







参考资料
论文:
Large-Scale Video Classification with Convolutional Neural Networks
博客:
Large-scale VideoClassification with CNN(CVPR2014)
第1章 引言
这是一篇来自CVPR2014年的关于视频分类的论文,由李飞飞组创造,应该算是深度学习开始挑战 视频领域 的宣战书。众所周知,2012年,AlexNet拿下ImageNet图像分类的冠军,之后几年的时间里,冠军都是各种CNN的改进变形。随后的几年中,各路大神开始思考既然CNN这玩意在图像分类领域这么厉害,是不是也可以在图像的其它任务中尝试一下呢?于是CNN进入了图像语义分割,于是有了FCN,进入目标检测,于是有了RCNN。
视频是一连串的帧画面,相比静态图像,多了一维时序信息。在过去的方法中,首先会密集地或稀疏地提取用来描述视频部分区域的局部特征子,随后将这些特征聚合后送进机器学习分类模型进行分类。CNN已经被证明能够学习强大的和可解释的图像特征,是不是也可以使用CNN来做呢?
视频毕竟是具有时序信息的连续画面,网络不仅可以访问单个静态图像中的外观信息,还可以访问它们复杂的时间演化。在这种情况下,扩展和应用CNN有以下几个挑战:
- (1)缺少具有标注信息的大规模的多样性视频:图像领域有ImageNet,数量众多、类别众多,而视频领域数据集少。
答:提出了一个新的数据集:
Sports-1M数据集,其中包括100万个YouTube视频,属于487个体育类的分类。
- (2)视频存在时序信息,怎么连接并利用这些时间信息?
通过评估多个CNN体系结构来检验这些问题,每个体系结构都采用不同的方法来融合跨时间域的信息,也就是下面的几种帧融合策略。
- (3)CNN需要长时间的训练才能有效地优化数以百万计的参数化模型。当处理对象是videos时,运算量更大,因为网络一次必须处理多帧视频,而不仅仅是一个图像。
诚然,视频每秒钟包含24帧画面,要处理的数据量更大。修改CNN的架构,使其包含两个独立的处理流:一个上下文流(它学习低分辨率帧上的特性)和一个高分辨率中心流(它只在帧的中间部分操作)。我们观察到,由于输入的维数减少,网络的运行时性能提高了2-4倍,同时保持了分类的准确性。
- (4)在SPORTS-1M数据集上学习的特性是否足够通用,可以泛化到不同的、较小的数据集?
通过将在SPORTS-1M提取到的特征迁移到UCF101上,可以验证模型能够扩展到UCF101数据集上,且显著提升了精确率。
文章主要有以下3个贡献点:
- 采用多种方法扩展CNN到视频识别,并用
Sports-1M数据集进行验证和测试。 - 提出了将输入处理为低分辨率流和高分辨率流的方法,在不影响精确度的前提下显著减少了CNN的训练时间。
- 验证模型能够扩展到
UCF101数据集上,且显著提升了精确率。
第2章 网络结构
2.1 时间信息融合模型
将CNN扩展到视频分类的多种方法,并在sports-1M上进行了广泛的实验性评估,总结了使用卷积神经网络提取时序语义的几种模式:Single Fusion,Late Fusion,Early Fusion,Slow Fusion。

红色、绿色和蓝色框分别表示卷积层、归一化层和池化层。在慢融合模型中,所示列共享参数。
(1)单帧模型(Single-frame):用于得到静态图像对视频分类的贡献。说白了,就是随机的从视频中任意选取一帧,将视频分类转换成图像分类。将这种做法作为baseline方法,效果还可以,因为某些行为是可以通过单帧画面就能判断出来的,但是有些行为就不可以,所以这种方法总的来说不靠谱,学术一点的说法,就是不够健壮。
CNN结构:C(96,11,3)-N-P-C(256,5,1)-N-P-C(384,3,1)-C(384,3,1)-C(256,3,1)-P-FC(4096)-FC(4096)。C(d,f,s)中d代表卷积核个数,f代表卷积核大小f X f,s代表步长。N代表normalization layers,P代表池化层,参数均为2 X 2,分类器为softmax。整个流程就是单帧画面的前向卷积识别操作。
(2)早期融合(Early Fusion):使用连续的 T 帧进行预测, 在第一个卷积层前就将其融合(也是因为在卷积之前进行融合,所以称为early fusion),第一个卷积层上的滤波器扩展为11×11×3×T像素来实现的,T是融合的帧数,在较高分辨率的位置进行融合,卷积层可以更清晰地看到动作的方向和速率,但语义信息较弱。
(3)晚期融合(Late Fusion):使用同一视频前后相隔 15 帧的两帧过同一卷积神经网络,在最后的全连接分类网络前进行融合,因为在卷积之后,全连接之前,所以称为late fusion。也就是说,前面的卷积部分不进行时序求解, 只有最后的全连接层能接收到时序信息,即通过比较两帧的输出来计算整体运动特性。
(4)慢融合(Slow Fusion):慢融合模型是两种方法之间的一种平衡混合,这两种方法在整个网络中缓慢融合时间信息,从而使更高的层能够在空间和时间维度中逐步获得更多的全局信息。依旧使用连续的 10 帧,将 [0, 10) 帧以 4 为长度,2 为步长,分为 [0, 4),[2, 6),[4, 8),[6, 10) 四段分别进行前融合式卷积。之后在将这四部分局部时序语义分为前后两组进行同样的前融合式卷积,最后将这两组再进行融合。总体而言该过程将感受野从 4 帧提至 8 帧最后提至 10 帧。明显可以看出来这个思路就很深度学习。
其实就是利用3D卷积滑动实现感受野的提升,和2D卷积在图像上滑动一样,随着网络加深,感受野也在逐步提升。
2.2 多分辨率视频理解网络
提出了一种由人类视网膜启发的视频理解网络:
- (1)使用两种不同的分辨率的帧分别作为输入,输入到两个CNN中,在最后的两个全连接层将两个CNN统一起来;
- (2)两个流分别是低分辨率的内容流和采用每一个帧中间部分的高分辨率流;
- (3)该网络基于上文的任一时序融合模型,以178×178分辨率帧为原始数据;

