







# 激光雷达原理
全球汽车行业正在进行自动化变革,这将彻底改变交通运输的安全和效率水平。
戴姆勒在S级豪华车型中引入L3级自动驾驶(L3,在特定条件下自动驾驶,人类驾驶员一旦被请求就会随时接管)是自动驾驶革命的一个重大突破。其他多家汽车公司已经宣布即将推出这一功能,包括本田和宝马。使用LiDAR(光探测和测距)的3D成像是使之成为可能的关键传感技术。
在过去的8年里,LiDAR公司约50亿美元的投资的主要重点是用于乘车、卡车运输和物流的L4级自动驾驶(不需要人类司机的L4级)。由于技术、安全、监管和成本方面的考虑,实现L4/L5级自动驾驶能力已被证明比最初设想的更具挑战性。在许多情况下,这种能力的货币化的商业案例也被证明是不明确的。对于激光雷达公司来说,这是一个艰难的探索,因为时间跨度较长,而且主要的L4玩家正在开发他们的激光雷达(Waymo、Aurora、Argo)。
完全自动驾驶的目标市场:车辆的数量大大降低(<500万辆/年,而消费者的汽车使用约为1亿辆/年)。汽车原始设备制造商没有能力在完全自动驾驶市场上竞争,他们看到了在他们的汽车上增加有限的自动驾驶功能并向更大的客户群销售舒适、自由时间和安全的产品的机会。这使许多LiDAR公司转向解决L2和L3自动驾驶问题。最近宣布的公司包括法雷奥(奔驰)、Innoviz(宝马)、Luminar(沃尔沃)、Cepton(通用汽车)、Ibeo(长城汽车)和Innovusion(Nio)。与汽车一级供应商的合作关系也已经具体化(Aeye-Continental, Baraja-Veoneer, Cepton-Koito, Innoviz-Magna)。
范围和点密度(点/秒或PPS)是制约LiDAR提供的感知能力的关键性能参数。这些参数包括在足够的范围内对车道标记、交通基础设施、路面、行人、车辆和道路碎片进行探测和分类,以实现安全和舒适的自动操纵。虽然性能是至关重要的,但向消费类汽车的转移促使LiDAR公司也关注更多的 "普通 "特性,如价格、尺寸、功耗、车辆集成/造型、制造可扩展性和安全认证。
美国底特律Autosens的一个小组会议讨论了使消费类车辆能够负担得起LiDAR的价格(或痛苦)门槛。作为参考,汽车摄像头和毫米波雷达的价格分别在10-20美元和50-100美元之间,理想的是LiDAR将达到类似的价格点。这在可预见的未来是不合理的,有几个原因。首先,相机和毫米波雷达已经在消费汽车的ADAS(汽车驾驶辅助系统)方面有着几十年的技术积累和发展。其次,它们主要依赖于硅和CMOS技术,这些技术利用了消费和工业电子的规模。激光雷达没有那么成熟,它依赖于复杂的光学半导体技术(特别是激光器)。这个领域的供应链今天根本没有定位来支持这种定价。
使LiDAR的可接受门槛价格合理化的一种方法是将其与L3级自动驾驶车辆配置的价格联系起来。对于奔驰S级车来说,这个价格大约是5000美元。鉴于LiDAR使这一功能成为可能,有理由认为LiDAR可以获得500美元(或L3选项价格的10%)的价格点。随着中等价位的汽车开始提供这个配置,L3的价格将需要降低(约3000美元),而LiDAR的价格将降低到约300美元。只有当设计运行域(ODD)扩大(在速度、位置、天气等方面),并且在这个演变过程中没有发生重大安全事故时,才有可能出现广泛的客户接受。
其次,传感器集成必须在不影响消费者汽车的整体风格和情感吸引力的情况下进行。尺寸和功耗制约着传感器的集成位置和方式。传感器(尤其是LiDAR)所消耗的大部分功率被转化为热量。从效率、热管理和缩小尺寸的角度来看,尽量减少热量是有益的。
毫米波雷达传感器的体积为100-500立方厘米,消耗5-15W的功率(取决于性能)。照相机明显更小,更省电(通常在25-200立方厘米的范围内,耗电约3W)。汽车中的空间是宝贵的,随着L2级和L3级功能的发展,LiDAR需要与这些传统的传感器在空间、功率、计算资源和热管理方面进行竞争。
操作物理学、扫描方法和波长是驱动尺寸和功耗的关键因素。表1的主要结论如下。
④是最不紧凑的方法。1550nm ToF(飞行时间)操作需要高峰值功率的光纤激光器,它不像半导体二极管激光器那样紧凑。二维扫描和独立的发射/接收孔径也往往使LiDAR的体积更大。
①似乎是最紧凑的方法。FMCW/RMCW(频率/随机调制连续波)使用同调检测(将一部分发射光束与接收光束光学混合)。这允许使用与半导体光放大器集成的二极管激光器。光机械扫描发生在一个维度上(水平方向)。垂直扫描是通过可调谐激光器和类似棱镜的光学器件(没有移动部件)完成的。它还使用了一个单静止结构(通过一个光圈进行发射/接收)。
与905纳米(②)相比,1550纳米LiDAR(①和④)消耗更高的功率,但也提供更高的范围性能。较高的功率消耗是由多种因素造成的。首先,激光器被允许以更高的光功率驱动(1550纳米的眼睛安全阈值比905纳米的高得多)。其次,1550纳米的激光器效率较低,消耗更多的电功率。最后,由于温度敏感性较高,1550纳米激光器需要被冷却或温度稳定。这就消耗了电力。
LiDAR射程和PPS性能的世代改进(Innoviz和Valeo在②)增加了电力消耗。这是可以理解的,因为更高的性能需要更多的激光功率、占空比和空间频率。信号处理计算能力也会增加。在这些情况下,尺寸似乎与功耗的增加成正比。
相对于Flash LiDAR(③)提供的适度性能,它在尺寸和功耗方面是昂贵的。如果消除移动部件是一个关键的考虑因素(可靠性或集成度),那么使用电子扫描的架构就更有吸引力(③),因为它们在同等大小的情况下能提供明显更高的性能,并大大降低功耗。折衷的办法是,全局快门操作是不可能的,从而导致点云的模糊效应。
LiDAR在集成度、尺寸和功耗方面正在逐渐成熟。相对于毫米波雷达,它在尺寸和功耗方面仍然是~2-3倍大。成像相机甚至更紧凑、更省电(尺寸低10倍,功率低5倍)。
随着时间的推移,LiDAR是否会达到与这些其他传感器同等的水平?1550纳米的FMCW/RMCW LiDAR(①)一旦在硅光子学平台上实现了芯片级的二维光学扫描,就能提供与雷达同等尺寸的最佳潜力(这是目前积极研究的领域,但在实际中还不可行)。功耗不可能降低,因为基本的激光技术需要有重大的材料改进(在过去的三十年里,为了支持光纤通信,已经在这个领域进行了大量的投资,而且不太可能有巨大的改进)。功率消耗的主要部分是由激光器引起的,其中70%以上被转化为热量,需要加以管理。这反过来又对尺寸设定了一个下限。
要确保像LiDAR这样复杂的光机械传感器能够从原型到大批量生产的扩展,需要在设计的早期阶段考虑供应链和可制造性。在这方面,LiDAR公司和一级供应商(他们已经掌握了有效扩展到批量生产的流程和科学)之间的伙伴关系是非常宝贵的。
