







1. 问题描述
在二维平面上,给定若干个点,求一条直线能够很好的拟合这些点。如图所示。
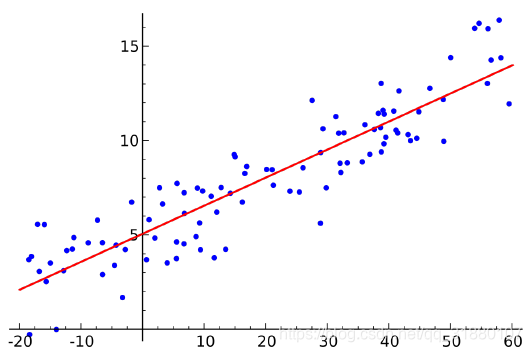
为什么这个问题很重要?
- 这是一个非常重要而且很常见的问题;
- 是控制、滤波、优化、视觉、机器学习等领域的一个基础问题;
- 涉及到很多必须的数学知识,为将来研究的研究打下基础;
- 这是一个很好的由浅入深的问题。
本文的仿真代码请看我附带的资源。
2. 问题分析
这是一个线性拟合或者线性回归问题,目的是在二维平面上,找到一条直线来拟合给出的点。
线性拟合有很多方法,每个方法都有自己的目标函数,不同的情况下应该要使用相应的目标函数和相应的方法。每种方法都有其自己的适用范围和意义,每种方法也都有自己的优缺点。
3. 解析解法
这个问题的复杂程度还不是很大,所以能够通过数学的方法求出解析解。
3.1 一般最小二乘法
一般最小二乘是最常用的线性拟合的方法。
一般最小二乘法的目的是找到因变量 y y y与自变量 x x x之间的函数关系 y = f ( x ) y=f(x) y=f(x)。对于本文讨论的为题,可以将点的横坐标看做自变量,将纵坐标看做因变量。然后使用一般最小二乘法找到自变量和因变量之间的函数关系,由这个函数关系可以确定一条直线,这就是拟合出来的直线。
3.1.1目标函数
假设给出的若干点的坐标为:
(
x
1
,
y
1
)
,
(
x
2
,
y
2
)
⋯
(
x
n
,
y
n
)
(x_1,y_1),(x_2,y_2) \cdots (x_n,y_n)
(x1,y1),(x2,y2)⋯(xn,yn)。定义纵坐标
y
y
y的误差
ϵ
i
\epsilon_i
ϵi为真值与观测值之差,定义
y
y
y的残差
ϵ
^
i
\hat{\epsilon}_i
ϵ^i为估计值与观测值的差,公式如下:
ϵ
i
=
y
i
−
y
i
⋆
\epsilon_i=y_i-y_i^{\star}
ϵi=yi−yi⋆
ϵ ^ i = y i − y ^ i \hat{\epsilon}_i=y_i-\hat{y}_i ϵ^i=yi−y^i
一般最小二乘法的目的是使拟合误差(残差和)最小,也就是
min
∑
ϵ
^
i
\min \sum \hat{\epsilon}_i
min∑ϵ^i ,所以目标函数的形式如下:
J
1
=
1
2
∑
i
=
1
n
ϵ
^
i
2
=
1
2
∑
i
=
1
n
(
y
^
i
−
y
i
)
2
=
1
2
(
y
^
−
y
)
T
(
y
^
−
y
)
\bold{J}_1=\dfrac{1}{2}\sum_{i=1}^{n}\hat{\epsilon}_i^2 =\dfrac{1}{2}\sum_{i=1}^{n}(\hat{y}_i-y_i)^2 =\dfrac{1}{2}(\hat{\boldsymbol{y}}-\boldsymbol{y})^T(\hat{\boldsymbol{y}}-\boldsymbol{y})
J1=21i=1∑nϵ^i2=21i=1∑n(y^i−yi)2=21(y^−y)T(y^−y)
其中
y
=
[
y
1
,
y
2
,
⋯
,
y
n
]
T
\boldsymbol{y}=[y_1,y_2,\cdots,y_n]^T
y=[y1,y2,⋯,yn]T,这里添加的
1
2
\dfrac{1}{2}
21只是为了方便计算。
所以最小二乘法就是找到一组直线的参数,使得目标函数最小。
3.1.2 求解推导
直线方程使用斜截式直线方程:
y
=
k
x
+
c
y=kx+c
y=kx+c,所以要求解的直线参数为斜率
k
k
k和截距
c
c
c。所以有:
y
i
^
=
k
^
x
i
+
c
^
\hat{y_i}=\hat{k}x_i+\hat{c}
yi^=k^xi+c^。写成矩阵形式为:
y
^
=
X
θ
\hat{\bold{y}}=\boldsymbol{X}\boldsymbol{\theta}
y^=Xθ
其中,
X
=
[
x
1
1
x
2
1
⋮
⋮
x
n
1
]
