







继去年推出 I-JEPA 之后,Meta 现在又带来了 V-JEPA,这是一种通过观看视频教会机器理解和建模物理世界的方法,这加快了向 Yann LeCun 所设想的高级机器智能进军的步伐。
论文链接:https://ai.meta.com/research/publications/revisiting-feature-prediction-for-learning-visual-representations-from-video/
Meta 副总裁兼首席 AI 科学家 Yann LeCun 表示:“V-JEPA 让我们更接近于实现让机器具备对世界的深入理解,进而实现更加广泛的推理与规划能力。” 这番话再次强调了提高机器智能的宏大目标 —— 仿照人类学习过程,构建世界内在模型,以便于学习、适应,并在复杂的任务中进行有效规划。
#01 什么是 V-JEPA?
V-JEPA 是一种视觉模型,它通过预测视频中的特征来进行训练,这种方法与传统依赖预先训练好的图像编码器、文本或人工注释的机器学习方法不同。V-JEPA 能够直接从视频数据中学习,无需外部的监督。
#02 V-JEPA 的几大特点
-
自我监督学习:V-JEPA 采用自我监督学习,这意味着它能够在没有标记数据的情况下进行训练,这提高了其适应性和多样性。
-
以特征预测为目标:不同于重建图像或依赖像素级预测,V-JEPA 专注于预测视频特征,这使得训练更加高效,且在后续任务中表现更佳。
-
效率提高:Meta 通过 V-JEPA 实现了显著的效率提升,在缩短训练时间的同时,仍然保持了高性能。
-
多功能的视觉表征:V-JEPA 能够产生适用于多种任务的视觉表征,无论是基于运动还是外观的任务,它都能有效捕捉视频数据中的复杂互动。
#03 V-JEPA 方法论
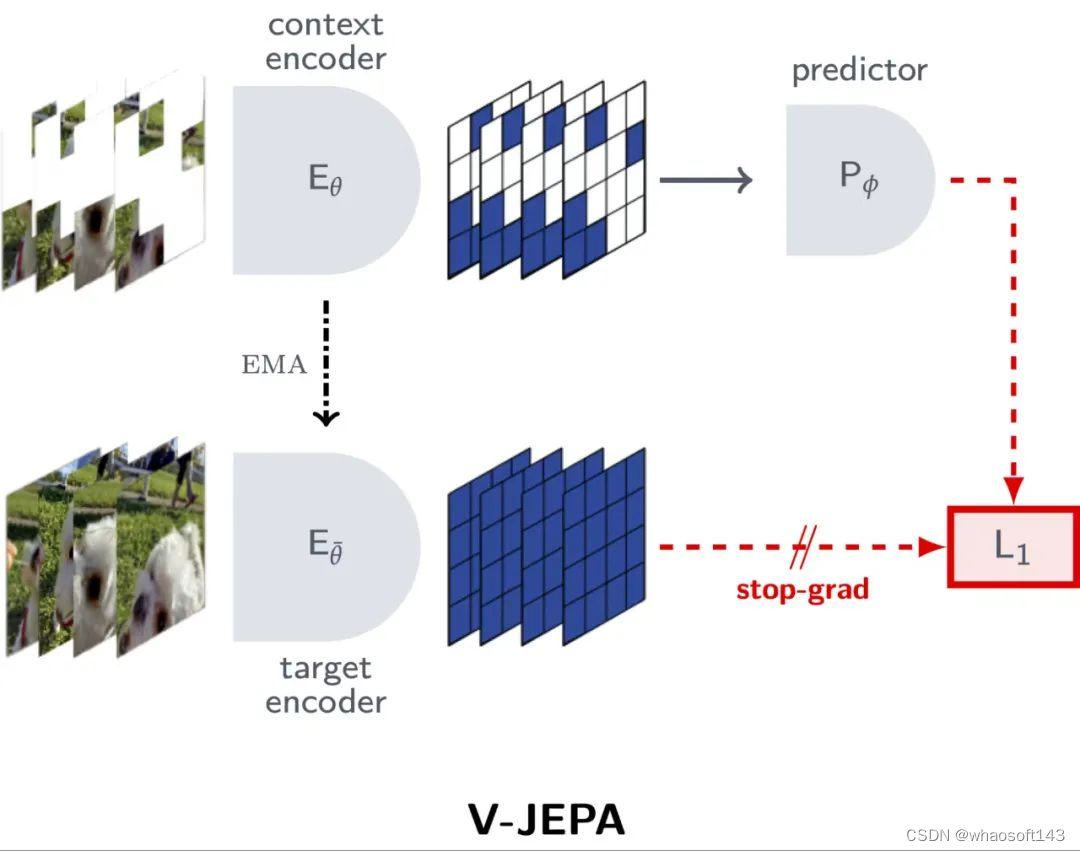
该 AI 模型利用了 VideoMix2M 数据集进行训练,在没有明确指导的情况下,通过观察视频像素来学习。V-JEPA 通过一个无监督学习的方法来预测视频中的特征,而不需要依赖任何外部的标签或注释。这种独特的训练方式使其区别于传统的学习方法,因为它在训练过程中既不依赖预训练的图像编码器、文本、负例、人工注释,也不进行像素级的重建。
与直接处理像素级信息不同,V-JEPA 在潜在空间进行预测,这一点与生成模型明显不同。接下来,一个条件扩散模型被训练来将这些在特征空间中的预测转化为可理解的像素图像,而在这个过程中,V-JEPA 的编码器和预测网络被冻结,不参与更新。值得注意的是,解码器仅处理视频中被遮挡区域的预测表征,而不触及其他部分。