法雷奥公司设计和制造其LiDAR(SCALA系列)。在Autosens,他们提出了影响设计过程的考虑因素--技术选择、供应商、工艺简单性、成本、可靠性和可扩展性。周期时间和废品水平得到了严格的分析和验证。法雷奥的理念是推出满足当前汽车客户需求的 "适合功能 "的设计(最初可能在性能上不领先于竞争对手,但对客户来说是可靠和易于部署的),将这些设计投入批量生产,并将规模化和低成本的经验作为未来设计的性能升级的基础。迄今为止,已经生产了超过17万个汽车级LiDAR(跨越SCALA 1和2系列,SCALA 2目前是在前面讨论的奔驰S级中设计的)。SCALA 3利用这一经验,性能显著提高,将于2023年推出。法雷奥的方法与许多风险投资的LiDAR公司不同,这些公司最初往往专注于最大限度地提高性能,并假设一旦产量增加,规模和成本要求将得到解决。这是一个困难的主张。 whaosoft aiot http://143ai.com
希捷科技是一家大型的硬盘驱动器(HDD)制造商,每年生产超过1亿台。在Autosens会议上,他们介绍并演示了他们的LiDAR,这是一个1550纳米的系统,能够实现动态凹陷,120°视场,250米范围和25W的功耗。该公司首创了HAMR(热辅助磁记录),用于增加硬盘的存储容量。安装在记录头上的激光二极管被用来局部加热单个比特,以翻转磁极并协助写入过程。光学、精密机械、高速电子和扫描是关键的设计平台。硬盘制造线利用光学、机械和电子部件的精确定位(亚微米)和粘合,以及高产量的在线和最终测试。希捷公司的战略是利用其HDD产品的专利、相关技术块和制造基础设施,用于汽车LiDAR。在拥挤的LiDAR生态系统中,希捷公司可能不同于其他任何加入者。他们从现有的高产量、低成本的生产线开始,将类似复杂性的产品设计插入其中。他们可能在未来颠覆LiDAR市场。
Trioptics介绍了为汽车市场大批量制造LiDAR的一些制造设备挑战。光学、机械和电子元件的精确对准和粘合是高产量LiDAR制造的关键,同样也是在非常低的周期时间内校准和测试子组件和最终产品的能力。关键是要确保每一个子组件的设计和采购都有足够的精度水平和基准点,以便机器人自动化能够有效地发挥作用。Trioptics公司正在为LiDAR的生产建立商业化的设备,他们的主张与20年前基于光纤的通信系统的扩展类似。它催生了一个专门用于制造光电子元件的专业设备行业,包括预烧/测试、光纤对准/连接、芯片/导线粘接、密封和可靠性测试系统。
对传感器安全认证的两个关键标准的方法:ISO 26262功能安全标准和新兴的ISO 21448标准,涉及预期功能安全(SOTIF)。后者涉及一个特定的车辆功能在承诺的ODD中的表现。对于像LiDAR这样的新传感器,在不利的照明和天气条件下,将其转化为物体检测和分类(例如车辆、行人、障碍物和交通基础设施)是至关重要的。LiDAR供应商越来越关注这个新标准,尽管目前还不清楚这是否是由OEM或Tier 1承担的事情。
汽车LiDAR无疑已经到来。虽然L4自动驾驶市场还很遥远,但需要LiDAR的有限自动驾驶水平(L2和L3)提供了一个更有利可图的近期机会。设计的机会是有限的,对这些机会的竞争是残酷的。赢得这些机会将需要在性能、成本、可靠性和易于集成方面提供正确的平衡。
下文是TI关于激光雷达的介绍PPT欢迎大家关注,一起学习。
# 自动驾驶热点方向
端到端自动驾驶
Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
-
Paper: https://arxiv.org/pdf/2312.03031.pdf
-
Code: https://github.com/NVlabs/BEV-Planner
Visual Point Cloud Forecasting enables Scalable Autonomous Driving
-
Paper: https://arxiv.org/pdf/2312.17655.pdf
-
Code: https://github.com/OpenDriveLab/ViDAR
LLM Agent
ChatSim: Editable Scene Simulation for Autonomous Driving via LLM-Agent Collaboration
-
Paper: https://arxiv.org/pdf/2402.05746.pdf
-
Code: https://github.com/yifanlu0227/ChatSim
语义场景补全
Symphonize 3D Semantic Scene Completion with Contextual Instance Queries
-
Paper: https://arxiv.org/pdf/2306.15670.pdf
-
Code: https://github.com/hustvl/Symphonies
人工智能内容生成
Panacea: Panoramic and Controllable Video Generation for Autonomous Driving
-
Paper: https://arxiv.org/pdf/2311.16813.pdf
-
Code: https://github.com/wenyuqing/panacea
三维目标检测
PTT: Point-Trajectory Transformer for Efficient Temporal 3D Object Detection
-
Paper: https://arxiv.org/pdf/2312.08371.pdf
-
Code: https://github.com/KuanchihHuang/PTT
双目立体匹配
MoCha-Stereo: Motif Channel Attention Network for Stereo Matching
-
Paper:
-
Code: https://github.com/ZYangChen/MoCha-Stereo
协同感知
RCooper: A Real-world Large-scale Dataset for Roadside Cooperative Perception
-
Paper:
-
Code: https://github.com/ryhnhao/RCooper
SLAM
SNI-SLAM: SemanticNeurallmplicit SLAM
-
Paper: https://arxiv.org/pdf/2311.11016.pdf
Scene Flow Estimation
DifFlow3D: Toward Robust Uncertainty-Aware Scene Flow Estimation with Iterative Diffusion-Based Refinement
-
Paper: https://arxiv.org/pdf/2311.17456.pdf
-
Code: https://github.com/IRMVLab/DifFlow3D
Efficient Network
Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications
-
Paper: https://arxiv.org/pdf/2401.06197.pdf
Segmentation
OMG-Seg: Is One Model Good Enough For All Segmentation?
