







0. 概览
不同的框架支持不同的模型保存格式,以下是一些常见的格式:
1.TensorFlow格式
(1)SavedModel:TensorFlow 的一种模型保存格式,它不仅保存模型的权重,还包括计算图和签名定义,使得模型可以用于预测、导出或进一步训练。
在使用 TensorFlow Serving 时,会用到这种格式的模型。该格式为 GraphDef 和 CheckPoint 的结合体,另外还有标记模型输入和输出参数的 SignatureDef。从 SavedModel 中可以提取 GraphDef 和 CheckPoint 对象。
SavedModel 目录结构如下:
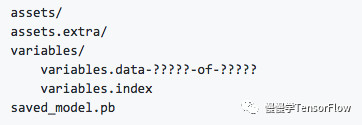
其中 saved_model.pb(或 saved_model.pbtxt)包含使用 MetaGraphDef protobuf 对象定义的计算图;assets 包含附加文件;variables 目录包含 tf.train.Saver() 对象调用 save() API 生成的文件。
以下代码实现了保存 SavedModel:

载入 SavedModel:
更多细节可以参考 tensorflow/python/saved_model/README.md。
(2)Checkpoint:TensorFlow 的检查点格式,主要用于保存和恢复模型的权重和优化器状态,便于训练过程中的中断和继续。
在训练 TensorFlow 模型时,每迭代若干轮需要保存一次权值到磁盘,称为“checkpoint”,如下图所示:
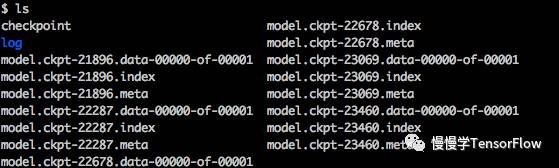
这种格式文件是由 tf.train.Saver() 对象调用 saver.save() 生成的,只包含若干 Variables 对象序列化后的数据,不包含图结构,所以只给 checkpoint 模型不提供代码是无法重新构建计算图的。
载入 checkpoint 时,调用 saver.restore(session, checkpoint_path)。
TensorFlow PB模型是指使用TensorFlow框架训练得到的模型,并以.pb文件格式保存。这种模型文件包含了模型的结构定义、权重参数以及其他必要的信息,可以在不需要源代码的情况下进行推断和部署。由于.pb模型文件具有轻量级和高效性的特点,因此在实际应用中得到了广泛的应用。
这种格式文件包含 protobuf 对象序列化后的数据,包含了计算图,可以从中得到所有运算符(operators)的细节,也包含张量(tensors)和 Variables 定义,但不包含 Variable 的值,因此只能从中恢复计算图,但一些训练的权值仍需要从 checkpoint 中恢复。下面代码实现了利用 *.pb 文件构建计算图:
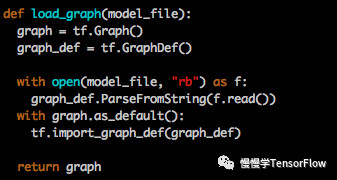
TensorFlow 一些例程中用到 *.pb 文件作为预训练模型,这和上面 GraphDef 格式稍有不同,属于冻结(Frozen)后的 GraphDef 文件,简称 FrozenGraphDef 格式。这种文件格式不包含 Variables 节点。将 GraphDef 中所有 Variable 节点转换为常量(其值从 checkpoint 获取),就变为 FrozenGraphDef 格式。代码可以参考 tensorflow/python/tools/freeze_graph.py
*.pb 为二进制文件,实际上 protobuf 也支持文本格式(*.pbtxt),但包含权值时文本格式会占用大量磁盘空间,一般不用。
2. PyTorch 格式
(1).pth 或 .pt:PyTorch 的标准模型保存格式,用于保存模型的权重和结构。
(2).bin:另一种用于保存模型权重的二进制格式,通常与模型结构定义一起使用。
(3).jit:PyTorch 的 TorchScript 格式,用于保存经过优化的模型,可以用于不依赖Python环境的部署。
3. ONNX (Open Neural Network Exchange)
(1).onnx:一种开放的格式,用于表示深度学习模型,允许模型在不同的深度学习框架之间进行转换和部署。
4. Hugging Face Transformers
(1).bin 和 .index:Hugging Face 提供的模型通常以 .bin 和 .index 文件形式保存,这些文件包含了模型的权重和配置信息。
(2).safetensors:Hugging Face 也支持 .safetensors 格式,这是一种更安全的模型保存格式,避免了潜在的恶意代码执行。
5. Other Formats
(1)JSON/YAML:有时模型的配置信息会以文本格式保存,如JSON或YAML文件,便于阅读和编辑。
(2)Protocol Buffers:Google 的一种数据序列化格式,有时用于保存模型元数据或配置。
6 .safetensors 格式
.safetensors 格式确保安全性的主要方式是通过限制文件内容,防止执行潜在的恶意代码。以下是 .safetensors 如何实现这一点的几个关键方面:
-
仅存储权重数据
.safetensors文件格式专门设计用来存储模型的权重数据,而不包含任何可执行代码。这意味着文件中不包含用于加载或操作模型的代码,从而降低了执行恶意代码的风险。 -
禁止元数据执行
在一些其他格式中,如.pt(PyTorch) 或.h5(HDF5),模型文件可能包含可执行的元数据或脚本。.safetensors格式明确禁止这种做法,确保文件中不包含任何可执行的元数据。 -
