







 本文概述了受限玻尔兹曼机(RBM)的训练方法,扩展到图像建模,介绍了变分自编码器(VAE)的基本思想和训练方式,以及GAN的理论问题和应用中的挑战。同时讨论了AE、VAE和GAN的联系与区别,以及最大均值差异在生成式矩匹配网络中的应用。
本文概述了受限玻尔兹曼机(RBM)的训练方法,扩展到图像建模,介绍了变分自编码器(VAE)的基本思想和训练方式,以及GAN的理论问题和应用中的挑战。同时讨论了AE、VAE和GAN的联系与区别,以及最大均值差异在生成式矩匹配网络中的应用。

目录
25.简单介绍 RBM的训练过程。如何扩展普通的 RBM 以对图像数据进行建模?
26.简述VAE的基本思想,以及它是如何用变分推断方法进行训练的?
27.什么是最大均值差异?它是如何应用到生成式矩匹配网络中的?
25.简单介绍 RBM的训练过程。如何扩展普通的 RBM 以对图像数据进行建模?

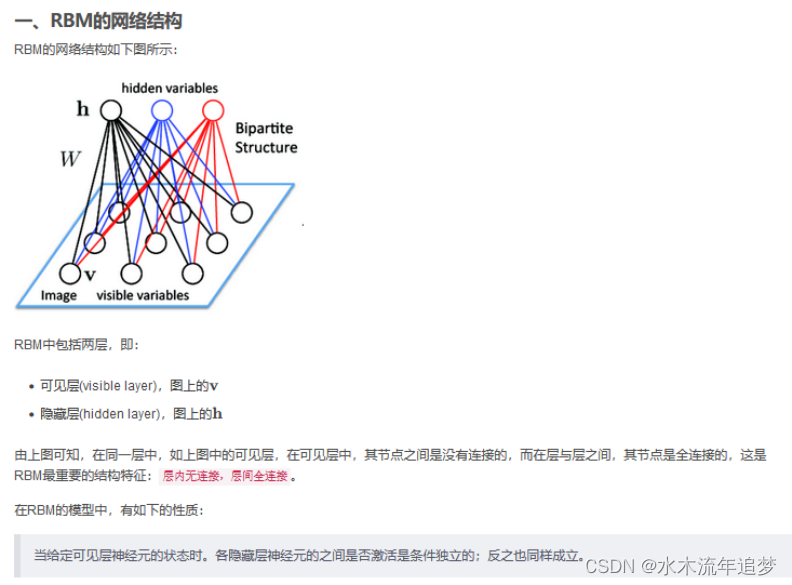
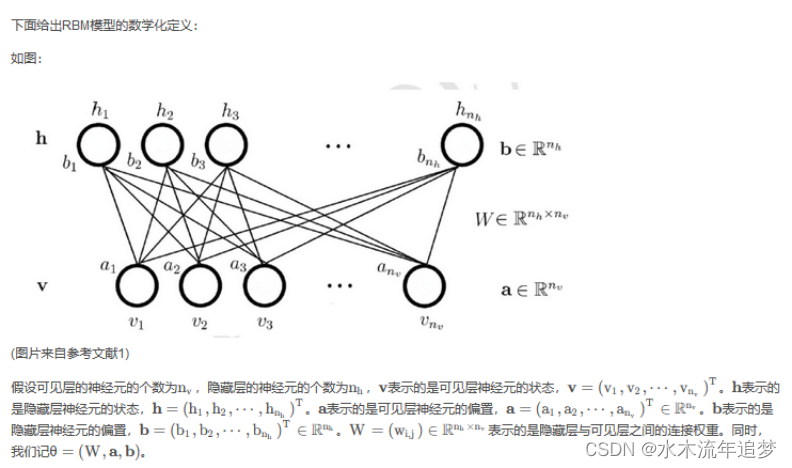
受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)是一种基于能量模型的神经网络模型,在Hinton提出针对其的训练算法(对比分歧算法)后,RBM得到了更多的关注,利用RBM的堆叠可以构造出深层的神经网络模型——深度信念网(Deep Belief Net, DBN)。





