









内容预告
这期带你一步步在香橙派 5 Max 上跑 Deepseek R1。 结论先行: 香橙派 5 (RK3588) 采用不同计算单元推理速度: NPU >> CPU > GPU
Deepseek-8B 8bit 量化版 (8.6GB) 推理速度在 2.8 tokens / 秒。
其他小模型,比如 Llama 3.2, Phi 3, Qwen 1.5B 推理速度会更快。
所有文件项目 下载链接在文末 (国内 ICloud 直链下载, 看我的 ICloud 容量限制,后期会删除。也可自行🪜外网下载)。
💡 下期预告:如何像 OpenAI 一样用聊天界面在 RK3588 上跟 LLM 聊天?不想错过的朋友欢迎关注公众号!
RK3588 的 AI 推理速度
关于要为 树莓派 4 或者 5 证明的朋友,先来看下面这张 CPU Benchmark 对比图:
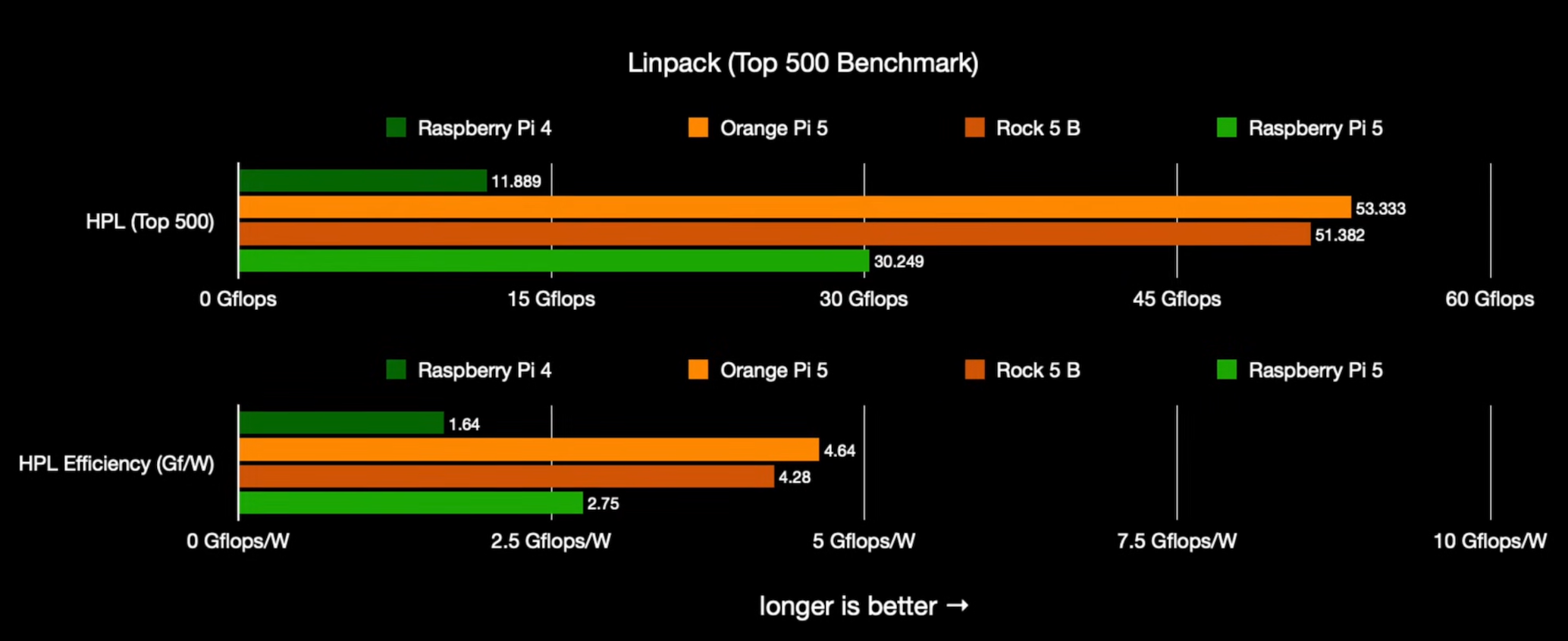
亮绿色是 树莓派 5,亮橙色是 香橙派 5。 孰强孰弱?不言自明。 目前市场上能打的,大概只有英伟达的 Jetson 系列,但 16GB 版本要 4000+ RMB。
而香橙派 AI Pro 虽然算力更高 (8-20 TOPs),但听说(三个个例听来的,目前无实测数据)发热严重,希望华为 昇腾 310B 的硬件优化再做好点,另外软件生态也要跟上。
吐槽一句:瑞芯微是难产了吗?RK3688 什么时候出?RK3588 能吹一辈子牛吗?