\boldsymbol{X}=\left[\begin{matrix}x_1 & 1 \\x_2 & 1 \\\vdots & \vdots \\x_n & 1 \end{matrix}\right]
X=⎣⎢⎢⎢⎡x1x2⋮xn11⋮1⎦⎥⎥⎥⎤,
θ
=
[
k
^
c
^
]
\boldsymbol{\theta}=\left[\begin{matrix}\hat{k} \\\hat{c}\end{matrix}\right]
θ=[k^c^],将其带入目标函数
J
1
\boldsymbol{J}_1
J1得:
J
1
=
1
2
(
X
θ
−
y
)
T
(
X
θ
−
y
)
\boldsymbol{J}_1=\dfrac{1}{2}(\boldsymbol{X}\boldsymbol{\theta}-\boldsymbol{y})^T(\boldsymbol{X}\boldsymbol{\theta}-\boldsymbol{y})
J1=21(Xθ−y)T(Xθ−y)
目标函数对
θ
\theta
θ求导,并令其等于零,得:
∂
∂
θ
J
1
=
X
T
(
X
θ
−
y
)
=
0
\dfrac{\partial}{\partial\boldsymbol{\theta}} \boldsymbol{J}_1 = \boldsymbol{X}^T (\boldsymbol{X}\boldsymbol{\theta} -\boldsymbol{y})=0
∂θ∂J1=XT(Xθ−y)=0
解得:
θ
=
(
X
T
X
)
−
1
X
T
y
\boldsymbol{\theta}=(\boldsymbol{X}^T\boldsymbol{X})^{-1}\boldsymbol{X}^T\boldsymbol{y}
θ=(XTX)−1XTy
即:
[
k
^
c
^
]
=
(
X
T
X
)
−
1
X
T
y
\left[ \begin{matrix} \hat{k} \\ \hat{c} \end{matrix} \right]=(\boldsymbol{X}^T\boldsymbol{X})^{-1}\boldsymbol{X}^T\boldsymbol{y}
[k^c^]=(XTX)−1XTy
3.1.3 几何意义
从目标函数上看,一般最小二乘法的直观上的理解是:在二维平面上找到一条直线,使得每个点到直线的竖直距离之和最小。也就是说,一般最小二乘优化的是竖直距离,即纵坐标
y
y
y的误差。
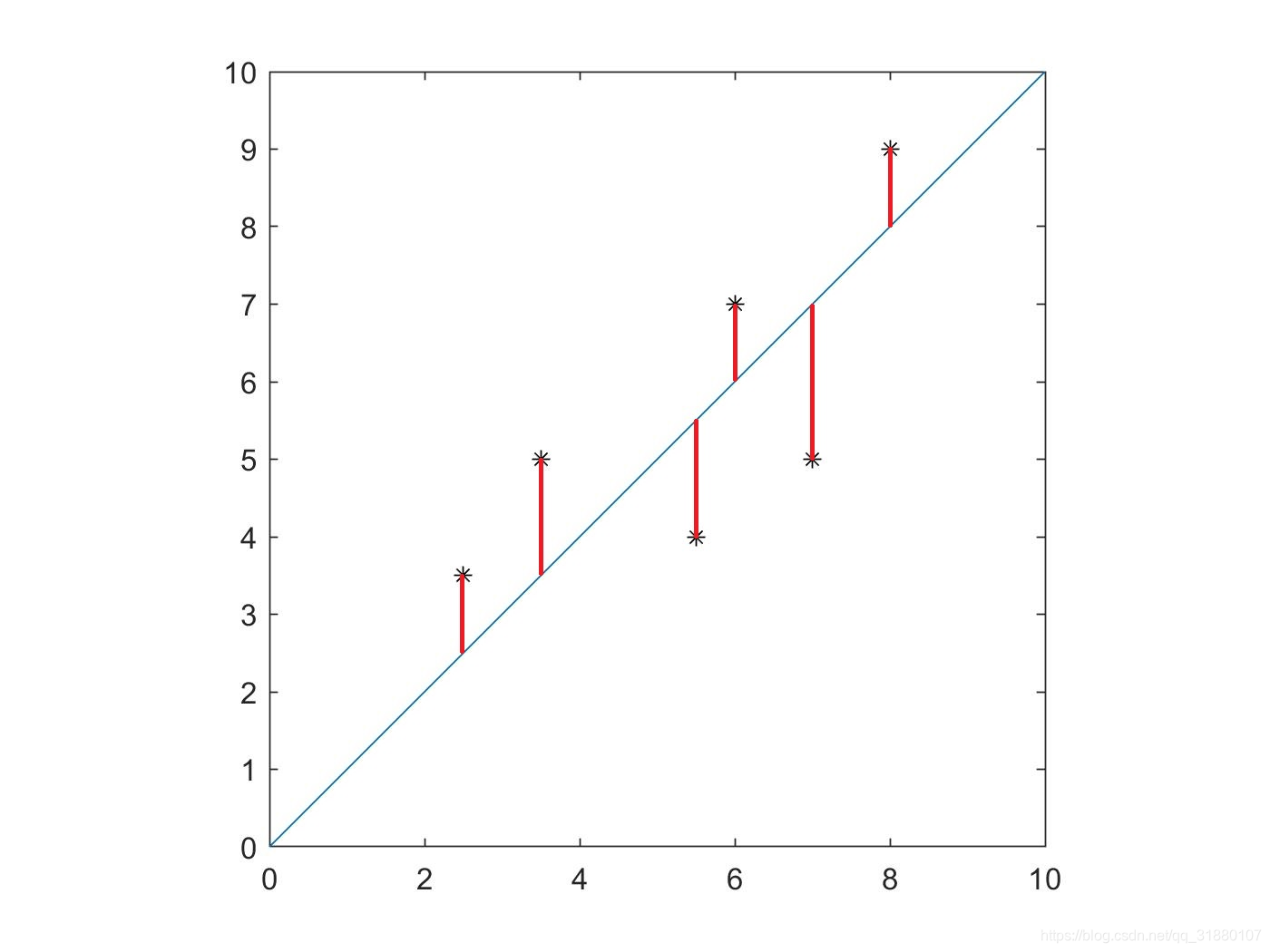
上图中红色线段即为每个点的竖直误差,一般最小二乘法就是找到这样一条直线,使得红色线段的和最小。
3.1.4 缺点
3.1.4.1 对异常值很敏感
一般最小二乘法对异常值很敏感,只要一个奇怪的异常值就可能会改变最后的结果。
从其代数解法的最后结果来看,一般最小二乘法仅使用了点的均值信息和方差信息,所以仅对存在普通噪声的情况下适用,当存在异常值时,一般最小二乘法就无能为力了,此时需要其他的方法来解决。
3.1.4.2 没有考虑自变量的误差
一般最小二乘法仅考虑了因变量 y y y存在误差的情况,没有考虑自变量 x x x的误差,所以其应用条件有一定的限制。只有当自变量不存在偏差,或者自变量的偏差在一定范围内可以忽略不计时,才比较适用。当自变量和因变量的测量都存在偏差时,一般最小二乘法就不太合适了。
对于本文所讨论的问题:用一条直线拟合平面上的若干点。题目并没有提到这些点的来源,当这些点的横坐标的测量比较精确时,可以使用考虑使用一般最小二乘法。但是当这些点的横纵坐标都存在误差,而且都不能忽略时,一般最小二乘法就不太适用了,这时就必须考虑其他的方法了。
3.1.4.3 存在不可求解的情况
当要拟合的直线是垂直或接近垂直于 x x x轴的时候,就无法求解了。垂直于 x x x轴的直线,斜率无穷大,无法用斜截式直线方程表示。
从可解性的角度考虑,当直线垂直于 x x x轴的时候,矩阵 X T X \boldsymbol{X}^T\boldsymbol{X} XTX是不可逆的,所以无法求出其最小二乘解。当直线接近垂直于 x x x轴的时候,矩阵 X T X \boldsymbol{X}^T\boldsymbol{X} XTX接近奇异,如果直接求逆,也会导致很大的偏差。
