






多意图算法及专利调研整理

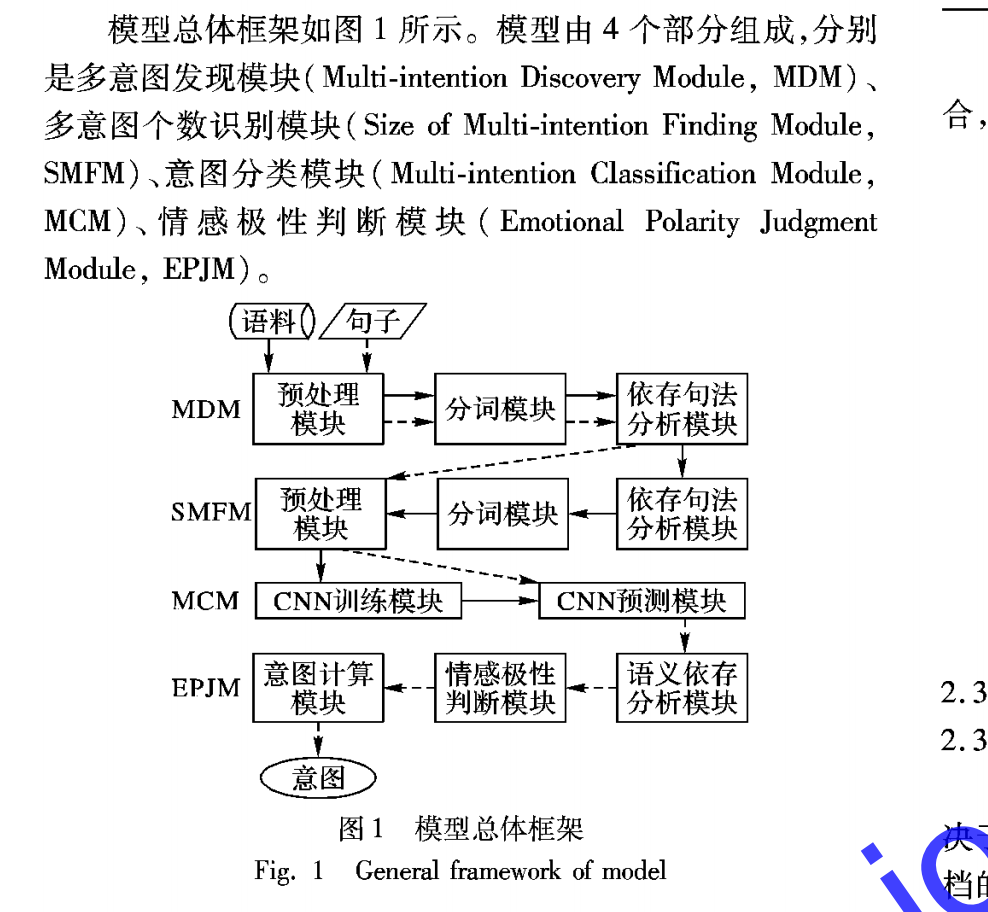
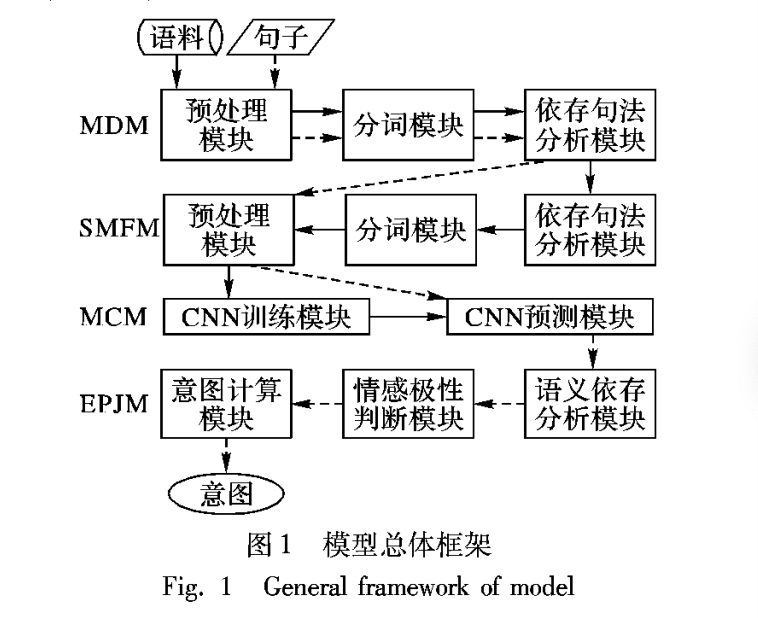
多意图语义解析包括多意图发现MID(Multi-intent discovery)模块、多意图识别MIR(Multi-intent recognition)模块,情感极性判断EPJ(Emotion polarity judgment)模块。
MID模块主要利用依存句法分析抽取句子的句法特征,根据句法特征中是否包含COO并列关系和VOB动宾关系来判定句子是否包含多意图;利用语义依存分析eSUCC顺承关系判断句子是否包含多意图。通过以上2种方法可以显示的初步判断句子中多意图的个数。
MIR模块通过like-BERT模型序列标注任务识别句子中多意图个数。
步骤:1.使用依存句法分析抽取句子中是否有并列关系和动宾关系来判断是否是多意图 2.使用bert序列标签来识别意图个数
多意图识别模型可以采用3种实现方式:
- 一是序列标注方式,标注子句;
- 二是采用多标签分类的方式;
- 三是单意图的组合枚举,转化为多分类模型
多意图&断句 专利调研综述
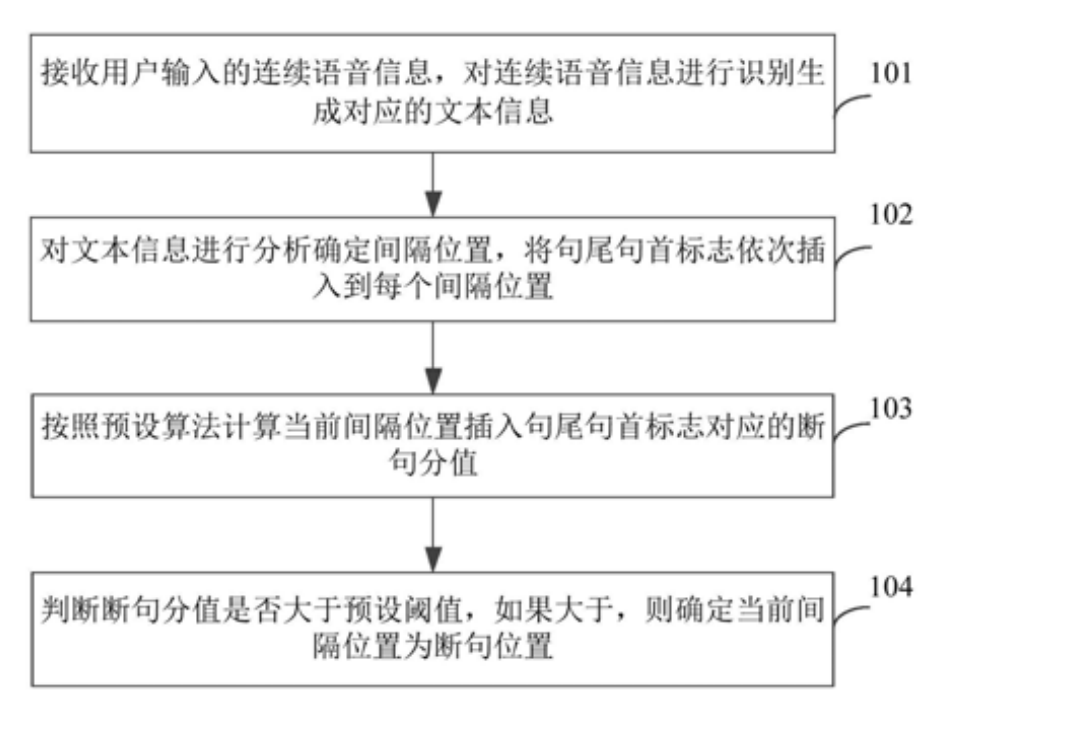
先对句子分词,然后提前预设好的一个关键词库,比如“我想要一个降落伞”,一个、降落伞,在关键词库内(为啥??),这个关键词是来自大量语料统计的,符合用户连续发音习惯的词。然后在关键词后面加断句符号。 其次,根据上下文信息,和词间停顿信息(来自asr吗,此处没有细说),来计算刚才所加的断句符号的概率,分别将上下文信息,包括phrase的长度,前后词的词性,都各自加不同的权重,比如前后都是形容词的,就认为可能是顿号分开的分句,权重高一点。如此,计算出每个预加断句的得分,设一直阈值,如果高于阈值,就确认此处有断句。
