







参考 Deep visual domain adaptation: A survey - 云+社区 - 腾讯云
目录
深度视觉域适配作为一个解决大量标注数据缺失的新的学习技巧而出现。与传统的学习共享特征子空间或使用浅层表示重用重要源实例的方法相比,深度域适应方法通过将域适应嵌入深度学习管道中,利用深度网络学习更多可迁移的表示。对于浅域适应的研究已经有了全面的调查,但很少及时回顾基于深度学习的新兴方法。在这篇论文中,我们提供了一个全面的调查深入领域适应方法的计算机视觉应用有四个主要贡献。首先,根据定义两个领域如何分化的数据属性,我们给出了不同深度领域适应场景的分类。其次,我们根据训练损失将深度领域适应方法归纳为若干类别,并对这些类别下的最新方法进行简要分析和比较。第三,我们概述超越图像分类的计算机视觉应用,如人脸识别、语义分割和目标检测。第四,指出了现有方法可能存在的不足和未来的发展方向。
1、简介
在过去的几年里,机器学习取得了巨大的成功,并使实际应用受益匪浅。然而,为每个新的任务和领域收集和注释数据集是非常昂贵和费时的过程,充分的训练数据可能并不总是可用的。幸运的是,大数据时代为其他领域和任务提供了大量数据。例如,尽管公开的大规模标签视频数据库只包含少量样本,但从统计学上讲,YouTube人脸数据集(YTF)由3.4 K个视频组成。标记的静止图像的数量超过了足够的人脸数据集[1]。因此,在当前任务中巧妙地使用数据稀缺的辅助数据将有助于实际应用。
然而,由于许多因素(如光照、姿态和图像质量),两个域之间的分布变化或域移位都会降低性能,如图1所示。模仿人类视觉系统,领域适应(DA)是迁移学习(TL)的一种特殊情况,它利用一个或多个相关源领域中的标记数据在目标领域执行新的任务。在过去的几十年里,人们提出了各种浅层DA方法来解决源域和目标域之间的域漂移。常用的浅层数据挖掘算法主要分为两类:基于实例的数据挖掘和基于特征的数据挖掘。第一类通过对源样本进行加权来减少误差,并对加权后的源样本进行训练。对于第二类,通常学习一个公共共享空间,其中两个数据集的分布是匹配的。
近年来,基于神经网络的深度学习方法在视觉分类应用中取得了许多令人鼓舞的成果,如图像分类、人脸识别、目标检测。深层网络模拟人脑的感知,可以通过多层非线性转换来表示高层抽象。现有的深度网络结构,包括卷积神经网络(CNNs)、深度信念网络(DBNs)、堆叠自编码器(SAEs)等。尽管一些研究表明,深度网络可以学习更多可转移的表示,它可以根据数据样本和群体特征与不变因素的相关性,分层地分离数据样本背后的变异探索因素和群体特征。深层特征最终会由一般特征过渡到具体特征,在更高层次上表示的可转移性急剧下降。因此,最近的研究通过将深度学习和数据挖掘相结合的深度数据挖掘来解决这个问题。

