







 文章介绍了AdaLoRA,一种改进的低秩适应器,它通过让模型学习参数的重要性并动态调整秩,以提高微调效率。通过实验对比,AdaLoRA比LoRA更有效,强调了在模型微调中对不同模块和秩的灵活处理策略。
文章介绍了AdaLoRA,一种改进的低秩适应器,它通过让模型学习参数的重要性并动态调整秩,以提高微调效率。通过实验对比,AdaLoRA比LoRA更有效,强调了在模型微调中对不同模块和秩的灵活处理策略。
图解大模型微调系列之:AdaLoRA,能做“财务”预算的低秩适配器,无惧数学公式,图解AdaLoRA,简单明了搞懂原理和代码实现。
在“大模型微调系列”之前的文章中,我们介绍过LoRA的原理和代码实现。今天,我们就来看LoRA的改进版本:AdaLoRA(Adaptive Low-Rank Adaptation)的原理。
我猜,如果你曾读过AdaLoRA的原始论文,是不是曾被满屏的数学公式劝退过🐶。其实,AdaLoRA这篇论文写得非常非常好,它的数学符号简洁明了地表达出了算法的全部细节,而背后的数学原理(主要是SVD分解)其实一点也不复杂。毕竟大家都说,深度学习的数学怎么能叫....
AdaLoRA在做一件什么事
LoRA是怎么做微调的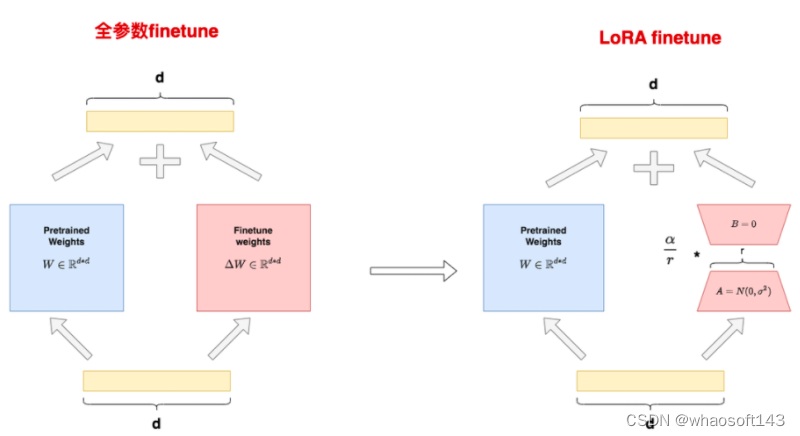
 好,那么现在,问题来了:
好,那么现在,问题来了:
-
对所有模块都采用同一个秩r,这是合理的吗?
-
在微调过程中,一直保持秩r不变,这是合理的吗?
我们来分别细看这两个问题。
对所有模块都采用同一个秩,是否合理
这个问题,早在AdaLoRA之前,LoRA的作者就意识到了,并做了如下实验:
 所以到了AdaLoRA这里,它的作者也做了两个实验:
所以到了AdaLoRA这里,它的作者也做了两个实验: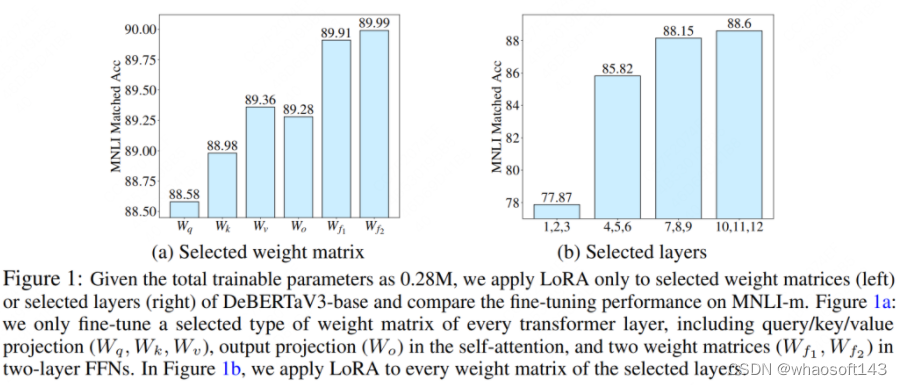
实验(a)对应着左图,作者使用LoRA,在模型的每个layer中微调特定的某个模块,然后去评估模型的效果。可以直观发现,微调不同模块时效果差异显著。
实验(b)对应着右图,作者使用LoRA,对模型不同layer的所有模块做微调。例如1,2,3表示对模型前三层的所有模块做lora微调。可以发现,微调不同layer时模型效果差异显著,微调最后三层的效果最好。
这些实验都证明了一件事:在使用LoRA微调时,对模型的不同模块使用相同的秩,显然是不合理的。
微调过程中一直保持秩不变,是否合理
对于这点,作者并没有做实验来说明,但我们可以从1.2的分析中得到一些思路。
在1.2中,我们通过实验证明“对不同模块采用不同秩”的必要性,那么接下来势必就要解决“每个模块的秩到底要设成多少”的问题。解答这个问题最直接的办法,就是交给模型去学。那模型学习的过程,肯定是个探索性的过程呀,理想情况下,你给模型一个初始化的秩,然后让它在训练过程中,学会慢慢调整这个秩,直到最优。 所以,在微调step的更新过程中,秩也不会保持不变。
