






URL
https://arxiv.org/pdf/2208.15001
主页:https://mingyuan-zhang.github.io/projects/MotionDiffuse.html
TD;DR
22 年 8 月商汤的文章,引用量 200+。基于 SD,任务是输入文本的动作描述,生成对应的动作序列。
已有的 motion 生成方法的输入 condition 可以分为 3 类,包括预设好的 pose 序列类别、音乐、自然语言,本文主要关注的是自然语言生成的方式。用语言生成的方法大多只能支持少量词语的短句生成,或者只能生成简单的 pose

Model & Method
因为是 22 年的文章,当时还有 motion module 这个东西,所以本文生成连续帧的方式是吧时间信息 t 通过 positional embedding 的方式注入到训练过程中,生成的动作序列长度是固定的。
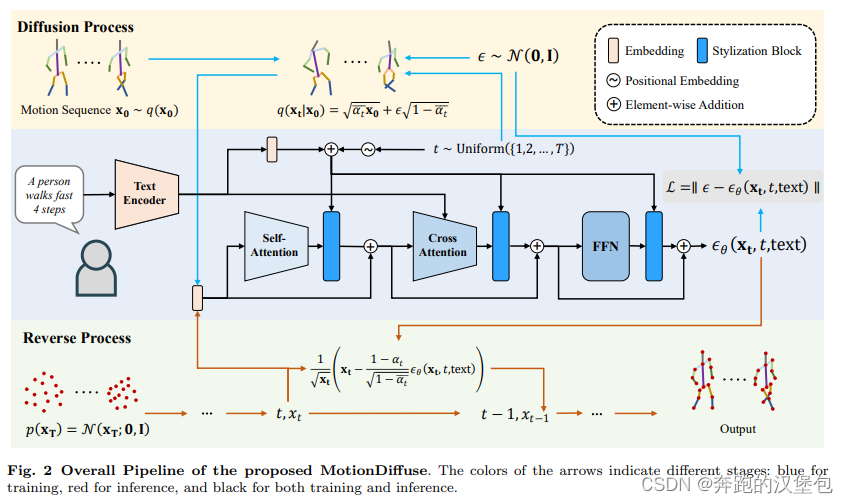
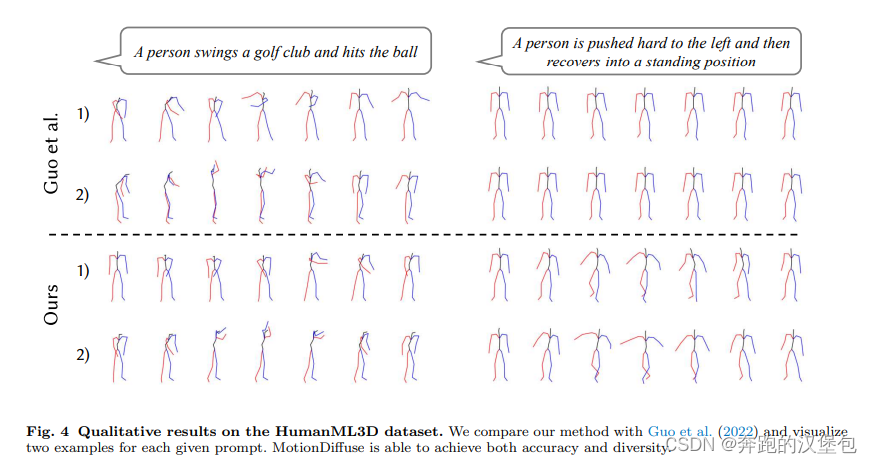
Dataset & Results
Thought
- 文章比较老,t 注入的方式没有什么参考价值。可以参考一下造数据的方法,和 gt 格式
- 本文似乎可以用 prompt 分别控制 body 的每一个独立肢体 lib















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