本文主要对深度数据挖掘方法进行分析和讨论。具体来说,该综述的主要贡献如下:(1)、根据定义两个领域如何分化的数据属性,我们提供了不同深度DA场景的分类。(2)、我们对三个子设置(分类损失训练、差异损失训练和对抗式损失训练)进行了改进和细化,总结了在不同的DA场景中使用的不同方法。(3)考虑到源域和目标域的距离,研究了多步数据挖掘方法,并将其分为手工处理机制、基于特征机制和基于表示机制。(4)我们提供了许多计算机视觉应用的调查,如图像分类,人脸识别,风格翻译,目标检测,语义分割和人的重新识别。
2、概览
2.1、概念和定义
在本节中,我们将介绍一些本调查中使用的符号和定义。域![]() 由特征空间
由特征空间![]() 和边缘分布概率
和边缘分布概率![]() 组成,其中
组成,其中![]() 。给定一个指定域
。给定一个指定域![]() ,任务
,任务![]() 由特征空间
由特征空间![]() 和目标预测函数
和目标预测函数![]() 组成,从概率的角度也可以看成是条件概率分布
组成,从概率的角度也可以看成是条件概率分布![]() 。通常情况下,我们可以从标记数据
。通常情况下,我们可以从标记数据![]() 以监督的方法来学习
以监督的方法来学习![]() ,其中
,其中![]() 和
和![]() 。
。
假设我们有两个域:具有足够标记数据的训练数据集是源域,![]() ,带有少量标记数据或没有标记数据的测试数据集是目标域,
,带有少量标记数据或没有标记数据的测试数据集是目标域,![]() 。我们看到部分标记的部分
。我们看到部分标记的部分![]() ,和未标记的部分,
,和未标记的部分,![]() ,形成整个目标域,
,形成整个目标域,![]() 。每个域和它的任务一起
。每个域和它的任务一起![]() 。同样的,
。同样的,![]() 可以从源域数据
可以从源域数据![]() 中学习,同时
中学习,同时![]() 可以从标记了的数据
可以从标记了的数据![]() 中学习,同时
中学习,同时![]() 可以从标记了的目标数据
可以从标记了的目标数据![]() 和未标记的数据
和未标记的数据![]() 中学习。
中学习。
2.2、不同的领域适应设置
传统机器学习的情况是![]() 并且
并且![]()
![]() ,不同数据集之间的差异可能是由领域差异造成的
,不同数据集之间的差异可能是由领域差异造成的![]()
![]() (例如,分布移位或特征空间差异),任务的分歧
(例如,分布移位或特征空间差异),任务的分歧![]() ,(例如,条件分布移位或标签空间差),或同时。在此基础上,将TL分为三大类:诱导型、转导型和无监督型。
,(例如,条件分布移位或标签空间差),或同时。在此基础上,将TL分为三大类:诱导型、转导型和无监督型。
根据这种分类,DA方法是假设任务相同的转导TL解决方法,例如,![]() ,这些差异仅仅是由区域的散度引起的,
,这些差异仅仅是由区域的散度引起的,![]() ,因此,基于区域差异(分布位移或特征空间差异),DA可以分为两大类:均质DA和异质性DA。
,因此,基于区域差异(分布位移或特征空间差异),DA可以分为两大类:均质DA和异质性DA。

然后,考虑到目标域的标记数据,我们可以进一步将DA分为有监督的、半监督的和无监督的。分类如图2所示。
- 在同质DA设置中,源域和目标域之间的特征空间是相同的
 ,具有相同的维度
,具有相同的维度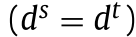 ,因此源和目标数据集在数据分布方面通常是不同的
,因此源和目标数据集在数据分布方面通常是不同的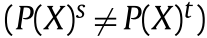 。
。
此外,我们可以进一步将齐次DA设置分为三种情况:
- 在有监督的数据处理中,少量标记的目标数据,
 出现。但是,标记的数据对于任务来说通常是不够的。
出现。但是,标记的数据对于任务来说通常是不够的。 - 在半监督DA中,训练阶段可以得到目标域中有限的标记数据
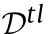 和冗余的未标记数据
和冗余的未标记数据 ,使网络能够学习目标域的结构信息。
,使网络能够学习目标域的结构信息。 - 在无监督DA中,训练网络时可观察到无标记但有足够的未标记目标域数据
 。
。
在异构DA设置中,源域和目标域之间的特征空间是不等价的![]() ,维度通常也可能不同于
,维度通常也可能不同于![]() 。与同构设置相似,异构DA设置也可以分为监督式DA、半监督式DA和无监督式DA。
。与同构设置相似,异构DA设置也可以分为监督式DA、半监督式DA和无监督式DA。
以上所有DA设置都假设源域和目标域是直接相关的;因此,知识的传递可以一步到位。我们称之为一步DA。然而在现实中,这种假设有时是不可用的。这两个域之间几乎没有重叠,因此执行一步DA将是无效的。幸运的是,有一些中间域能够使源域和目标域比它们原来的距离更近。因此,我们使用一系列中间桥连接两个看似不相关的域,然后通过这个桥执行一步DA,称为多步(或传递)DA。例如,人脸图像和车辆图像由于形状或其他方面的不同而存在差异,因此一步DA会失败。但是,一些中间图像,如“football helmet”,可以被引入作为一个中间域,实现平滑的知识转移。图3显示了单步DA技术和多步DA技术学习过程的差异。