所以当拟合的直线垂直或者接近垂直于 x x x轴的时候,是不能用一般最小二乘法进行直线拟合的。
3.2 正交回归
一般最小二乘仅考虑了因变量 y y y存在误差的情况,但是很多情况下,原始点的横纵坐标都会有误差存在。正交方法能够同时考虑自变量 x x x和因变量 y y y的误差。
3.2.1 目标函数
直线方程用点法式的形式表示,定义拟合直线经过的点坐标为 p 0 = ( x 0 , y 0 ) p_0=(x_0,y_0) p0=(x0,y0),直线的法向量为 v \boldsymbol{v} v,这里我们假设直线的法向量为单位向量。所以可以使用两个向量 ( p 0 , v ) (p_0,\boldsymbol{v}) (p0,v)来表示一条直线,而且是二维平面上的任意直线。
正交回归的目的是点到直线的距离之和最小,也就是点到直线上投影点的距离最短。点到投影点的距离可以用向量 p i = ( p i − p 0 ) \boldsymbol{p}_i=(p_i-p_0) pi=(pi−p0)向直线法向量 v \boldsymbol{v} v方向上的投影的模长来表示。
向 v \boldsymbol{v} v投影的投影矩阵为 v v T \boldsymbol{v}\boldsymbol{v}^T vvT。
所以目标函数可以表示为:
J
2
=
1
2
n
∑
∣
∣
v
v
T
(
p
i
−
p
0
)
∣
∣
2
\boldsymbol{J}_2=\dfrac{1}{2n}\sum ||\boldsymbol{v}\boldsymbol{v}^T(p_i-p_0)||^2
J2=2n1∑∣∣vvT(pi−p0)∣∣2
这里的
1
2
n
\dfrac{1}{2n}
2n1是为了计算方便。
也可以化简为几种不同的形式:
J
2
=
1
2
n
∑
v
T
(
p
i
−
p
0
)
(
p
i
−
p
0
)
T
v
J
2
=
1
2
n
∑
[
v
T
(
p
i
−
p
0
)
]
2
\begin{aligned} \boldsymbol{J}_2&=\dfrac{1}{2n}\sum\boldsymbol{v}^T(p_i-p_0) (p_i-p_0)^T\boldsymbol{v}\\ \boldsymbol{J}_2&=\dfrac{1}{2n}\sum [ \boldsymbol{v}^T (p_i-p_0)]^2 \end{aligned}
J2J2=2n1∑vT(pi−p0)(pi−p0)Tv=2n1∑[vT(pi−p0)]2
3.2.2 求解推导
目标函数
J
2
\boldsymbol{J}_2
J2对
p
0
p_0
p0求导,得:
d
J
2
d
p
0
=
d
p
0
{
1
2
n
∑
[
v
T
(
p
i
−
p
0
)
]
2
}
=
−
v
T
(
∑
p
i
n
−
p
0
)
v
\dfrac{d\boldsymbol{J}_2}{d p_0}=\dfrac{d}{p_0}\{\dfrac{1}{2n}\sum [\boldsymbol{v}^T (p_i-p_0)]^2\}=-\boldsymbol{v}^T(\dfrac{\sum p_i}{n}-p_0)\boldsymbol{v}
dp0dJ2=p0d{2n1∑[vT(pi−p0)]2}=−vT(n∑pi−p0)v
令
d
J
2
d
p
0
=
0
\dfrac{d\boldsymbol{J}_2}{d p_0}=\boldsymbol{0}
dp0dJ2=0,得:
v
T
(
p
ˉ
−
p
0
)
v
=
0
\boldsymbol{v}^T(\bar{p}-p_0)\boldsymbol{v}=\boldsymbol{0}
vT(pˉ−p0)v=0
其中
p
ˉ
\bar{p}
pˉ为所有拟合点的质心。
因为法向量不是零向量,所以可以得出:
v
T
(
p
ˉ
−
p
0
)
=
0
\boldsymbol{v}^T(\bar{p}-p_0)=0
vT(pˉ−p0)=0
所以,
p
ˉ
\bar{p}
pˉ一定是直线上的一点,所以不妨设
p
0
=
p
ˉ