明确的文件结构
.safetensors文件具有明确的结构,其中权重数据以键值对的形式存储。这种结构易于解析,但不支持执行任何代码。 -
开源和透明性
.safetensors是开源的,这意味着任何人都可以审查其代码和文件格式,确保没有隐藏的漏洞或后门。 -
不支持自定义扩展
与一些其他格式不同,.safetensors不支持自定义扩展或添加额外的、可能不安全的组件。 -
限制文件操作
.safetensors格式的设计避免了复杂的文件操作,如动态加载库或执行外部命令,这些操作在其他格式中可能被利用来执行恶意代码。 -
易于验证和检查
由于.safetensors文件的结构简单明了,用户可以轻松地使用文本编辑器或专用工具检查文件内容,确保没有不期望的数据。
7.gguf - 高效本地推理格式
- 开发方:由
llama.cpp项目引入,专为高效推理设计 - 设计目标:优化本地推理性能
- 特色功能:支持多种量化方案(如 4-bit、8-bit)
- 优势:
- 高效推理:专为 CPU 和 GPU 混合推理设计。
- 内容:单个文件包含模型的所有权重和配置信息。
- 跨平台:适合在资源受限设备(如 Apple Silicon)上运行。
- 边缘设备部署
- 资源受限环境
- 需要量化优化的场景
Ollama使用的就是这种数据格式
为什么GGUF格式对大模型文件性能很好
GGUF文件格式能够更快载入模型的原因主要归结于以下几个关键特性:
-
二进制格式:GGUF作为一种二进制格式,相较于文本格式的文件,可以更快地被读取和解析。二进制文件通常更紧凑,减少了读取和解析时所需的I/O操作和处理时间。
-
优化的数据结构:GGUF可能采用了特别优化的数据结构,这些结构为快速访问和加载模型数据提供了支持。例如,数据可能按照内存加载的需要进行组织,以减少加载时的处理。
-
内存映射(mmap)兼容性:GGUF支持内存映射(mmap),这允许直接从磁盘映射数据到内存地址空间,从而加快了数据的加载速度。这样,数据可以在不实际加载整个文件的情况下被访问,特别是对于大模型非常有效。
-
高效的序列化和反序列化:GGUF使用高效的序列化和反序列化方法,这意味着模型数据可以快速转换为可用的格式。
-
少量的依赖和外部引用:如果GGUF格式设计为自包含,即所有需要的信息都存储在单个文件中,这将减少解析和加载模型时所需的外部文件查找和读取操作。
-
数据压缩:GGUF格式采用了有效的数据压缩技术,减少了文件大小,从而加速了读取过程。
-
优化的索引和访问机制:文件中数据的索引和访问机制经过优化,使得查找和加载所需的特定数据片段更加迅速。
总之,GGUF通过各种优化手段实现了快速的模型加载,这对于需要频繁载入不同模型的场景尤为重要。
GGUF文件结构
一个GGUF文件包括文件头、元数据键值对和张量信息等。这些组成部分共同定义了模型的结构和行为。具体如下所示:

同时,GGUF支持多种数据类型,如整数、浮点数和字符串等。这些数据类型用于定义模型的不同方面,如结构、大小和参数。
GGUF文件具体的组成信息如下所示:
文件头 (Header)
-
作用:包含用于识别文件类型和版本的基本信息。
-
内容:
-
Magic Number:一个特定的数字或字符序列,用于标识文件格式。 -
Version:文件格式的版本号,指明了文件遵循的具体规范或标准。
元数据key-value对 (Metadata Key-Value Pairs)
-
作用:存储关于模型的额外信息,如作者、训练信息、模型描述等。
-
内容:
-
Key:一个字符串,标识元数据的名称。 -
Value Type:数据类型,指明值的格式(如整数、浮点数、字符串等)。 -
Value:具体的元数据内容。
张量计数器 (Tensor Count)
-
作用:标识文件中包含的张量(Tensor)数量。
-
内容:
-
Count:一个整数,表示文件中张量的总数。
张量信息 (Tensor Info)
-
作用:描述每个张量的具体信息,包括形状、类型和数据位置。
-
内容:
-
Name:张量的名称。 -
Dimensions:张量的维度信息。 -
Type:张量数据的类型(如:浮点数、整数等)。 -
Offset:指明张量数据在文件中的位置。
对齐填充 (Alignment Padding)
-
作用:确保数据块在内存中正确对齐,有助于提高访问效率。
-
内容:
-
通常是一些填充字节,用于保证后续数据的内存对齐。
张量数据 (Tensor Data)
-
作用:存储模型的实际权重和参数。
-
内容:
-
Binary Data:模型的权重和参数的二进制表示。
端序标识 (Endianness)
-
作用:指示文件中数值数据的字节顺序(大端或小端)。
-
内容:
-
通常是一个标记,表明文件遵循的端序。
扩展信息 (Extension Information)
-
作用:允许文件格式未来扩展,以包含新的数据类型或结构。
-
内容:
-
可以是新加入的任何额外信息,为将来的格式升级预留空间。
在张量信息部分,GGUF定义了模型的量化级别。量化级别取决于模型根据质量和准确性定义的值(ggml_type)。在 GGUF 规范中,值列表如下:
| 类型 | 来源 | 描述 |
|---|---|---|
| F64 | Wikipedia | 64 位标准 IEEE 754 双精度浮点数。 |
| I64 | GH | 64 位整数。 |
| F32 | Wikipedia | 32 位标准 IEEE 754 单精度浮点数。 |
| I32 | GH | 32 位整数。 |