其中一支接收178×178分辨率 全尺寸下采样 缩放为89×89(即缩放为之前的四分之一) 的帧,即上下文网络 (余光网络)。另一支接收178×178分辨率 中央裁剪 为89×89的帧 (即不进行缩放变换),即中央凹网络。由于接接收的都是分辨率为89×89的帧,作者去掉了最后一个池化层以维持最终7×7×256的特征维度。进入全连接分类层前将两支在通道维度上进行连接,以聚合不同分辨率的信息。
这种设计利用了许多在线视频中存在的相机偏差,因为感兴趣的对象通常占据中心区域。
第3章 实验结果
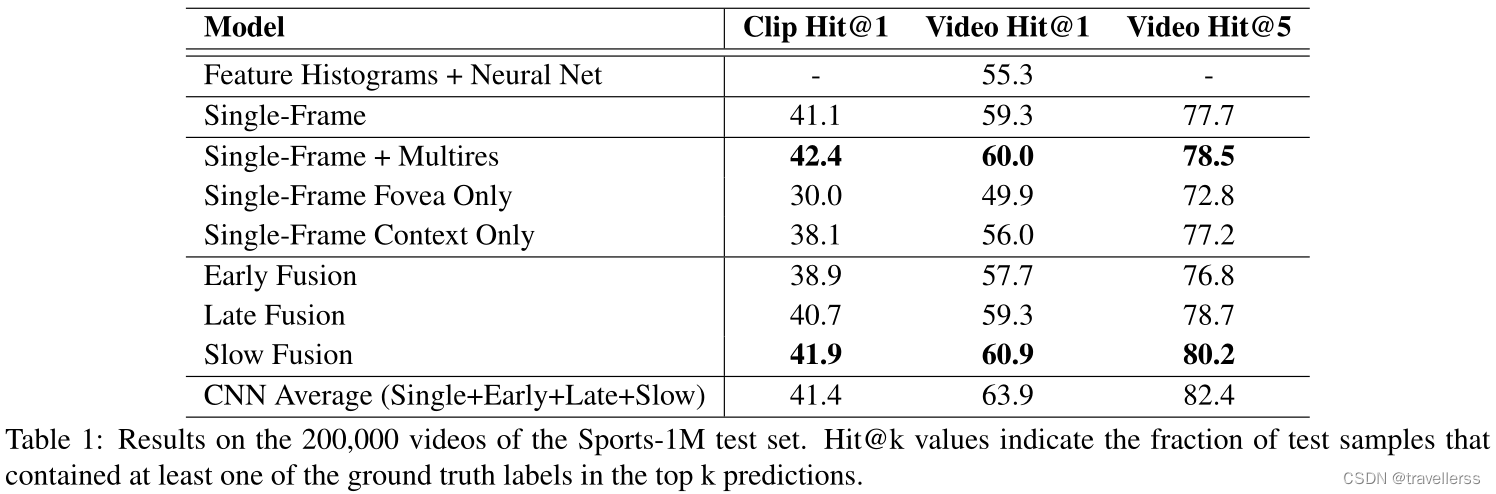
评判标准是按准确率,因为实验中数据集中的视频都是单标签的,相当于单标签的图像分类,如果是activityNet这种多标签的,则需要使用map评价策略,相当于多标签的图像分类。top-N正确率是指识别算法给出前N个答案中有一个是正确的概率。我们最好的时空网络跟基于特征的方法比较来看,表现出了很好的性能(55.3%VS63.9%),但是相比于单帧模型,只有一点点的提升(59.3%VS60.9%)。
第4章 总结
1、Slow Fusion的效果显然超过其它的方法,原因是它融合了更多帧,保留了更多了时空特征,实际上是变相使用了3D卷积的方法,证明了3D卷积的有效性,可以更好的提取时空特征。
2、多分辨率网络的思路(使用不同分辨率作为输入的方法)是不是可以用来做图像分类呢?
3、这种通过叠加多个帧画面来获取时间信息的方式并不成功,所以没必要看代码,知道在视频理解早起有过这么一个方法就好,在以后的处理方法中思考是不是有些东西值得借鉴。

















 2619
2619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