p_0=\bar{p}
p0=pˉ。
此时目标函数可以化简:
J
2
=
1
2
n
∑
v
T
(
p
i
−
p
ˉ
)
(
p
i
−
p
ˉ
)
T
v
=
1
2
n
v
T
S
v
\boldsymbol{J}_2=\dfrac{1}{2n}\sum\boldsymbol{v}^T (p_i-\bar{p})(p_i-\bar{p})^T\boldsymbol{v} =\dfrac{1}{2n}\boldsymbol{v}^T\boldsymbol{S}\boldsymbol{v}
J2=2n1∑vT(pi−pˉ)(pi−pˉ)Tv=2n1vTSv
其中
S
=
∑
(
p
i
−
p
ˉ
)
(
p
i
−
p
ˉ
)
T
\boldsymbol{S}=\sum(p_i-\bar{p})(p_i-\bar{p})^T
S=∑(pi−pˉ)(pi−pˉ)T
这是一个二次型,所以当 v \boldsymbol{v} v取矩阵 S \boldsymbol{S} S最小特征值对应的特征向量时,目标函数的值最小。
3.2.3 结果总结
p 0 p_0 p0为拟合点的质心坐标。
v \boldsymbol{v} v应该取矩阵 S = ∑ ( p i − p ˉ ) ( p i − p ˉ ) T \boldsymbol{S}=\sum(p_i-\bar{p})(p_i-\bar{p})^T S=∑(pi−pˉ)(pi−pˉ)T最小特征值对应的特征向量。
3.2.4 几何意义
从正交回归的直观上的理解是:在二维平面上找到一条直线,使得每个点到直线的垂直距离之和最小。也就是说,正交回归优化的是垂直距离。
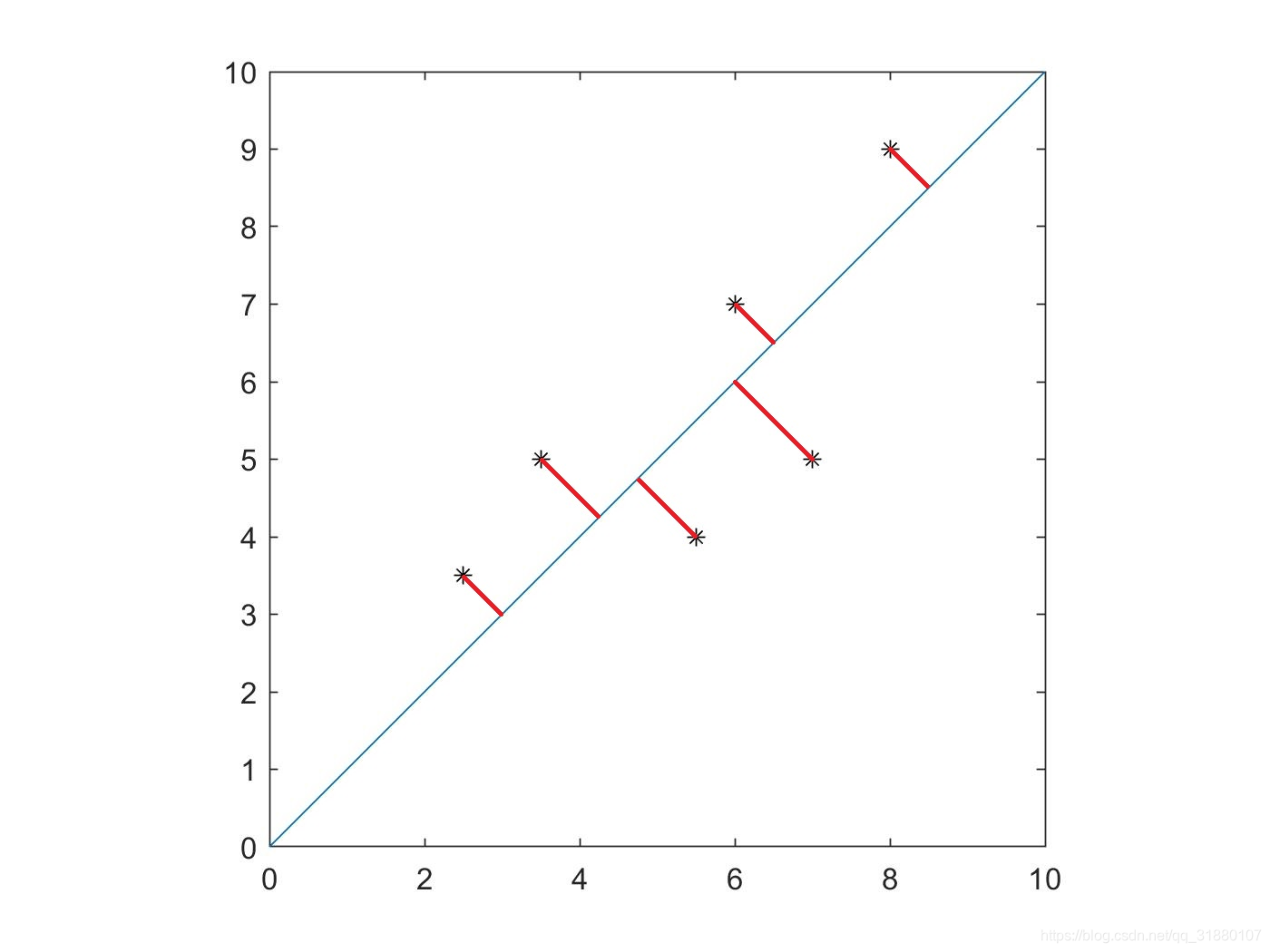
上图中红色线段即为每个点的竖直误差,正交回归就是找到这样一条直线,使得红色线段的和最小。
4 数值解法
前面两种方法都是解析法,能够准确地求出具体值,但是如果矩阵的规模很大,用计算机求解就有些得不偿失(尤其是矩阵求逆),甚至最后的结果是错误的。
4.1 梯度下降法
梯度下降法是一个很好的方法,用计算机去迭代近似,能够达到很快的收敛速度,同时也能保证比较高的精确度。
梯度下降法的基本思想可以类比为一个下山的过程,每次循环都已当前位置为基准,找到当前这个位置最陡峭的方向,然后朝着这个方向往下走,最终就会抵达山底。对于算法来说,一个关键的点是如何找到最陡峭的方向。而且每次循环的频率也是一个关键点的参数,如果频率太高,则会收敛太慢,如果频率太低,则可能会偏离方向。
梯度下降法相当于一种迭代算法,先随机给定一个解,然后循环迭代,每次都以目标函数下降最快的
4.1.1 迭代公式
将梯度下降的思想应用到一般最小二乘中。将一般最小二乘的目标函数作为梯度下降的损失函数,将直线的点法式方程中的参数作为梯度下降的优化量。
这里为了方便,对损失函数做一个简单的变换,对损失函数除以
n
n
n:
J
1
=
1
2
n
∑
(
k
x
i
+
c
−
y
i
)
2
\boldsymbol{J}_1=\dfrac{1}{2n}\sum(kx_i+c-y_i)^2
J1=2n1∑(kxi+c−yi)2
则迭代公式为:
θ
n
e
w
=
θ
o
l
d
−
α
d
d
θ
J
3
(
θ
)
\boldsymbol{\theta}_{new}=\boldsymbol{\theta}_{old}-\alpha\dfrac{d}{d \boldsymbol{\theta}}\boldsymbol{J_3}(\boldsymbol{\theta})
θnew=θold−αdθdJ3(θ)
其中
α
\alpha
α为步长。
4.1.2 算法步骤
线性拟合梯度下降法的迭代步骤如下:
输入:
数据点: ( x 1 , y 1 ) , ( x 2 , y 2 ) , ⋯ , ( x n , y n ) (x_1,y_1),(x_2,y_2),\cdots,(x_n,y_n) (x1,y1),(x2,y2),⋯,(xn,yn);
输出:
直线参数:斜率 k k k和截距 c c c;