| F16 | Wikipedia | 16 位标准 IEEE 754 半精度浮点数。 |
| BF16 | Wikipedia | 32 位 IEEE 754 单精度浮点数的 16 位缩短版本。 |
| I16 | GH | 16 位整数。 |
| Q8_0 | GH | 8 位 RTN 量化 (q). 每个块有 32 个权重。权重公式: w = q * block_scale. 传统的量化方法(目前尚未广泛使用)。 |
| Q8_1 | GH | 8 位 RTN 量化 (q). 每个块有 32 个权重。权重公式: w = q * block_scale + block_minimum. 传统的量化方法(目前尚未广泛使用)。 |
| Q8_K | GH | 8 位量化(q). 每个块有 256 个权重。仅用于量化中间结果。所有 2-6 位点积都是为此量化类型实现的。权重公式: w = q * block_scale. |
| I8 | GH | 8 位整数。 |
| Q6_K | GH | 6 位量化 (q). 超级块有 16 个块,每个块有 16 个权重。权重公式: w = q * block_scale(8-bit),得出每个权重 6.5625 位。 |
| Q5_0 | GH | 5 位 RTN 量化 (q). 每个块有 32 个权重。权重公式: w = q * block_scale. 传统的量化方法(目前尚未广泛使用)。 |
| Q5_1 | GH | 5 位 RTN 量化 (q). 每个块有 32 个权重。权重公式: w = q * block_scale + block_minimum. 传统的量化方法(目前尚未广泛使用)。 |
| Q5_K | GH | 5 位量化 (q). 超级块有8个块,每个块有32个权重。权重公式: w = q * block_scale(6-bit) + block_min(6-bit),得出每个权重 5.5 位。 |
| Q4_0 | GH | 4 位 RTN 量化 (q). 每个块有 32 个权重。权重公式: w = q * block_scale. 传统的量化方法(目前尚未广泛使用)。 |
| Q4_1 | GH | 4 位 RTN 量化 (q). 每个块有 32 个权重。权重公式:w = q * block_scale + block_minimum. 传统的量化方法(目前尚未广泛使用)。 |
| Q4_K | GH | 4 位量化 (q). 超级块有8个块,每个块有32个权重。权重公式: w = q * block_scale(6-bit) + block_min(6-bit) ,得出每个权重 4.5 位。 |
| Q3_K | GH | 3 位量化 (q). 超级块有 16 个块,每个块有 16 个权重。权重公式: w = q * block_scale(6-bit), 得出每个权重3.4375 位。 |
| Q2_K | GH | 2 位量化 (q). 超级块有 16 个块,每个块有 16 个权重。权重公式: w = q * block_scale(4-bit) + block_min(4-bit),得出每个权重 2.5625 位。 |
| IQ4_NL | GH | 4 位量化 (q). 超级块有 256 个权重的。权重w是使用super_block_scale和importance matrix获得的。 |
| IQ4_XS | HF | 4 位量化 (q). 超级块有 256 个权重的。具有 256 个权重的超级块。权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 4.25 位。 |
| IQ3_S | HF | 3 位量化 (q). 超级块有 256 个权重的。权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 3.44 位。 |
| IQ3_XXS | HF | 3 位量化 (q). 超级块有 256 个权重的。权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 3.06 位。 |
| IQ2_XXS | HF | 2 位量化 (q). 超级块有 256 个权重的。权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 2.06 位。 |
| IQ2_S | HF | 2 位量化 (q). 超级块有 256 个权重的。权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 2.5 位。 |
| IQ2_XS | HF | 2 位量化 (q). 超级块有 256 个权重的。权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 2.31 位。 |
| IQ1_S | HF | 1 位量化 (q). 超级块有 256 个权重的。权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 1.56 位。 |
| IQ1_M | GH | 1 位量化 (q). 超级块有 256 个权重的。权重w是使用super_block_scale和importance matrix获得的,结果是每个权重 1.75 位。 |

















 3952
3952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









