






 本文详细探讨了大模型如transformer的微调策略,包括训练技巧如Lora微调、Prompt-tuning和Qlora量化,以及如何解决训练中的常见问题如遗忘、内存优化和模型落地的注意事项。文章还提到了不同场景下微调的需求和适用模型,如agent、知识库和闲聊任务的prompt选择。
本文详细探讨了大模型如transformer的微调策略,包括训练技巧如Lora微调、Prompt-tuning和Qlora量化,以及如何解决训练中的常见问题如遗忘、内存优化和模型落地的注意事项。文章还提到了不同场景下微调的需求和适用模型,如agent、知识库和闲聊任务的prompt选择。
一 大模型微调训练经验
NLP大模型微调答疑:https://mp.weixin.qq.com/s/J1r9N5PGQdXRM-aqhlFiJw
· 大模型训练的坑和解决思路
参考
https://zhuanlan.zhihu.com/p/657774871
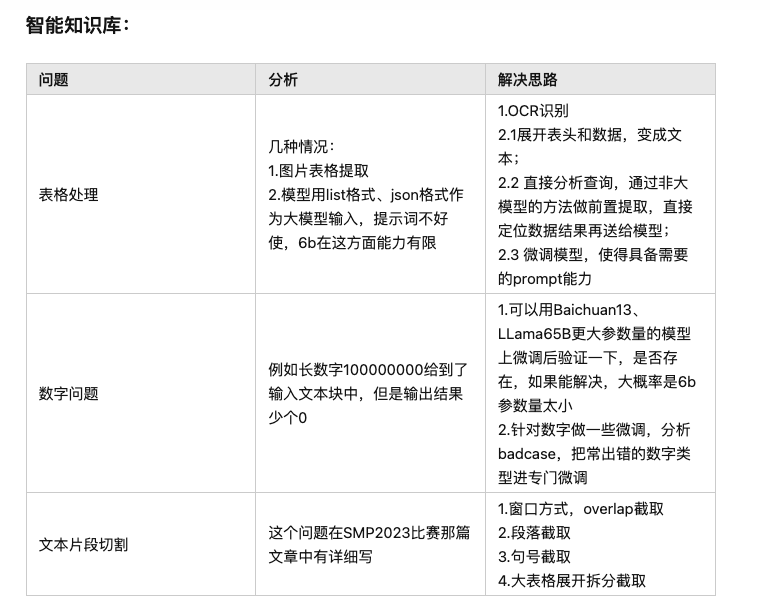
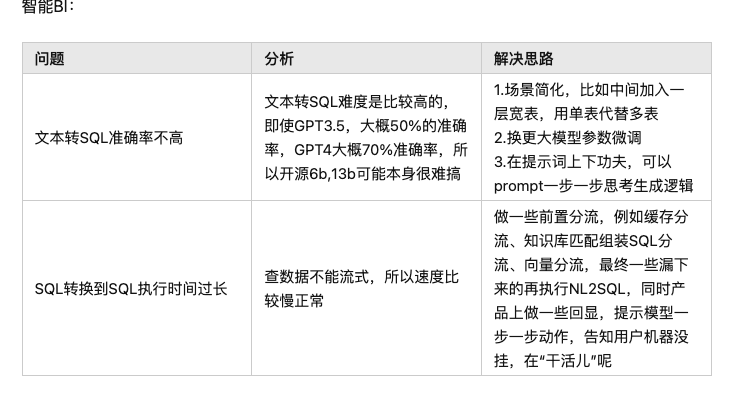
· 大模型微调训练经验
https://www.bilibili.com/video/BV13L411h7ZX/?spm_id_from=333.337.search-card.all.click&vd_source=c4e1d9d645f9a1554bc220274b5b24a8
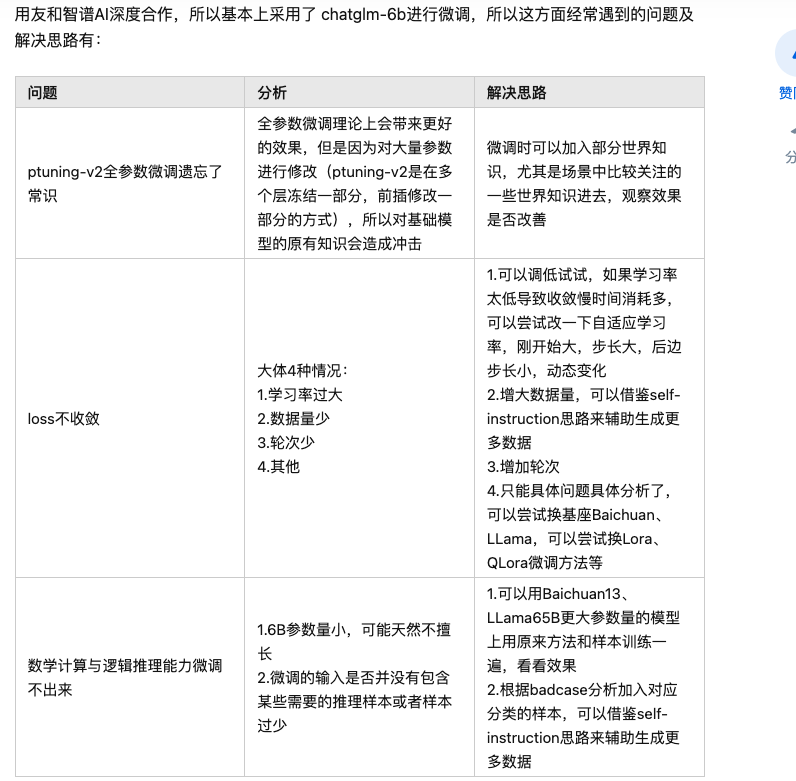
- 大模型结构都是transformer。区别只是训练方法和参数量上
- chatglm6b作为基座模型,8张A100的卡
- 微调用lora,原理简单,非常有起效。rank的大小要根据领域来,领域的垂直型越强,rank越要大 (为什么??)