-
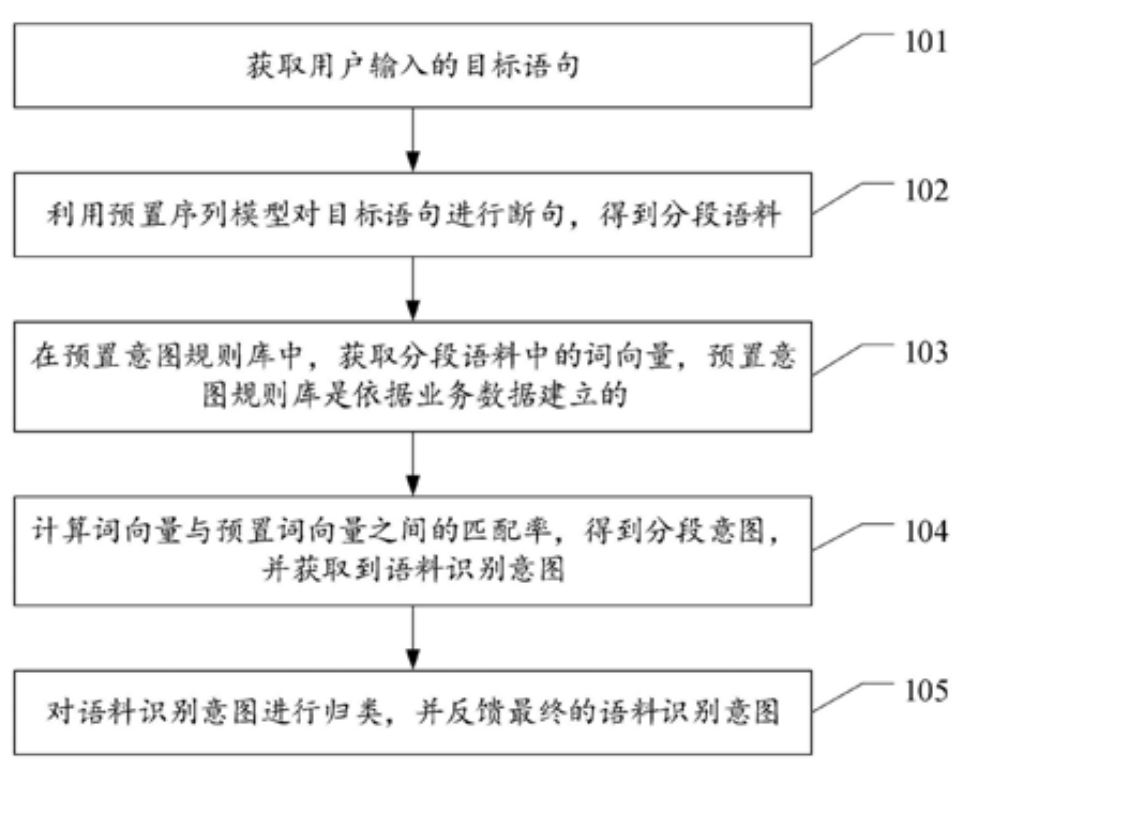
专利[2]中介绍方案:
首先,根据一个序列标签模型,对长句预分段,分为多段语料。
其次,事先定义了一个意图和语句对应多意图-断句 专利调研综述的库。此处句子用词向量表示。类似意图语料的标注,该意图下所属的句子有哪些,这样的一个数据库
再次,计算分段语料和预制意图库内词向量的匹配度,就是识别分段语料属于哪个意图,可以用分类,此处用了文本匹配。
最后,对分段语料的意图做整理,如果前后是互斥关系(我不去天安门要去西单 这种),取转折后的意图作为句子意图。
其中,分段语料提取和分段语料的意图拆分,还有详细说明,没看懂。
-
论文[3]中介绍方案:
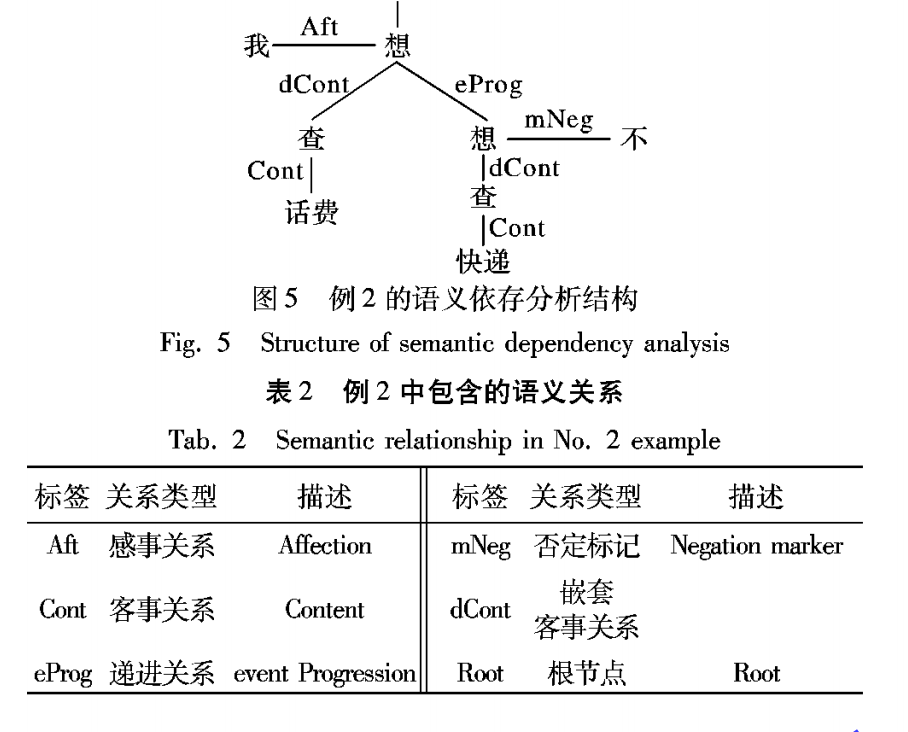
首先,对输入句子经过分词后,做依存句法分析,来判定句子内是否存在COO(并列)关系。如果存在,则判定该句为多意图。
其次,做一个cnn的改进,对输入,转换为,单词和每个类别之间的距离的一个矩阵,也就是用textCNN来依次识别是否属于该意图。可是两个意图的间隔怎么区分没写。
最后,提到了情感极性的判断。类似互斥语句,前面肯定后面否定,则取肯定的意图。依然使用依存句法分析。

-
专利[4]中介绍方案
主要阐述了多意图执行方面的方案。
首先,可以采用多分类,对多意图句式中所有slot都标记出。比如“打开空调调高音量放一首歌”,按顺序把所有slot都标记出。
其次,根据每个slot定义对应的action,可对应的path。然后判断该条指令是否能执行,单独来分析是否需要再确认,或者补全。
同时,要判断前后指令是否存在冲突。“听广播听音乐”,就是冲突,需要反馈,只能选一个。