-
Paper: https://arxiv.org/pdf/2401.10229.pdf
-
Code: https://github.com/lxtGH/OMG-Seg
# 关于BEV车道线落地的点点滴滴
21年 埋下了一颗种子
看过BEV障碍物故事的同学应该清楚,我们组是在21年10月左右开始做BEV 障碍物的。那个时候不敢想着去做BEV 车道线,因为没有人力。但是我记得在12月左右的时候,我们面到了一个候选人,在面试的过程中听到他们做了差不多半年多的BEV 车道线,整个技术路线是通过高精地图来作为BEV 车道线网络的训练真值,并说效果还不错。很遗憾,那个候选人最后没有来我们这里。结合21年Telsa AI day 讲的车道线内容,一个要做BEV 车道线的种子就这样在组内埋下了。
22年 走对了第一步
整个22年,我们组内人力都是很紧张的,我记得在6,7月份的时候,我们刚好有人力去探索一下BEV 车道线。但是当时我们组只有一个同学(我们就先叫他小轩同学吧)有2个月的时间去做这件事。然后21年的那颗种子开始发芽了,我们准备先从数据下手,小轩同学还是很给力的(很有想象力,后续小轩同学也做了更多令大家惊喜的东西),差不多用了2月的时间,我们可以通过高速高精地图来提取对应的车周围的车道线数据。当时做出来的时候,我记得大家还是很激动的。

图1: 高精地图车道线 投影到图像系的效果
大家从图1上可以看出,贴合对还是有一些问题,因此小轩同学又做了系列的优化。2个月后,小轩同学去做其他任务了,现在回头看,我们的BEV 车道线探索之路,已经走对了第一步。因为在21年,22年已经逐步有很多优秀的BEV 车道线论文和代码相继开源。看到这里,你可能以为23年一定有一个完完美美的BEV 车道线落地的故事,然后理想往往都很丰满,现实却是很残酷。
23年 跌跌撞撞
由于我们BEV 障碍物已经证明BEV 这条路是可以走下去了,并且在路测也表现出了不错的效果。组内开始有了更多的资源来考虑车道线这件事,注意这里不是BEV了。为什么呢?因为在这个时候,我们面临了很大的上线压力,BEV 车道线又没有足够的经验,或者说整个组内做过2D 车道线量产的人都几乎没有。23年前半年,真的可以用跌跌撞撞来形容,我们内部激烈的讨论了很多次,最后决定形成2条线,一条线为2D 车道线: 大部分的人力在2D 车道线这条线上,重后处理,轻模型,通过2D 车道线这条线来积累车道线后处理量产经验。一条线为BEV 车道线:只有一小部分人力(其实就1-2个人力),注重BEV 车道线的模型设计, 积累模型经验。BEV 车道线的网络已经有很多了,我在这里贴2篇对我们影响比较大的论文供大家参考。《HDMapNet: An Online HD Map Construction and Evaluation Framework》 和 《MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction》
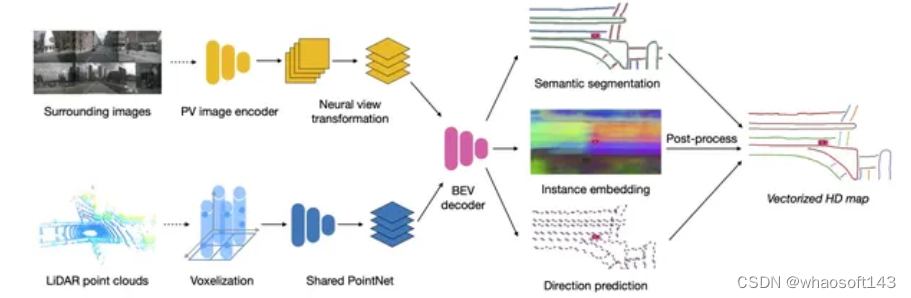
图2: HDMapNet
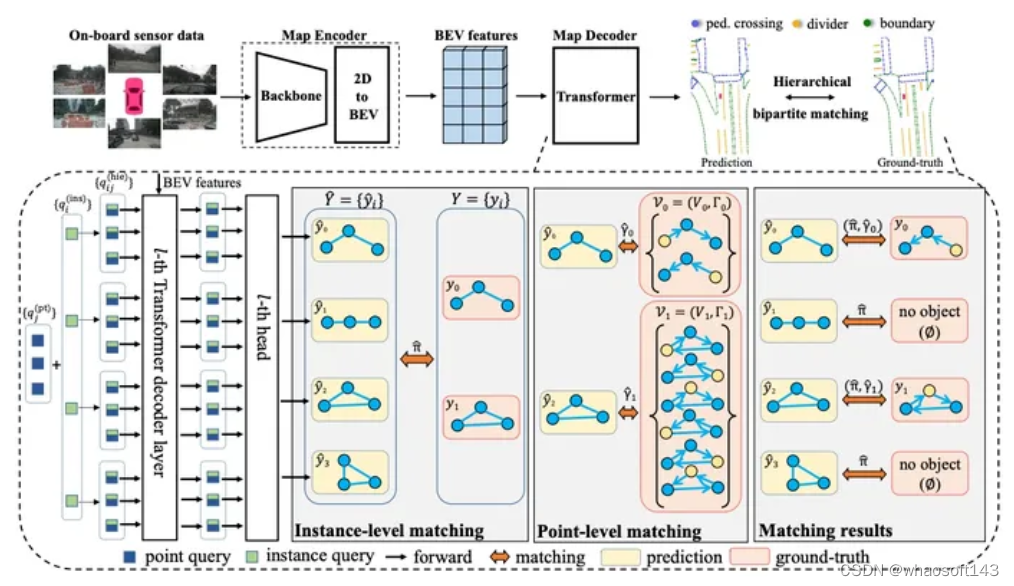
图3 MapTR
很幸运,在4,5月份的时候,我们在2D 车道线这条线积累了大量的车道线后处理量产经验,我们的BEV 车道线网络也设计出来了,在5月底,很快BEV 车道线顺利上车。在这里不得不说一下我们负责车道线后处理的大海同学,还是很给力的。然而当你觉得很顺利的时候,往往噩梦就要开始了。BEV 车道线部署后,控车效果不理想,这个时候大家陷入了自我怀疑阶段,到底是因为BEV 车道线3次样条曲线拟合的问题,还是下游参数没有适配好的问题。万幸的是,我们车上有供应商的效果,我们在路测时把供应商的车道线结果保存下来,然后在可视化工具里面在和我们的结果对比。当控车效果不好的时候,先证明我们自己的车道线质量是没有问题,这样驱动下游来适配我们的BEV车道线。一个月,整整一个月的时间,我们才稳定控车。我记得很清楚,我们还从上海跑到苏州,那天还是周六,大家在群里看到高速的控车效果都很激动。
然而一个故事往往都是一波三折的,我们只能利用高速高精地图来生产车道线数据。城市怎么办,还有那么多badcase 需要解决。这个时候重要人物终于要出现了,我们就先叫他小糖同学吧(我们数据组的大管家)。小糖同学他们利用点云重建来给我们重建出来重建clip(这个过程还是蛮痛苦,我记得那两个月是他们压力最大的时候,哈哈,当然我们和小糖同学经常相爱相杀,毕竟经常在开会时常常说又没有数据了。)。然后重建出来后怎么标注,放眼当时手里的供应商们,都没有这样的标注工具,别说什么标注经验了。又是和小糖同学他们一起,经历了漫长的1个月时间,标注工具终于和供应商打磨好了。(我们经常开玩笑说,我们这是在赋能整个自动驾驶的标注行业,这个过程是真痛苦,重建clip 加载是真慢 )。然而整个标注还是比较慢的,或者比较贵,这个时候小轩同学带着他的车道线预标注大模型闪亮登场(车道线预标注的大模型效果还是杠杠的),大家看他的眼神都在闪闪发光。这一套组合拳打下来,我们的车道线数据生产终于是磨合的差不多了。8月份的时候我们的BEV 车道线控车道线已经迭代的不错了,对于简单的高速领航功能。现在小轩同学在大模型预标注方向依旧不断的给我们带来更多的惊喜,我们和小糖同学依旧在相爱相杀中。