- 初始化直线参数,令 θ = [ k c ] = [ 1 1 ] \boldsymbol{\theta}= \left[ \begin{matrix} k \\ c \end{matrix} \right]= \left[ \begin{matrix} 1 \\ 1 \end{matrix}\right] θ=[kc]=[11];
- 初始化步长,令 α = 0.1 \alpha=0.1 α=0.1;
- 计算梯度 Δ = d d θ J 1 ( θ ) \Delta=\dfrac{d}{d\boldsymbol{\theta}}\boldsymbol{J}_1(\boldsymbol{\theta}) Δ=dθdJ1(θ);
- while
Δ
>
1
0
−
5
\Delta > 10^{-5}
Δ>10−5 do
- 更新直线参数 θ ← θ − α Δ \boldsymbol{\theta} \leftarrow \boldsymbol{\theta}-\alpha \Delta θ←θ−αΔ;
- 更新梯度 Δ = d d θ J 1 ( θ ) \Delta=\dfrac{d}{d\boldsymbol{\theta}}\boldsymbol{J}_1(\boldsymbol{\theta}) Δ=dθdJ1(θ);
- end
4.1.3 收敛性证明
目标函数的梯度计算为:
d
J
1
(
θ
)
d
θ
=
A
T
(
A
θ
−
y
)
\dfrac{d \boldsymbol{J}_1(\boldsymbol{\theta})}{d\boldsymbol{\theta}}=\boldsymbol{A}^T(\boldsymbol{A}\boldsymbol{\theta}-\boldsymbol{y})
dθdJ1(θ)=AT(Aθ−y)
所以迭代公式可以写成:
θ
n
e
w
=
θ
o
l
d
−
α
A
T
(
A
θ
−
y
)
\boldsymbol{\theta}_{new}=\boldsymbol{\theta}_{old}-\alpha\boldsymbol{A}^T(\boldsymbol{A}\boldsymbol{\theta}-\boldsymbol{y})
θnew=θold−αAT(Aθ−y)
定义收敛值为
θ
∗
\boldsymbol{\theta}^*
θ∗,通过解析解法,我们知道:
θ
∗
=
(
A
T
A
)
−
1
A
T
y
\boldsymbol{\theta}^*=(\boldsymbol{A}^T\boldsymbol{A})^{-1}\boldsymbol{A}^T\boldsymbol{y}
θ∗=(ATA)−1ATy
定义第
k
k
k步的结果与收敛值的差为:
e
k
=
θ
k
−
θ
∗
\boldsymbol{e}_k=\boldsymbol{\theta}_k-\boldsymbol{\theta}^*
ek=θk−θ∗
将
θ
k
=
e
k
+
θ
∗
\boldsymbol{\theta}_k=\boldsymbol{e}_k+\boldsymbol{\theta}^*
θk=ek+θ∗和
θ
k
+
1
=
e
k
+
1
+
θ
∗
\boldsymbol{\theta}_{k+1}=\boldsymbol{e}_{k+1}+\boldsymbol{\theta}^*
θk+1=ek+1+θ∗带入迭代公式,得:
e
k
+
1
+
θ
∗
=
e
k
+
θ
∗
−
α
A
T
(
A
e
k
+
A
θ
∗
−
y
)
=
e
k
+
θ
−
α
A
T
A
e
k
\begin{aligned} \boldsymbol{e}_{k+1}+\boldsymbol{\theta}^*&=\boldsymbol{e}_k+\boldsymbol{\theta}^*-\alpha\boldsymbol{A}^T(\boldsymbol{A}\boldsymbol{e}_k+\boldsymbol{A}\theta^*-\boldsymbol{y}) \\ &=\boldsymbol{e}_k+\boldsymbol{\theta}-\alpha\boldsymbol{A}^T\boldsymbol{A}\boldsymbol{e}_k \end{aligned}