以及,判断前后指令的顺序,按顺序执行。
-
专利5
就是bilstm+crf,序列标签,来对句子标记断句位置。基于字序列。有一点改进点是,考虑到英文情况,如果当前字符后面是断句位置,判断下一个字符是否是英文单词,如果是,不要分开,因为英文自带空格。如果不是,就是一个分句节点。
-
专利6
类似tts的停顿预测,先根据分词,词的词性,词的句法特征,来训练一个crf模型来表示句子的停顿位置,再用该模型初级标注句子的断句位置,得到各个分句。用标准的人工的断句,训练一个ngram,再用该ngram对每个分割后的断句计算得分,高于阈值的,认为断句正确。保留断句标记。
-
专利7和专利8
就是一个常规的双向lstm来实现,预测句子内部标点符号的序列标注模型,以此来断句。
-
专利9
弱化了断句模型的介绍,提出首先用断句模型,输出多个断句候选结果。然后计算断句位置附近的字,和断句的共现概率。类似逆文档频率,统计大量文章中,如果该字后面常见断句标记,就该字断句的共现概率就高。如此来确定最佳断句结果。
-
专利10
方法依然是序列标签来标记断句位置,然后是动态的,用一个滑动窗,边asr识别边切分句子,对每次窗口内切分后标记出的断句,用ngram语言模型判定句子合理度,合理的在判断是否该断句曾经注册过,没注册过才保留作为一个断句。
-
专利11
序列标签(lstm or 双向rnn),来标记断句位置,同时用到了声学特征,将语音和文本对齐,获取每个断句位置的声学特征,包括停顿时长,词间停顿时长、词尾基频走势、词内音素平均时长,说话人历史平均语速等。两者结合来判定正确的断句位置
-
专利12
提出lstm+crf来标记出断句位置后,劈分出分句,创新点在于,对分句,如果句子不完整,用一个语义改写模型来补充完整,比如:打开空调和音乐,经过分句+语句改写,变成 打开空调/打开音乐。亮点为,对于组合句式,不需要标注组合语料,直接用单意图语料合并作为多意图语料。