然而一个故事都不是这么容易结束,我们在9月份的时候,开始动手做多模态(Lidar,camera,Radar)多任务(车道线,障碍物,Occ)前融合模型,并后续支持城市领航功(NCP), 也就是所谓的重感知,轻地图的方案。基于BEV障碍物和BEV 车道线的经验前融合网络我们很快就部署上车了,应该是在9月底的时候。车道线也加了很多子任务,路面标识别,路口的拓扑等等。在这个过程中,我们对BEV 车道线的后处理进行了升级,抛弃了车道线3次样条曲线拟合,而采用点的跟踪方案,点的跟踪方案和我们的车道线模型的输出可以很好的结合在一起。这个过程也是一个痛苦的,我们连续2个月,每周开一次专项会,毕竟我们已经基于拟合的方案做的不错了,但是为了更高的上限,只能痛并快乐着。最终目前我们已经把基础的功能进行路测了。
稍微给大家解释一下图4,左边是车道线点跟踪的效果目前我们模型的感知范围只有前80米,大家可以看到车后也有一些点,这是跟踪留下的。右边是我们的建立的实时感知图,当然现在还在一个快速迭代的过程,还有很多问题正在解决中。
24年 新的开始
时刻,站在24年回看我们从21年到现在的一路成长和积累,很庆幸在21年那个点,有机会去做BEV, 也很庆幸有一群志同相合的小伙伴一路相辅相成。24年,对我们来说,有很多东西需要去追寻,前融合模型的量产上线,数据方向的发力,时序模型的探索,端到端的畅想等等。
# 开环端到端自动驾驶中自车状态是你所需要的一切吗?
原标题:Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving?
论文链接:https://arxiv.org/abs/2312.03031
代码链接:https://github.com/NVlabs/BEV-Planner
作者单位:南京大学 NVIDIA
论文思路:
端到端自动驾驶最近作为一个有前景的研究方向浮现出来,以全栈视角为目标寻求自动化。沿这条线,许多最新的工作遵循开环评估设置在 nuScenes 上研究规划行为。本文通过进行彻底的分析并揭示更多细节中的难题,更深入地探讨了这个问题。本文最初观察到,以相对简单的驾驶场景为特征的 nuScenes 数据集,导致在整合了自车状态(ego status)的端到端模型中感知信息的利用不足,例如自车的速度。这些模型倾向于主要依赖自车状态进行未来路径规划。除了数据集的局限性之外,本文还注意到当前的指标并不能全面评估规划质量,这导致从现有基准中得出的结论可能存在偏见。为了解决这个问题,本文引入了一个新的指标来评估预测的轨迹是否遵循道路。本文进一步提出了一个简单的基线,能够在不依赖感知标注的情况下达到有竞争力的结果。鉴于现有基准和指标的局限性,本文建议学术界重新评估相关的主流研究,并谨慎考虑持续追求最先进技术是否会产生令人信服的普遍结论。
主要贡献:
现有基于 nuScenes 的开环自动驾驶模型的规划性能受到自车状态(ego status) (速度、加速度、偏航角)的高度影响。当自车状态(ego status) 参与进来,模型最终预测的轨迹基本上由它主导,导致对感知信息的使用减少。
现有的规划指标未能完全捕捉到模型的真实性能。模型的评估结果在不同指标之间可能会有显著差异。本文主张采用更多样化和全面的指标,以防止模型在特定指标上实现局部最优,这可能会导致忽视其他安全隐患。
与在现有的 nuScenes 数据集上推动最先进性能相比,本文认为开发更合适的数据集和指标代表了一个更为关键和紧迫的挑战。
论文设计:
端到端自动驾驶旨在以全栈方式共同考虑感知和规划[1, 5, 32, 35]。一个基本的动机是将自动驾驶车辆(AV)的感知作为达成目的(规划)的手段来评估,而不是过度拟合某些感知度量标准。
与感知不同,规划通常更加开放式且难以量化[6, 7]。理想情况下,规划的开放式特性将支持闭环评估设置,在该设置中,其他代理可以对自车的行为做出反应,原始传感器数据也可以相应地变化。然而,到目前为止,在闭环模拟器中进行代理行为建模和真实世界数据模拟[8, 19]仍然是具有挑战性的未解决问题。因此,闭环评估不可避免地引入了与现实世界相当大的域差距(domain gaps)。
另一方面,开环评估旨在将人类驾驶视为真实情况,并将规划表述为模仿学习[13]。这种表述允许通过简单的日志回放,直接使用现实世界的数据集,避免了来自模拟的域差距(domain gaps)。它还提供了其他优势,例如能够在复杂和多样的交通场景中训练和验证模型,这些场景在模拟中经常难以高保真度生成[5]。因为这些好处,一个已经建立的研究领域集中于使用现实世界数据集的开环端到端自动驾驶[2, 12, 13, 16, 43]。
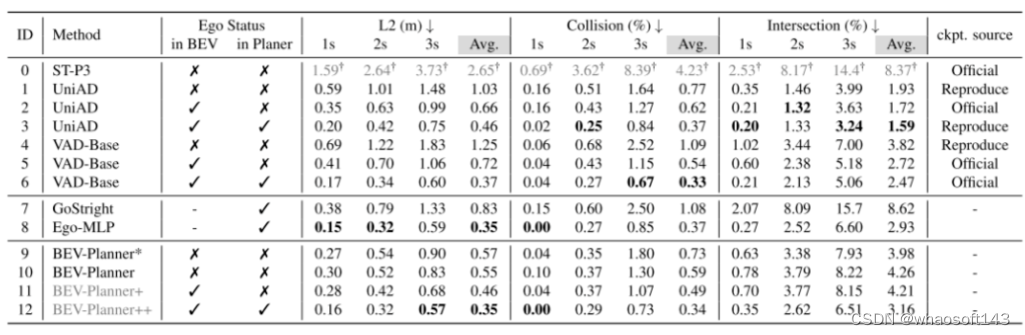
目前流行的端到端自动驾驶方法[12, 13, 16, 43]通常使用 nuScenes[2] 来进行其规划行为的开环评估。例如,UniAD[13] 研究了不同感知任务模块对最终规划行为的影响。然而,ADMLP[45] 最近指出,一个简单的MLP网络也能仅依靠自车状态(ego status) 信息,就实现最先进的规划结果。这激发了本文提出一个重要问题:
开环端到端自动驾驶是否只需要自车状态(ego status) 信息?
