







参考:
【迁移学习】Domain Adaptation系列论文解析(不断更新中) - 知乎
transfer learning 和 cross domain 有怎样的联系? - 知乎
cross-domain detection:
*******************重磅*******************
awesome-domain-adaptation-object-detection papers with code:
https://github.com/wangs311/awesome-domain-adaptation-object-detection
---------------------------------------------------------------------------------------------------------------------------------
参考:
Domain adaptation 与 Domain generalization_笙久拥的博客-CSDN博客
Cross Domain,Domain Adaptation,Domain Generalization概念的解释_BBBBBAAAAAi的博客-CSDN博客
Understanding Transfer Learning (B) - 知乎
Cross Domain,Domain Adaptation,Domain Generalization概念的解释_BBBBBAAAAAi的博客-CSDN博客迁移学习与跨域推荐,以及解决跨域推荐的方法 - 知乎Cross Domain,Domain Adaptation,Domain Generalization概念的解释_BBBBBAAAAAi的博客-CSDN博客
1 概念
Domain Adaptation(DA) 是一种将源任务和目标任务一样,但源域和目标域的数据分布不一样,并且源域有大量的标记样本,目标域则没有(或很少)标记样本的迁移学习方法。
Domain Generalization (DG) 主要做的就是通过多个标注好的源域数据,学习一个通用的特征表示,并希望该表示也能应用于未见过的相似样本,即目标域数据,即使目标域一个数据都没有。
解决OOD(Generalization to out-of-distribution)问题的一个最直接的方法就是搜集一些目标域的数据去适应源域上训练的模型,于是催生一个新任务DA,即域适应。然而,DA任务的一个假设是目标域的数据是能够获取到的,但有些情景下无法满足。因此,DG任务被引入来解决这种情景。由于不能接触目标域数据,且要在目标域数据有效,DG任务可以说是机器学习领域最难解决的问题之一。
在经典的机器学习中,当 源域 和 目标域 数据分布不同,但是两者的任务相同时,这种 特殊 的迁移学习就是域自适应(Domain Adaptation)。上面含义若看不太懂,简要解释如下:我们一般都是假设训练集和测试集分布一致,但是在实际中,训练集和测试集其实分布会有差异,因为测试场景非可控,因此存在测试集和训练集分布有很大差异的情况,这时候训练好的模型在测试集上效果却不理想,为解决这样的问题,出现了迁移学习。 简单举例来说:我们熟知的人脸识别,如果用东方人人像来训练,最后用于识别西方人,那当然性能会明显下降。
DA与DG比较:
- DA不够高效,每来一个新域,都需要重复进行适应,而DG只需训练一次;
- DA的性能比DG的性能要高,由于使用了目标域的数据;
- DA的强假设是目标域的数据是可用的,显然有些情况是无法满足的,或者代价昂贵。
- DA关注如何利用无标注的目标数据,而DG主要关注泛化性
在迁移学习(Transfer Learning)任务里面,迁移算法能够利用在源域(Source Domain)学习到的知识辅助目标域(Target Domain)的模型的建立。在非深度迁移(Shallow Transfer Learning)领域,以基于样本的迁移(Instance-based)、基于特征的迁移(Feature-based)为主;在深度迁移(Deep Transfer Learning)领域,以基于对抗网络的迁移(Adversarial Domain Adaptation)技术为主。
基于样本的迁移主要是给源域样本赋予一个权重,使得加权(Instance Re-weighting)或者重采样(Importance Sampling)之后的源域样本和目标域样本的分布对齐,比如KMM、KLIEP、TrAdaboost等等;基于特征的迁移主要是基于子空间(Subspace)的方法,目的是寻找一个合适的映射矩阵使得源域和目标域在子空间里面的距离最小,比如SA、TCA等等。
无论是哪种迁移算法,出发点都有两个:第一,减小源域和目标域的距离,对齐数据分布;第二,保证分类算法在源域和目标域(如果目标域有标记)上的性能不会下降太多。
迁移学习中有两个很重要的概念:域(domain)和任务(Task)。
域:数据特征和特征分布组成,是学习的主体
- 源域 (Source domain):已有知识的域
- 目标域 (Target domain):要进行学习的域
任务:由目标函数和学习结果组成,是学习的结果
域的不同有两种可能的场景:
- 特征空间不同
例如文本分类任务中,中文文本和英文文本的特征空间不同
图像识别任务中,人脸图片和鸟类图片的特征空间不同 - 边缘概率分布不同
例如文本分类任务中,文本都是中文语言的特征空间,但讨论的是不同的主题,如政治和娱乐
图片识别任务中,图片都是鸟类的特征空间,但一个是在城市中拍到的鸟,一个是在大自然中拍到的
任务的不同也有两种可能的场景:
- 标签空间不同
例如在文本分类任务中,一个标签是新闻类别标签,一个标签是文本情感标签;
人脸识别任务中,一个标签是性别,一个标签是人名。 - 条件概率不同
例如源和目标数据类别分布不均衡。这种情况非常普遍,可用过采样(over-sampling)、欠采样(under-sampling)、SMOTE 等方法进行处理。
一般标签不同,条件概率分布也会不同,因为很少会出现两个不同的任务有不同的标签空间而条件概率分布完全相同的情况。
也有论文将域(domain)和 任务(task)合二为一称之为一个 dataset,cross-dataset 指的就是 domain 或者 task 不同
1.4 迁移学习分类
按特征空间分
- 同构迁移学习(Homogeneous TL): 源域和目标域的特征空间相同
- 异构迁移学习(Heterogeneous TL):源域和目标域的特征空间不同
按迁移情景分

参考上图,根据所使用的传统机器学习算法,迁移学习方法可分类为:
- 归纳式迁移学习(Inductive Transfer learning):在该场景中,源域和目标域相同,但源任务和目标任务彼此不同。算法尝试利用来自源域的归纳偏差帮助改进目标任务。根据源域中是否包含标记数据,归纳式迁移学习可以进一步分为类似于**多任务学习(Multi-task Learning)和自学习(Self-taught Learning)**这两类方法
- 直推式迁移学习(Transductive Transfer Learning):源域和目标域不同,学习任务相同。在该场景中,源任务和目标任务之间存在一些相似之处,但相应的域不同。通常源域具有大量标记数据,而目标域没有。根据特征空间或边缘概率的设置不同,直推式迁移学习可进一步分类为多个子类
- 无监督迁移学习(Unsupervised Transfer Learning):源域和目标域均没有标签。该场景类似于归纳式迁移学习,重点关注目标域中的无监督任务
下表总结了上述迁移学习策略在不同场景和领域下的对比:

按迁移内容来分:
- 基于样本的迁移学习(Instance transfer):通常,理想场景是源域中的知识可重用到目标任务。但是在大多数情况下,源域数据是不能直接重用的。然而,源域中的某些实例是可以与目标数据一起重用,达到改善结果的目的。对于归纳式迁移,已有一些研究利用来自源域的训练实例来改进目标任务,例如 Dai 及其合作研究者对 AdaBoost 的改进工作
- 基于特征表示的迁移学习(Feature-representation transfer): 该类方法旨在通过识别可以从源域应用于目标域的良好特征表示,实现域差异最小化,并降低错误率。根据标记数据的可用性情况,基于特征表示的迁移可采用有监督学习或无监督学习
- 基于参数的迁移学习(Parameter transfer): 该类方法基于如下假设:针对相关任务的模型间共享部分参数,或超参数的先验分布。不同于同时学习源和目标任务的多任务学习,在迁移学习中我们可以对目标域的应用额外的权重以提高整体性能
- 基于关系知识的迁移学习(Relational-knowledge transfer): 与前面三类方法不同,基于关系知识的迁移意在处理非独立同分布(i.i.d)数据即每个数据点均与其他数据点存在关联。例如,社交网络数据就需要采用基于关系知识的迁移学习技术
下表清晰地总结了不同迁移内容分类和不同迁移学习策略间关系:

OK上边的便是关于迁移学习的介绍了,相信你读完之后会有自己的理解!
2 解决方法
参考:
Domain adaptation 与 Domain generalization_笙久拥的博客-CSDN博客
Understanding Transfer Learning (A) - 知乎
2.1 Shallow DA
样本自适应 Instance adaptation :对源数据每一个样本加权,学习一组权重使得分布差异最小化,然后重新采样,从而逼近目标域的分布。源域总有一部分数据类似于目标域,找到那部分数据就可以了,越像的数据,给的权重就越大。
特征自适应 Feature adaptation:将源域和目标域投影到公共特征子空间,这样两者的分布相匹配,通过学习公共的特征表示,这样在公共特征空间,源域和目标域的分布就会相同。将源域和目标域提取到一个共同的特征空间中,使他们之间足够近,足够对齐,目标域的性能就可以提升。
模型自适应 Model adaptation:考虑目标域的误差,对源域误差函数进行修改。假设利用上千万的数据来训练好一个模型,当我们遇到一个新的数据领域问题的时候,就不用再重新去找几千万个数据来训练,只需把原来训练好的模型迁移到新的领域,在新的领域往往只需相对较少的数据就同样可以得到很高的精度。实现的原理则是利用模型之间存在的相似性。
以下是三种自适应的公式表达
本节介绍一些传统的迁移算法,有的只是列出优化目标,并不会详细进行推导,主要是一个梳理工作,大概包括以下算法(按发表时间排序):
- KMM(NeurIPS 2006)
- KLIEP(NeurIPS 2007)
- MMDE(AAAI 2008)
- TCA(IJCAI 2009)
- GFK(CVPR 2012)
- ITL(ICML 2012)
- MSDA(ICML 2012)
- SA(ICCV 2013)
- GTL(TKDE 2014)
- CORAL(AAAI 2016)
- LSDT(TIP 2016)
更加详细内容参考:
Understanding Transfer Learning (A) - 知乎
方法1:特征的适应,Feature adaptation
feature adaptation:将源域和目标域的特征提取到一个共同的特征空间里,在这个空间中源域和目标域的距离足够的近,二者足够的对齐,这样目标域的性能就会提升,上面SVHN-MNIST。
方法2:实例的适应,Instance adaptation
源域有部分数据和目标域比较像,对于越像的数据,给的权重越大,使用这些数据训练出来的模型在目标域上的效果就会比较好。
方法3模型的适应,Model adaptation
找到一些参数进行迁移,使得目标域的性能得到提升
上面三种都是非深度的迁移学习?。
————————————————
原文链接:https://blog.csdn.net/lh16130130282/article/details/128046481
2.2 Deep Domain Adaptation
参考:
【迁移学习】Domain Adaptation系列论文解析(不断更新中) - 知乎
Understanding Transfer Learning (B) - 知乎
代表性工作有很多,比如DDC、DAN、DANN(RevGrad)、ADDA、CADA等等。关于深度迁移学习,推荐一篇综述文章:Neurocomputing 2018的《Deep visual domain adaptation: A survey》
https://arxiv.org/pdf/1802.03601.pdf
上述文献综述中将DA方法主要分为
- (1)One-step DA
- (2)Multi-step DA
其主要区别体现在:
- (1)One-step DA是假设源域(source domain)和目标域(target domain)是相关的,但是可能域分布存在一些差异,需要通过调整域间的分布(一步)实现域适应;
- (2)Multi-step DA是假设源域(source domain)和目标域(target domain)是无关的(更符合现实)。该类方法主要通过在源域和目标域之间建立一些桥梁(中间域),(多步)实现域适应。
作者将该One-step DA按下表进行分类