-
专利13
对输入的问题做切分,然后每个切分的子句,用对应的答案技能来回答。如果两个答案最终互斥,就计算分句和答案的相似度,取相似度最高的作为回答。如果不互斥,就把两个答案组合起来当做回答。感觉是LG的内容
-
专利14
首先,先根据分词规则和分词词典对输入句子分词,得到多个词语。词语和意图库中意图做予以匹配,得到多个意图。此处意图库是每个意图的提取指令,和对应的词,命名体识别等。
-
专利15
首先把句子输入一个单意图模型,得到句子的主意图。再把句子得到句向量,预先准备的一个意图库,其中有每个意图的向量。计算句子向量和每个意图向量的距离,马氏距离,距离最近的,作为子意图。如此得到多意图。
-
专利16
首先使用textcnn,对句子分类得到一个主意图。同时事先总结整理,都有哪些话术会同时出现在一个句子中,呈现多意图的指令,这些话术中总结出正则表达式或者关键词,比如“预定”+“打招呼”是很常见的多意图。然后设定每个意图的优先级,预定的优先级高于打招呼。如果输入句的主意图识别为预定,则用输入句子和预定+{},所有设定意好的意图组合,挨个计算匹配度,计算句子格式的匹配度,或者关键词的匹配度。匹配度高的,意图组合,就作为目标句子的多意图。相当于用单意图粗排,再用多意图挨个计算关键词和正则格式的匹配度来精排。
-
专利17
S1:获取待识别文本并进行去重和删除停用词,得到训练语料;
S2:获取句向量; 此处使用bert-as-service得到。
S3:利用lightgbm模型训练用于识别意图的的句向量模型,得到意图类别,输出所有的主意图;主意图可能有多个。
S4:选取标准向量;分别计算同一主意图的所有文本在该类意图文本中出现的频率,以出现频率最高的文本的句向量为该类文本的标准向量。也就是,对数据标注中,一个意图下面的所有句子,哪个句子出现的频率高,就把该句子作为该意图的标准句。