这种方法确保了 V-JEPA 的特征预测与视频中未遮挡部分在时间和空间上的一致性,这对于它能够生成在后续视频和图像任务中表现出色的多功能视觉表征至关重要,而且这一切都无需对模型参数进行调整。
#04 相较于传统的像素预测的优势
V-JEPA 在一个更为抽象的表征空间中进行预测,这使得它能专注于视频中的高层概念信息,而不会被不重要的细节所干扰。
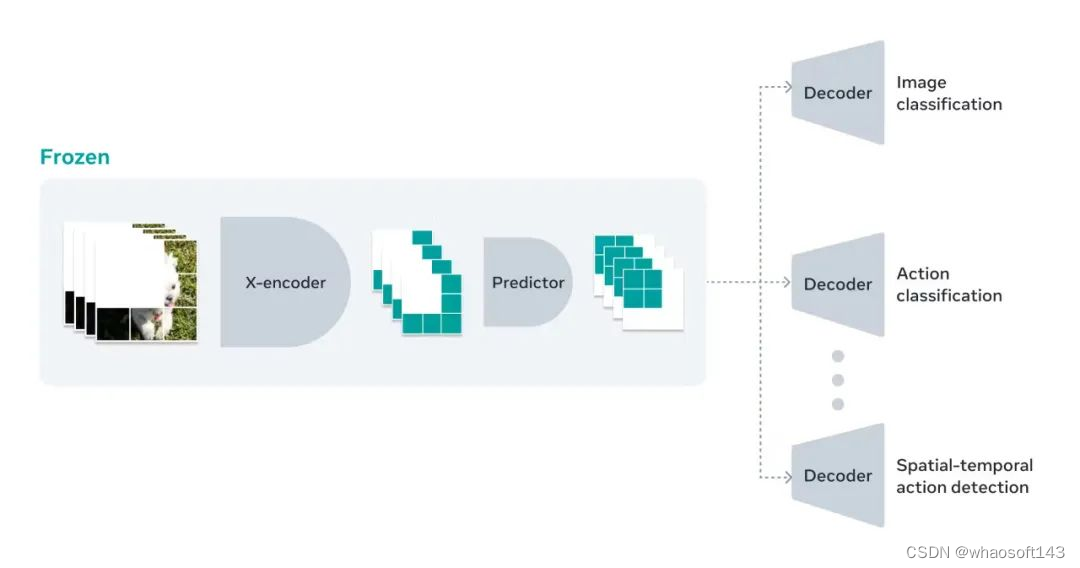
它是首个在 “冻结评估” 环境下表现出色的视频模型,即对编码器和预测器只进行一次预训练后,便不再进行调整。这意味着,为新任务定制模型只需要在其基础上训练一个轻量级的专用层,既高效又迅速。
不同于之前的方法,每个新任务都需要进行全面的微调,V-JEPA 的策略允许在多个任务中复用相同的模型部件,而无需每次都进行针对性训练。这证明了它在执行动作分类和对象交互等任务时的多用途性。
#05 V-JEPA 性能
V-JEPA 在一个包含了 200 万个视频的庞大数据集上接受了训练,这些视频来源于公开的数据集。随后,在一系列的下游图像和视频任务上对模型进行了评估,V-JEPA 在各方面都展示了出色的性能。
与像素预测的比较
在进行像素预测的视频处理方法中,V-JEPA 通过保持所有基准测试的架构一致性进行了评估。诸如 VideoMAE、Hiera 和 OmniMAE 等模型被采用了 ViT-L/16 或 Hiera-L 编码器进行了评估,这两种编码器具有相似的参数设置。评估涵盖了使用注意力探针进行的冻结评估和端到端微调,在下游的视频和图像任务上进行。
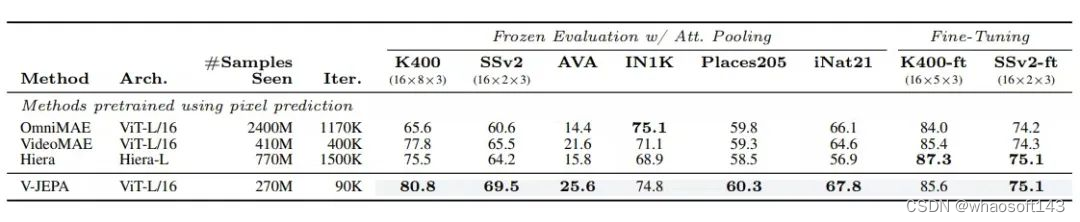
在冻结评估的环境下,V-JEPA 在所有下游任务上均展现了优越性能,仅在 ImageNet 任务上与直接在 ImageNet 上训练的 OmniMAE 模型相比,V-JEPA 的准确率为 74.8%,与 OmniMAE 的 75.1% 相近。
在微调协议下,V-JEPA 的表现超过了其他使用 ViT-L/16 进行训练的模型,并且与使用 Hiera-L 的表现持平,但 V-JEPA 在预训练阶段使用的样本数量明显更少,这强调了以特征预测为核心的学习原则的高效性。 whaosoft aiot http://143ai.com
与最先进模型的比较
在视频上预训练的 V-JEPA 模型与当前最先进的自我监督图像和视频模型进行了对比。这包括了针对图像预训练模型的 OpenCLIP、DINOv2 和 I-JEPA,以及视频预训练模型的 VideoMAE、OmniMAE、Hiera、VideoMAEv2 和 MVD 等多个基线的比较。