AdaLoRA的总体改进目标
好,到此为止,AdaLoRA的总体改进目标就出来了:
找到一种办法,让模型在微调过程中,去学习每个模块参数对训练结果(以loss衡量)的重要性。然后,根据重要性,动态地调整不同模块的秩。
作者管这样的策略叫参数预算(parameter budget),作为一个学财会出身的人,这真是非常形象了。待训练的参数越多,训练代价越大,因此做好参数预算方案,集中训练最重要的那些参数,ROI才会越高。
AdaLoRA的原理
SVD分解
由于AdaLoRA重度依赖SVD分解原理,因此我把LoRA原理篇4.2节中的内容再copy一次。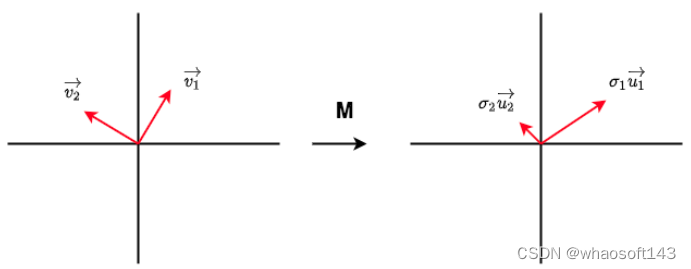
 我们再通过一个代码例子,更直观地感受一下这种近似,大家注意看下注释(例子改编自:https://medium.com/@Shrishml/lora-low-rank-adaptation-from-the-first-principle-7e1adec71541)
我们再通过一个代码例子,更直观地感受一下这种近似,大家注意看下注释(例子改编自:https://medium.com/@Shrishml/lora-low-rank-adaptation-from-the-first-principle-7e1adec71541)
import torch
import numpy as np
torch.manual_seed(0)
# ------------------------------------
# n:输入数据维度
# m:输出数据维度
# ------------------------------------
n = 10
m = 10
# ------------------------------------
# 随机初始化权重W
# 之所以这样初始化,是为了让W不要满秩,
# 这样才有低秩分解的意义
# ------------------------------------
nr = 10
mr = 2
W = torch.randn(nr,mr)@torch.randn(mr,nr)
# ------------------------------------
# 随机初始化输入数据x
# ------------------------------------
x = torch.randn(n)
# ------------------------------------
# 计算Wx
# ------------------------------------
y = W@x
print("原始权重W计算出的y值为:\n", y)
# ------------------------------------
# 计算W的秩
# ------------------------------------
r= np.linalg.matrix_rank(W)