本文的答案是肯定的也是否定的,这考虑到了在当前基准测试中使用自车状态(ego status) 信息的利弊:
是。自车状态(ego status) 中的信息,如速度、加速度和偏航角,显然应有利于规划任务的执行。为了验证这一点,本文解决了AD-MLP的一个公开问题,并移除了历史轨迹真实值(GTs)的使用,以防止潜在的标签泄露。本文复现的模型,Ego-MLP(图1 a.2),仅依赖自车状态(ego status) ,并且在现有的L2距离和碰撞率指标方面与最先进方法不相上下。另一个观察结果是,只有现有的方法[13, 16, 43],将自车状态(ego status) 信息纳入规划模块中,才能获得与 Ego-MLP 相当的结果。尽管这些方法采用了额外的感知信息(追踪、高清地图等),但它们并未显示出比 Ego-MLP 更优越。这些观察结果验证了自车状态(ego status) 在端到端自动驾驶开环评估中的主导作用。
不是。很明显,作为一个安全至关重要的应用,自动驾驶在决策时不应该仅仅依赖于自车状态(ego status) 。那么,为什么仅使用自车状态(ego status) 就能达到最先进规划结果的现象会发生呢?为了回答这个问题,本文提出了一套全面的分析,涵盖了现有的开环端到端自动驾驶方法。本文识别了现有研究中的主要缺陷,包括与数据集、评估指标和具体模型实现相关的方面。本文在本节的其余部分列举并详细说明了这些缺陷:
数据集不平衡。NuScenes 是一个常用的开环评估任务的基准[11–13, 16, 17, 43]。然而,本文的分析显示,73.9%的 nuScenes 数据涉及直线行驶的场景,如图2所示轨迹分布反映的那样。对于这些直线行驶的场景,大多数时候保持当前的速度、方向或转向率就足够了。因此,自车状态(ego status) 信息可以很容易地被作为一种捷径来适应规划任务,这导致了 Ego-MLP 在 nuScenes 上的强大性能。
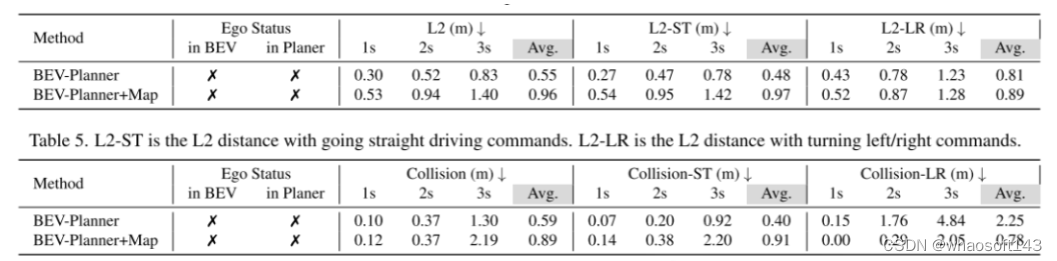