- 业务领域的答案长短不一。如何训练超长文本?方法:对长文本先分段,对各段做摘要抽取。再用另一个大模型BART,对摘要做扩写,生成答案。
- 配知识库,对实时性要求高的问题回答
- 对用户的输入和模型的回答要做内容审核,内容审核是上线之前的重中之重。
· 大模型训练trick
https://zhuanlan.zhihu.com/p/648798461
- 领域标准技术文档比来自网页,新闻的数据更有价值。对于继续预训练大模型(Continue PreTrain)方面。
- 领域数据训练时候,再加点通用数据,比例1:5 ,1:10,来缓解通用数据的遗忘能力
- 预训练过程中,可以加下游SFT的数据,可以让模型在预训练过程中就学习到更多的知识
- 仅用SFT做领域模型时,资源有限就用在Chat模型基础上训练,资源充足就在Base模型上训练。
- 在Chat模型上进行SFT时,请一定遵循Chat模型原有的系统指令&数据输入格式。
- 领域模型词表扩增是不是有必要的
- 如果想快速的将领域大模型落地,最简单的是将系统中原有能力进行升级,即大模型在固定的某一个或某几个任务上的效果超过原有模型。
- 最终大模型的落地拼的不是模型效果本身,而是一整套行业解决方案,任务场景要比模型能力更重要。
· 大模型训练重点坑
https://mp.weixin.qq.com/s/Aa8jYs4xgcI4clwie-wO1g
(1)灾难性遗忘问题
chatglm3的pt微调中遇到问题:对原始问题遗忘严重,基本没法用。
解决办法:参考如下讨论 https://github.com/THUDM/ChatGLM-6B/issues/1148
修改lr,lr调大,看看效果。
(2)如何最小化利用内存,提升推理效率
· 大模型训练和微调需要多少容量
各个精读的含义 https://hub.baai.ac.cn/view/29387
一个可以估算模型所需多少内存的工具 https://huggingface.co/spaces/hf-accelerate/model-memory-usage