- (1)Discrepancy-based;这类方法主要利用微调网络参数降低域偏移(domain shift)。
- (2)Adversarial-based;这类方法引入了判别器,并引入对抗损失来使得源域和目标域使得域判别器难以分辨(也就是混淆域判别器),那么源域和目标域就靠的足够近了。
- (3)Reconstruction-based;这类方法为了保证域适应过程中图片信息的完整性,通常将数据重建(保证重建误差最小)作为域适应过程中另一辅助任务。
同样,作者将Multi-step DA也进行了分类,具体如下:

更加详细内容参考:
【迁移学习】Domain Adaptation系列论文解析(不断更新中) - 知乎
https://arxiv.org/pdf/1802.03601.pdf
参考:Domain adaptation 与 Domain generalization_笙久拥的博客-CSDN博客
2.2.1 关于Fine-tune的一个实验 (Supervised)
2.2.1.1 实验操作
使用Dataset A,在一个固定的网络结构上进行训练得到model A(下图第一行绿色)
再使用Dataset B,在相同的网络结构上训练得到model B(下图第二行紫色)。
固定model B的前3层,在Dataset B上训练得到B3B(下图第三行上半部分),不固定model B的前3层,在Dataset B上训练得到B3B+(下图第三行下半部分)
同理固定/不固定model A的前三层,在Dataset B上训练得到A3B/A3B+(下图第四行)。
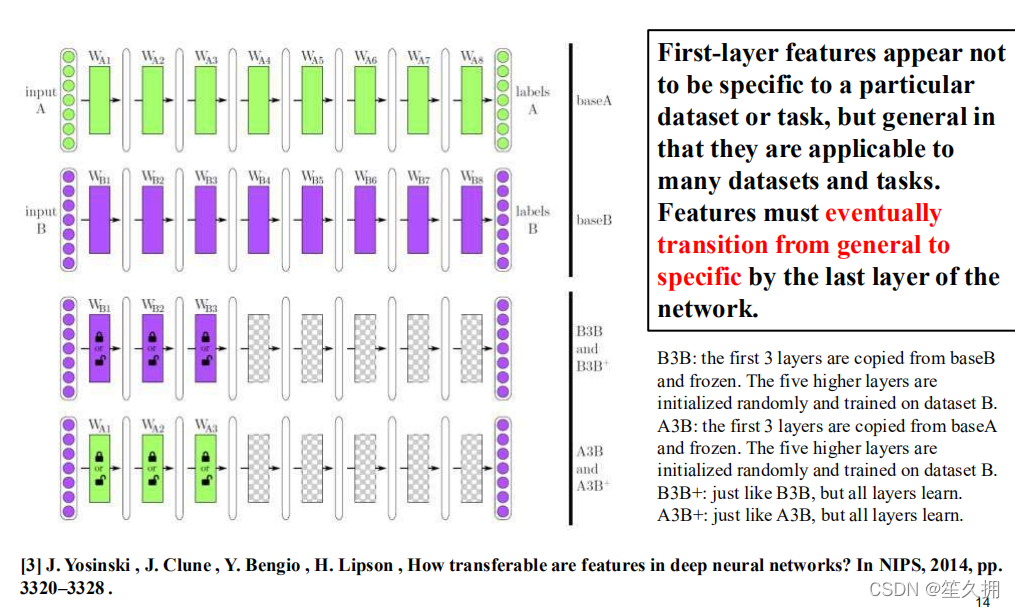
《How transferable are features in deep neural networks?》:https://arxiv.org/abs/1411.1792
2.2.1.2 实验现象解释
对于BnB(2)而言,原来训练好的B模型的前两层直接拿来就可以用,而且不需要调整,不会对精度造成影响。从3层开始有点下降,到了第4~5层,模型精度开始下降,然而到了6-7层,模型精度又奇迹般地回升了!这是为什么呢?
作者说明如下:对于一开始精度下降的4~ 5层,确实是到了这一步,feature变得specific了,但是都是从B数据训练来的,就算4~ 5层的特征specific,那不也是数据B的特征吗?为什么会下降呢?作者认为:**中间连续层之间存在一定的相互适应调整关系,这种关系是复杂而又脆弱的,这种关系不能够仅仅通过上层学习到,所以在3层开始,我们固定底层,导致网络无法进行上下之间的相互适应调整,使得3层之后的层无法进行很好地协调而学习到相对于task很specific的特征,使得精度开始下降。**而到了6~7层,精度又回升了,这是因为网络一共就8层,你把6层都固定住了,基本上整个特征学习也被固定住了,因此精度和原来的B不会相差太多。因此作者认为:神经网络中间特征层的连续协调关系要强于最顶和最下层的,这是之前文献所没有注意到的。
对于BnB+来说(3),模型精度没有什么变化,说明finetune对模型没有损失,并且训练时间还可减少,对训练有促进作用。
对AnB来说,直接将网络的前两层迁移到B,固定住,貌似对精度不会有什么影响,这说明AlexNet的前两层学习的特征是很基础,很泛化的,因此可以直接从A迁移到B而不损失精度。到了4~ 5层,精度开始大幅下降,而到了6~ 7层,精度出现小小上升然后又下降,这是为什么呢?根据BnB的结论,我们认为这种下降由两个因素导致:1)中间层之间具有相互适应协调的依赖关系。 2)特征太specific了,导致迁移到B上特征不适用
再看AnB+,加入了finetune之后的模型,在任何时候表现都很好,甚至比base B的表现还好,这又一次说明finetune对模型有很好的促进作用!
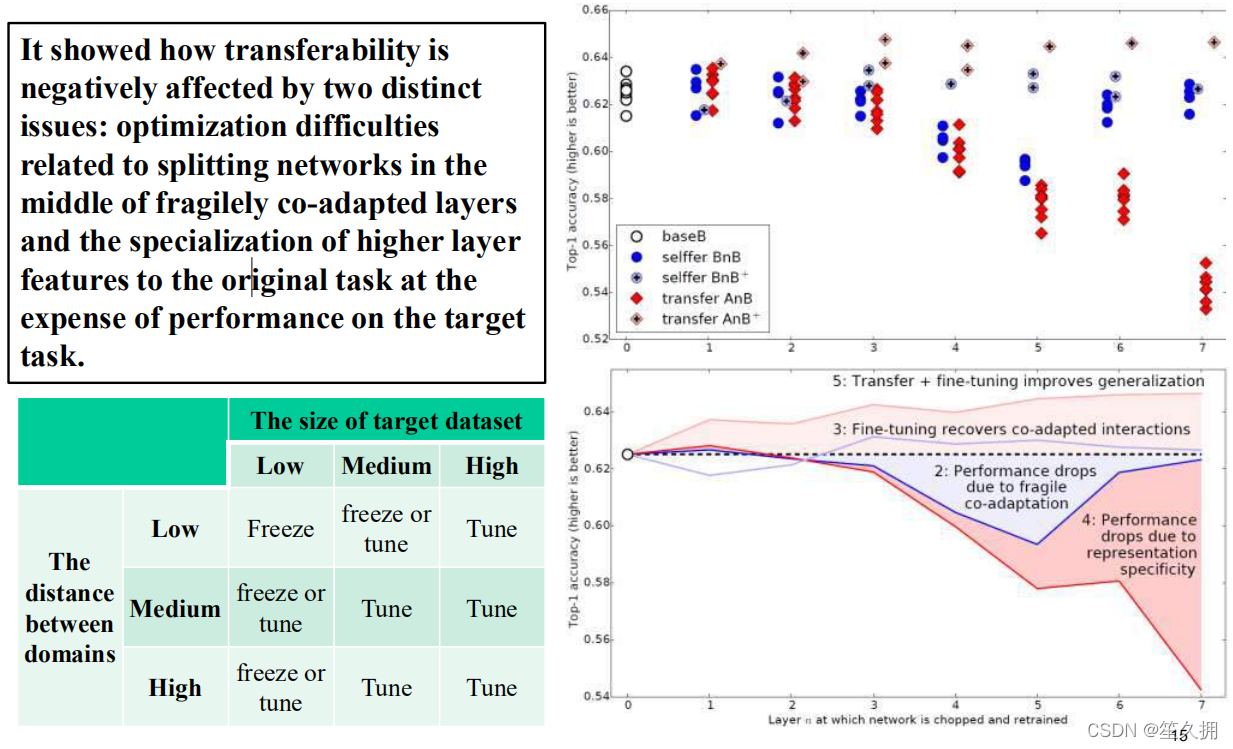
2.2.1.3 实验结果
神经网络的前3层基本都是general feature,进行迁移的效果会比较好;
深度迁移网络中加入fine-tune,效果会提升比较大,可能会比原网络效果还好;
Fine-tune可以比较好地克服数据之间的差异性;
深度迁移网络要比随机初始化权重效果好;
网络层数的迁移可以加速网络的学习和优化。
2.2.2 Discrepancy-based DA (Unsupervised)
无监督域适应的大体思路:源域和目标域之间存在一定的距离,在数学公式中找到一个能很好的衡量两个域之间距离的度量公式(特征上),然后就将这种距离数字化了,数字化后就可以作为网络中的loss,然后让深度网络优化这个loss,让距离逐渐变小(很重要的思路).
衡量两个domain之间的相似性