S5:计算标准向量的马氏距离,输出子类别意图。计算s2得到的句向量,和每个主意图的标准句计算马氏距离,topk作为子意图。主意图+子意图,作为多意图。 -
专利18
S1获取用户输入的语料;
S2对所述语料进行分词,得到所述语料中的主体词语;
S3匹配所述主体词语对应的意图;
S4当所述主体词语匹配到多个平行关系的意图时,计算每个所述意图在所述主体词语对应的预设排序维度上的相关度;
S5根据各所述意图在所述主体词语对应的预设排序维度上的相关度,识别出目标意图。 -
专利19
事先准备一些句子对,句子对数据的形式为(目标句,代表句,0/1),目标句是意图类别中的句子,代表句包括三种:意图类别、意图类别名;人为定义的典型例句(我想寄快递);从意图标注数据中随机抽取的一部分句子。
对每一个意图类别设置一组代表句,然后对输入句子,和每个意图的代表句计算相似度,如果得分高,就认为包含该意图。
数据转化模块,配置为将原始的意图标注数据转化为句子对数据,其中,所述句子对数据中至少包含所述原始的意图标注数据中的目标句、所述意图标注数据所包含的意图类别的代表句组成的句子对以及所述目标句和所述代表句的相似度;
句向量编码模块,配置为句向量编码器对所述目标句和所述代表句进行编码,形成与所述目标句对应的目标句向量和与所述代表句对应的代表句向量;
相似判断训练模块,将所述目标句向量和所述代表句向量进行向量拼接后,输入分类器以判断所述句子对是否相似,对所述句向量编码器和所述分类器的训练。对每一个意图类别设置一组代表句,通过计算用户说的句子与代表句的相似性来决定用户是否表达了该类意图,比如对于“我要寄快递,但是我想先查下寄件费用”,将其与寄快递类别中的代表句“我想寄快递”和查询寄件费用中的代表句“查询寄件价格”计算相似性,如果相似性较高则说明包含了寄快递和查询寄件费的意图,同理与其他类别中的代表句计算相似度,如果相似性较低则说明不包含其他意图。