大致估算 https://zhuanlan.zhihu.com/p/643950399


· 大模型训练如何解决badcase
https://mp.weixin.qq.com/s/WzXflFyyX0uXo1fQv5vJ9g
1)预训练阶段的问题:难解决。模型升级
2)sft和对齐阶段的问题:使用强化数据,正例构造reward model的正样本,badcase构造负样本,使用ppo或者dpo等方法来让大模型记住正确数据
3)推断阶段阶段:生成参数调整; prompt层面调整:使用RAG方案,来给模型更多参考信息,让模型有外部知识储备。
4**)外部工具支持:使用cot,tool use等构建agent能力,来弥补大模型的局限性。**
5)前置后置干预。前置:检查用户输入的prompt,进行拒绝来避免不合规输入。 后置:对输出内容检测,不合规的整体替换。
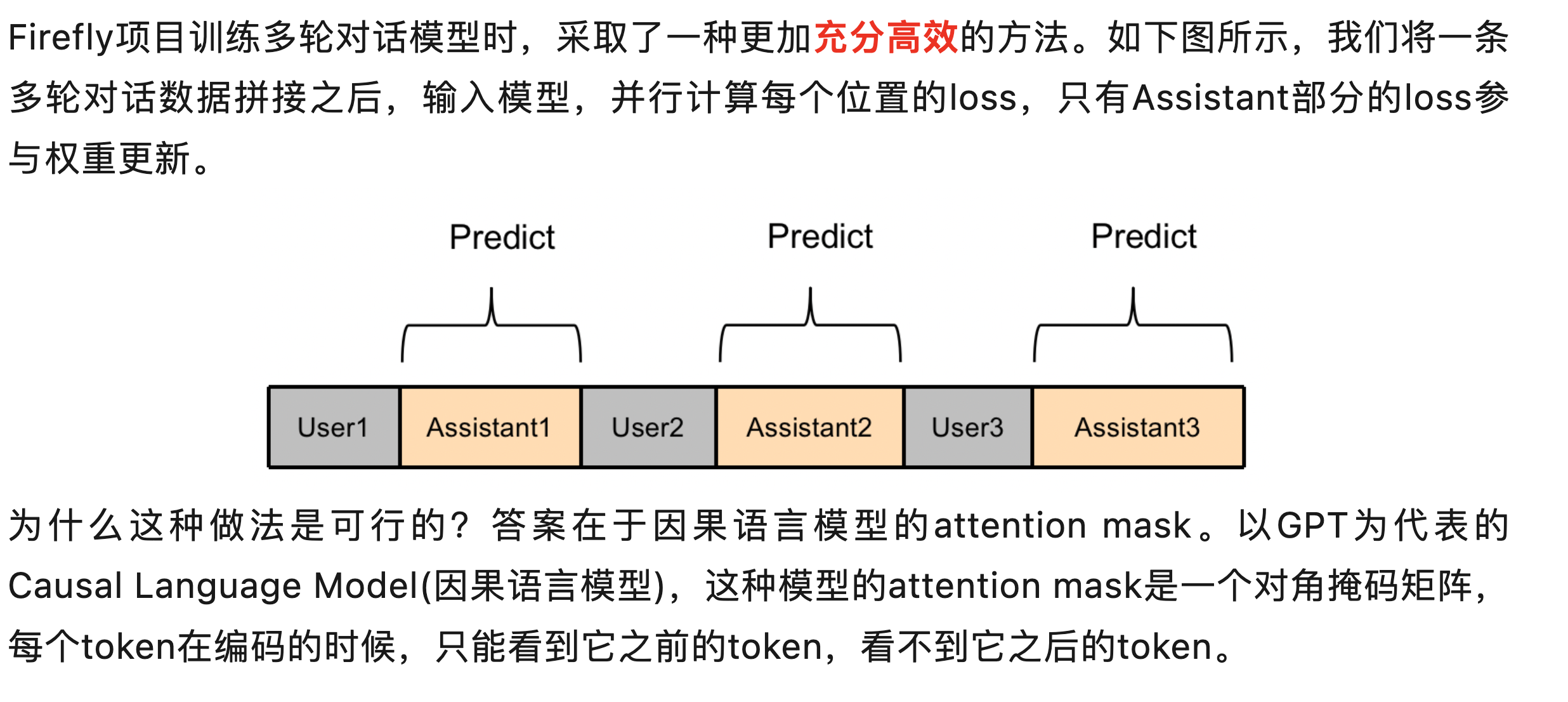
· 如何使用多轮数据微调模型
https://mp.weixin.qq.com/s?__biz=MzA3MTgwODE1Ng==&mid=2247484435&idx=1&sn=54317dddeacae305e51a902827f2b776&chksm=9f26a1e0a85128f69f4dae61d4c8afd942ac795e57c50acd45577204fd2a48193459f1a783d2&cur_album_id=3019347495656718337&scene=190#rd
二 各种微调方法解读
https://zhuanlan.zhihu.com/p/646748939
· prompt-tuning
Prompt-tuning 给每个任务定义了自己的 Prompt,拼接到数据上作为输入,同时 freeze 预训练模型进行训练,在没有加额外层的情况下,可以看到随着模型体积增大效果越来越好,最终追上了精调的效果.