26.简述VAE的基本思想,以及它是如何用变分推断方法进行训练的?
变分自编码器VAE(variational auto-encoder)
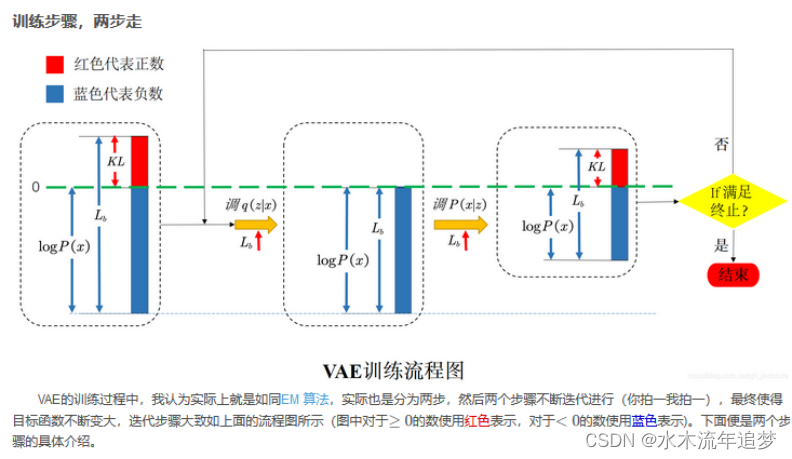
变分自编码器(Variational auto-encoder,VAE) 是一类重要的生成模型(generative model),它于2013年由Diederik P.Kingma和Max Welling提出1。2016年Carl Doersch写了一篇VAEs的tutorial2,对VAEs做了更详细的介绍,比文献1更易懂(墙裂推荐)。
vae是什么:vae就是通过Encoder对输入(我们这里以图片为输入)进行高效编码,然后由Decoder使用编码还原出图片,在理想情况下,还原输出的图片应该与原图片极相近。
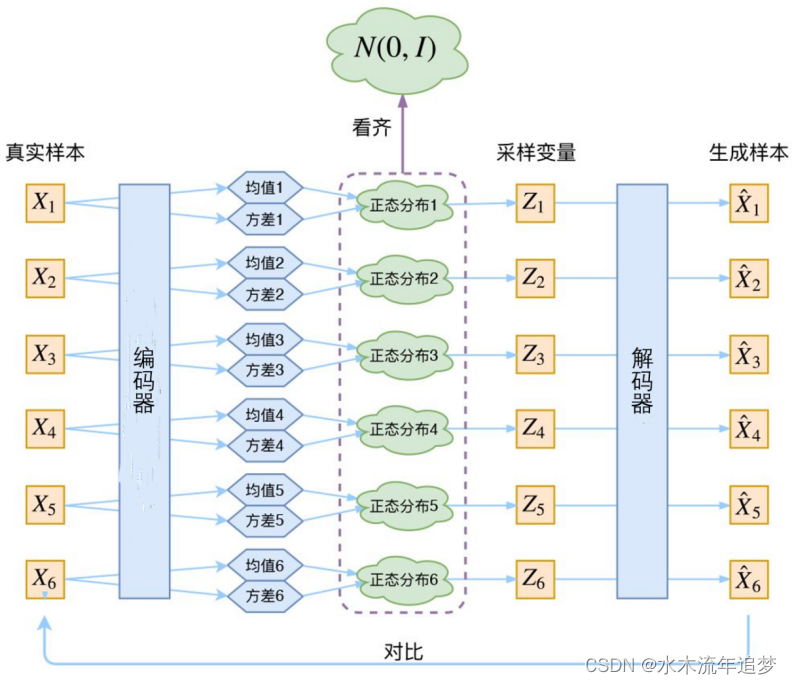
vae网络结构组成:可以大致分成Encoder和Decoder两部分。对于输入图片,Encoder将提取得到编码:一个mean vector和一个deviation vector,然后将这个编码(两个vector)作为Decoder的输入,最终输出一张和原图相近的图片。