ek+1+θ∗=ek+θ∗−αAT(Aek+Aθ∗−y)=ek+θ−αATAek
因此,
e
k
+
1
=
(
I
−
α
A
T
A
)
e
k
\boldsymbol{e}_{k+1}=(\boldsymbol{I}-\alpha\boldsymbol{A}^T\boldsymbol{A})\boldsymbol{e}_k
ek+1=(I−αATA)ek
所以,当
α
\alpha
α足够小,使得
I
−
α
A
T
A
\boldsymbol{I}-\alpha\boldsymbol{A}^T\boldsymbol{A}
I−αATA小于1的时候,结果是收敛的。
5 仿真对比
因为不同的算法不同的目标函数适用不同的情况,所以根据目标函数的不同,生成两种数据集。
5.1 原始数据采集
使用 − 2 x + y + 3 = 0 -2x+y+3=0 −2x+y+3=0当做原始直线方程,在直线上随机采取1000个点,然后对这些点的横纵坐标加正态分布的噪声。在这里,我们分两种情况来采集数据集,第一种情况只对纵坐标加噪声,第二种情况对横纵坐标同时加噪声。
采集后的数据点集如下图所示:
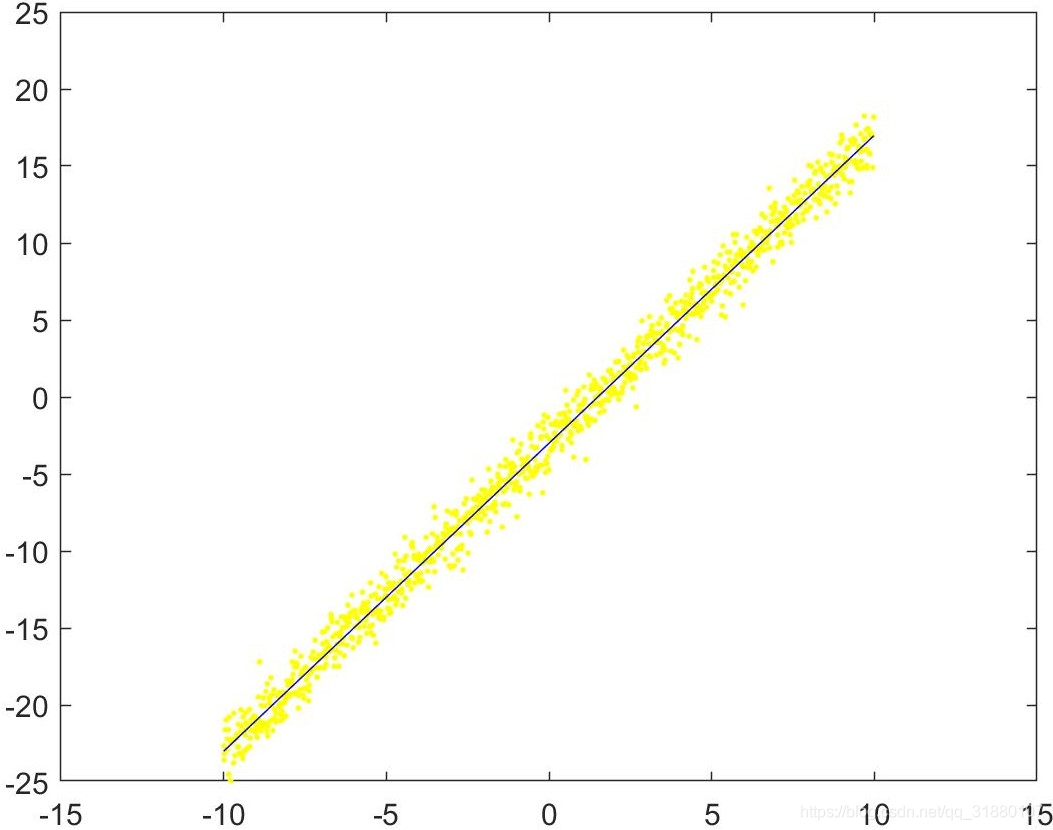 | 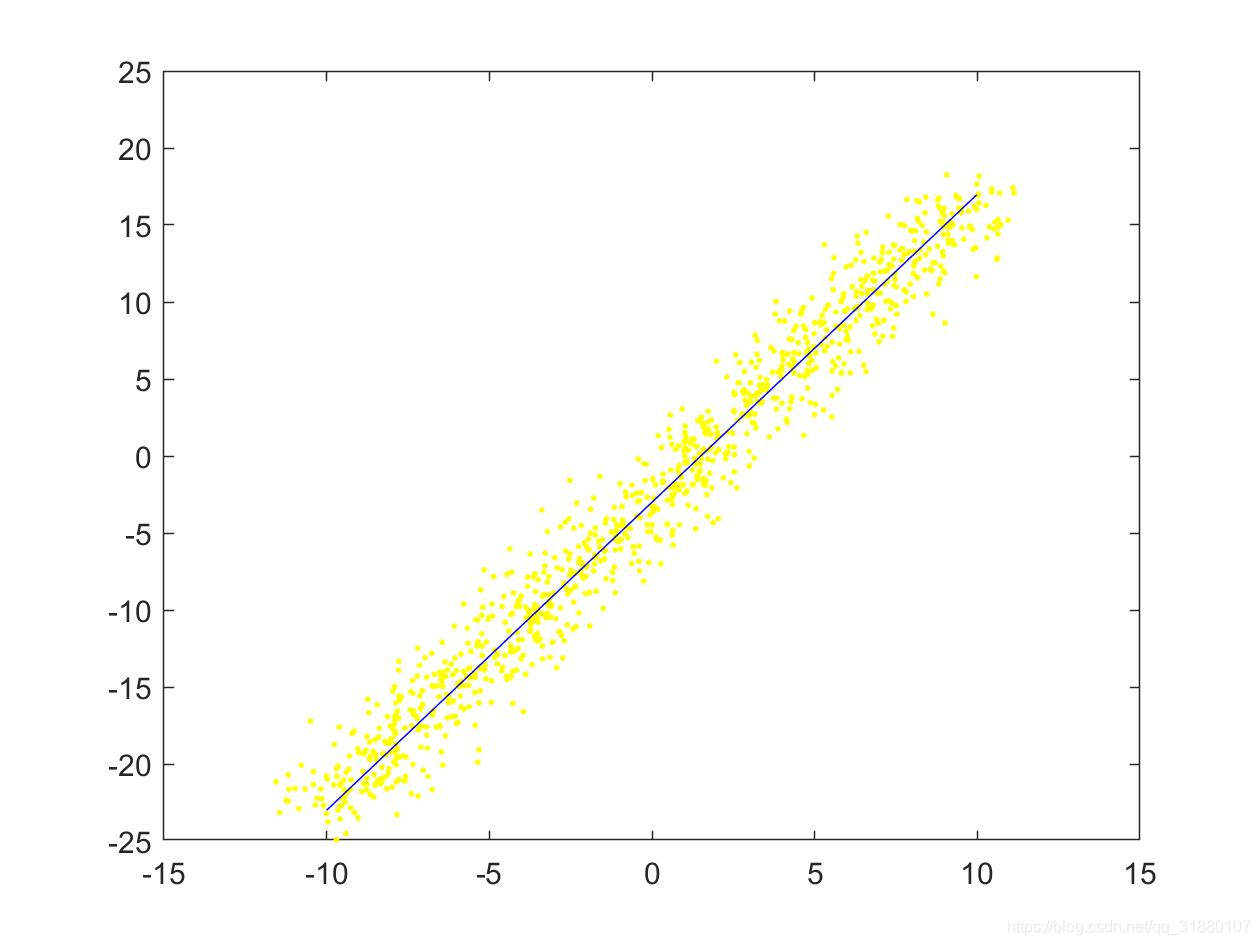 |
|---|---|
| (a) 数据集1:只对 y y y加噪声 | (b)数据集2:同时对 x x x和 y y y加噪声 |
上图中,原始直线用蓝色的直线表示,添加噪声后的点用黄色的点表示。明显可以看出,同时对 x x x和 y y y添加噪声后的点要相对稀疏一些。
5.2 仿真结果对比与分析
用截距式直线方程来表示,原直线方程为:
y
=
2
x
−
3
y=2x-3
y=2x−3。所以原直线方程的参数为:
k
=
2
c
=
−
3
\begin{aligned} k&=2\\ c&=-3 \end{aligned}
kc=2=−3
5.2.1 仿真结果对比
首先列出三种算法求出的直线方程的参数,如下表所示:
| 使用数据集1 | 使用数据集2 | |
|---|---|---|
| 一般最小二乘 | k = 2.0010 , c = − 2.9709 k=2.0010, c=-2.9709 k=2.0010,c=−2.9709 | k = 1.9386 , c = − 2.9061 k=1.9386, c=-2.9061 k=1.9386,c=−2.9061 |
| 正交回归 | k = 2.0130 , c = − 2.9708 k=2.0130, c=-2.9708 k=2.0130,c=−2.9708 | k = 1.9926 , c = − 2.9038 k=1.9926, c=-2.9038 k=1.9926,c=−2.9038 |
| 梯度下降法 | k = 2.0010 , c = − 2.9709 k=2.0010, c=-2.9709 k=2.0010,c=−2.9709 | k = 1.9386 , c = − 2.9061 k=1.9386, c=-2.9061 k=1.9386,c=−2.9061 |
| 使用数据集1 | 使用数据集2 | |
|---|---|---|
| 一般最小二乘 | e k = 0.0010 , e c = 0.0291 e_k=0.0010, e_c=0.0291 ek=0.0010,ec=0.0291 | e k = 0.0614 , e c = 0.0939 e_k=0.0614, e_c=0.0939 ek=0.0614,ec=0.0939 |
| 正交回归 | e k = 0.0130 , e c = 0.0292 e_k=0.0130, e_c=0.0292 ek=0.0130,ec=0.0292 | e k = 0.0074 , e c = 0.0962 e_k=0.0074, e_c=0.0962 ek=0.0074,ec=0.0962 |