· Freeze
即参数冻结,对原始模型部分参数进行冻结操作,仅训练部分参数,就可以对大模型进行训练
· Lora微调训练方法
全量微调训练存在的问题:
将预训练的大模型在下游任务上微调的时候,需要更新和预训练大模型一致的模型参数量,训练开销大。
解决方法:
Lora方法:极大地减少finetune时候的模型参数量
对于 GPT-3 175B 模型来说,可训练的模型参数可以是原始模型 0.01%
它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入到 Transformer 架构的每一层,极大地减少了下游任务的可训练参数的数量
lora原理:
额外引入了可训练的低秩分解矩阵,同时固定住预训练权重,在transformer的attention上使用lora
1.LoRA的思想很简单,在原始PLM旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank 。
2.训练的时候固定PLM的参数,只训练降维矩阵A与升维矩阵B。而模型的输入输出维度不变,输出时将BA与PLM的参数叠加。
3.加在qkv的部分。
lora微调的代码样例解读
lora源代码: https://github.com/huggingface/peft/blob/v0.4.0/src/peft/tuners/lora.py
参考资料:
https://zhuanlan.zhihu.com/p/635449788
https://zhuanlan.zhihu.com/p/644524136
B站: https://www.bilibili.com/video/BV15T411477N/?spm_id_from=333.788.recommend_more_video.4&vd_source=c4e1d9d645f9a1554bc220274b5b24a8