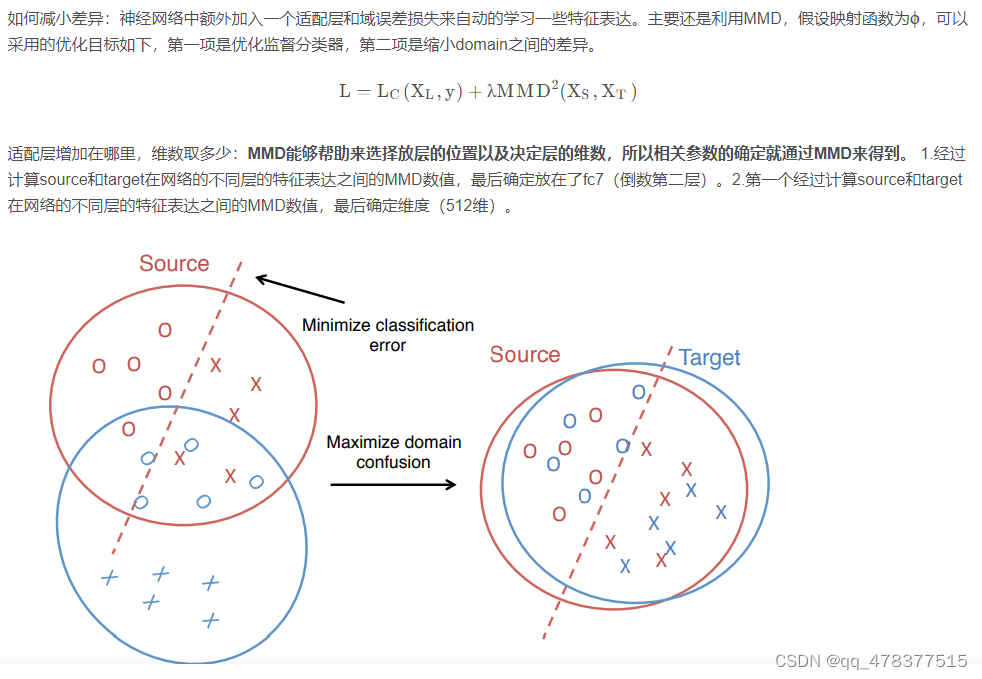
2.2.2.1 DDC (Deep Domain Confusion)(可以参考下面对DDC和DAN的公式介绍,有助于理解)
问题:两类数据的分布不同,source训练好的分类器在target不一定适用
解决方案:在训练的时候能够同时减小source和target分布的差异,来让网络学习到更有迁移性的特征。
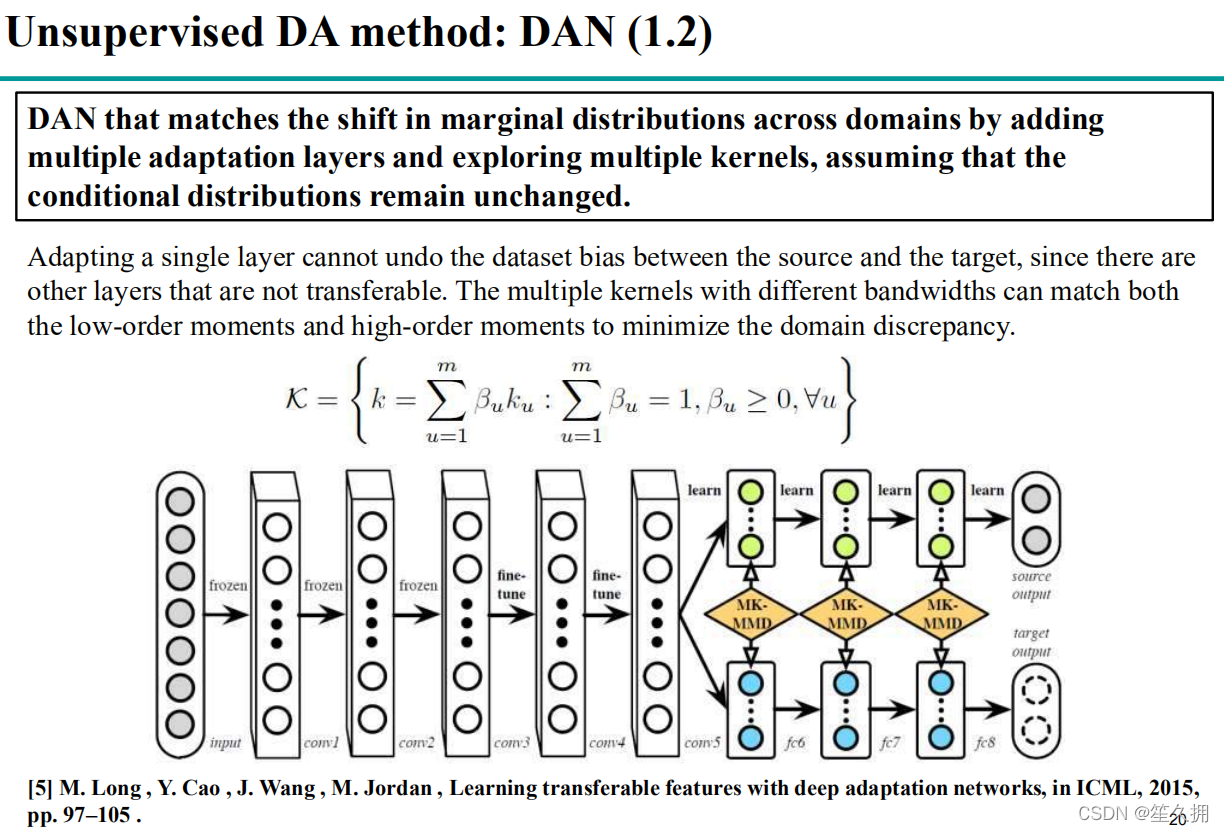
2.2.2.2 DAN (可以参考下面对DDC和DAN的公式介绍,有助于理解)
在DDC的基础上进行了改进:
1) 多个全连接层(最后三层)算domain之间的MMD loss以降低domain之间的差异。
2) 网络浅层进行特征映射的时候,使用更加复杂的高斯核的组合MMD(多核MMD)。具体实现中采用了多核MMD,根据核技巧和多核的无偏估计,能够将复杂度变成O(n),且可以正常使用SGD的方式来优化
2.2.3 Adversarial-based DA (Unsupervised, 参考下面的有助于理解--李宏毅机器学习——领域适应Domain Adaptation or 李宏毅机器学习——领域适应Domain Adaptation_iwill323的博客-CSDN博客)
2.2.3.1 DANN( Domain Adversarial Neural Network ,又称 RevGrad 2016)
解决方案:针对无监督域的自适应,提取出源域和目标域同分布的特征(绿色部分),在特征上学习分类(蓝色)。方法是利用对抗学习的思想迫使提取的特征同分布(粉色部分),而且满足分类要求。
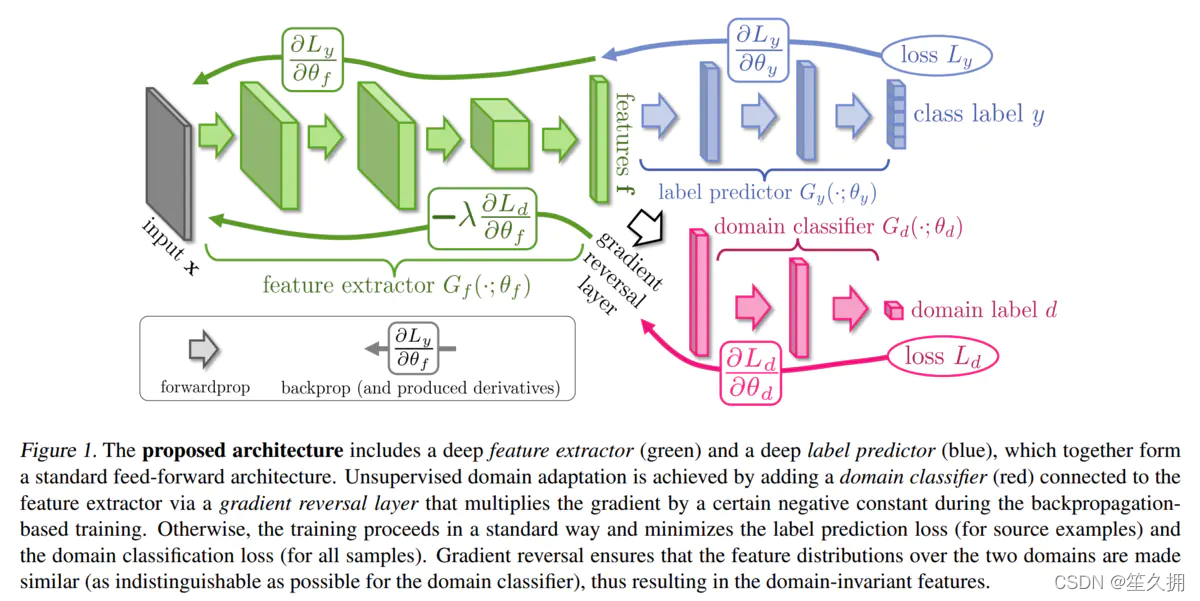
目标函数:提取的特征满足两个要求:1)可以分类,所以该特征可以使得分类器分类损失最小;2)源域目标域特征同分布,这要求判别器难以判别样本来自哪个域,需要最大化判别器的损失。这两个损失要求相反,那就增加一个梯度反转层来实现域判别器梯度的反转。