现有的评估指标不全面。NuScenes 数据中剩余的26.1%涉及更具挑战性的驾驶场景,可能是规划行为更好的基准。然而,本文认为广泛使用的当前评估指标,如预测与规划真实值之间的L2距离以及自车与周围障碍物之间的碰撞率,并不能准确衡量模型规划行为的质量。通过可视化各种方法生成的众多预测轨迹,本文注意到一些高风险轨迹,如驶出道路可能在现有指标中不会受到严重惩罚。为了回应这一问题,本文引入了一种新的评估指标,用于计算预测轨迹与道路边界之间的交互率(interaction rate)。当专注于与道路边界的交汇率(intersection rates) 时,基准将经历一个实质性的转变。在这个新的评估指标下,Ego-MLP 倾向于预测出比 UniAD 更频繁偏离道路的轨迹。
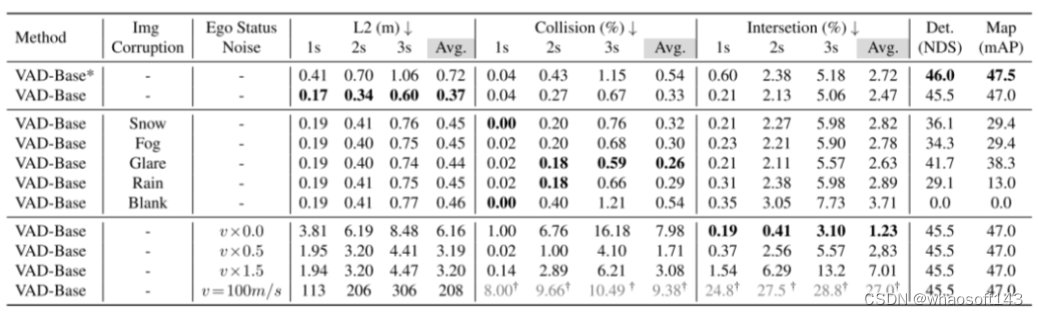
自车状态(ego status)偏见与驾驶逻辑相矛盾。由于自车状态(ego status) 可能导致过拟合,本文进一步观察到一个有趣的现象。本文的实验结果表明,在某些情况下,从现有的端到端自动驾驶框架中完全移除视觉输入,并不会显著降低规划行为的质量。这与基本的驾驶逻辑相矛盾,因为感知被期望为规划提供有用的信息。例如,在 VAD [16] 中屏蔽所有摄像头输入会导致感知模块完全失效,但如果有自车状态(ego status) 的话,规划的退化却很小。然而,改变输入的自身速度可以显著影响最终预测的轨迹。
总之,本文推测,最近在端到端自动驾驶领域的努力及其在 nuScenes 上的最先进成绩很可能是由于过度依赖自车状态(ego status) ,再加上简单驾驶场景的主导地位所造成的。此外,当前的评估指标在全面评估模型预测轨迹的质量方面还不够。这些悬而未决的问题和不足可能低估了规划任务的潜在复杂性,并且造成了一种误导性的印象,那就是在开环端到端自动驾驶中,自车状态(ego status) 就是你所需要的一切。
当前开环端到端自动驾驶研究中自车状态(ego status) 的潜在干扰引出了另一个问题:是否可以通过从整个模型中移除自车状态(ego status) 来抵消这种影响?然而,值得注意的是,即使排除了自车状态(ego status) 的影响,基于 nuScenes 数据集的开环自动驾驶研究的可靠性仍然存疑。