代码:https://github.com/chunhuizhang/personal_chatgpt/blob/main/tutorials/02_lora_baics.ipynb

· Qlora微调方法
将模型采用4bit量化加载,训练时再反量化到bt16后进行训练。
QLORA 可以使用 4 位基础模型和低秩适配器 (LoRA) 复制 16 位完全微调性能,可以实现单卡gpu上微调大模型
1.双量化:第一次量化后的那些常量再进行一次量化,减少存储空间。相比于当前的模型量化方法,更加节省显存空间。
2.在GPU偶尔OOM的情况下,进行CPU和GPU之间自动分页到分页的传输,以实现无错误的 GPU 处理
3.插入更多的apapter,来减少精读损失。每层全连接处都插入adapter
4.包含一种低精度存储数据类型(通常为4-bit)和一种计算数据类型(通常为BFloat16)。用4bit加载模型,再反量化到16bf后进行计算
4-bit数据类型,优于普遍的float4和int4
· ptuning
该方法将prompt转换为可以学习的embedding层。并用MLP+LSTM的方式来处理这一层
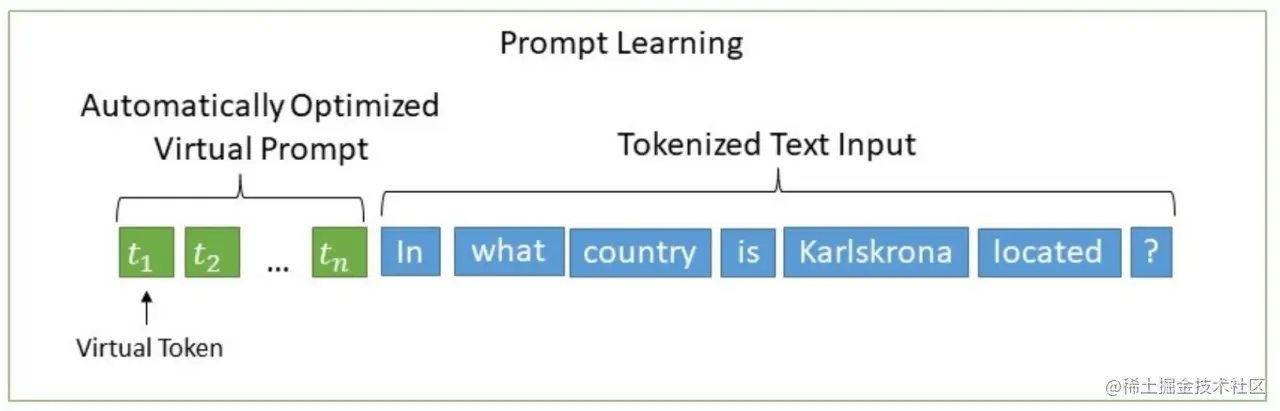
· ptuning-v2训练方法
代码:chatglm3/ChatGLM3/finetune_chatmodel_demo/finetune.py中实现的就是pt-v2的微调方法
原理:
https://zhuanlan.zhihu.com/p/422713214
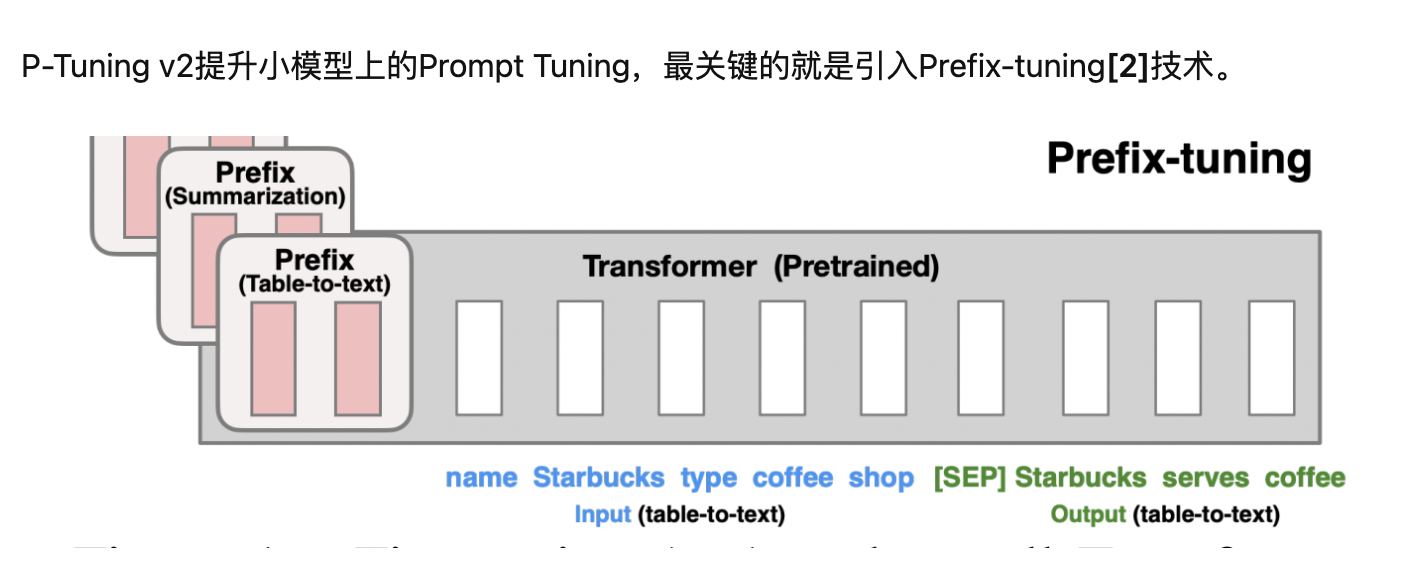
Prefix-tuning(前缀微调)最开始应用在NLG任务上,由[Prefix, x, y]三部分构成,如上图所示:Prefix为前缀,x为输入,y为输出。Prefix-tuning将预训练参数固定,Prefix参数进行微调:不仅只在embedding上进行微调,也在TransFormer上的embedding输入每一层进行微调。