特征可视化结果:

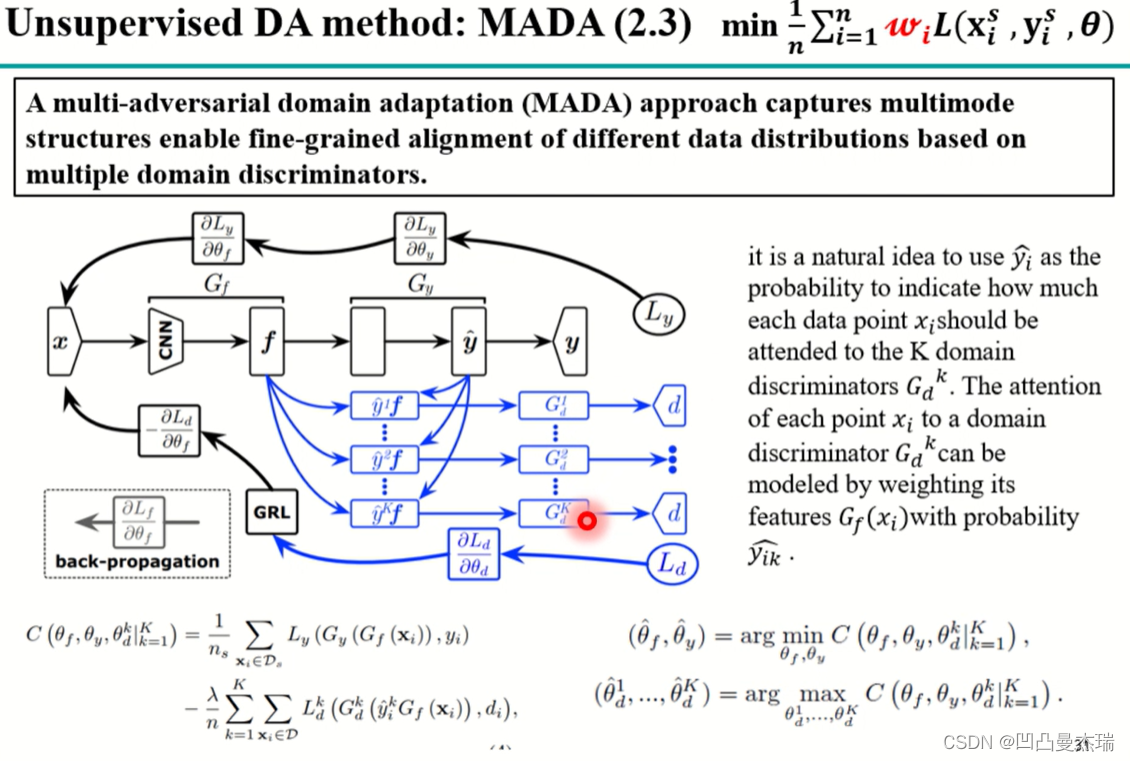
2.2.3.2 MADA
问题:目标域是源域的子集,无法直接进行聚类。
解决方案:应该精细到类别与类别的对齐。只在网络最后一层加判别器,但是是有多个判别器,每一个判别器对应一个子类
网络介绍:看蓝色箭头部分:目标域进入到源域的分类器中得到分类概率,这个分类概率对目标域的feature进行加权,实现语义信息的对齐。举个栗子:如果target域的一幅图像经过之前训练好的源域的网络中,网络会对它所属类别进行归类。=> 引入语义的对齐

