






本博文下载链接:http://pan.baidu.com/s/1mhY7tu4
1. ORB的算法原理
ORB特征是将FAST特征点的检测方法与BRIEF特征描述子结合起来,并在它们原来的基础上做了改进与优化。它利用FAST特征点检测的方法来检测特征点,然后利用Harris角点的度量方法,从FAST特征点从挑选出Harris角点响应值最大的N个特征点。其中Harris角点的响应函数定义为:
1.1 旋转不变性
我们知道FAST特征点是没有尺度不变性的,所以我们可以通过构建高斯金字塔,然后在每一层金字塔图像上检测角点,来实现尺度不变性。那么,对于局部不变性,我们还差一个问题没有解决,就是FAST特征点不具有方向,ORB的论文中提出了一种利用灰度质心法来解决这个问题,灰度质心法假设角点的灰度与质心之间存在一个偏移,这个向量可以用于表示一个方向。对于任意一个特征点p来说,我们定义p的邻域像素的矩为:
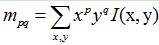
其中I(x,y)为点 (x,y)处的灰度值。那么我们可以得到图像的质心为:
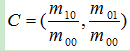
那么特征点与质心的夹角定义为FAST特征点的方向: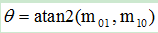
1.2 特征点的描述
ORB选择了BRIEF作为特征描述方法,但是我们知道BRIEF是没有旋转不变性的,所以我们需要给BRIEF加上旋转不变性,把这种方法称为“Steer BREIF”。对于任何一个特征点来说,它的BRIEF描述子是一个长度为n的二值码串,这个二值串是由特征点周围n个点对(2n个点)生成的,现在我们将这2n个点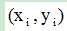
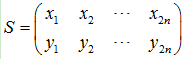
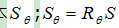
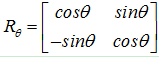
1.3 解决描述子的区分性
BRIEF令人惊喜的特性之一是:对于n维的二值串的每个比特征位,所有特征点在该位上的值都满足一个均值接近于0.5,而方差很大的高斯分布。方差越大,说明区分性越强,那么不同特征点的描述子就表现出来越大差异性,对匹配来说不容易误配。但是当我们把BRIEF沿着特征点的方向调整为SteeredBRIEF时,均值就漂移到一个更加分散式的模式。可以理解为有方向性的角点关键点对二值串则展现了一个更加均衡的表现。而且论文中提到经过PCA对各个特征向量进行分析,得知SteeredBRIEF的方差很小,判别性小,各个成分之间相关性较大。
为了减少SteeredBRIEF方差的亏损,并减少二进制码串之间的相关性,ORB使用了一种学习的方法来选择一个较小的点对集合。方法如下:
首先建立一个大约300k关键点的测试集,这些关键点来自于PASCAL2006集中的图像。
对于这300k个关键点中的每一个特征点,考虑它的31×31的邻域,我们将在这个邻域内找一些点对。不同于BRIEF中要先对这个Patch内的点做平滑,再用以Patch中心为原点的高斯分布选择点对的方法。ORB为了去除某些噪声点的干扰,选择了一个5×5大小的区域的平均灰度来代替原来一个单点的灰度,这里5×5区域内图像平均灰度的计算可以用积分图的方法。我们知道31×31的Patch里共有N=(31−5+1)×(31−5+1)个这种子窗口,那么我们要N个子窗口中选择2个子窗口的话,共有
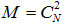

那么当300k个关键点全部进行上面的提取之后,我们就得到了一个 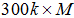
对该矩阵的每个列向量,也就是每个点对在300k个特征点上的测试结果,计算其均值。把所有的列向量按均值进行重新排序。排好后,组成了一个向量T,T的每一个元素都是一个列向量。
进行贪婪搜索:从T中把排在第一的那个列放到R中, T中就没有这个点对了测试结果了。然后把T中的排下一个的列与R中的所有元素比较,计算它们的相关性,如果相关超过了某一事先设定好的阈值,就扔了它,否则就把它放到R里面。重复上面的步骤,只到R中有256个列向量为止。如果把T全找完也没有找到256个,那么,可以把相关的阈值调高一些,再重试一遍。
这样,我们就得到了256个点对。上面这个过程我们称它为rBRIEF。
2. OpenCV中的ORB
ORB中有很多参数可以设置,在OpenCV中它可以通过ORB来创建一个ORB检测器。
ORB::ORB(int nfeatures=500, float scaleFactor=1.2f, int nlevels=8, int edgeThreshold=31, intfirstLevel=0, int WTA_K=2, int scoreType=ORB::HARRIS_SCORE, int patchSize=31)下面介绍一下各个参数的含义:
nfeatures -最多提取的特征点的数量;
scaleFactor -金字塔图像之间的尺度参数,类似于SIFT中的$k$;
nlevels –高斯金字塔的层数;
edgeThreshold –边缘阈值,这个值主要是根据后面的patchSize来定的,靠近边缘edgeThreshold以内的像素是不检测特征点的。
firstLevel -看过SIFT都知道,我们可以指定第一层的索引值,这里默认为0。
WET_K -用于产生BIREF描述子的 点对的个数,一般为2个,也可以设置为3个或4个,那么这时候描述子之间的距离计算就不能用汉明距离了,而是应该用一个变种。OpenCV中,如果设置WET_K= 2,则选用点对就只有2个点,匹配的时候距离参数选择NORM_HAMMING,如果WET_K设置为3或4,则BIREF描述子会选择3个或4个点,那么后面匹配的时候应该选择的距离参数为NORM_HAMMING2。
scoreType -用于对特征点进行排序的算法,你可以选择HARRIS_SCORE,也可以选择FAST_SCORE,但是它也只是比前者快一点点而已。
patchSize –用于计算BIREF描述子的特征点邻域大小。

















 4999
4999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