前缀微调将一个连续的特定于任务的向量序列添加到输入,称之为前缀,
P-tuning v2在实际上就是Prefix-tuning,在Prefix部分,每一层transformer的embedding输入都带上prompt token。而P-tuning v1只有transformer第一层的embedding输入带上prompt。
优点:1.更多可学习的参数。 2.prompt加入到更深层的结构中,给模型的预测能带来直接影响。
三 各个模型单多卡微调命令集合
参考 https://www.doumiao.net/blog/245756
四 大模型落地坑
https://www.bilibili.com/video/BV1zk4y1g7Bi/?spm_id_from=333.337.search-card.all.click&vd_source=c4e1d9d645f9a1554bc220274b5b24a8
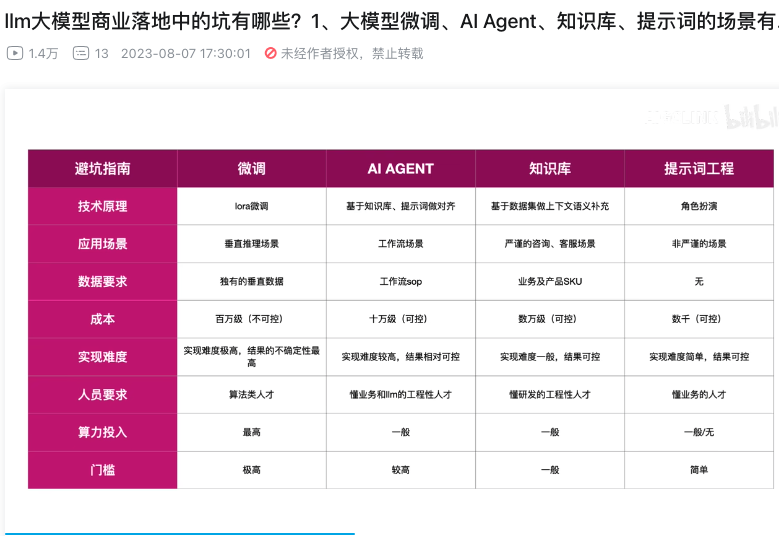
微调:为了垂直推理场景,比如医疗问答。需要有推理能力。没有百万数据不要考虑微调,调不出来。
agent:工作流需求,比如销售工具,研究工具。需要十万级数据。
知识库:严谨的场景。数万条数据。
prompt:不太严谨的场景,比如闲聊。
https://www.bilibili.com/video/BV1cu4y1k7Pg/?spm_id_from=333.788.recommend_more_video.7&vd_source=c4e1d9d645f9a1554bc220274b5b24a8

















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