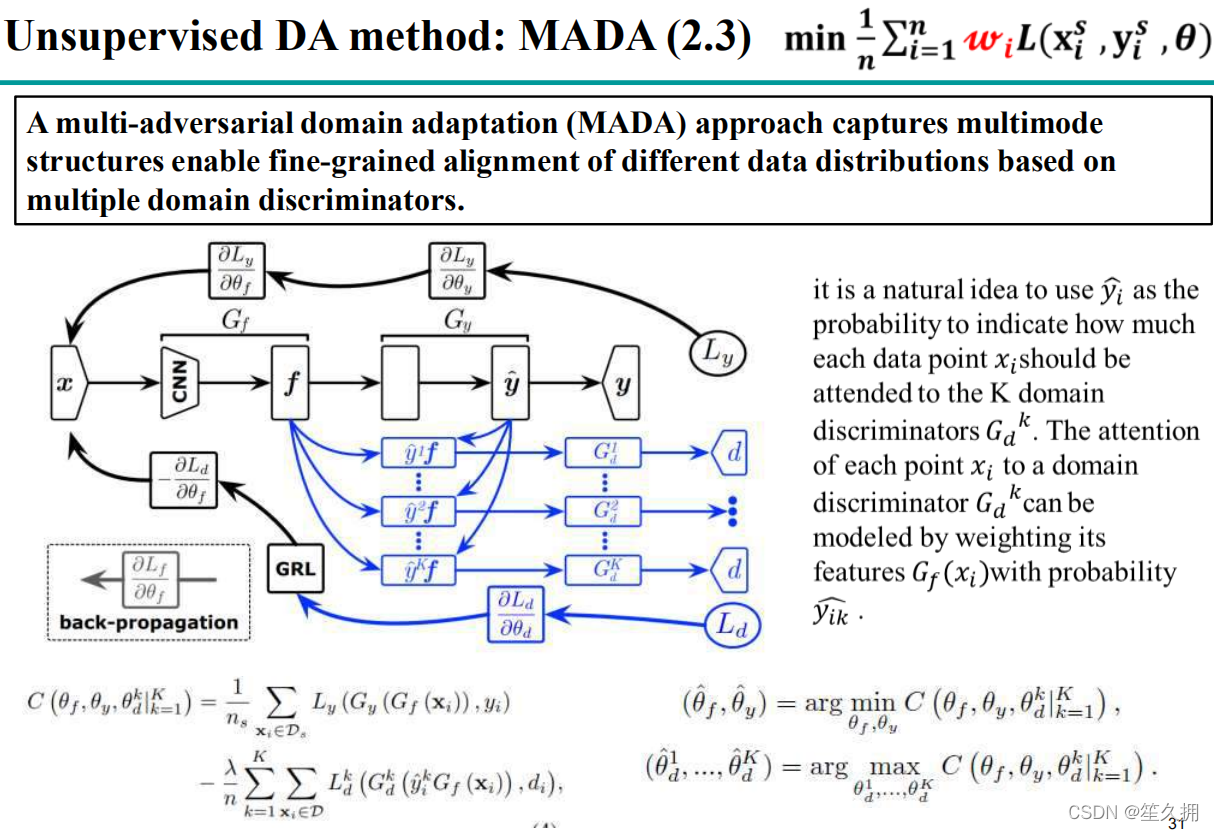
2.2.3.3 Weighted Adversarial Nets
2.2.3 Reconstruction-based DA
参考:
深度域适应技术综述_域适应综述_凹凸曼杰瑞的博客-CSDN博客
Deep visual domain adaptation: A survey_深度域混淆_Wanderer001的博客-CSDN博客
Deep Reconstruction-Classification Networks for Unsupervised Domain Adaptation: https://arxiv.org/abs/1607.03516
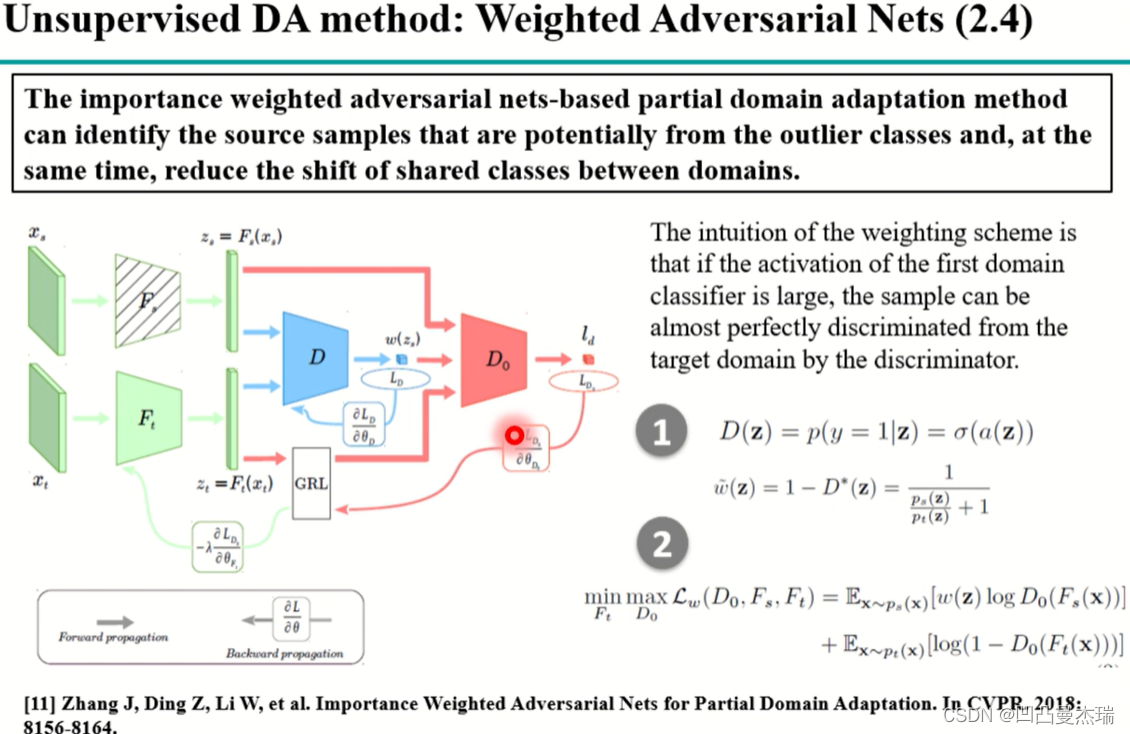
《Importance Weighted Adversarial Nets for Partial Domain Adaptation》(2018).
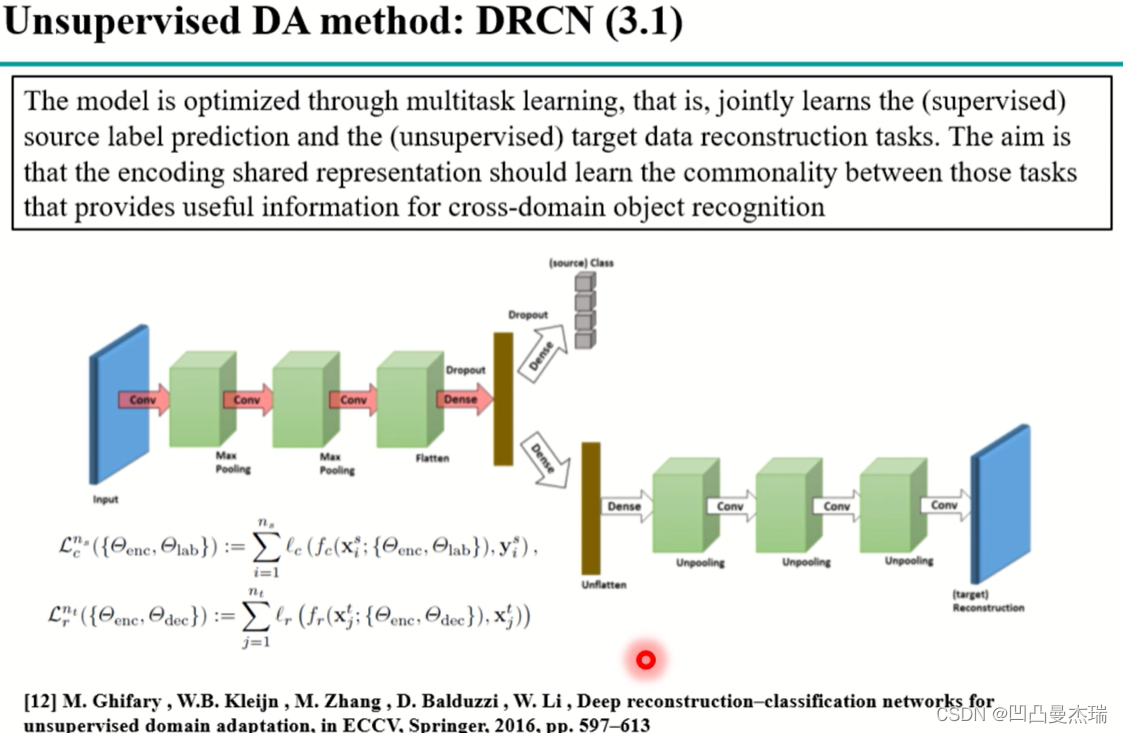
模型中在开始也是设置一个参数共享的特征提取器,源域和目标域都输入进去,然后编码成特征之后输入到源域分类器上去优化网络,第二部分做解码重构,使得特征重新解码后变回目标域的特征等信息,这两个部分,源域的分类器能让模型在源域上的分类变的更好,目标域重构使特征离目标域不会太远。
类似于上述的重构,还有一种利用编解码器的方法:《Domain separation networks》,2016
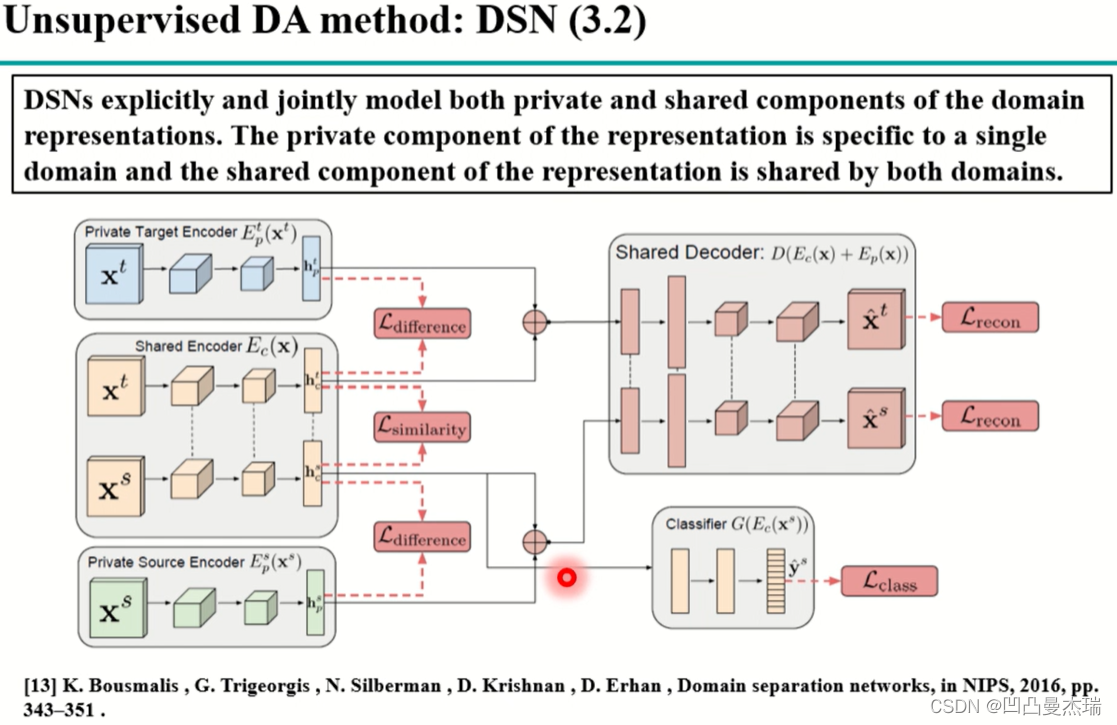
该方法较上一个更复杂,思路:将目标域和源域的样本拆成两个部分,一部分是域私有的包含了域的特定信息,另一部分是共有的,包含了域的共有特征;对于共有的特征,在源域训练好后就可以在目标域上使用,但怎么分的更好,需要约束。即让私有和共有的特征更正交,即更不一样,这样私有和共有就会分开;分开的同时,这两个特征重新结合后,经过decoder后能重构原样本,即重要的信息没有损失;对于共同特征的和特有的特征,分别有difference和similarity损失函数。
2.2.4 DA for heterogeneous
上面的介绍基于homogenerous, 对于heterogeneous的域适配参考:
Deep visual domain adaptation: A survey_深度域混淆_Wanderer001的博客-CSDN博客
在异构DA中,源域和目标域的特征空间并不相同,,而且特征空间的维数也可能不同。根据特征空间的发散性,可以将异质性DA进一步划分为两种场景。在一个场景中,源和目标域都包含图像,特征空间的发散主要是由不同的感官设备(如可见光vs.近红外(NIR)或RGB vs. depth)和不同的图像风格(如草图vs.照片)引起的。在另一个场景中,源和目标领域中存在不同类型的媒体(例如,文本和图像以及语言和图像)。
--更加详细内容参考above文献.
--------------------------------------------------------