如何在香橙派 5 (RK3588) 上运行 LLM?
第一步:下载并安装项目
打开终端,执行以下命令:
git clone https://github.com/Pelochus/ezrknn-llm.git
cd ezrknn-llm
sudo bash install.sh
我把项目下载在了 orange-pi 目录下。
如果你用默认路径,项目会下载在 Home 目录。
第二步:下载适配 RK3588 的 LLM 模型
进入 Huggingface 的 RK3588 模型专区 🔗
👉 https://huggingface.co/models?sort=trending&search=rk3588
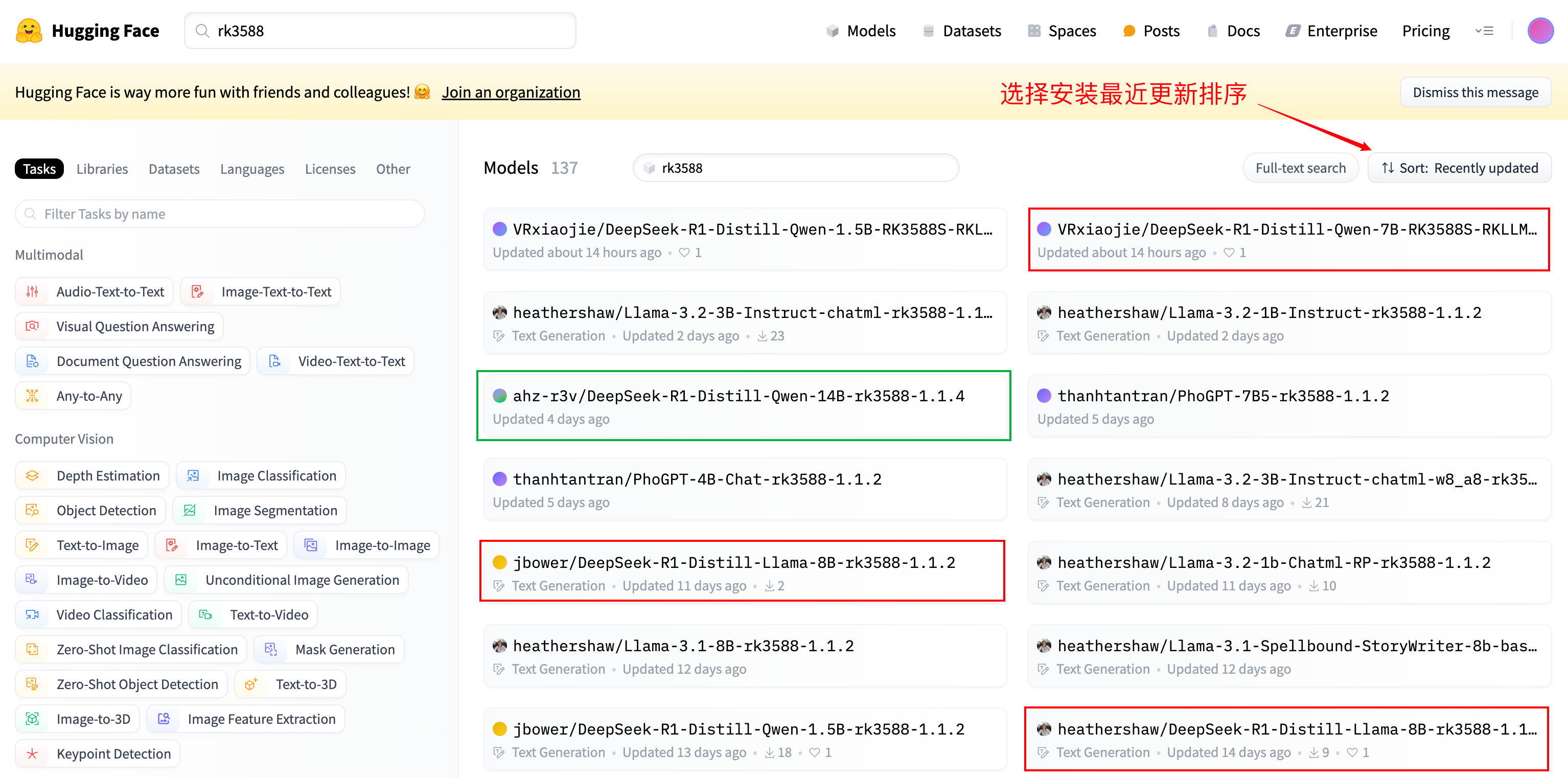
按 最近更新 排序,推荐下载 DeepSeek R1 蒸馏模型:
-
红色框:8B 模型 (8.5GB) -
绿色框:14B 模型 (目前作者还没有更新,不过挺期待)
💡 建议购买至少 16GB 内存的香橙派 5,8GB 版本也可以跑一些小模型: 比如 Llama 3.2, Phi3, Qwen 1.5B 等,回答速度杠杠的。
我下载了最右上角的模型,点击进入 HuggingFace 页面,下载模型文件 📂 deepseek-r1-7B-rkllm1.1.4.rkllm。 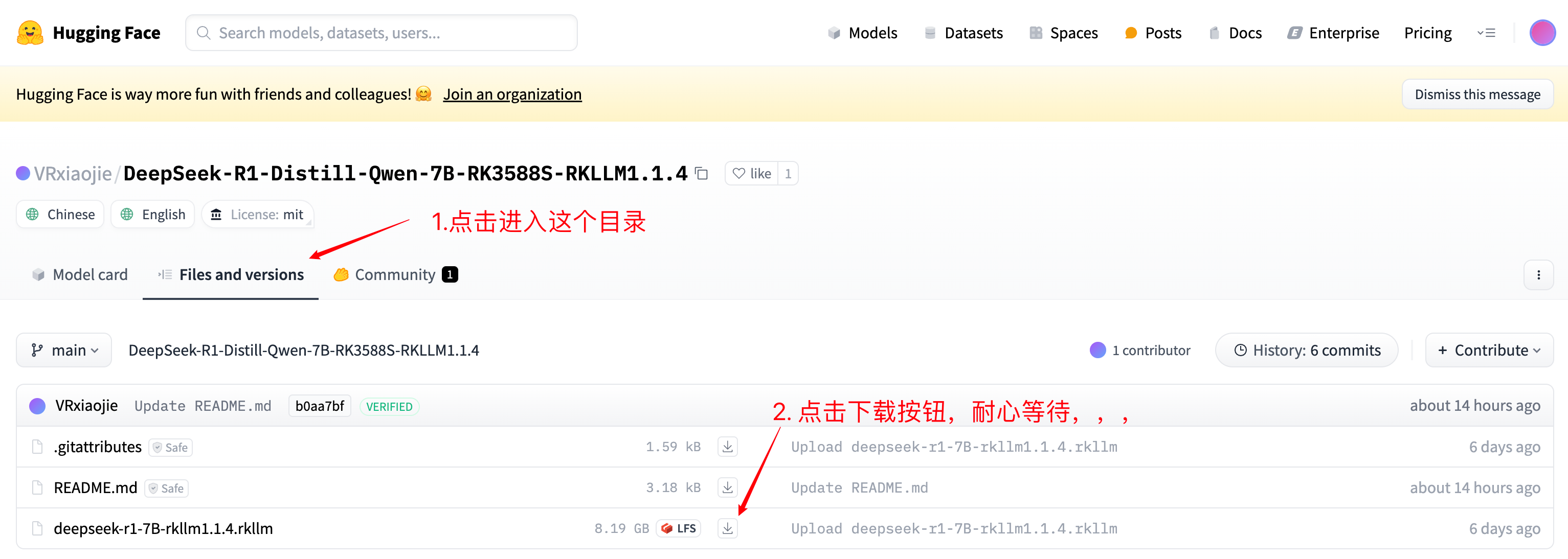
默认在 Download 目录下 
第三步:运行 LLM
使用以下命令启动:
rkllm /home/jason/Downloads/deepseek-r1-7B-rkllm1.1.4.rkllm 4096 4096