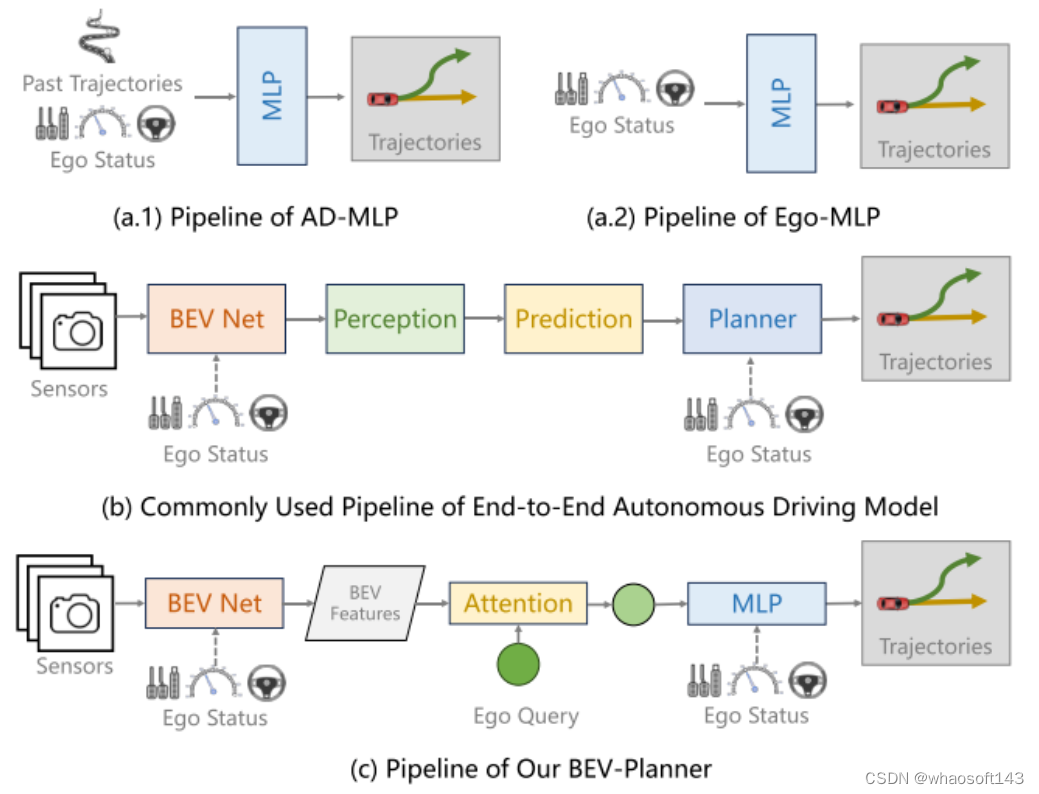 图1。(a) AD-MLP 同时使用自车状态(ego status) 和过去轨迹的真实值作为输入。本文复现的版本(Ego-MLP)去掉了过去的轨迹。(b) 现有的端到端自动驾驶流程包括感知、预测和规划模块。自车状态(ego status) 可以集成到鸟瞰图(BEV)生成模块或规划模块中。(c) 本文设计了一个简单的基线以便与现有方法进行比较。这个简单的基线不利用感知或预测模块,而是直接基于 BEV 特征预测最终轨迹。
图1。(a) AD-MLP 同时使用自车状态(ego status) 和过去轨迹的真实值作为输入。本文复现的版本(Ego-MLP)去掉了过去的轨迹。(b) 现有的端到端自动驾驶流程包括感知、预测和规划模块。自车状态(ego status) 可以集成到鸟瞰图(BEV)生成模块或规划模块中。(c) 本文设计了一个简单的基线以便与现有方法进行比较。这个简单的基线不利用感知或预测模块,而是直接基于 BEV 特征预测最终轨迹。
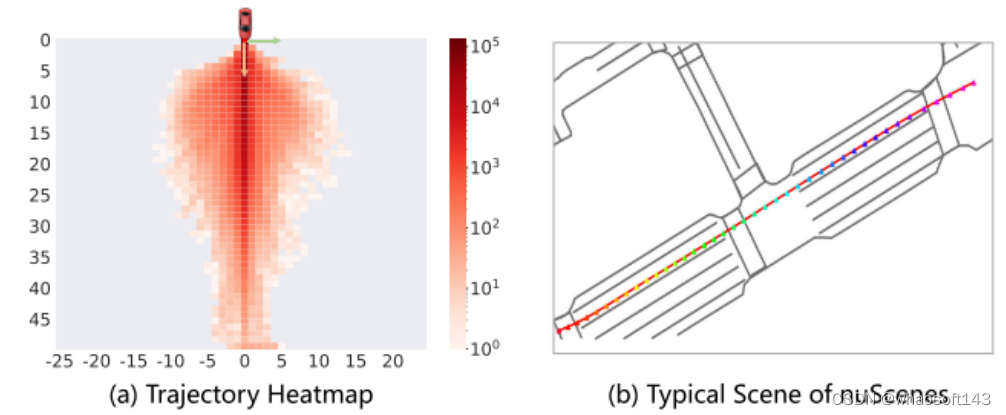
图2。(a) nuScenes 数据集中的自车轨迹热图。(b) nuScenes 数据集中的大多数场景由直行驾驶情况组成。
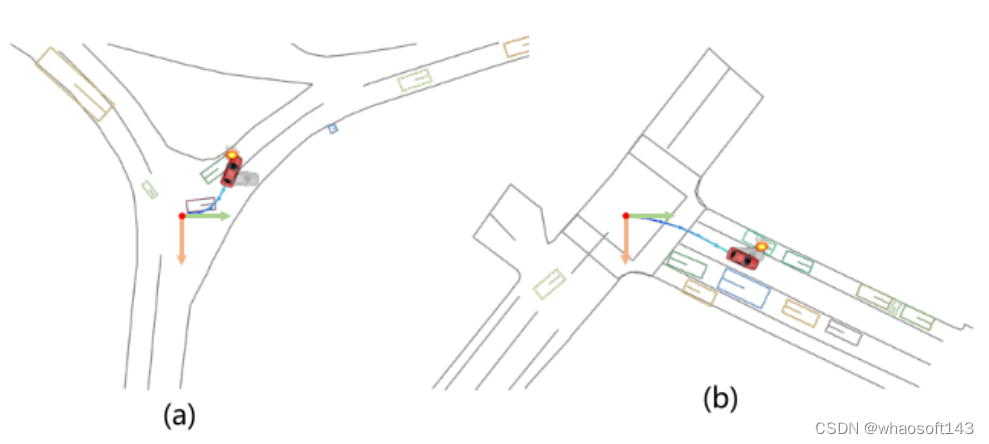
图3。当前方法[12, 13, 16]忽略了考虑自车的偏航角变化,始终保持0偏航角(由灰色车辆表示),从而导致假阴性(a)和假阳性(b)的碰撞检测事件增加。本文通过估计车辆轨迹的变化来估计车辆的偏航角(由红色车辆表示),以提高碰撞检测的准确性。
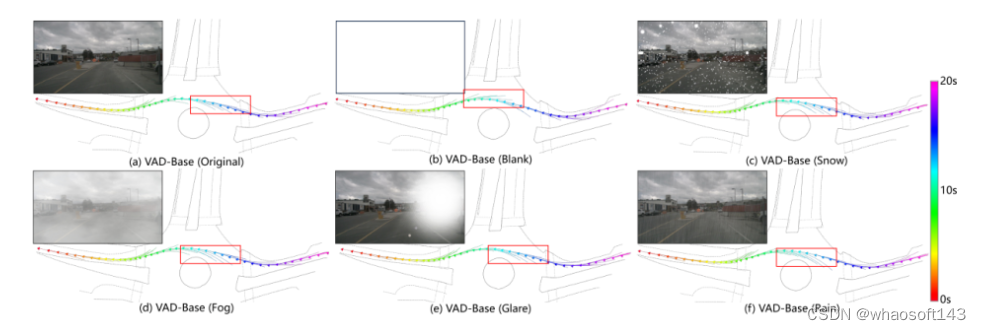
图4。本文展示了 VAD 模型(在其规划器中结合了自车状态(ego status) )在各种图像损坏情况下的预测轨迹。给定场景中的所有轨迹(跨越20秒)都在全局坐标系统中呈现。每个三角形标记代表自车的真实轨迹点,不同的颜色代表不同的时间步。值得注意的是,即使输入为空白图像,模型的预测轨迹仍保持合理性。然而,红色框内的轨迹是次优的,如图5中进一步阐述的。尽管对所有环视图像都进行了损坏处理,但为了便于可视化,只显示了初始时间步对应的前视图像。