· DAN
DAN是ICML 2015 《Learning Transferable Features with Deep Adaptation Networks》中提出来的,作者是清华大学软件学院龙明盛老师团队。DAN是在DDC上进行改进得到的框架,先介绍一下DDC。
DDC是《Deep Domain Confusion: Maximizing for Domain Invariance》提出来的架构,主要是下图所示:这里(Unsupervised)和上面的Fine-tune(Supervised)不一样
是无监督域适应的一个例子:源域数据还是通过有标签的数据(labeled images)训练一个网络,目标域的数据是无标签的(unlabeled images),由于目标域的数据是无监督的,无法适用loss对模型进行微调。使用以下方法解决:首先,让源域和目标域网络保持参数一致,源域参数改变,目标域参数也改变;其次,在某一层,一般是高层,增加一个domain loss,计算源域和目标域之间的距离(我的理解是计算original domain与target domain直接的数据分布距离),classification loss和domain loss加在一起不断的在网络中回传微调,通过使domain loss不断的减小,最终源域训练的结果在目标域上也会有一个比较好的结果。
————————————————
原文链接:https://blog.csdn.net/lh16130130282/article/details/128046481
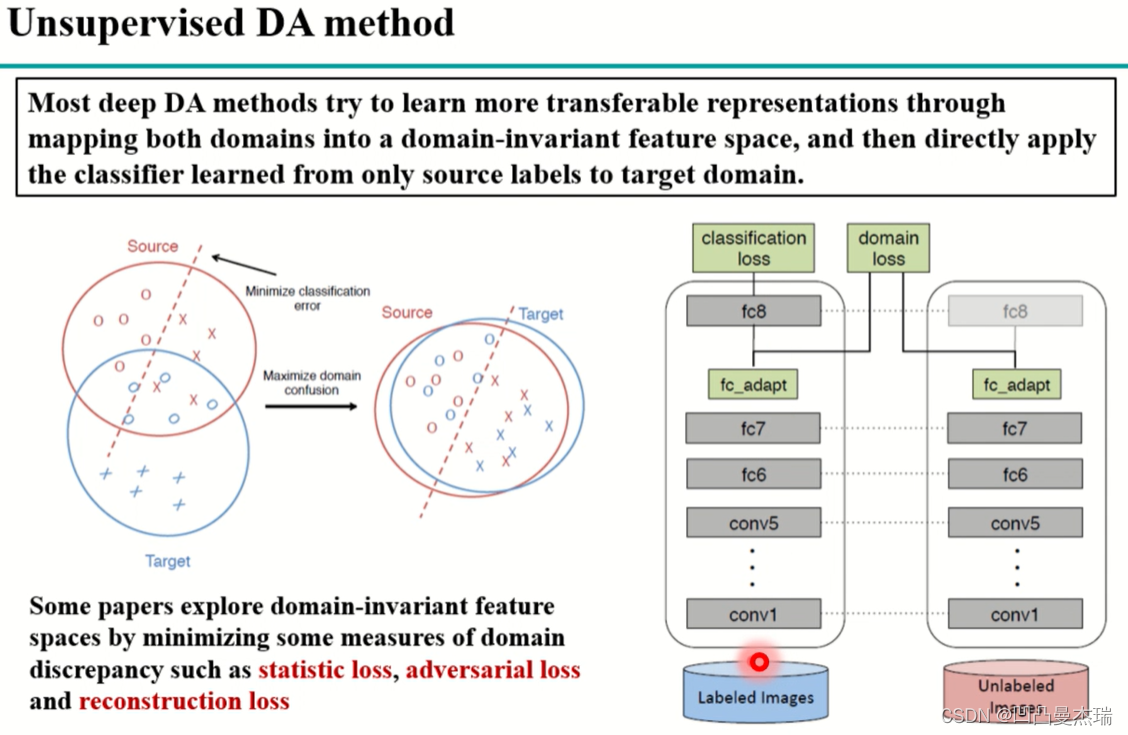
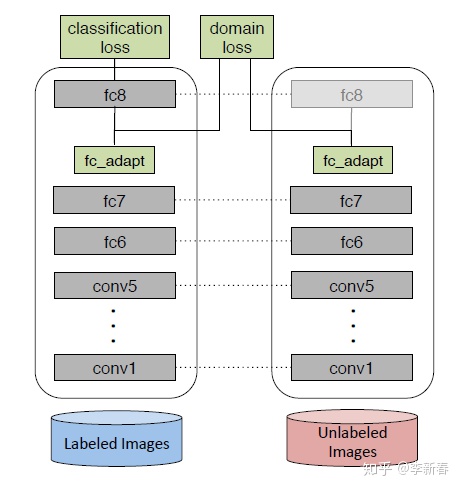
其中,左边是一个CNN网络,用来做分类问题的,从Labeled Images经过各种卷积、全连接层,最后计算Classification Loss。传统的图片分类问题是这么做,但是这样会带来一个问题,由于网络都是在Source Domain上做的,没有见过Target Domain数据的网络很难再目标领域(图中右边的Unlabeled Images)上做到如此好的效果。因此需要加一个Domain Loss,目的是使得两个域之间的距离更加接近。其中最为常用的是MMD Loss:
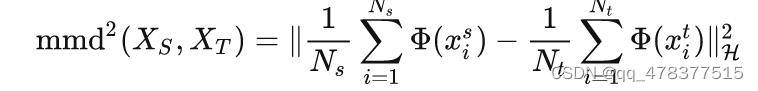
MMD,全称是Maximum Mean Discrepancy,经常被用来做Two Sample Test,即测试两个样本集是否同分布。DDC最终的优化目标就是:
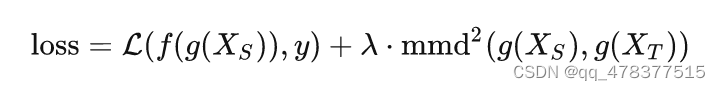
其中 g(⋅) 表示特征提取网络,输出是深度网络的中间某一层, f(⋅) 表示目标分类器。而DAN做的改进主要有两点:第一,在网络的多层加入MMD损失;第二,MMD的计算上采用多个核。
其一,DAN的优化目标如下:
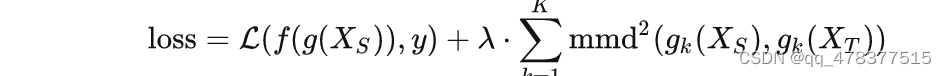
其中 gk(⋅) 表示深度网络某一中间层的输出。图示为:

· DANN
DANN,Domain Adversarial Neural Network,又被称为RevGrad。是基于Adversarial的一个经典Domain Adaptation工作。发表在ICML 2015 《Unsupervised Domain Adaptation by Backpropagation》上。
其主要思想是利用 H−Divergence 来衡量两个域之间的距离,并且和GAN的思想糅合到一起。下面给出其框架图:

在这个里面包括三个部分,特征提取器(Feature Extractor)、分类器(Label Predictor)和领域分类器(Domain Classifier)。
其中特征提取器和分类器两个部分组成了以往网络的经典架构,目标是最大化分类性能。这个框架里面主要是加入了一个Domain Classifier模块。下面简单阐述三个模块的作用:
- Feature Extractor用来提取源域和目标域数据的特征,一方面最大化Label Predictor在源域上的分类性能,另一方面使得提取的源域/目标域特征让Domain Classifier分不开;
- Label Predictor根据Feature Extractor提取的特征,最大化源域数据的分类性能;
- Domain Classifier目的是尽可能地区分开Feature Extractor提取的源域/目标域特征。
从以上介绍,可以看出Feature Extractor和Domain Classifier是两个对抗的部分,因此自然也是一个minimax的问题。将以上三个部分的参数分别记为 θf,θy,θd ,因此得到下面的目标:
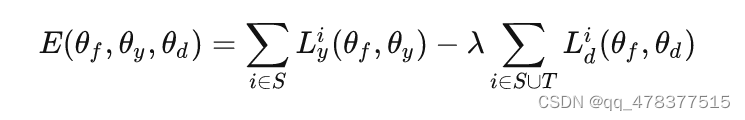
其中 i∈S 表示样本来自源域, Lyi 代表的是分类损失,比如Multi-Class Cross-Entropy, Ldi 表示Domain Classifier分类的损失(具体做法是源域的样本的Domain Label为0,目标域样本的为1,训练一个二分类器,采用Binary Cross Entropy损失)。
那么优化过程就是下面所示的迭代过程:
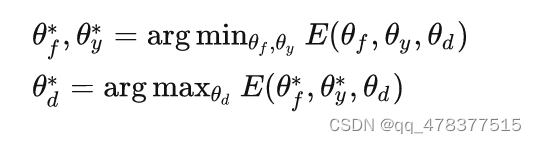
为了避免迭代优化,DANN引入了一个梯度反转层(Gradient Reversal, RevGrad),主要是在Domain Classifier的梯度回传的过程中加一个反向操作,使得优化过程可以不用迭代。
--------------------------------------------------------
2.3 Domain Generalization
参考:Domain Generalization Notes - 知乎
Domain Generalization: A Survey:https://arxiv.org/abs/2103.02503
Transfer Learning (TL) 是指利用数据、任务或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。fine-tune和DA都是TL的一种类型。与DG的相似之处就是目标域数据存在domain shift。
Zero-Shot Learning (ZSL) 的目标也是解决未见的数据分布。与DG不同的是,ZSL的distribution shift是由于标签空间的不同所导致的,而DG是由于covariate shift。
DG 分类
根据标签空间:
- Homogeneous DG: 源域标签空间和目标域标签空间一致,在图像分类和分割中较常见;
- Heterogeneous DG:源域标签空间和目标域标签空间不一致,更加实际且更具挑战,例如跨数据集的行人重识别人物,不同数据集中的人物是不一样的。
根据源域数量:
- Multi-source:使用多种不同源域数据,能够提高让模型发现更稳定模式的机会;
- Single-source:一般通过破坏和干扰数据提高模型的鲁棒性,比如进行数据增广。
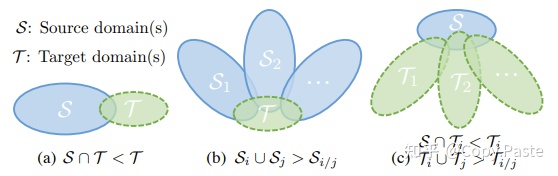
图:域差异。(a)DA, (b)Multi-source DG, (c) Single-source DG
3 其他
3.1 参考:transfer learning 和 cross domain 有怎样的联系? - 知乎
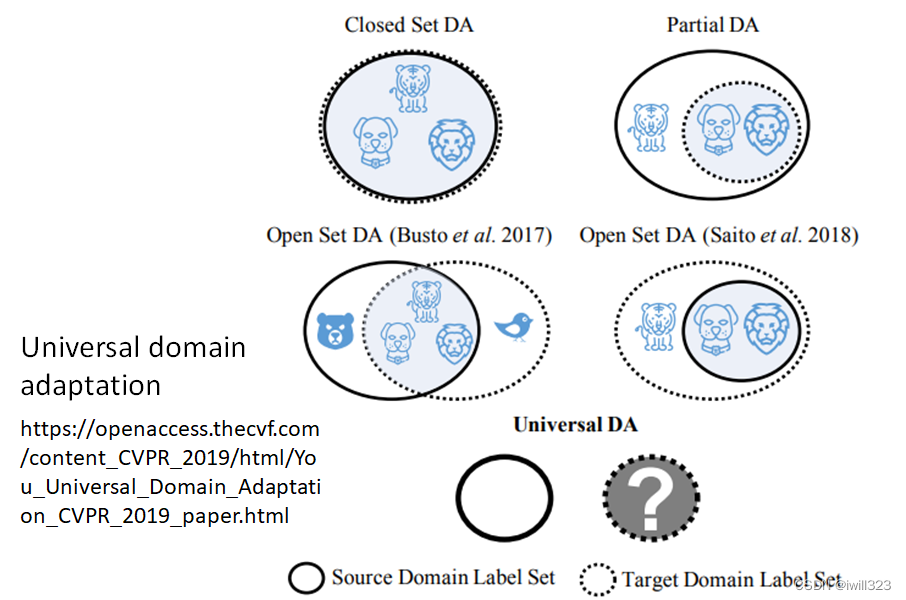
Universal Domain Adaptation:https://youkaichao.github.io/files/cvpr2019/1628.pdf
source资料和target资料不一定有相同的标签。实线的圈圈代表Source Domain 裡面有的东西,虚实线的圈圈代表 Target Domain 裡面有的东西。
Source Domain 裡面的东西比较多,Target Domain 裡面的东西比较少
Source Domain 裡面的东西比较少,Target Domain 的东西比较多
可能两者虽然有交集,但是各自都有独特的类别
当有不一样的label的时候怎么办呢:通用领域自适应Universal Domain Adaptation,参见下面引用的文献
————————————————
原文链接:https://blog.csdn.net/iwill323/article/details/127603129
3.2 transfer learning 和 cross domain 有怎样的联系?
要解释二者的联系,首先解释下什么是Domain:Domain中文表示--域,即领域,这里主要指的是数据本身及其分布,更确切地说主要包括数据的特征空间X、类别空间Y以及边缘分布即P(X) 。
而迁移学习是将源域的知识迁移到目标域,从而解决目标域数据量有限的方法,利用的是源域和目标域之间的相似性;迁移过程种往往由于源域和目标域在特征空间、类别空间、边缘分布中的某一项或几项存在差异,没有办法直接进行迁移,即出现Cross Domain即跨域问题。
当前解决跨域问题的流行的方法包括域适应、域泛化等等。更符合实际应用情况的标签空间不一致域适应问题还包括部分域适应, 开集域适应以及通用域适应等等就不在这里展开了,关于更多域适应技术可以阅读CVPR2019的文章:Universal Domain Adaptation。
https://youkaichao.github.io/files/cvpr2019/
3.3 CVPR2020 有关Cross Domain论文阅读总结与思考
CVPR2020 有关Cross Domain论文阅读总结与思考_Leepupupu的博客-CSDN博客
3.4 李宏毅机器学习——领域适应Domain Adaptation(值得一看)
参考:
李宏毅机器学习——领域适应Domain Adaptation_iwill323的博客-CSDN博客
【李宏毅机器学习】Domain Adaptation 域适应_山顶夕景的博客-CSDN博客
概述领域自适应 (Domain Adaptation)_哔哩哔哩_bilibili
少量有标注的目标领域资料:微调
大量无标注的目标领域资料:Feature Extractor
这种情境蛮符合在真实的系统上有可能会发生的情境
处理思想:训练一个Network作为Feature Extractor(特征提取器),使用feature extractor将两个领域相同的部分提取出来,剔除掉不同的部分。下图例子中,Feature Extractor 可以学到无视顏色这件事情,把顏色的资讯滤掉,不管是来自 Source Domain还是来自 Target Domain 的图片,只要通过 Feature Extractor 以后得到的 Feature 有一样的分布,那么后面的模型就会因为输入是正常的output而发挥正常的作用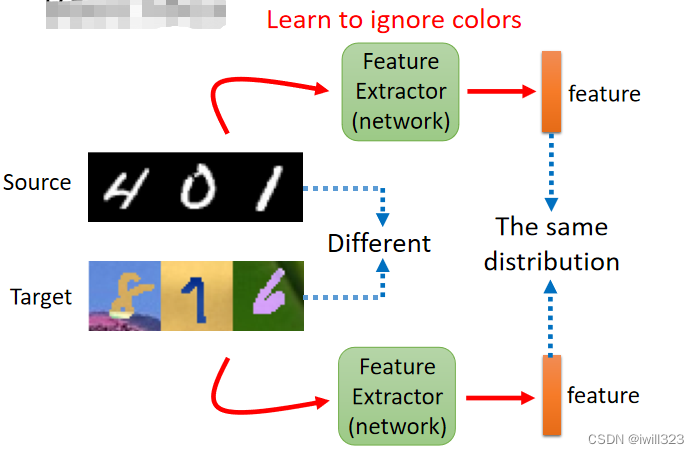
下面有助于解释GAN-adapation思想:
如何找到Feature Extractor: domain adversarial training(域对抗训练)
可以把一般的 Classifier分成 Feature Extractor和Label Predictor 两个部分。比如将前 5 层算是 Feature Extractor,后 5 层算是 Label Predictor,这个层数是一个超参数,需要进行调整得到。(下图中红色和蓝色的点)。训练时,把Source Domain 和 Target Domain的图片丢到这个Image Classifier,希望Feature Extractor 的 Output 看起来要分不出差异。
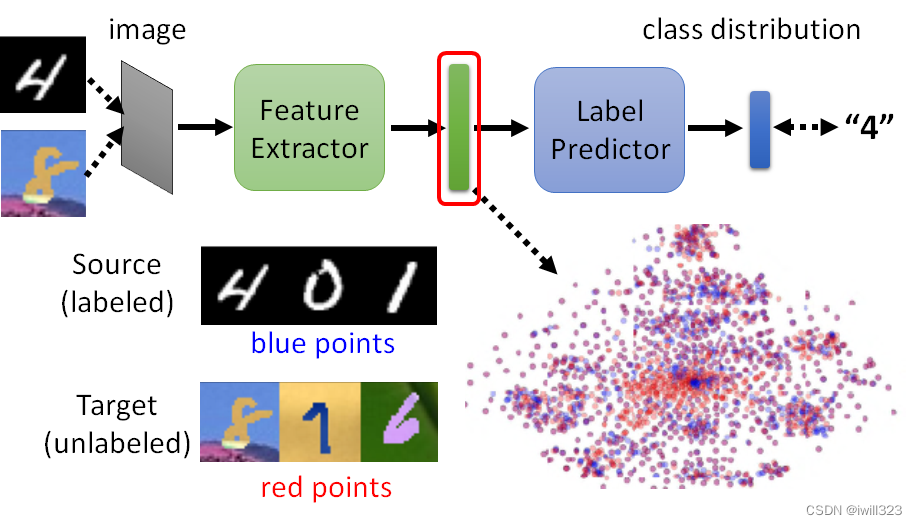
藉由 Domain Adversarial Training 技术实现。训练一个domain classifier,它是二元分类器,用来判断输入向量是来自於 Source Domain还是来自於 Target Domain。Feature Extractor 学习的目标就是要去想办法骗过这个 Domain Classifier。
并且label predictor要正确分辨图片中是什么数字,这样对Feature Extractor的输出进行了限制,比如Feature Extractor不能看到什麼东西永远输出零向量,虽然这样能骗过 Discriminator。因此,feature extractor抽取的特征既要让domain classifier无法区分两个domain,又要让label predictor能区分Source Domain中的图片。
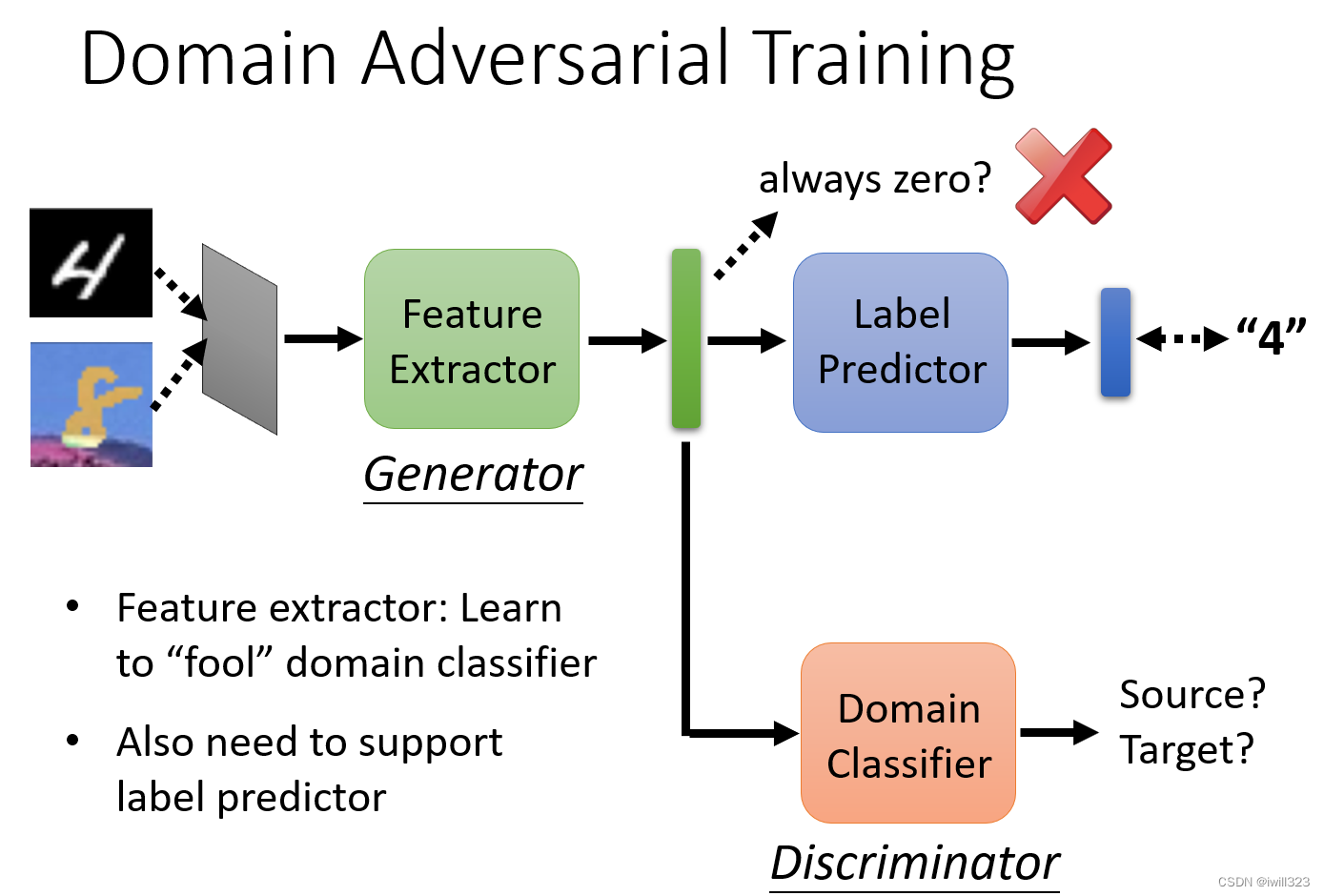
Label Predictor 的参数叫θp,Domain Classifier 的参数叫做θd,Feature Extractor 的参数叫做θf。
Label Predictor对实际的分类任务进行分类,分类结果与实际分类之间的CrossEntropy记为L(Source Domain 上的 Image分类),Domain Classifier对Feature Extractor得到的feature进行二元分类,判断来自哪个Domain,分类结果与实际分类之间的Loss记为Ld。
训练目标:
Label Predictor找到θp,让L越小越好
Domain Classifier 找到θd,让Ld越小越好
Feature Extractor找到θf,既能让LabelPredictor分类准确,减小L,又能让尽量让DomainClassifier难以分辨,增大Ld。所以Feature Extractor 的Loss定义为L-Ld,找到θf使之尽可能小。
但是L-Ld这个式子存在问题,本来是想用 -Ld来表示让classifier分不清向量来源,但是把source误判为target,把target误判为source,这也能实现min-Ld。但是这个式子是有用的,只不过未必是最好的方法,还有待探究。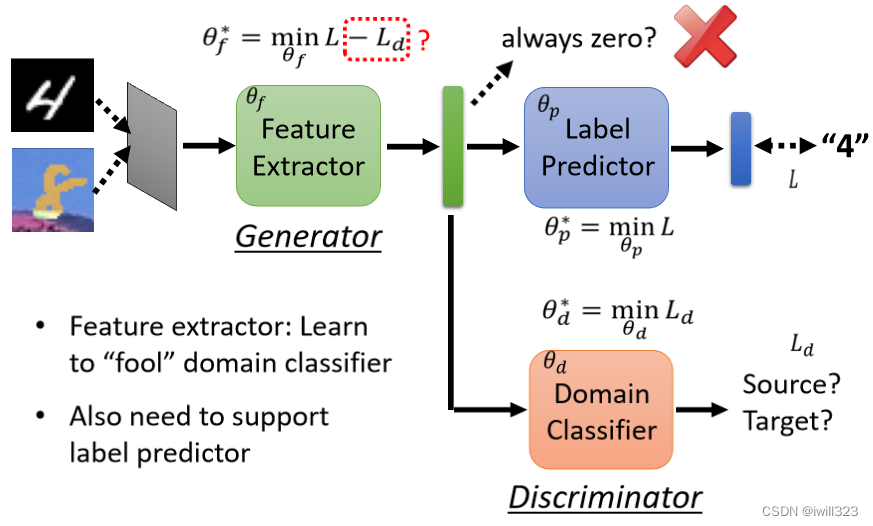
结果如下图表格的第二行
Unsupervised Domain Adaptation by Backpropagation:https://arxiv.org/abs/1409.7495cc
code: GitHub - fungtion/DANN: pytorch implementation of Domain-Adversarial Training of Neural Networks
Domain-Adversarial Training of Neural Networks: https://arxiv.org/abs/1505.07818

