









逻辑回归(Logistic regression)
我们现在只考虑二分类,即
y∈{0,1}
。
类似于线性回归问题,我们同样定义一个估计(hypothesis)函数
hθ(x)
。显然我们的输出值要限定在
{0,1}
之间会更加有利。因此选择模型:
我们称上式为 logistic function或 sigmoid function.
下面给出 g(z)的曲线:
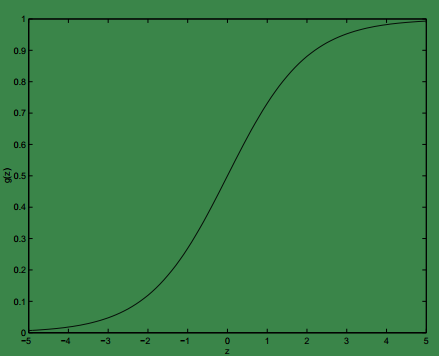
显然,当z→∞时,g(z)→1;当z→−∞时,g(z)→0 。
和之前一样,我们令 x0=1,这样我们类似的就得到θTx=θ0+∑nj=1θjxj 。
下面让我们来看看怎样得到
θ
:
假设: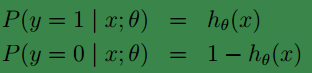
上式可以合并为一个式子:
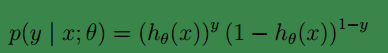
类似于我的这一篇博客中求最大似然值一样,我们可得:
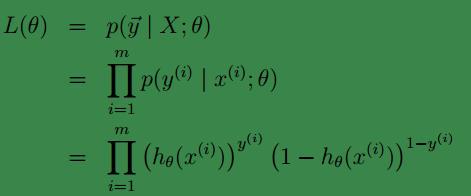
进而得到log likehood:
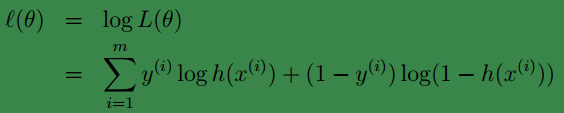
然后还是一如既往的求导:
在求
ℓ(θ)
关于
θ
的导数前,我们先来看看
g(z)
的导数,因为在对
ℓ(θ)
求导时会用到。
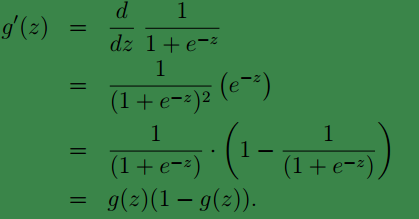
下面开始对
ℓ(θ)
求导:
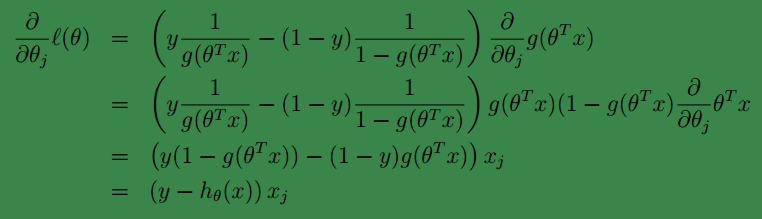
还记得梯度下降吗,不记得点这里,当时我们是为了求最小值。比较一下呢,现在我们是要求最大值,所以我们可以用梯度上升法求
θ
:
可以看到,与线性回归类似,不同之处只是 θTx(i)在这里变成了hθ(x(i)),事实上hθ(x(i))就是由θTx(i)经过函数g(z)映射后得到的。
扩展到整个样本集就是:
感知学习算法(perceptron learning algorithm)
这里我们改写Logistic regression中的映射函数