print("W的秩为: ", r)
# ------------------------------------
# 对W做SVD分解
# ------------------------------------
U, S, V = torch.svd(W)
# ------------------------------------
# 根据SVD分解结果,
# 计算低秩矩阵A和B
# ------------------------------------
U_r = U[:, :r]
S_r = torch.diag(S[:r])
V_r = V[:,:r].t()
B = U_r@S_r # shape = (d, r)
A = V_r # shape = (r, d)
# ------------------------------------
# 计算y_prime = BAx
# ------------------------------------
y_prime = B@A@x
print("SVD分解W后计算出的y值为:\n", y)
print("原始权重W的参数量为: ", W.shape[0]*W.shape[1])
print("低秩适配后权重B和A的参数量为: ", A.shape[0]*A.shape[1] + B.shape[0]*B.shape[1])
输出结果为:
原始权重W计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
W的秩为: 2
SVD分解W后计算出的y值为:
tensor([ 3.3896, 1.0296, 1.5606, -2.3891, -0.4213, -2.4668, -4.4379, -0.0375,
-3.2790, -2.9361])
原始权重W的参数量为: 100
低秩适配后权重B和A的参数量为: 40
参数量变少了,但并不影响最终输出的结果。通过这个例子,大家是不是能更好体会到低秩矩阵的作用了呢~
让模型学习SVD分解的近似 AdaLoRA动态更新秩的过程
AdaLoRA动态更新秩的过程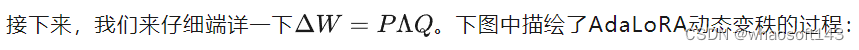
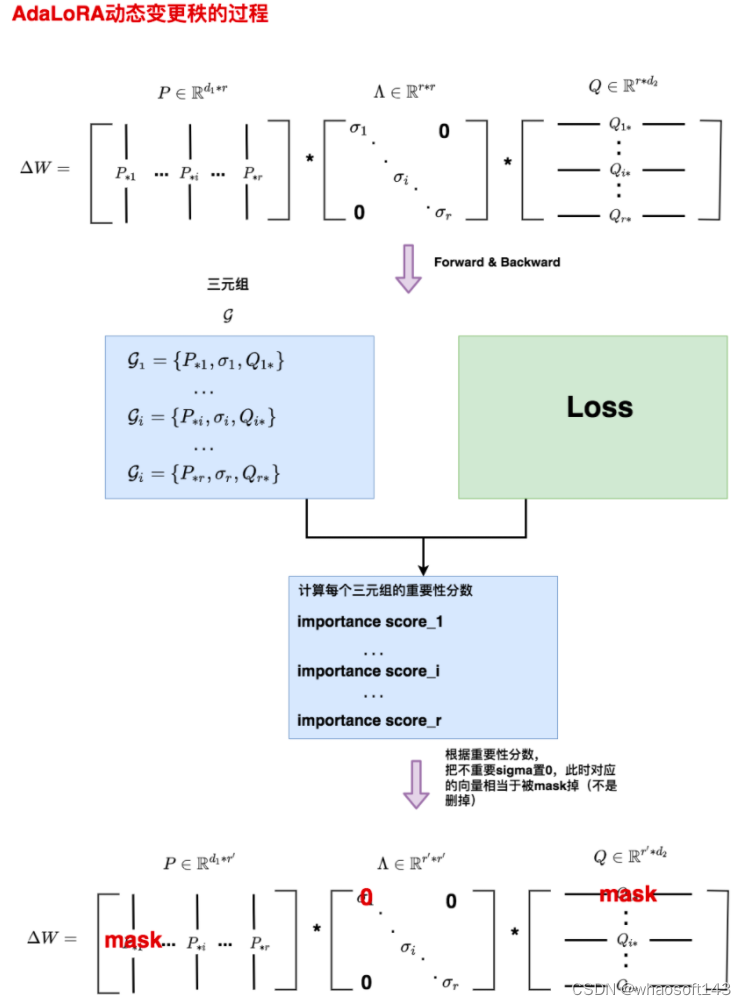
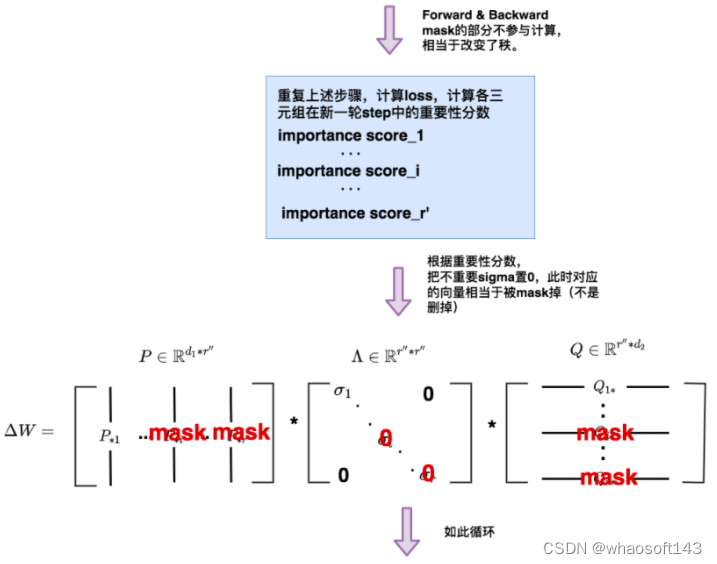 AdaLoRA变秩的整体流程如下:
AdaLoRA变秩的整体流程如下:  好,理清了整体流程后,我们就可以来看细节了,在上述过程里,我们遗留了3个细节问题有待探讨:
好,理清了整体流程后,我们就可以来看细节了,在上述过程里,我们遗留了3个细节问题有待探讨:
-
AdaLoRA中,Loss要怎么设计?
