 incontext learning 方式生成)
- 第二部分是 latent 的处理。因为需要生成非典型 shape 的图片,但是传统的 SD 模型一般只能在特定比例和特定分辨率范围内效果比较良好。所以文章使用了滑窗的方式来保证不同比例的图片生成,同时可以保证每一个滑窗内图片的质量。
- 第三部分是 style control,作者使用了 input reference image 的方式控制生成图片的 style
Dataset & Results
训练的数据集包括三部分:
- 中国古风山水画,来自故宫博物院官网
- 漫画数据,来自 eBDtheque
- 电影全景数据,来自 Movie Scripts Corpus

结果展示可以参考上文的图片
Thought
- 对于不同的题材和风格,需要更换 gpt 的输入 prompt。应该是 gpt 没有办法做到通用识别全品类的 story、漫画等文本,并不是很优的方法。
- 滑窗导致了图片生成明显的分块现象(特别是一整张画卷的情况)
- 整体来说值得细读,特别是滑窗也许可以支持业务分镜















 2701
2701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