g(z)
:
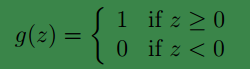
经过与逻辑回归中同样的推导后我们会得到类似的结果:
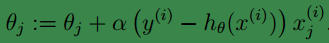
这就是感知学习算法。。。
它只输出0或1
牛顿迭代法
在逻辑回归中我们求最大似然值 ℓ(θ) 时,是使用的梯度上升法。牛顿迭代法是另一种求最值的方法,这里让我们来看看怎样用牛顿迭代法求最大似然值 ℓ(θ) 。
首先什么是牛顿迭代法?
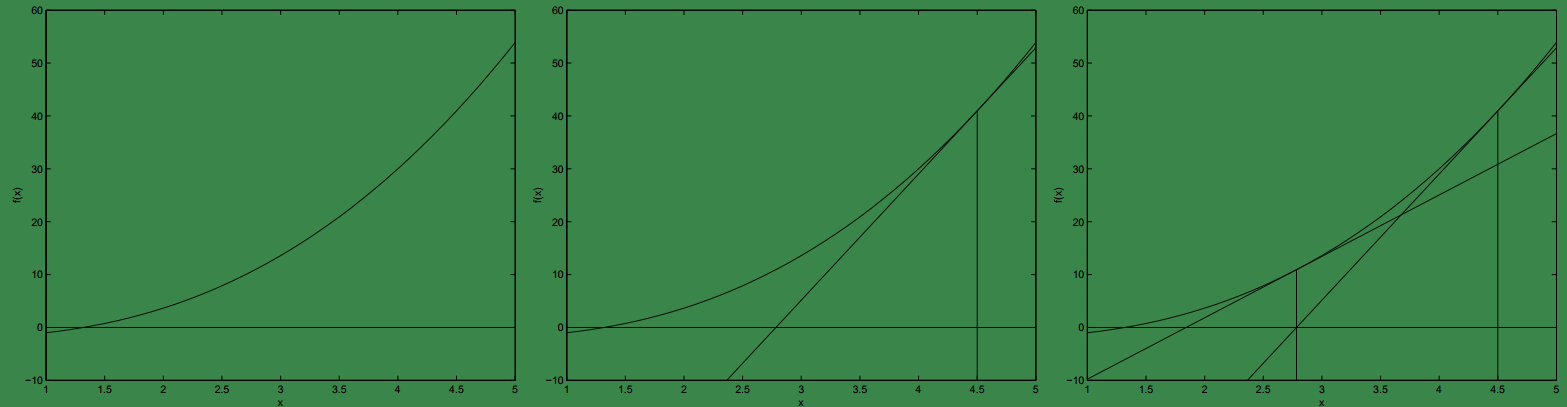
假如我们有一个函数f(θ),其曲线如下,我们希望获得使得f(θ)=0的θ的值,此时便可以用牛顿迭代法求解:
牛顿迭代法公式:
我们将公式和图形结合来看:首先在中间那幅图中我们给 θ一个初始值4.5,此时f′(4.5)与f(θ)=0大概相交在θ=2.8,而f′(θ) 的值等于两个直角边长的比值,所以 f′(4.5)=f(4.5)4.5−2.8,因此f(4.5)f′(4.5)=4.5−2.8.
其本质就是通过迭代,使得 θ 不断的接近目标值。
牛顿迭代求最大似然值
上面是用牛顿迭代来求零点处的值,怎样用牛顿迭代来求最大值呢。很简单,我们只要求
ℓ′(θ)=0
处的
θ值即可
,因此牛顿迭代法要写成下面的形式:
当然实际应用中,θ不可能是个常量,而应是个向量,故写成下面的形式:
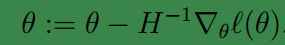
其中H称为 Hessian矩阵,就是2阶偏导数构成的矩阵,它是一个 n×n 的矩阵(在实际应用中加上偏置项,其实会是一个 (n+1)×(n+1) 的矩阵)。
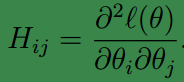
牛顿迭代法相对于梯度上升法的优点是,只需较少的迭代次数便可完成计算
缺点是,每次迭代都需要计算Hessian矩阵,若属性过多,计算代价会很大。















 964
964

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