VAE相比GAN的优势在于,GAN是implicit density,意思是它对潜变量的分布隐式建模,整个GAN训练完后我们是不知道潜变量具体分布是怎么样的,也就无法随心所欲生成想要的图片,我们只能任意的输入一个噪声,然后网络的生成数据看起来像训练数据集中的数据。但是VAE是explict density,它对潜变量的分布显式建模,我们训练完VAE后是可以得到潜变量的具体分布的,因此也就可以指定生成的数据的样子。
VAE相比GAN的劣势在于,它没有GAN那样的判别器,所以最后生成的数据会比较模糊(以图片数据为例)。当然也有结合VAE和GAN的工作。
简述AE、VAE、GAN的联系与区别
详细:标准的AE由编码器和解码器两部分组成,整个模型可以看作一个“压缩”与“解压”的过程:首先编码器将真实数据(真实样本) x x x压缩为低维隐空间中的一个隐向量 z z z,该向量可以看作世俗如的”精华“;软化解码器将这个隐向量 z z z解压,得到生成数据(生成样本) x ^ \hat{x} x^。在训练过程中,会将生成样本与真实样本进行比较,朝两者之间差异的方向去更新编码器和解码器的参数,最终目的时期望由真实样本 x x x压缩得到的 z z z能够尽可能地抓住输入的精髓,使得生成样本与真实样本尽可能接近。AE可应用于数据去噪、可视化降维和数据生成等方向。
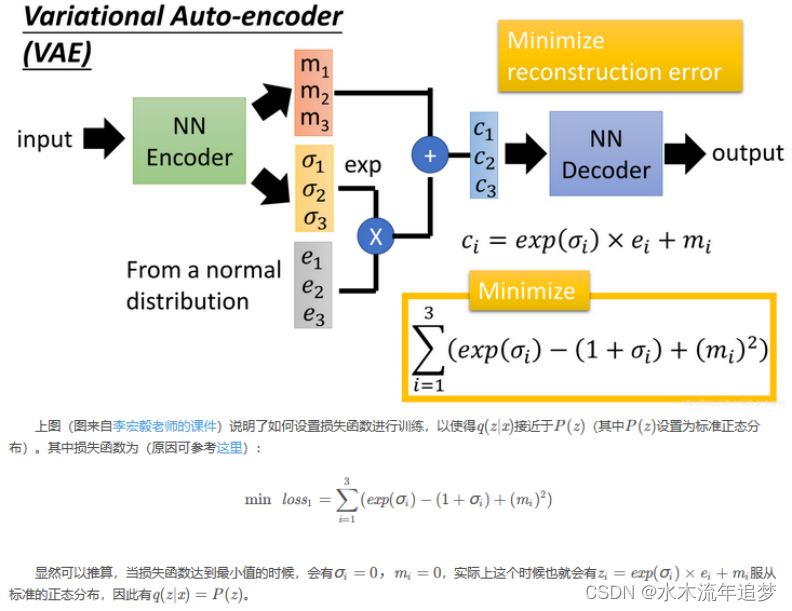
VAE是AE的升级版本,其结构也是由编码器和解码器组成,如下图。AE本身无法直接产生新的隐向量来生成新的样本,VAE能产生新的隐向量z,进而生成有效的新样本。VAE能够生成新样本的原因是:VAE在编码过程中加入了一些限制,迫使编码器产生的隐向量的后验分布 q ( z ∣ x ) q(z|x) q(z∣x)尽量接近某个特定分布(如正态分布).训练过程的优化目标包括重构误差和对后验分布 q ( z ∣ x ) q(z|x) q(z∣x)的约束这两部分。VAE编码器的输出不是隐空间中的向量,而是所属正态分布的均值和标准差,然后再根据均值与标准差来采样出隐向量z。
GAN,思路就是一个判别器,一个生成器,两个对抗训练,判别器尽量能识别出真实样本,生成器尽量生成出判别器无法正确判别的样本。这目标的优化目标是:
AE与VAE的联系与区别
速记:二至都属于有向图模型。但AE不可以创造新样本。
详细:AE和VAE 都属于有向图模型,模型的目的都是对隐变量空间进行建模;但是AE智能模仿,不能创造,VAE可以根据随机生成第的隐向量来生成新的样本。
AE的优化目标是最小化真实样本与对应的生成样本之间的重构误差;VAE除考虑重构误差外,还加入了对隐变量空间的约束目标。
AE编码器的输出代表真实样本对应的隐向量,而VAE编码器的输出可以看作由隐向量所对应的分布的均值和标准差组成。
GAN和AE/VAE的联系区别
速记:内部都存在对抗思想。
详细:VAE与GAN内部都存在对抗思想,但VAE是将两部分同步优化,而GAN则是交替优化的。
与AE相同的是,GAN的优化目标只涉及生成样本和真实样本之间的比较,没有VAE中对后验分布的约束。不同的是,GAN再判断样本真假时不需要真实样本与胜场样本一一对应。
GAN没有像AE那样从学习到的隐向量后验分布 q ( z ∣ x ) q(z|x) q(z∣x)中获得生成样本 x ^ \hat{x} x^的能力,科恩那个因此导致模式坍塌、训练不稳定等问题。
原始GAN在理论上存在哪些问题?
速记:梯度消失、模式坍塌等
详细:在训练开始时,生成器还很差,生成数据与真实数据相差甚远,判别器可以以高置信度将二者区分开来,这样 l o g ( 1 − D ( G ( z ) ) ) log(1-D(G(z))) log(1−D(G(z)))达到饱和,梯度消失。
原始GAN在实际应用中存在哪些问题?
速记:不能保证实际应用时的收敛性;模式坍塌;缺乏理性的评价和准则。
27.什么是最大均值差异?它是如何应用到生成式矩匹配网络中的?

GMMN存在一个难点:直接生成高维数据较为困难,因为:高维的图像实际上存在低维流形。高维数据不易处理
print('每天都要开心')


















 66
66

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