-
[model path]: /home/jason/Downloads/deepseek-r1-7B-rkllm1.1.4.rkllm你下载的模型文件路径 -
[max_new_tokens]: 4096 控制生成 token 数量 (越大,回复越长) -
[max_context_len]: 4096 影响模型记忆容量 (越大,记忆上下文越多)

运行过程中可能会报错,如果报错请到 ezrknn-llm/rkllm-runtime/runtime/Linux/librkllm_api/include/rkllm.h 这个头文件中的第三行插入 #include <cstdint> 
NPU、CPU、GPU 推理速度对比
在 RK3588 上运行 LLM,推理速度如下:
结论
NPU >> CPU > GPU ✅
NPU 的推理速度明显领先 GPU,但稍慢于 CPU。
但 CPU 占用率很高,而 NPU 能释放 CPU 资源,实际体验更好!
模型载入 & 运行
载入后,系统 + 模型共占 10.6GB 内存。
CPU 占用 10% 左右,说明 LLM 主要在 NPU 上跑。
💡 测试问题:
"给我的公众号上的朋友们写一首赛博朋克风格的爱情赞歌"
 模型载入后,加上系统软件一起占用了 10.6GB 内存。CPU 几乎维持在 10% 上下,因为 LLM 加载在 NPU 上跑。
模型载入后,加上系统软件一起占用了 10.6GB 内存。CPU 几乎维持在 10% 上下,因为 LLM 加载在 NPU 上跑。
