









这篇文章来解读最近比较有意思的 Transformer 预训练模型在自动生成代码方面的应用,
Paper Link: Evaluating Large Language Models Trained on Code
自动生成Code系列文章解读:
【AlphaCode】Competition-Level Code Generation with AlphaCode
Abstract
我们提出了Codex模型,基于GPT的模型架构,在GItHub上微调,可以用来编写Python代码。在HumanEval这个验证集上,可以解决28.8%的问题,GPT-3解决了0%,GPT-J解决了11.4%。进一步发现,从模型中重复采样,对于解困难问题是个高效的策略。基于这种方法,我们采样每个问题的100个解可以达到70.2%的完成率。
Introduction
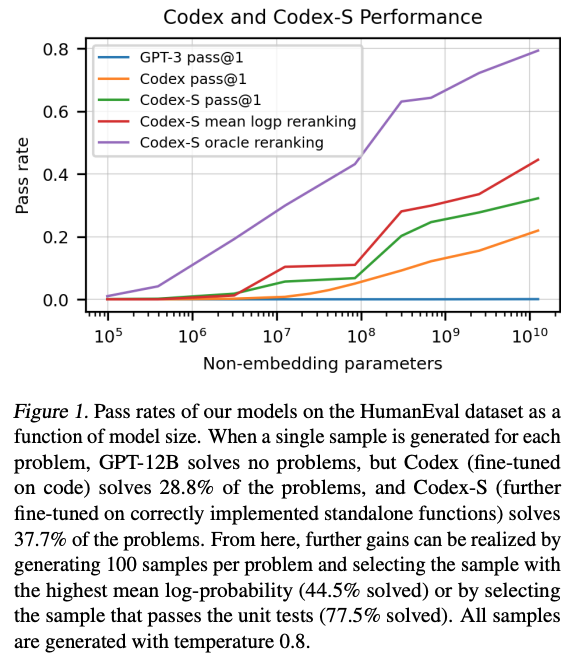
模型大小和通过率的关系。如果每个问题只选一个样本提交,GPT-12B没有完成一个问题,微调后的Codex的通过率为28.8%,Codex-S的通过率为37.7%。
Codex生成的代码示例:

Evaluation Framework
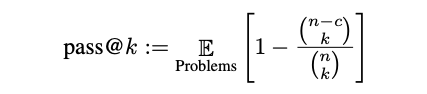
评估指标:pass@k,k表示从每个问题中生成的样本解,k中的任何一个解通过单元测试,即表示这个问题被解决。用这种方法评估的话,方差会比较大,所以提出来替代方法。生成n个样本解(n>=k),然后统计可通过单元测试的解的个数c,然后用下式计算出通过率的无偏估计:
Code Fine-Tuning
基于GPT模型,在GitHub上微调模型,模型参数量 120亿。
数据集:截止到20年5月份GitHub上开源的项目库,只用了Python文件,数据量级179GB,过滤后159GB。
有意思的一点是:作者团队首先在GPT-3上微调模型,发现效果并不好,原因可能是微调数据集太大了。然而,在GPT上微调后的模型收敛非常快,效果也不错。
Results
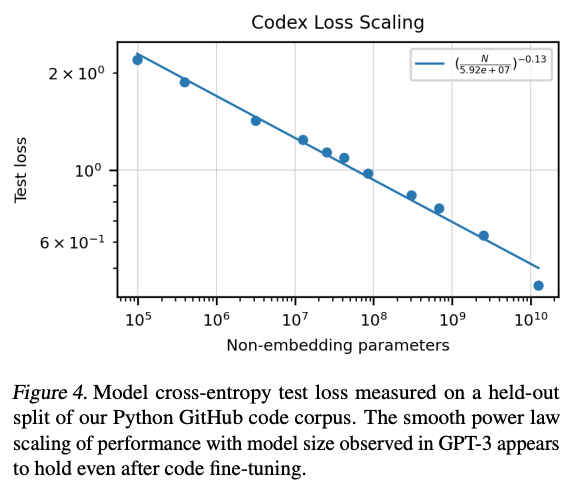
模型的非嵌入参数量级和测试集上的损失 基本服从幂律分布,如下图:
样本集k的数量和Temperature这个超参数,对通过率的影响很大。一般来说,越大的k,就需要更大的Temperature。如下图:
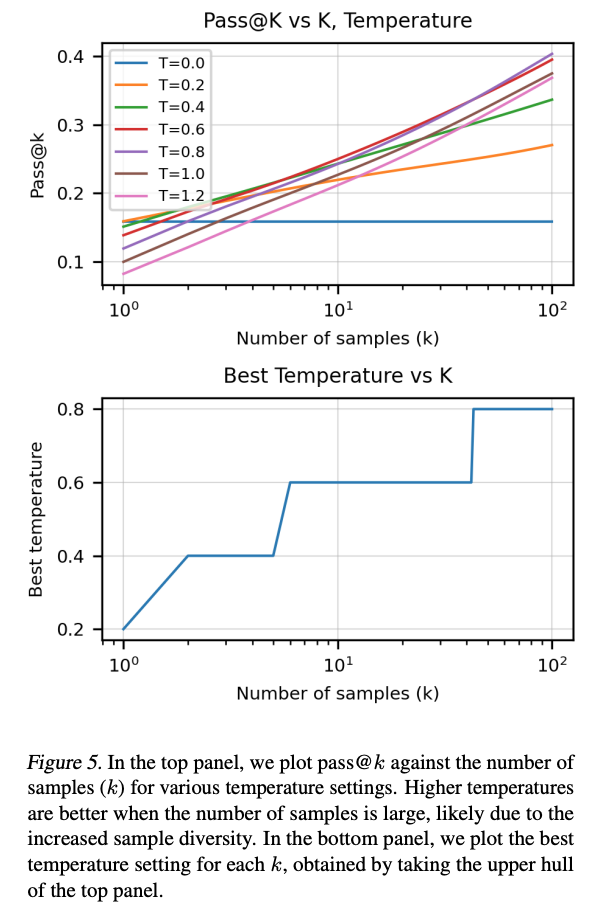
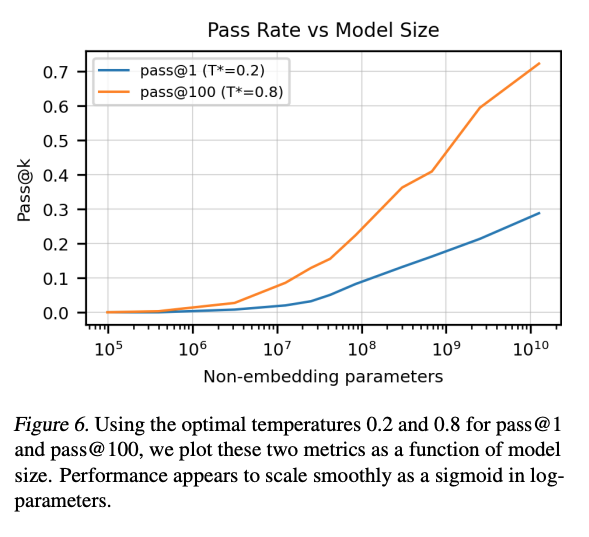
对于pass@1和pass@100,最好的T分别是0.2和0.8;在对应的最好的T下,这两个的通过率随着模型大小的变化,曲线是比较平滑的。
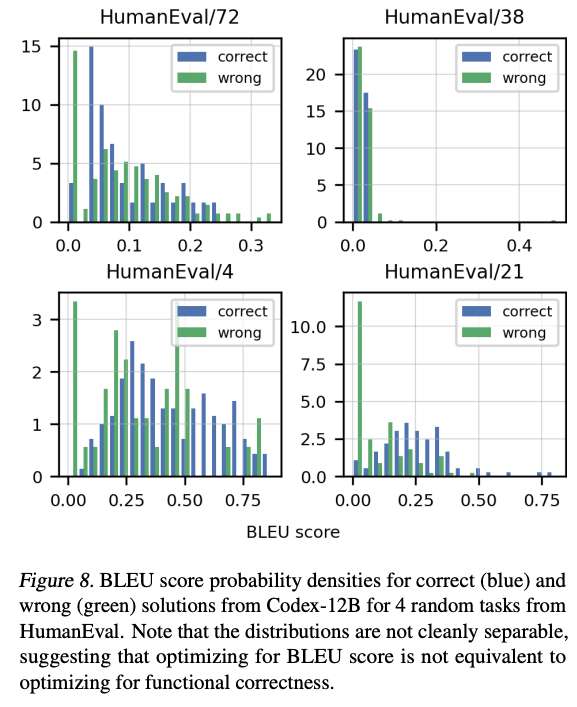
BLEU 得分情况:

















 2986
2986











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