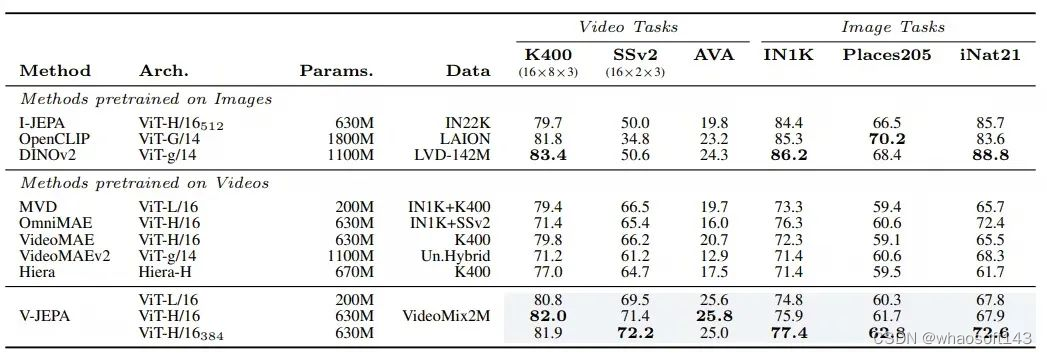
通过对下游图像和视频任务使用注意力探针进行的冻结评估,V-JEPA 在所有任务中都展现了持续的改进,特别是在需要理解运动的任务上表现突出。它有效地缩小了在依赖静态外观特征的任务上,视频和图像模型之间的性能差距。
#06 V-JEPA 应用案例探索
视频内容洞察
V-JEPA 在解析各种视频流内容方面展现出了卓越能力,这使其成为视频分类、动作识别和时空动作侦测等计算机视觉任务的宝贵工具。它能够详细捕捉对象之间的互动并识别精细的动作,这使得 V-JEPA 在视频理解领域独树一帜。
情境智能助理
V-JEPA 提供的情境理解能力为开发具备深层次环境感知的 AI 助手打下了基础。无论是提供基于情境的推荐,还是帮助用户在复杂环境中导航,V-JEPA 都能在多种应用场景中提升 AI 助手的功能。
AR 体验
通过对视频内容的深入理解,V-JEPA 能够为增强现实体验提供丰富的情境信息,无论是提升游戏体验还是提供实时信息的叠加,V-JEPA 都能为沉浸式 AR 应用的发展做出贡献。
随着 Apple Vision Pro 的推出,这项技术可能在提升混合现实体验方面发挥至关重要的作用。
#07 推动高级机器智能(AMI)的 JEPA
V-JEPA 的开发主要集中在感知方面 —— 理解各种视频流的内容,以实现对周围世界的即时情境感知。它的预测器在联合嵌入预测架构中扮演了一个早期的物理世界模型角色,能够在不需深入分析每个细节的情况下理解视频帧中的事件。Meta 的未来目标是利用这一预测模型进行规划和序列决策任务,使其应用范围扩展到感知之外。
作为一种研究模型,V-JEPA 为未来的各种应用带来了希望。它的情境理解能力对于实体化 AI 的发展以及未来 AR 眼镜中情境智能助理的开发可能极为重要。
Meta 强调负责任的开放科学精神,已经在 CC BY-NC 许可下发布了 V-JEPA 模型,鼓励 AI 研究社区的合作与这一开创性工作的进一步发展。
GitHub:https://github.com/facebookresearch/jepa
原文链接:https://encord.com/blog/meta-v-jepa-explained/

















 1017
1017

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