Considering Decision Boundary
希望两个domain的分布更加接近——让target domain 的data尽量避开 source domain中得到的分界点boundary,离boundary越远越好,于是让不同类别的“输出”之间差异尽可能地大,尽可能地集中在某一类别上
有一个知名的方法叫做 DIRT-T,还有另外一个招数叫Maximum Classifier Discrepancy
3.5 跨领域元学习综述
4 待解读论文:
(0) 深度域适应技术综述_域适应综述_凹凸曼杰瑞的博客-CSDN博客
***这篇文章解释的很好,值得参考***
(1)Cross-Domain Weakly-Supervised Object Detection through Progressive Domain Adaptation:
Domain adaptation for object detection_domain adaptation detection_wuguangbin1230的博客-CSDN博客CDWSOD
GitHub - naoto0804/cross-domain-detection: Cross-Domain Weakly-Supervised Object Detection through Progressive Domain Adaptation [Inoue+, CVPR2018].
(2)Domain Adaptive Faster R-CNN for Object Detection in the Wild
https://arxiv.org/abs/1803.03243
GitHub - krumo/Detectron-DA-Faster-RCNN: Domain Adaptive Faster R-CNN in Detectron
https://arxiv.org/abs/1803.03243
GitHub - naoto0804/cross-domain-detection: Cross-Domain Weakly-Supervised Object Detection through Progressive Domain Adaptation [Inoue+, CVPR2018].
(3)awesome-domain-adaptation-object-detection
(4)SSDA-YOLO:新的YOLOv5改进方法——用于跨域目标检测的半监督域自适应YOLO方法
SSDA-YOLO:新的YOLOv5改进方法——用于跨域目标检测的半监督域自适应YOLO方法_人工智能算法研究院的博客-CSDN博客GitHub - hnuzhy/SSDA-YOLO: Codes for my paper "SSDA-YOLO: Semi-supervised Domain Adaptive YOLO for Cross-Domain Object Detection"SSDA-YOLO:新的YOLOv5改进方法——用于跨域目标检测的半监督域自适应YOLO方法_人工智能算法研究院的博客-CSDN博客
multiscale domain adaptive yolo for cross-domain object detection:
【multiscale domain adaptive yolo for cross-domain object detection】论文阅读-CSDN博客
https://arxiv.org/abs/2106.01483v1
Domain Adaptive YOLO for One-Stage Cross-Domain Detection:
https://arxiv.org/abs/2106.13939
(5)Cross-Domain Adaptive Teacher for Object Detection
https://arxiv.org/abs/2111.13216#GitHub - wangs311/awesome-domain-adaptation-object-detection: A collection of papers about domain adaptation object detection. Welcome to PR the works (papers, repositories) that are missed by the repo.
(6)Deep Domain Adaptive Object Detection: a Survey
DEEP DOMAIN ADAPTIVE OBJECT DETECTION: A SURVEY_深度域适应目标检测_Wanderer001的博客-CSDN博客
https://arxiv.org/abs/2002.06797
(7)Cross-domain Contrastive Learning for Unsupervised Domain Adaptation
https://www.cnblogs.com/BlairGrowing/p/16934291.html
(8)目标检测和分类的域适配研究简述
目标检测和分类的域适配研究简述_progressive domain adaptation for object detection_Wanderer001的博客-CSDN博客
5 思考 to our customed dataset:
1) 前面的迁移学习使用的数据都是类似于office31或者手写数据集(0~9),这些数据的特征是:源域和目标域的数据类别是一样的,甚至类别的个数都一样。但现实生活中源域和目标域差别较大。
论文**《Multi-adversarial domain adaptation》2018**
当目标域是源域的子集的时候:
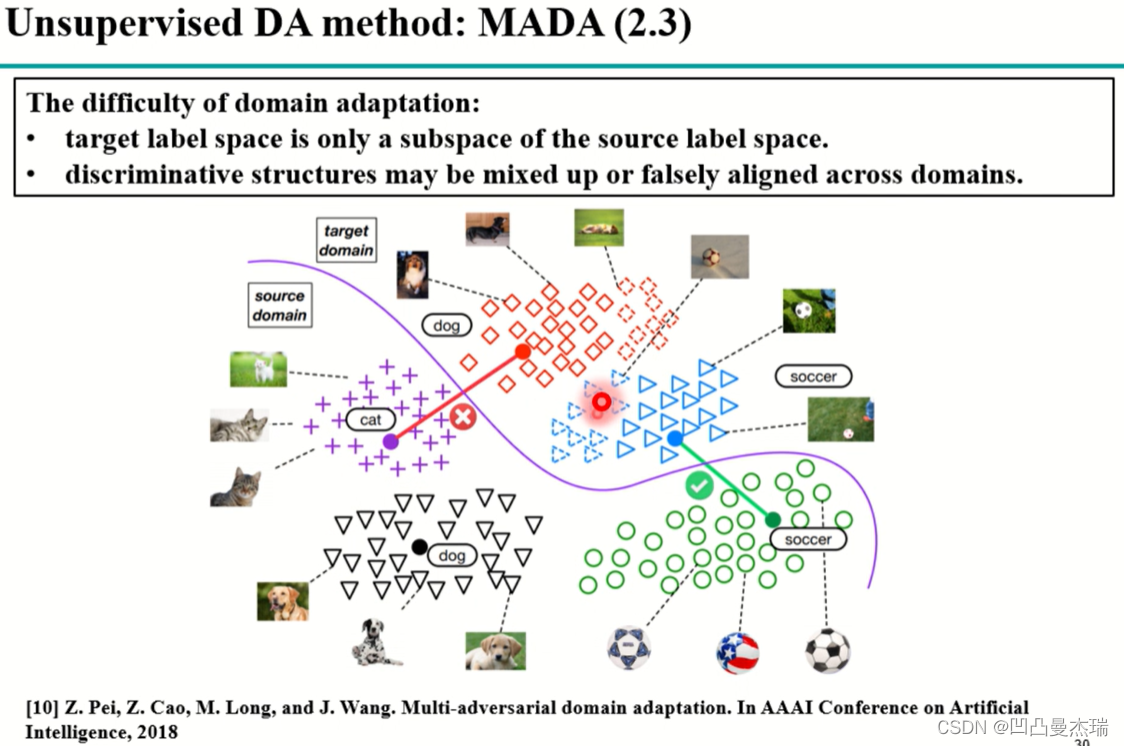
例如上图中,目标域是狗,足球,是源域的一个子集,这个时候猫就会没有数据对齐,这个时候会出现以下现象:源域中的部分狗对齐到了猫,导致数据的对齐出现混乱。这个时候人们发现源域和目标域的对齐应该精细化到类别,而不是简单的整个域的对齐。《Multi-adversarial domain adaptation》2018

2) 论文《Deep Visual Domain Adaptation: A Survey》中这样提到:
the discrepancy-based approaches have been studied for years and
produced more methods in many research works, whereas the
adversarial-based and reconstruction-based approaches are a
relatively new research topic but have recently been attracting
more attention.
————————————————
原文链接:https://blog.csdn.net/lh16130130282/article/details/128046481















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









