







一、Supervised Neural Networks
Neural Networks
假设:
(1)输入图像向量化的(忽略像素的空间布局)
(2)目标标签是离散的(用于分类)
Neural Networks: example
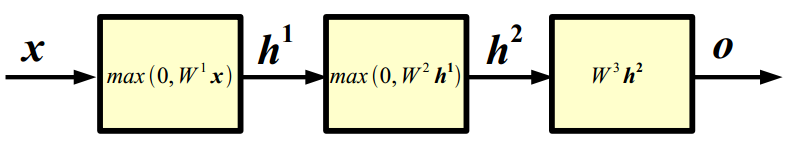
X : 输入
h1 : 第一隐含层
h2 : 第二隐含层
o : 输出层
(1)前向传播:给定输入,计算网络输出的过程;
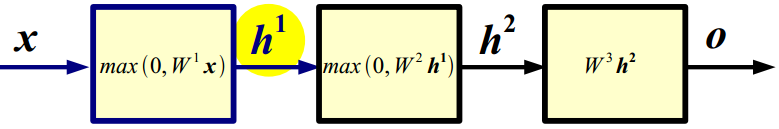
x∈ RD;W1∈RN1×D;b1∈RN;h1∈RN1
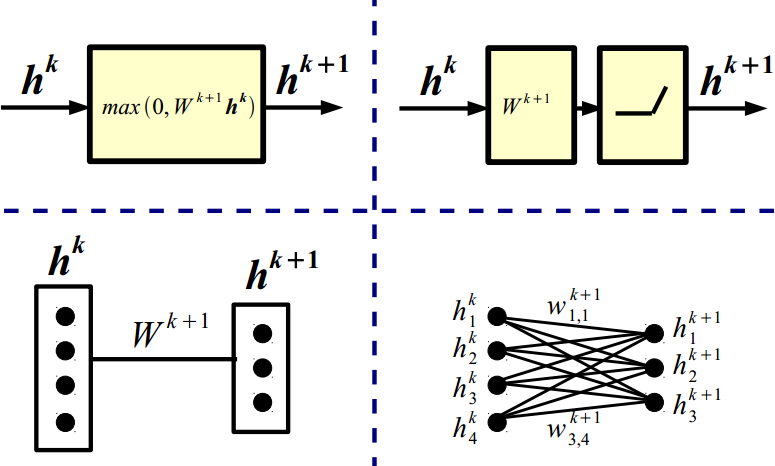
h1=max(0,W1X+b1) ;
其中,W1表示第一层的权值矩阵;b1表示第一层的偏差;非线性的函数U=max(0,V)叫做 ReLU(激活函数)
h1∈RN1;W2∈RN2×N1;b2∈RN2;h2∈RN2
h2=max(0,W2h1+b2) ;
h2∈RN2;W3∈RN3×N2;b3∈RN3;o∈RN3
o=max(0,W3h2+b3) ;
模型的选择表示:
问题1:为什么层与层之间的映射不能是线性的?
回答:因为线性函数的合成还是线性函数,神经网络就相当于一层的逻辑回归运算了。
问题2:为什么ReLU层能做到?
回答:分段线性的堆叠,映射都是局部线性的。
问题3:为什么神经网络需要很多层?
回答:当输入有层次结构,使用分层结构的可能更为高效,因为中间计算可以重新使用。DL架构是有效的也正是因为他们使用的跨类共享的分布式表示。
问题4:隐含层主要能做什么?
回答:可以被理解为一个分类器或者一个特征检测器?
问题5:网络有多少层?有多少隐含层?
回答:交叉验证或超参数搜索方法是答案。在一般情况下,网络更宽和更深,映射就更复杂。
问题6:权值矩阵怎么设定?
回答:权值矩阵和偏差是被学习的;首先,要定义当前映射初试尺度,然后定义调整参数的程序。
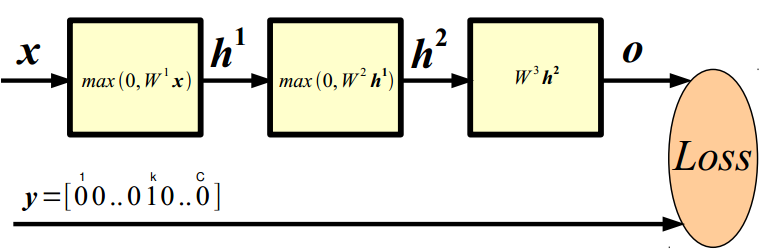
类别k的概率:

负对数似然函数:(适用于类别少的样本)
Training
学习最小化的损失函数:
问题7:怎么样最小化含有参数的复杂函数?