给公众号的朋友们献上这首 赛博朋克风格的爱情赞歌 
总结 & 互动
香橙派 5 (RK3588) 本地跑 LLM,值得入手吗? ✅ 适合:
-
16GB 版本,可流畅跑 7B-8B 级别模型 -
想体验 NPU 跑 AI 的玩家 -
对 Jetson 价格敏感,但仍需要 AI 计算能力
❌ 不适合:
-
8GB 版本,容易受限,推荐跑小于 8B 的模型
你对 RK3588 跑 AI 有什么想法?
📢 欢迎留言讨论,或者分享你的实测结果!🚀
如果你的 Ubuntu 环境还没设置好,请参考这篇:
如果你对其他的硬件感兴趣,请参考下面的文章:
-
预算有限也能玩转 AI: 香橙派、树莓派与 Jetson 的选择攻略 -
只要 249 美元! 67 TOPs 最具性价比 AI 电脑 -
全网最全香橙 Pi 选择指南: 这一篇就够了 -
本地跑 LLM 需要多少内存显存
树莓派环境搭建:
工具及模型下载链接🔗
-
公众号回复 "20250207"
参考链接
-
🔗 https://briliantn.com/blog/2024/rockchip-llm/ -
🔗 https://github.com/c0zaut -
🔗 https://huggingface.co/models?sort=trending&search=rk3588
不定期更新专业知识和有趣的东西,欢迎反馈、点赞、加星
您的鼓励和支持是我坚持创作的最大动力!ღ( ´・ᴗ・` )


















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