假设一共有k类意图,每一个类别的代表句数量为b,上述做法可以将一条标注文本,转换为约kb条句子对样本,增加了大量的标注样本,也充分利用了数据集中文本之间的关系信息。
参考
[1]文本断句位置识别方法和装置.pdf -百度*
*[2]基于断句的多意图识别方法、装置、设备及存储介质.pdf--平安*
*[3]结合句法特征和卷积神经网络的多意图识别模型.pdf*
*[4]钛学术专利意图识别和执行的方法、设备、车载语音对话系统以及计算机存储介质.pdf*
*[5]文本断句位置的识别方法及系统、电子设备及存储介质在审发明-携程*
*[6]断句模型训练方法、断句方法、装置及计算机设备-小爱科技*
*[7]基于双向长短时记忆网络的中文文本自动断句与标点生成模型构建方法及系统*
*[8]一种断句方法及装置*
*[9]文本断句方法、装置、电子设备和存储介质在审发明*
*10 流式自然语言信息的断句装置及方法*
*11 文本断句方法及系统*
*12 用户多意图的识别方法及装置,存储介质及车辆*
*13 一种基于多意图的多技能包问答方法、系统和机器人*
14 *多意图查询方法和装置*、计算机设备及计算机可读存储介质
15 一种中文文本多意图识别方法及系统
16 语句多意图识别方法、系统、电子设备及存储介质-携程
17 一种多意图的识别方法及装置、终端设备
18 基于历史结果的多意图查询方法、装置、设备及存储介质在审发明
19 多意图识别训练和使用方法及装置-思必驰


















 8434
8434

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