回答:链式法则,Backpropagation,计算梯度损失的程序,关于一个多层神经网络参数。
Key Idea : 降低损失;
通过调整权值矩阵W的数值降低损失,设e=0.00001;
计算:
然后更新:
(2)反向传播:
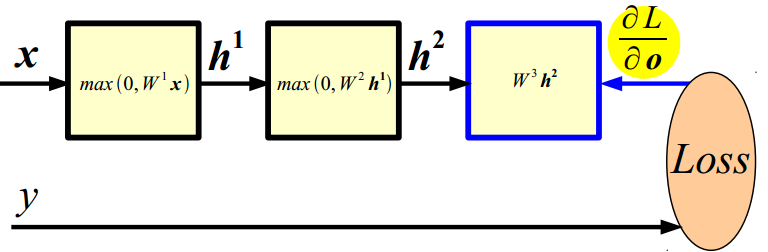
(1)给定 ∂L/∂o,假设我们能够简单的计算每个模型的雅可比行列式Jacobian;得到:
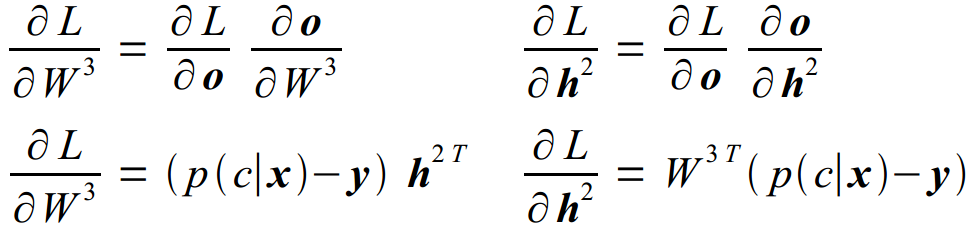
(2)给定∂L/∂h2,能够计算:
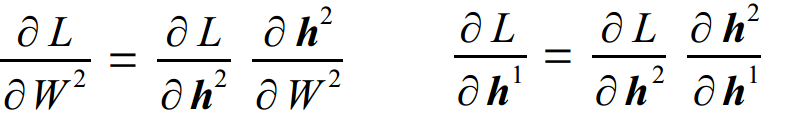
(3)给定∂L/∂h1,能够计算:
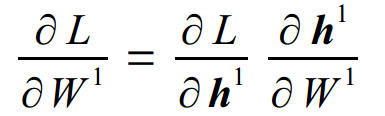
Optimization:
随机梯度下降:
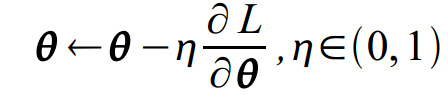
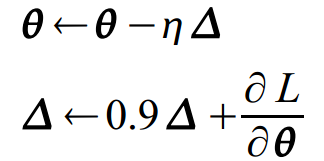
(matlab code)Neural Net Trainer
% F-PROP
for i = 1 : nr_layers - 1
[h{i} jac{i}] = nonlinearity(W{i} * h{i-1} + b{i});
end
h{nr_layers-1} = W{nr_layers-1} * h{nr_layers-2} + b{nr_layers-1};
prediction = softmax(h{l-1});
% CROSS ENTROPY LOSS
loss = - sum(sum(log(prediction) .* target)) / batch_size;
% B-PROP
dh{l-1} = prediction - target;
for i = nr_layers – 1 : -1 : 1
Wgrad{i} = dh{i} * h{i-1}';
bgrad{i} = sum(dh{i}, 2);
dh{i-1} = (W{i}' * dh{i}) .* jac{i-1};
end
% UPDATE
for i = 1 : nr_layers - 1
W{i} = W{i} – (lr / batch_size) * Wgrad{i};
b{i} = b{i} – (lr / batch_size) * bgrad{i};
end二、Convolutional Neural Networks
(1)Fully Connected Layer
- 空间相关性是局部的;
- 资源浪费+我们永远不会有足够的训练样本;
(2)Locally Connected Layer
因为在不同局部的统计特性是相似的;
(3)Convolutional Layer
- 不同的局部共享同样的参数(假设输入时固定的)、与学习到的内核进行卷积;
学习多个滤波器:
当n层有m个滤波器的时候,下一层将会生成m个map,n+1层每个map再和n+2层的每个滤波器分别进行卷积,然后分别累加和生成新的map,每个map包含不同的特征;
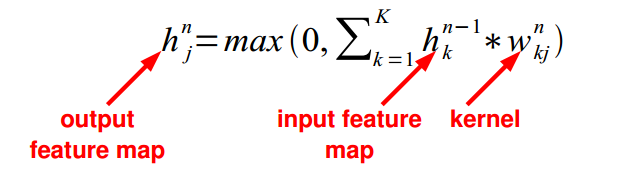
问题:输出的尺寸是多大?计算成本是多少?