-
AdaLoRA中,重要性分数要怎么算?
-
AdaLoRA中,如何根据重要性分数筛选不重要的三元组,进而动态调整矩阵的秩?
我们来分别细看这三个问题。
AdaLoRA的Loss设计
 其实,这也是AdaLoRA相比于LoRA效果能更好的原因之一:LoRA中是让模型学习BA,去近似SVD分解的结果,但是在训练过程中,没有引入任何SVD分解相关的性质做约束,所以模型就可能学歪了(因此LoRA作者在文章中写了很多实验,证明学出来的BA在一定程度上能近似SVD分解,能取得较好的效果)。而AdaLoRA则是直接将这一束缚考虑到了Loss中。
其实,这也是AdaLoRA相比于LoRA效果能更好的原因之一:LoRA中是让模型学习BA,去近似SVD分解的结果,但是在训练过程中,没有引入任何SVD分解相关的性质做约束,所以模型就可能学歪了(因此LoRA作者在文章中写了很多实验,证明学出来的BA在一定程度上能近似SVD分解,能取得较好的效果)。而AdaLoRA则是直接将这一束缚考虑到了Loss中。
AdaLoRA中的重要性分数
我们依然先明确几个数学表达: 单参数重要性分数
单参数重要性分数
在开始正式讲重要性分数怎么算之前,我们先来看一个问题:到底什么是重要性分数?
改进:单参数重要性分数
4.1中的这个直观有效的想法,被广泛运用在前人做的参数剪枝的优化中,但它有一个显著的问题:我是在mini-batch上计算重要性分数的,不同step间重要性分数可能会受到mini-batch客观波动的影响,有啥办法能消除这种影响吗?
当然有啦,遇到这种消除波动的问题,我们肯定要祭出momentum🐶。
所以,AdaLoRA作者就提出了这样一种计算t时刻,单个模型参数重要性的方法:
三元组重要性分数
在AdaLoRA中,三元组重要性分数计算方式如下: 太好啦,到这一步为止,我们已经把AdaLoRA中难啃的Loss和三元组重要性分数讲完了,是不是比想象得简单很多?接下来我们来啃最后一块硬骨头:知道了三元组的重要性分数后,怎么动态调整矩阵的秩? whaosoft aiot http://143ai.com
太好啦,到这一步为止,我们已经把AdaLoRA中难啃的Loss和三元组重要性分数讲完了,是不是比想象得简单很多?接下来我们来啃最后一块硬骨头:知道了三元组的重要性分数后,怎么动态调整矩阵的秩? whaosoft aiot http://143ai.com
动态调整矩阵的秩
老规矩,在开始讲解前,我们再来明确几个数学符号: 调整函数
调整函数 
top_b策略
在开始讲top_b策略前,我们先来思考一个问题:为什么每次选出的重要三元组的个数,要随着时刻t的变动而变动?
这个问题的答案还是:模型的学习是探索性的过程。
在训练刚开始,我们逐渐增加top_b,也就是逐渐加秩,让模型尽可能多探索。到后期再慢慢把top_b降下来,直到最后以稳定的top_b进行训练,达到AdaLoRA的总目的:把训练资源留给最重要的参数。这个过程就和warm-up非常相似。
具体的策略在原始论文3.3节中有讲解,不难,所以我就不另外分析啦,大家可以自行阅读。以及本文的实验部分,我也不在这边写了,实验部分一句话总结就是相比LoRA确实有了不错的提升,大家可以自己去看细节。
AdaLoRA训练流程总结(必看)
最后,我们把AdaLoRA的整体训练流程总结一下: 以此类推。😭妈呀敲字真的太累了啊。
以此类推。😭妈呀敲字真的太累了啊。
参考
1、https://arxiv.org/abs/2303.10512
2、https://github.com/QingruZhang/AdaLoRA

















 433
433

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