| 梯度下降法 | e k = 0.0010 , e c = 0.0291 e_k=0.0010, e_c=0.0291 ek=0.0010,ec=0.0291 | e k = 0.0614 , e c = 0.0939 e_k=0.0614, e_c=0.0939 ek=0.0614,ec=0.0939 |
5.2.2 仿真结果分析
从上面的结果可以得出如下结论:
- 一般最小二乘法更适用于只有 y y y有噪声的情况;
- 正交回归更适用于 x x x和 y y y同时包含噪声的情况;
- 梯度下降法,因为其损失函数和一般最小二乘法相同,所以结果也是一致的。
5.2.3 拟合直线图对比
三种方法的拟合直线图如下所示:
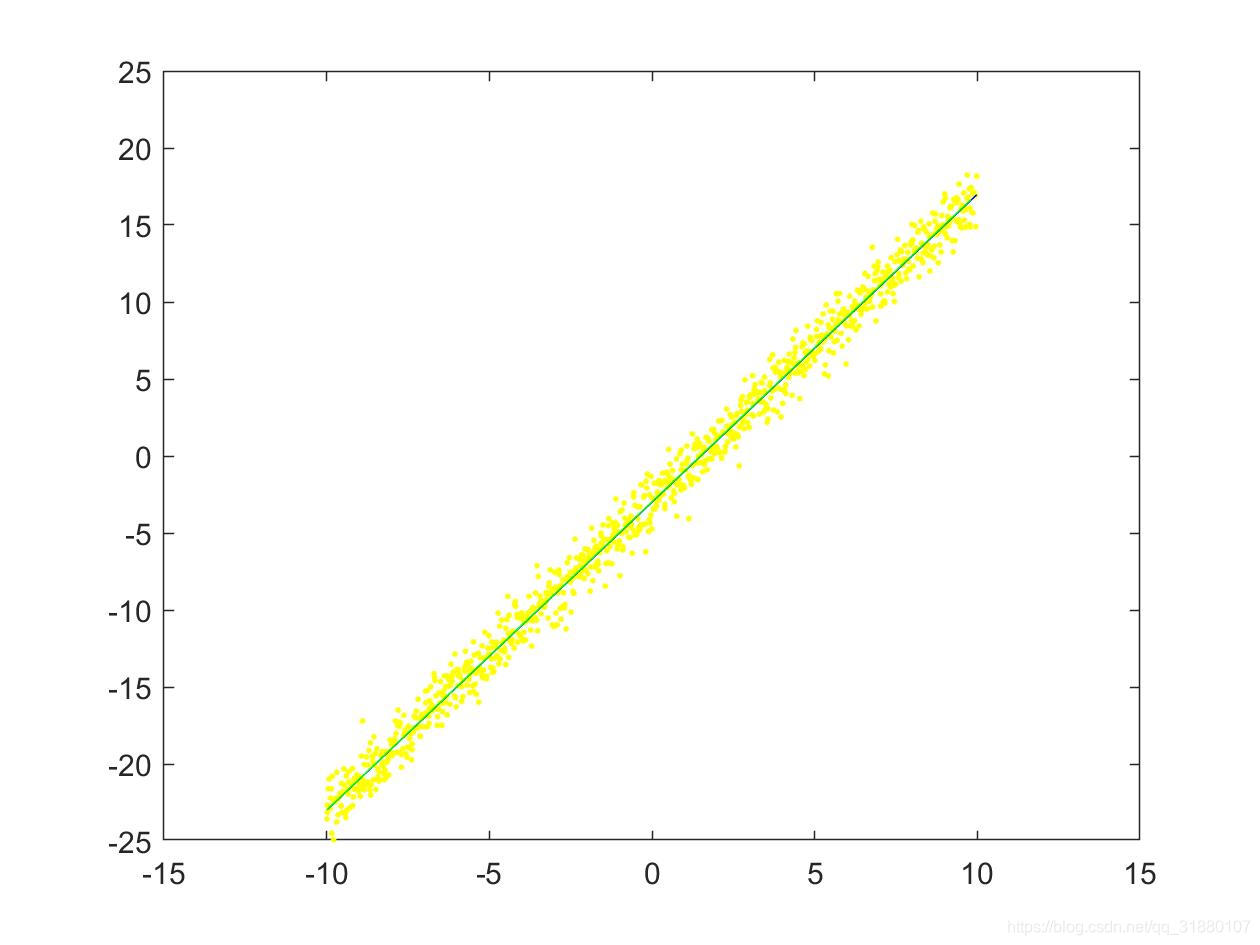 | 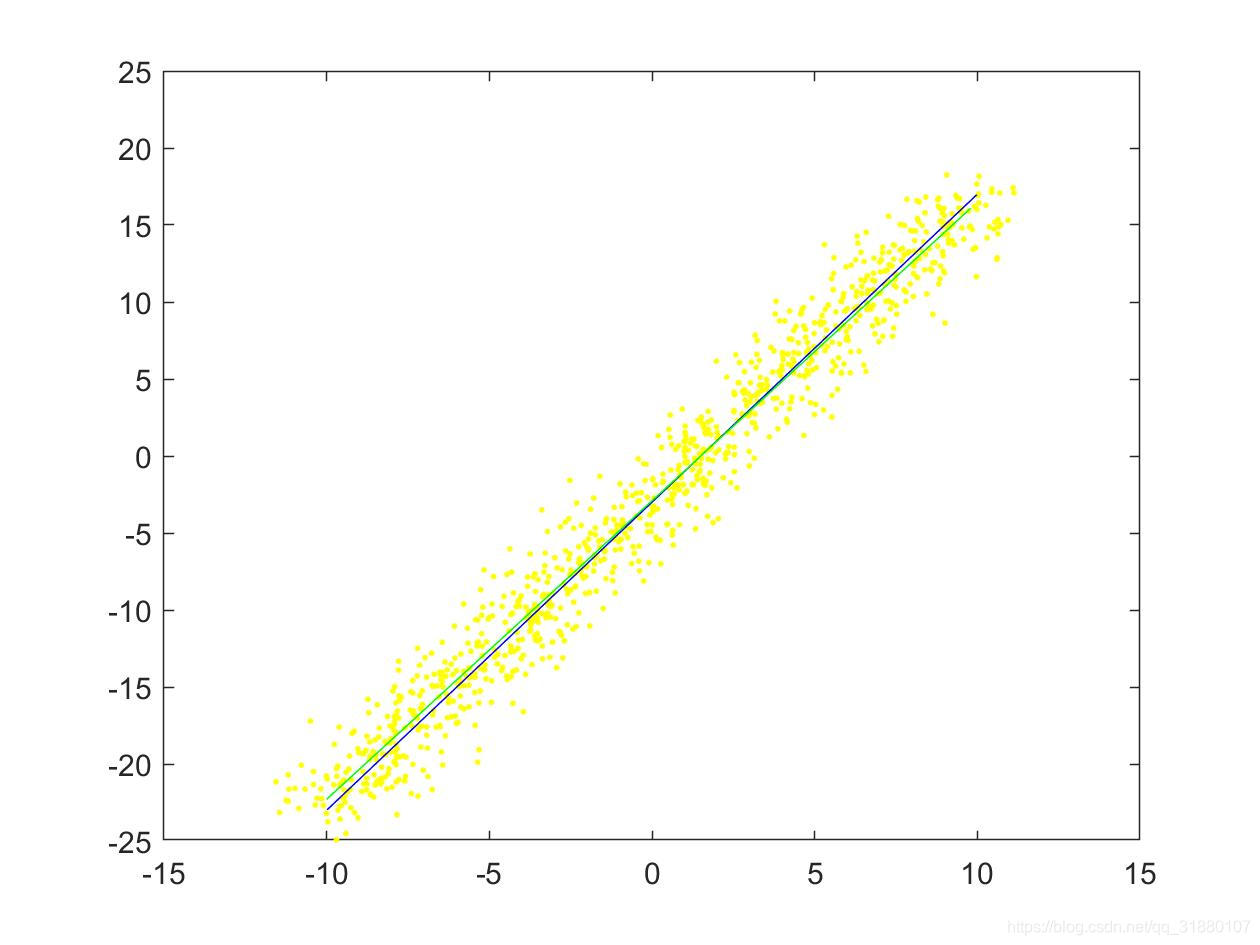 |
|---|---|
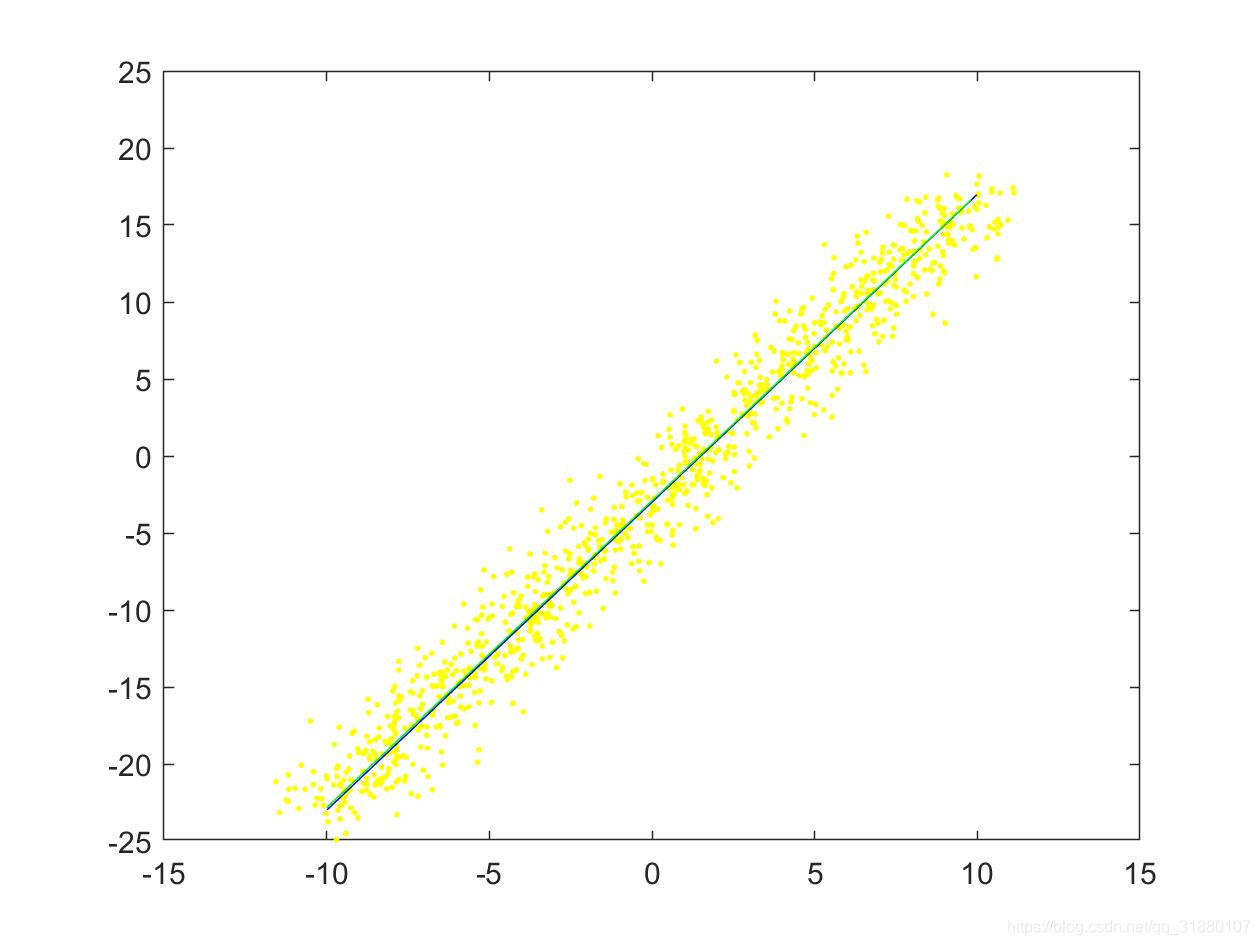
| (a)使用数据集1(只对 y y y加噪声) | (b)使用数据集2(同时对 x x x和 y y y加噪声) |
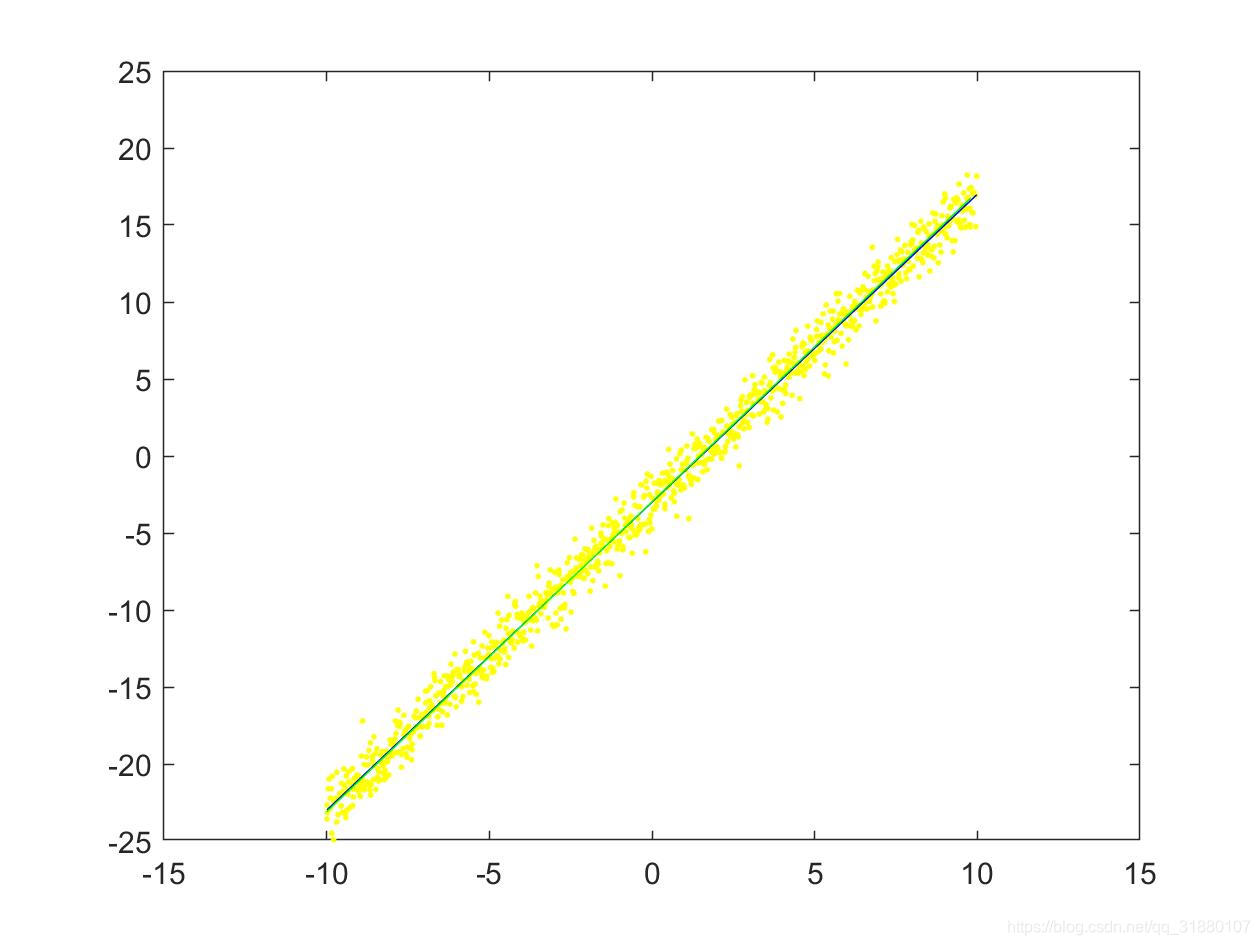 |  |
|---|---|
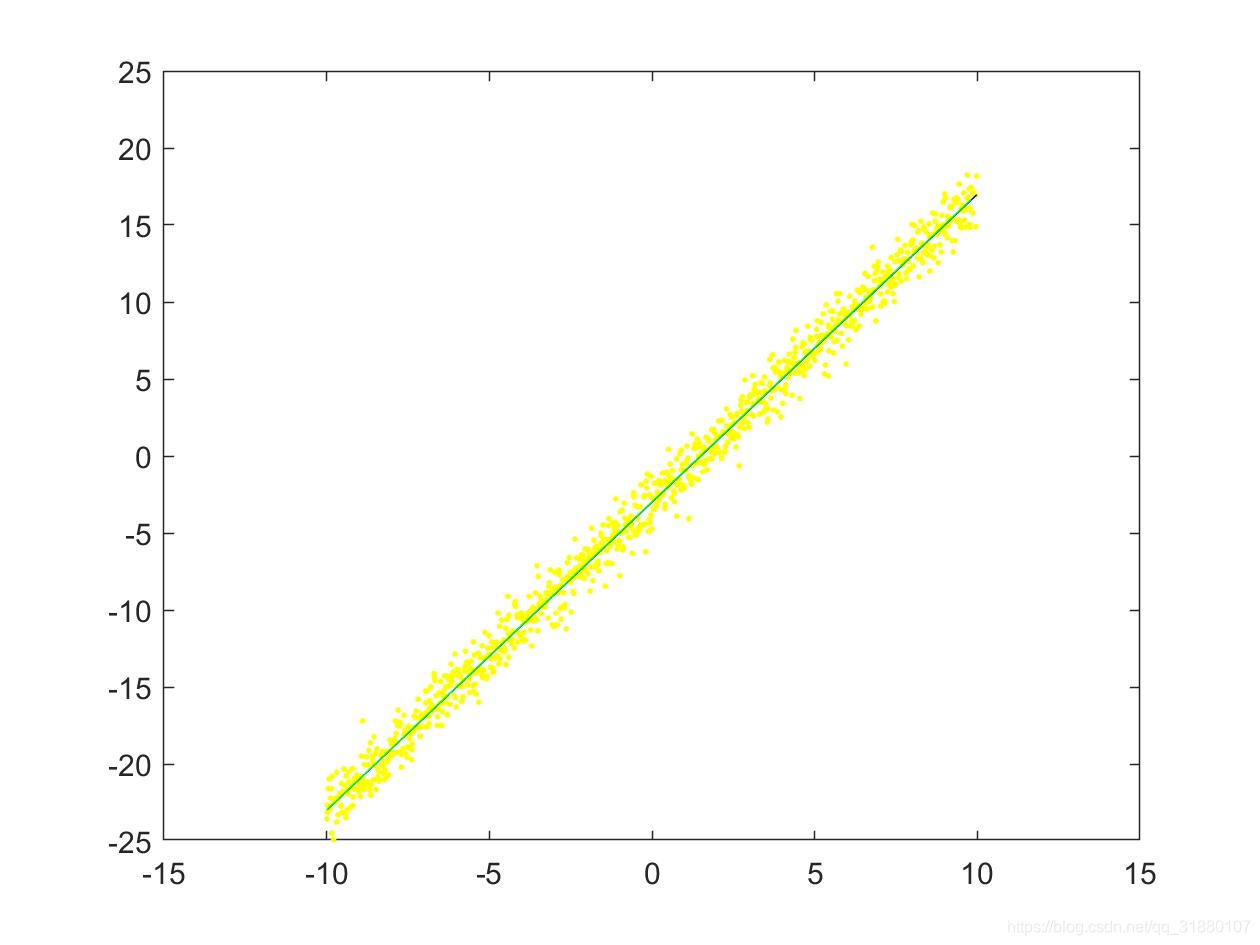
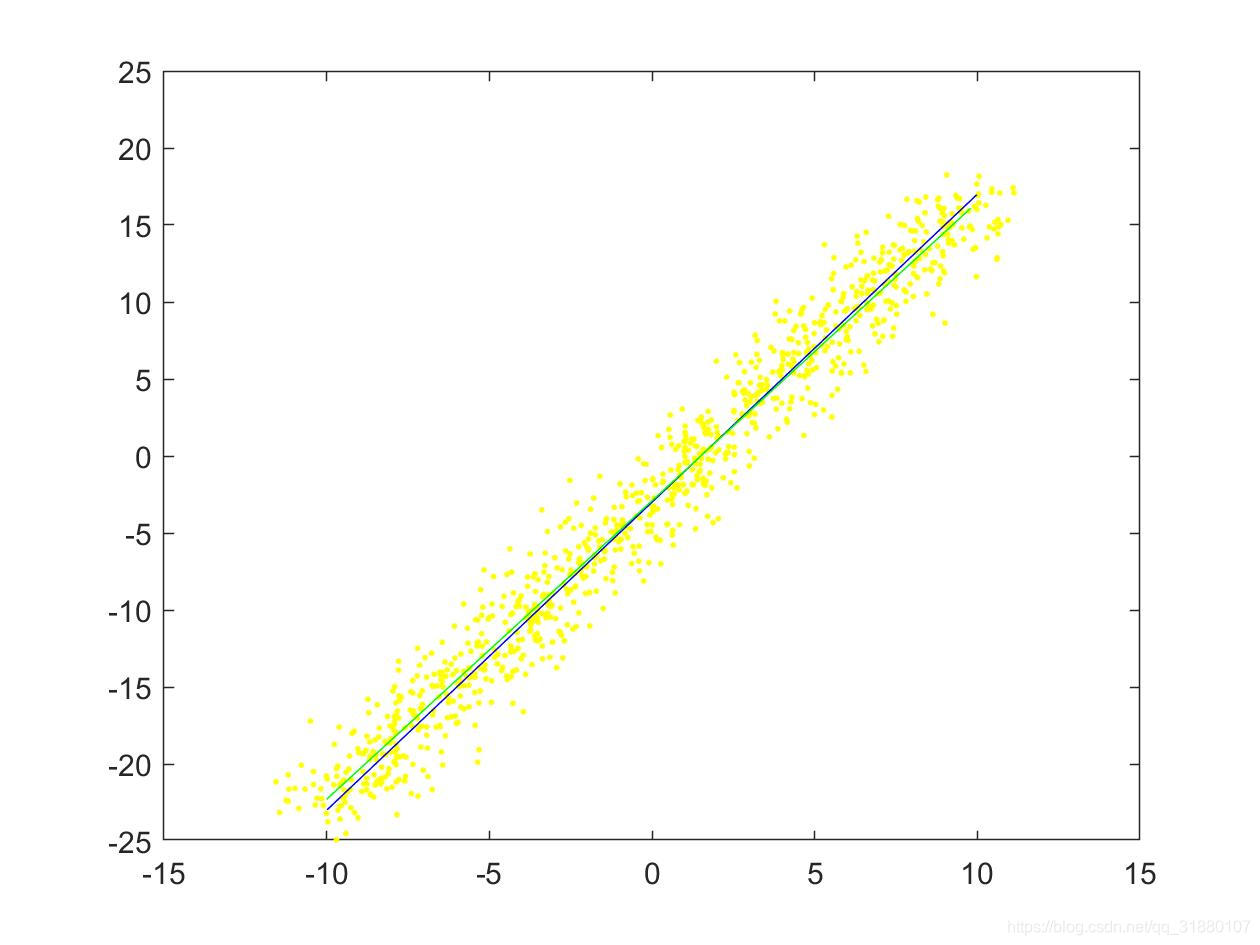
| (a) 使用数据集1(只对 y y y加噪声) | (b)使用数据集2(同时对 x x x和 y y y加噪声) |
 |  |
|---|---|
| (a)使用数据集1(只对加噪声) | (b)使用数据集2(同时对和加噪声) |
上图中,原始直线用蓝色直线表示,原始拟合点用黄色的点表示,拟合后的直线用绿色的直线表示。
5.3 曲线采点仿真
使用 y = ( x + 5 ) 2 y=(x+5)^2 y=(x+5)2作为原始曲线,随机采点,并对 x x x和 y y y都加噪声。分别使用最小二乘法和正交回归进行拟合仿真,结果如下:
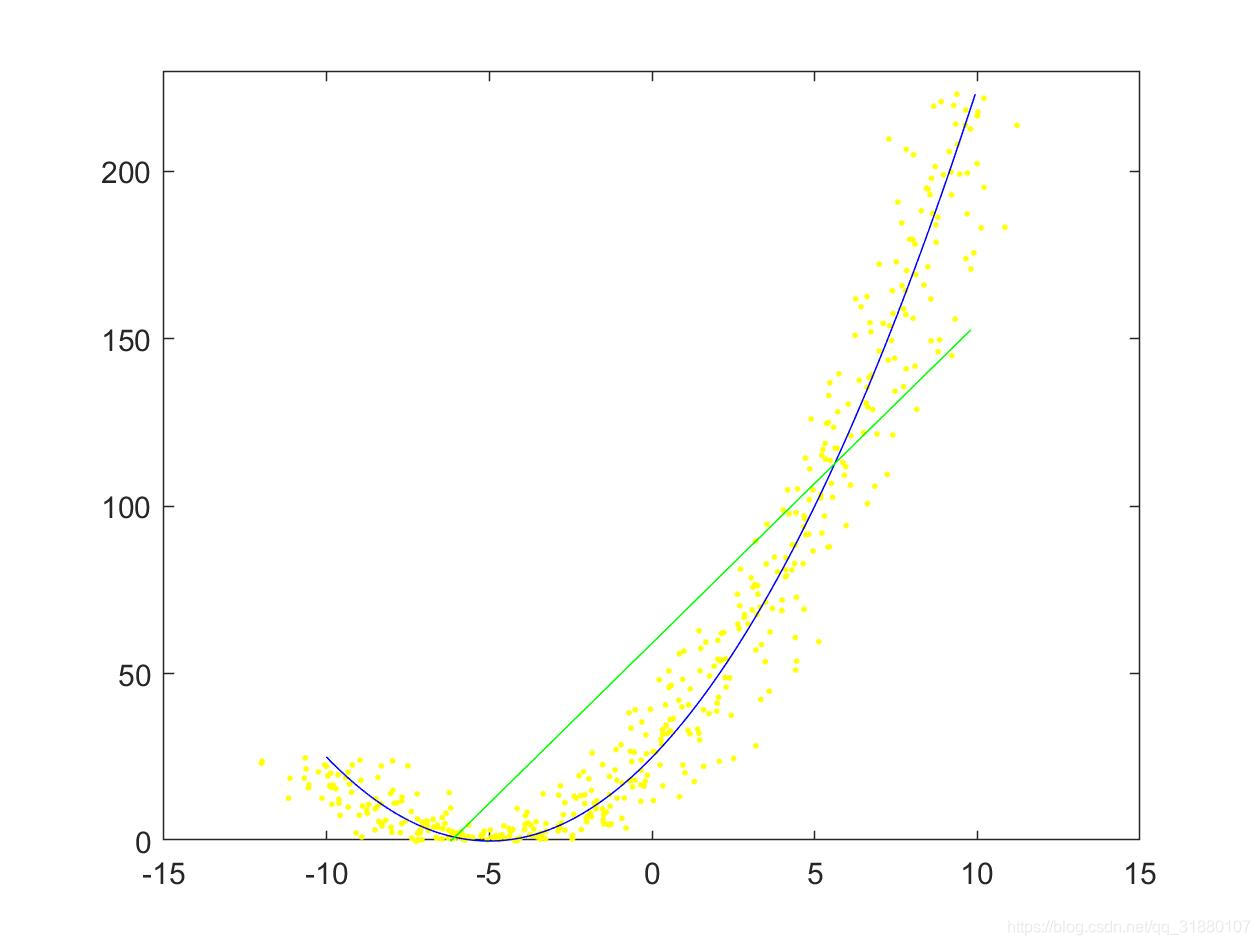 | 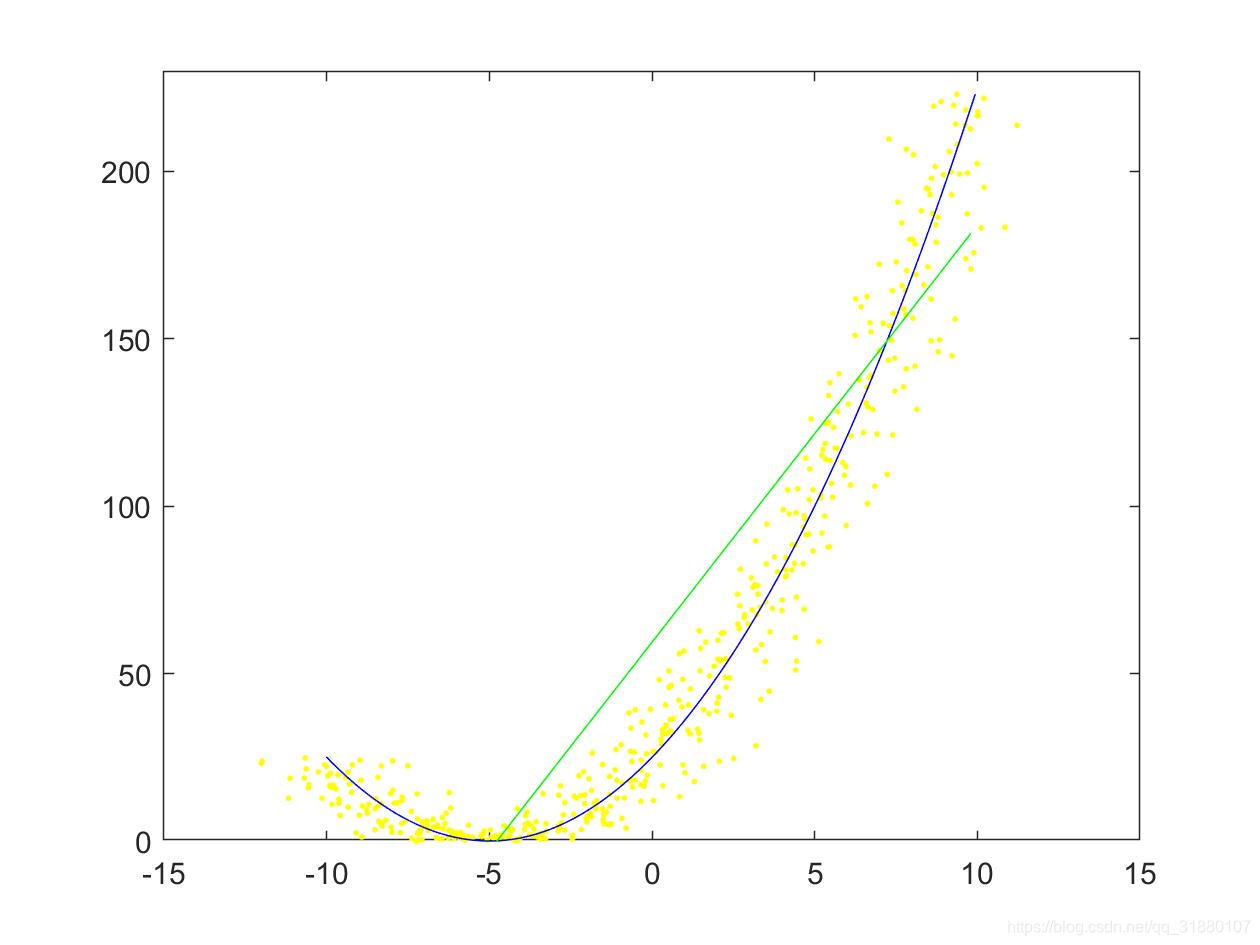 |
|---|---|
| (a)使用一般最小二乘法 | (b)使用正交回归 |
从结果看,两种算法的最后结果差别较大。
6 向高维推广
6.1 3维空间中的平面拟合
3维空间中的平面同样可以用点法式来进行表示。我们用 ( p 0 , v ) (p_0,\boldsymbol{v}) (p0,v)这样的组合来表示直线,其中 p 0 p_0 p0表示平面上的点, v \boldsymbol{v} v表示平面的法向量。
则目标函数可以写成:
J
4
=
1
2
n
∑
∣
∣
v
v
T
(
p
i
−
p
0
)
∣
∣
2
\boldsymbol{J}_4=\dfrac{1}{2n}\sum ||\boldsymbol{v}\boldsymbol{v}^T(p_i-p_0)||^2
J4=2n1∑∣∣vvT(pi−p0)∣∣2
这个跟2维直线拟合是一样的,只是向量和矩阵都多了一维。
直接写出结果:
p
0
p_0
p0为拟合点的质心点坐标;
v
\boldsymbol{v}
v应该取矩阵
S
=
∑
(
p
i
−
p
ˉ
)
(
p
i
−
p
ˉ
)
T
\boldsymbol{S}=\sum(p_i-\bar{p})(p_i-\bar{p})^T
S=∑(pi−pˉ)(pi−pˉ)T最小特征值对应的特征向量。
6.2 3维空间中的直线拟合
3维空间中的直线可以用点向式来表示。用
(
p
0
,
v
)
(p_0,\boldsymbol{v})
(p0,v)这样的组合来表示3维空间中的任意一条直线,其中
p
0
p_0
p0表示直线上的一点,
v
\boldsymbol{v}
v为直线的方向向量,因为只表示方向,其大小没有关系,所以直接定义其为单位向量。则,点到直线的投影距离为:
d
i
=
∣
∣
(
I
−
v
v
T
)
(
p
i
−
p
0
)
∣
∣
d_i=||(\boldsymbol{I}-\boldsymbol{v}\boldsymbol{v}^T)(p_i-p_0)||