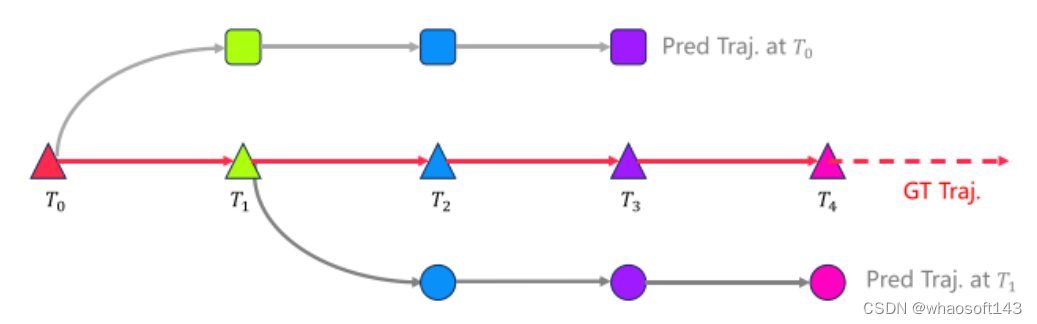
图5。在开环自动驾驶方法中,从自车的起始位置预测未来轨迹。在模仿学习范式内,预测轨迹理想情况下应该与实际的真实轨迹密切对齐。此外,连续时间步预测的轨迹应保持一致性,从而保证驾驶策略的连续性和平滑性。因此,图4 中红色框显示的预测轨迹不仅偏离了真实轨迹,而且在不同的时间戳上显示出显著的分歧。
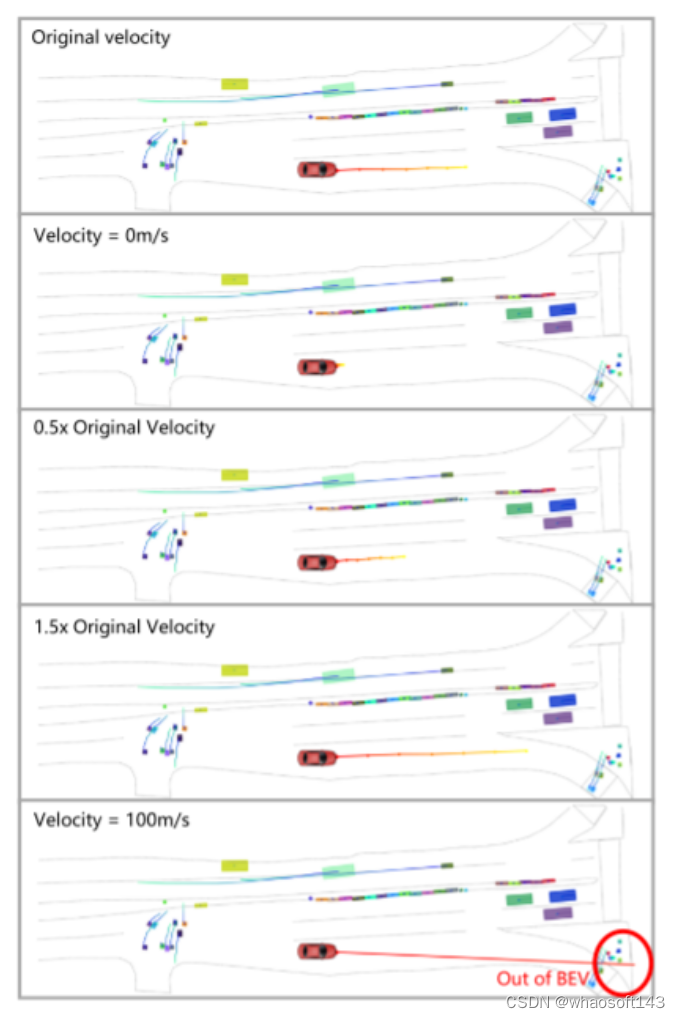
图6。对于在其规划器中结合了自车状态(ego status) 的基于VAD的模型,本文在视觉输入保持恒定的情况下,向自车速度引入噪声。值得注意的是,当自车的速度数据被扰动时,结果轨迹显示出显著的变化。将车辆的速度设置为零会导致静止的预测,而速度为100米/秒会导致预测出不切实际的轨迹。这表明,尽管感知模块继续提供准确的周围信息,模型的决策过程过分依赖于自车状态(ego status) 。
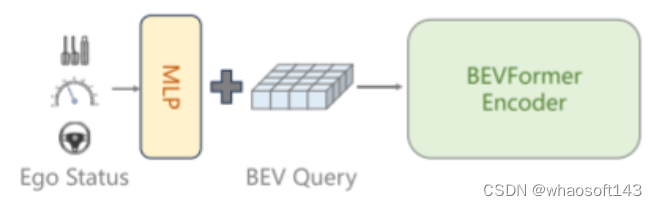
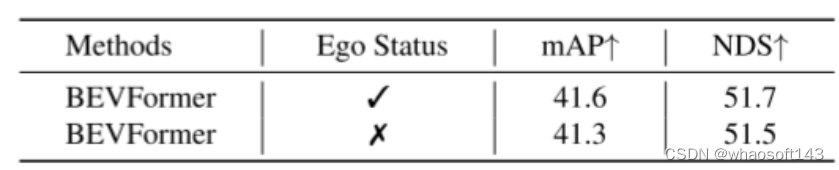
图7。BEVFormer在 BEV查询的初始化过程中结合了自车状态(ego status) 信息,这是当前端到端自动驾驶方法[13, 16, 43]未曾涉及的细节。
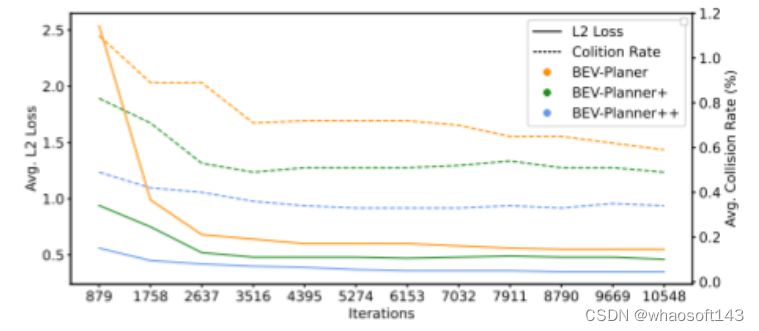
图8。在 BEV-Planner++ 中引入自车状态(ego status) 信息使得模型能够非常快速地收敛。
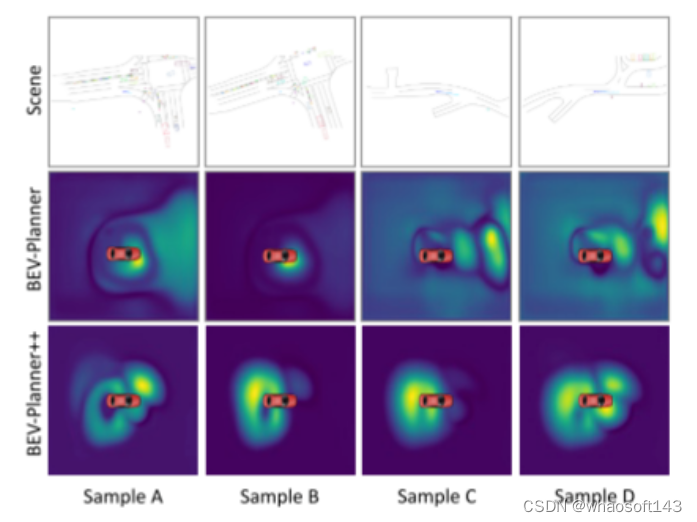
图9。比较本文基线的 BEV特征与相应的场景。
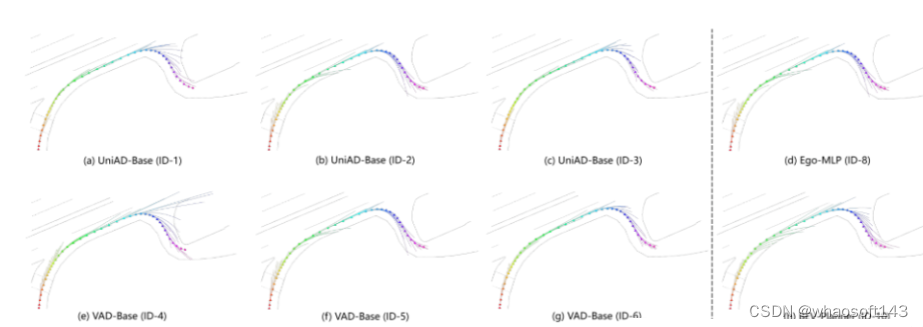
实验结果:


论文总结:
本文深入分析了当前开环端到端自动驾驶方法固有的缺点。本文的目标是贡献研究成果,促进端到端自动驾驶的逐步发展。

















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