回答:它正比如滤波器的数目,决定于滤波器的stride(幅度)。如果卷积核是k*k,输入时D*D,stride是1;有M个输入特征层(feture maps)和N个输出特征层;
则:输入的size是M@D*D
输出的size是N@(D-K+1)*(D-K+1)
卷积核有M*N*K*K个系数(必须被学习的)
计算成本是: M*K*K*N*(D-K+1)*(D-K+1)
问题8:有多少个特征映射层(feture map)?滤波器的尺寸是多大?
回答:通常,输出的特征映射层比输入的多,卷积层能够通过大因子(big factor)lai 增加隐含层的数目(同时会增加计算量);滤波器的大小必须和我们要检测(视任务而定)图案的尺寸/规模相匹配。
Key Ideas:
应用于图像的标准的(传统的非卷积的)神经网络:
- 规模是输入尺寸的平方
- 不利用平稳性
解决方法:
- 每个隐藏单元连接到输入的一小块
- 跨空间共享权值
(3)Pooling Layer
假设滤波器是一个“眼镜”观测器;
问题9:怎么样能够使检测器对眼睛的局部区域鲁棒?
回答:通过“池化(pooling)”(比如,取最大值)滤波器获得不同位置的响应,从而对确切的空间位置的特征获得鲁棒性。
Pooling Layer: Examples

问题10:Pooling层的输出尺寸?计算损失?
回答:输出的大小取决于池化层的幅度;
例如,如果池化层不重叠尺寸是K*K,
输入层:M个尺寸为D*D的map,
则输出层是:M@(D/K)x(D/K);计算复杂度与输入的尺寸成正比;(与卷积层相比可以忽略不计)
问题11:池化层的尺寸应该设置为多大?
回答:它取决于我们对想要的表述的”不变性”和鲁棒性畸变的容忍度;最好是慢慢的池化;
Pooling Layer: Interpretation
任务:检测方向;
卷积层:线性流形;
Pooling层:瓦解流形;
Pooling Layer: 感受野的尺寸
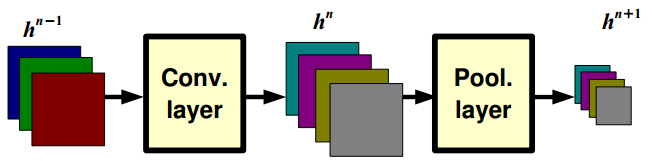
如果卷积滤波器的尺寸是K*K,幅度是1,pooling层的池化后尺寸是P*P, 则pooling层的每个单元输出取决于(前面卷积层的输入)尺寸,最终尺寸为:(P+K-1)x(P+K-1);
(5)局部对比度归一化:
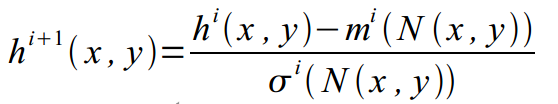
跨特征层,且在更高的层次执行;
作用:
- 改善不变性
- 改善优化
- 增加稀疏
(和卷积层相比,计算的成本可以忽略不计)
(6)ConvNets: Typical Stage
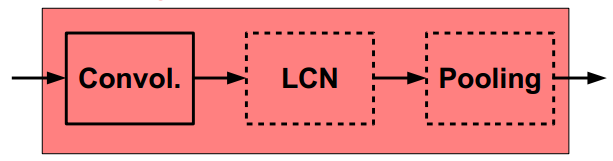
概念上类似与:SIFT、HoG等;
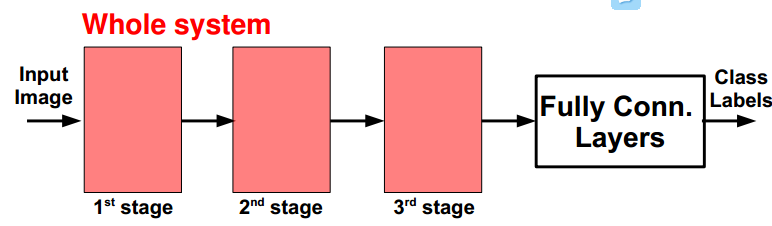
概念上类似与:
SIFT → K-Means → Pyramid Pooling → SVM
SIFT → Fisher Vect. → Pooling → SVM
(7)ConvNets: Training
所有的层都是可区分的,使用标准的BP算法;
(8)ConvNets: Test
在测试的时候,只进行前向传播;
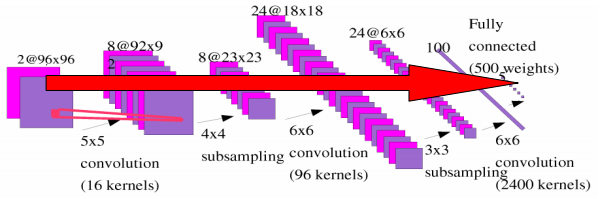
卷积网能够很低的损失处理大图片,传统的方法使用低效的滑动窗口。
对更大的图像进行解卷积,在多个局部区域产生输出;
二、CONV NETS: EXAMPLES
— 门牌号和交通标志分类;
Ciresan et al. “MCDNN for image classification” CVPR 2012
Wan et al. “Regularization of neural networks using dropconnect” ICML 2013
Jaderberg et al. “Synthetic data and ANN for natural scene text recognition” arXiv 2014
— 纹理分类
Sifre et al. “Rotation, scaling and deformation invariant scattering...” CVPR 2013
— 行人检测
Sermanet et al. “Pedestrian detection with unsupervised multi-stage..” CVPR 2013
— 场景解析
Farabet et al. “Learning hierarchical features for scene labeling” PAMI 2013
Pinheiro et al. “Recurrent CNN for scene parsing” arxiv 2013
Ciresan et al. “DNN segment neuronal membranes...” NIPS 2012
