









内容预告
英伟达的显卡算力到底怎么计算?到底用 TFLOPs 还是用 TOPs 衡量算力合理?它们之间有什么关系?
这篇文章用通俗易懂的方式,手把手教你计算 NVIDIA GPU 的理论峰值 FP32 性能(TFLOPs) 和 低精度运算性能(TOPs),同时揭开它们的真实含义!
为爱发电,如果对你有帮助,请不吝点赞和关注,谢谢。
术语速览
在正式计算 TFLOPs 之前,先搞懂这些关键概念。
-
GPU(Graphics Processing Unit)
图形处理器,主要用于图形渲染和通用并行计算。现代 GPU(如 NVIDIA 的 GeForce 系列)在 AI 推理和训练中也发挥着重要作用。 -
TFLOPs(Tera Floating-Point Operations Per Second)
表示每秒执行的万亿次浮点运算数。对于 FP32 运算(32 位浮点运算),常用 TFLOPs 来衡量 GPU 的算力。 -
TOPs(Tera Operations Per Second)
表示每秒执行的万亿次操作,通常用于描述低精度(如 INT8)运算的吞吐量,主要反映 GPU 内张量核心在 AI 推理任务中的性能。 -
CUDA 核心
每个 CUDA 核心是 NVIDIA GPU 中的基本运算单元,主要用于执行标准浮点运算(如 FP32 运算)。 -
MAC (Multiply-Accumulate)
乘加运算,是神经网络计算中常见的一种操作,涉及一次乘法后跟一次加法。 -
Boost 时钟频率
GPU 在负载下运行时可达到的最大加速频率。 -
INT8
8 位整数格式,常用于神经网络推理的量化运算,可以在较低精度下实现更高的运算吞吐量。
1. TFLOPs 的计算方法
对于 FP32 运算,理论峰值 TFLOPs 可按下式计算:
T F L O P s = 2 × ( CUDA 核心数 ) × ( Boost 时钟频率 ) / 1 0 12 TFLOPs = 2 \times (\text{CUDA 核心数}) \times (\text{Boost 时钟频率}) / 10^{12} TFLOPs=2×(CUDA 核心数)×(Boost 时钟频率)/1012
其中,“2”表示每个 FMA(融合乘加)操作在一个时钟周期内执行两次浮点运算。
举例:RTX 4080
- CUDA 核心数:9728
- Boost 时钟:约 2.51 GHz
T F L O P s ≈ 2 × 9728 × 2.51 × 1 0 9 / 1 0 12 ≈ 48.83 T F L O P s TFLOPs \approx 2 \times 9728 \times 2.51 \times 10^9 / 10^{12} \approx 48.83\,TFLOPs TFLOPs≈2×9728×2.51×109/1012≈48.83TFLOPs
以上计算与官方数据基本一致。
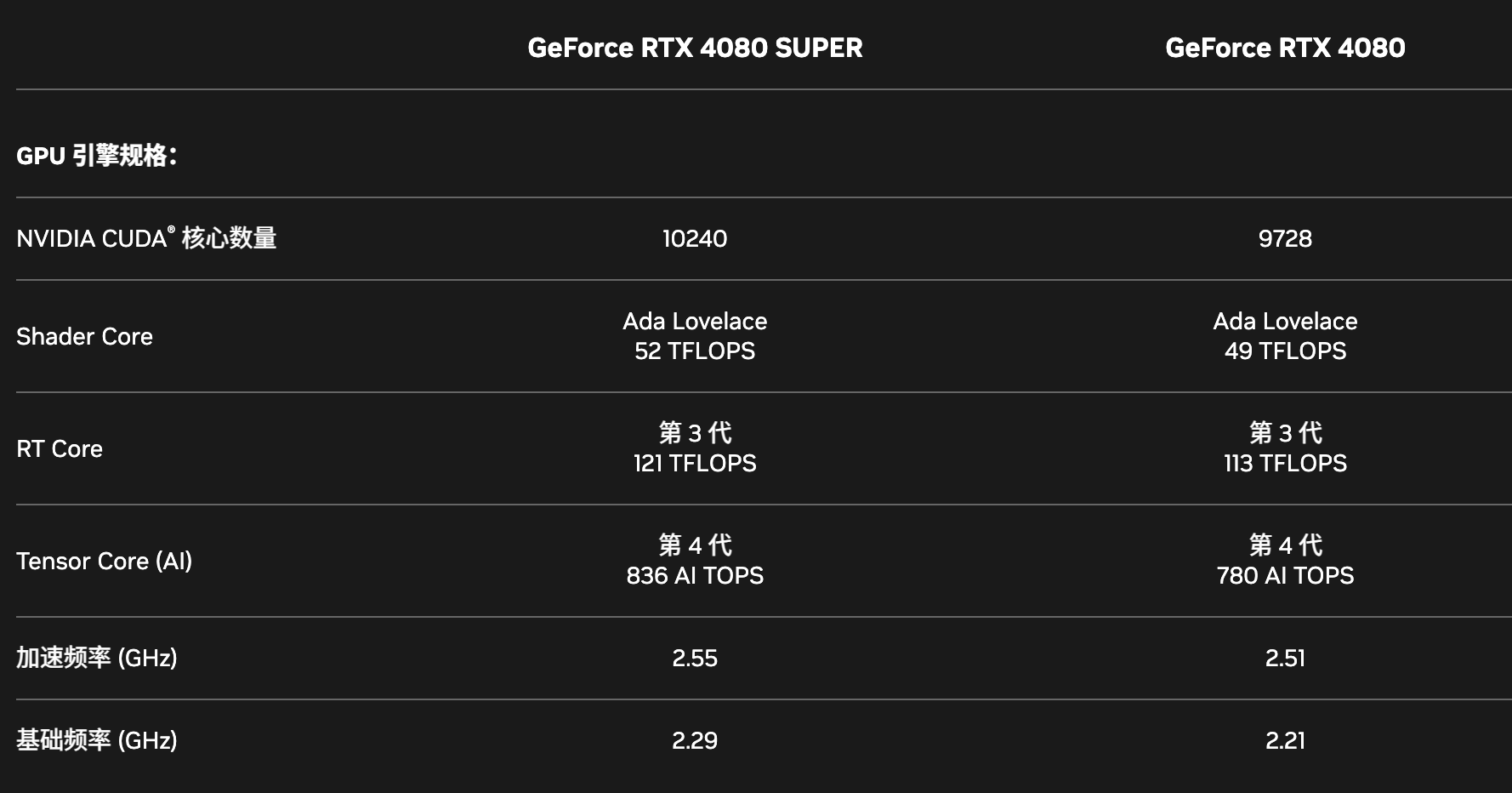
2. TOPs 的计算及比例观察
虽然可以用类似的公式计算 INT8(或其他低精度)运算的吞吐量,即:
T O P s = ( 每个时钟周期 MAC 操作数 ) × ( Boost 时钟频率 ) / 1 0 12 TOPs = (\text{每个时钟周期 MAC 操作数}) \times (\text{Boost 时钟频率}) / 10^{12} TOPs=(每个时钟周期 MAC 操作数)×(Boost 时钟频率)/1012
但实际上,NVIDIA 没有公开严格的计算方法,比如一个 CUDA 核心可以执行多少次乘加 (MAC) 运算。因为 TOPs 更多是一个市场描述指标,用于展示张量核心在 AI 推理中的潜在性能。
我们可以通过比较官方数据观察 TOPs 与 TFLOPs 之间的比例(记作 α \alpha α):
| 显卡 | 官方 TFLOPs | 官方 AI TOPs | α = TOPs / TFLOPs \alpha = \text{TOPs} / \text{TFLOPs} α=TOPs/TFLOPs |
|---|---|---|---|
| RTX 3080 | 29.768 | 238.1 | ≈ 8 |
| RTX 3090 | 35.581 | 284.7 | ≈ 8 |
| RTX 4080 | 48.737 | 779.8 | = 16 |
| RTX 4090 | 82.575 | 1321.2 | = 16 |
| RTX 5080 | 56.341 | 1802.9 | ≈ 32 |
| RTX 5090 | 104.883 | 3356.3 | = 32 |
由此可以看出,不同系列之间 TOPs 与 TFLOPs 的比例并非固定,而是存在变化:
- 30 系列: α ≈ 8 \alpha \approx 8 α≈8
- 40 系列: α ≈ 16 \alpha \approx 16 α≈16
- 50 系列:预计 α ≈ 32 \alpha \approx 32 α≈32
这说明,英伟达官方给出的 TOPs 数值实际上是通过将 TFLOPs 乘以一个架构相关的比例系数得到的,这个系数反映了架构在低精度运算优化上的变化,而并非严格的硬件计算结果。
3. 结论
-
对比不同英伟达显卡性能,使用 FP32 性能(TFLOPs) 更靠谱
-
低精度运算性能(TOPs)
官方数据显示,不同系列之间的 TOPs 与 TFLOPs 的比例( α \alpha α)大致为:- 30 系列: α ≈ 8 \alpha \approx 8 α≈8
- 40 系列: α ≈ 16 \alpha \approx 16 α≈16
- 50 系列:预计
α
≈
32
\alpha \approx 32
α≈32
这表明,TOPs 数值更多是为了展示在 AI 推理中低精度运算的优势,而非直接反映 GPU 硬件的计算能力。
总的来说,NVIDIA 的 GPU 在图形和通用并行计算上表现卓越,且其在 AI 低精度计算上的 TOPs 数据是通过架构优化和市场策略设定的指标。但是官方的 TOPs 没有反应出不同显卡之间的性能差异,推荐大家使用 TFLOPs。
参考
不定期更新专业知识和有趣的东西,欢迎反馈、点赞、加星
您的鼓励和支持是我坚持创作的最大动力!


















 7769
7769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