di=∣∣(I−vvT)(pi−p0)∣∣
目标函数可以写成:
J
5
=
1
2
n
∑
∣
∣
(
I
−
v
v
T
)
(
p
i
−
p
0
)
∣
∣
2
\boldsymbol{J}_5=\dfrac{1}{2n}\sum||(\boldsymbol{I}-\boldsymbol{v}\boldsymbol{v}^T)(p_i-p_0)||^2
J5=2n1∑∣∣(I−vvT)(pi−p0)∣∣2
也可以化简为多种形式:
J
5
=
1
2
n
∑
[
(
p
i
−
p
0
)
T
(
I
−
v
v
T
)
(
p
i
−
p
0
)
]
J
5
=
1
2
n
∑
[
(
p
i
−
p
0
)
T
(
p
i
−
p
0
)
−
v
T
(
p
i
−
p
0
)
(
p
i
−
p
0
)
T
v
]
\begin{aligned} \boldsymbol{J}_5&=\dfrac{1}{2n}\sum [(p_i-p_0)^T(\boldsymbol{I}-\boldsymbol{v}\boldsymbol{v}^T) (p_i-p_0)]\\ \boldsymbol{J}_5&=\dfrac{1}{2n}\sum [(p_i-p_0)^T(p_i-p_0)-\boldsymbol{v}^T(p_i-p_0)(p_i-p_0)^T\boldsymbol{v}] \end{aligned}
J5J5=2n1∑[(pi−p0)T(I−vvT)(pi−p0)]=2n1∑[(pi−p0)T(pi−p0)−vT(pi−p0)(pi−p0)Tv]
推导过程:
目标函数对
p
0
p_0
p0求导得:
∂
J
5
∂
p
0
=
−
1
n
∑
(
I
−
v
v
T
)
(
p
i
−
p
0
)
\dfrac{\partial \boldsymbol{J}_5}{\partial p_0}=-\dfrac{1}{n}\sum(\boldsymbol{I}-\boldsymbol{v}\boldsymbol{v}^T)(p_i-p_0)
∂p0∂J5=−n1∑(I−vvT)(pi−p0)
令
∂
J
5
∂
p
0
=
0
\dfrac{\partial \boldsymbol{J}_5}{\partial p_0}=\boldsymbol{0}
∂p0∂J5=0得:
p
0
=
p
ˉ
p_0=\bar{p}
p0=pˉ
其中 p ˉ \bar{p} pˉ为拟合点的质心。
此时,目标函数重写为:
J
5
=
1
2
n
∑
(
p
i
−
p
ˉ
)
T
(
p
i
−
p
ˉ
)
−
1
2
n
∑
v
T
(
p
i
−
p
ˉ
)
(
p
i
−
p
ˉ
)
T
v
\boldsymbol{J}_5=\dfrac{1}{2n}\sum(p_i-\bar{p})^T(p_i-\bar{p})-\dfrac{1}{2n}\sum\boldsymbol{v}^T(p_i-\bar{p})(p_i-\bar{p})^T\boldsymbol{v}
J5=2n1∑(pi−pˉ)T(pi−pˉ)−2n1∑vT(pi−pˉ)(pi−pˉ)Tv
所以为了求 J 5 \boldsymbol{J}_5 J5的最小值,应该求 J Q = 1 2 n ∑ v T ( p i − p ˉ ) ( p i − p ˉ ) T v \boldsymbol{J}_Q=\dfrac{1}{2n}\sum\boldsymbol{v}^T(p_i-\bar{p})(p_i-\bar{p})^T\boldsymbol{v} JQ=2n1∑vT(pi−pˉ)(pi−pˉ)Tv的最大值。
所以 v \boldsymbol{v} v应该取矩阵 S = ∑ ( p i − p ˉ ) ( p i − p ˉ ) T \boldsymbol{S}=\sum(p_i-\bar{p})(p_i-\bar{p})^T S=∑(pi−pˉ)(pi−pˉ)T最大特征值对应的特征向量。

















 5176
5176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