Turaga et al. “Maximin learning of image segmentation” NIPS 2009
— 基于视频的动作识别
Taylor et al. “Convolutional learning of spatio-temporal features” ECCV 2010
Karpathy et al. “Large-scale video classification with CNNs” CVPR 2014
Simonyan et al. “Two-stream CNNs for action recognition in videos” arXiv 2014
Sermanet et al. “Mapping and planning ...with long range perception” IROS 2008
Burger et al. “Can plain NNs compete with BM3D?” CVPR 2012
Hadsell et al. “Dimensionality reduction by learning an invariant mapping” CVPR 2006
Sermanet et al. “OverFeat: Integrated recognition, localization, ...” arxiv 2013
Szegedy et al. “DNN for object detection” NIPS 2013
Girshick et al. “Rich feature hierarchies for accurate object detection...” arxiv 2013
— 脸部验证与识别
Taigman et al. “DeepFace...” CVPR 2014
三、Optimization
随机梯度下降算法:
学习率=0.01
动量= 0.9
提高泛化性:
权值共享(卷积)
输入畸变
Dropout= 0.5
权值衰减=0.0005
Demo of classifier by Matt Zeiler & Rob Fergus:
Demo of classifier by Yangqing Jia & Trevor Darrell:
http://decafberkeleyvision.org/
Choosing The Architecture
1)依赖于任务
2)交叉验证
3)[卷积层→ LCN → pooling]* + 全连接层
4)数据越多:层数越多,卷积核越多(注意每层的参数、每层的浮点运算)
5)运算资源
6)富有创造性
How To Optimize
1)包含冲凉的SGD
2)通过运行数据的一个子集来选择学习速率 Bottou “Stochastic Gradient Tricks” Neural Networks 2012
——设定一个大的学习率,逐渐除以2,直到损失不发散;
——以1000倍的速度衰减学习率,直到训练结束;
3)使用非线性的激励函数
4)初始化参数,以便跨层的特征都有类似的差异,避免饱和单位。
Improving Generalization
1)权值共享(极大的减少参数的数量)
2)数据扩张 (比如注入抖动和噪音)
3)Dropout:Dropout是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),因为下次样本输入时它可能又得工作了
Hinton et al. “Improving Nns by preventing co-adaptation of feature detectors”arxiv 2012
4)权重衰减 (L2, L1)
5)稀疏的隐藏层的单元
6)多任务(为监督学习)
潜在的问题:容易陷入局部最小值;
所面临的挑战是关于:
1)泛化性
- 有多少训练样本,以适应1B参数?
- 多少参数/样品适应模型参数的维度为1M空间?
2)可扩展性
What If It Does Not Work?
1)训练发散
- 反向传播过程出现bug,数值梯度检查
2)参数崩溃/损耗最小,但精度低
- 检查损失函数→ 看其是否适应该问题? 它有退化的解决方案?
3)网络表现能力差
- 可视化隐藏单位/参数→修复最优化
4)网络运算太慢
- 检查浮点数运算和参数→如果太大,缩减网络;GPU;
四、Summary
监督学习:它是当今最成功的set。
ConvNets被用于各种各样的任务
Optimization
局部最小值问题很难解决,大部分项目中,局部最小值问题都不是最主要的优化问题;
Scaling
1)GPUs
2)分布式框架(Google)
3)更好的优化技术
Generalization on small datasets (维数灾难):
1)数据扩充
2)权重衰减
3)dropout
4)非监督学习
5)多任务学习















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