3、深度域适配的方法
从广义上讲,深度数据挖掘是利用深度网络提高数据挖掘性能的一种方法。在这个定义下,具有深度特征的浅层方法可以被认为是深度DA方法。浅层方法采用DA,而深度网络只提取矢量特征,不利于直接传递知识。例如从一个CNN中提取卷积激活作为张量表示,然后进行张量对齐不变子空间学习来实现DA。这种方法可靠地优于目前基于传统手工制作特征的最先进的方法,因为可以通过深度网络提取足够的代表性和可转移特征,这可以更好地处理辨别任务。在狭义上,深度数据挖掘是基于深度学习架构设计的数据挖掘,可以通过反向传播从深度网络中获得第一手的效果。直观的想法是将DA嵌入到学习表示的过程中,并学习一个语义上有意义且领域不变量的深度特征表示。使用“良好”的特征表示,目标任务的性能将显著提高。在这篇文章中,我们关注于狭义的定义,并讨论如何利用深度网络学习“好的”特征表示与额外的训练标准。
3.1、一步域适配的分类
在一步DA中,深层方法可以总结为三种情况。表1显示了这三种情况和简要描述。第一种是基于离散的深度DA方法,该方法假设使用标记或未标记的目标数据对深度网络模型进行微调可以减小两个域之间的移动。分类判据、统计判据、建筑判据和几何判据是进行微调的四种主要技术:
- 分类标准:使用类标签信息作为在不同领域之间传递知识的向导。当目标域的标记样本在监督DA中可用时,软标记和度量学习总是有效的。当这些样本不可用时,可以采用其他一些技术来替代类标记数据,如伪标签和属性表示。
- 统计标准:使用某些机制对齐源和目标域之间的统计分布变化。比较和减少分布偏移最常用的方法是最大平均差异(maximum mean差值,MMD),相关对齐(correlation alignment, CORAL), Kullback-Leibler (KL)散度和H散度等。
- 结构标准:目的是通过调整深度网络的结构来提高学习可转移特征的能力。被证明具有成本效益的技术包括自适应批处理归一化(BN)、弱相关权重、领域引导的dropout等。
- 几何标准:根据源域和目标域的几何特性建立连接。该判据假设几何结构之间的关系可以减小畴移。
第二种情况可以称为基于对抗性的深度DA方法。在这种情况下,用于分类数据点是来自源域还是目标域的域鉴别器被用来通过一个敌对的目标来鼓励域混淆,以最小化经验源和目标映射分布之间的距离。此外,基于对抗性的深度DA方法可以根据是否有生成模型分为两种情况。
- 生成模型:将判别模型与基于生成对抗网络(GANs)的生成组件相结合。典型的例子之一是利用源图像、噪声向量或两者同时生成与目标样本相似的模拟样本,并保留源域的标注信息。
- 非生成模型:而不是生成模型与输入图像分布,特征提取器学习歧视表示使用标签在源域和目标数据映射到同一空间通过domain-confusion损失,从而导致域不变表示。
第三种情况可以称为基于重构的DA方法,它假设源样本或目标样本的数据重构有助于提高DA的性能。该构造函数既能保证域内表示的特殊性,又能保证域间表示的不可区分性。
- 编码器-解码器重构:通过使用堆叠自动编码器(SAEs),编码器-解码器重构方法将用于表示学习的编码器网络与用于数据重构的解码器网络结合起来。
- 对抗式重构:重构误差是通过GAN鉴别器得到的循环映射来测量每个图像域内重构图像与原始图像的差值,如dual GAN[62]、cycle GAN和disco GAN。
3.2、多步域适配的分类
在多步骤DA中,我们首先确定与源域和目标域的关联比它们的直接连接更大的中间域。第二,通过一步DA实现源域、中间域和目标域之间的知识传递过程,减少信息损失。因此,多步骤数据挖掘的关键在于如何选择和利用中间域;另外,它也可以分为三类:手工制作、基于特性和基于表示的选择机制。
- 手工设计:用户根据经验决定中间领域。

- 基于实例:从辅助数据集中选择特定部分的数据组成中间域来训练深度网络。
- 基于表示:通过冻结之前训练过的网络,并使用它们的中间表示作为新网络的输入来实现传输。
4、一步域适配
如2.1节所述,目标域中的数据无论同质还是异质DA,都有三种类型:(1)、有标记数据的监督DA,(2)、有标记数据和无标记数据的半监督DA,(3)、无标记数据的非监督DA。结合设置1和设置3的方法可以完成第二设置;因此,在本文中我们只关注第一和第三种设置。表3显示了对每种DA设置主要使用不同方法的情况。如表3所示,由于有监督的DA有其局限性,我们将更多的工作集中在无监督场景上。当目标域内仅有少量标记数据时,使用源标记数据和目标标记数据训练模型参数通常会导致对源分布的过拟合。此外,基于离散的方法已经研究多年,在许多研究工作中产生了更多的方法,而基于对立的方法和基于重构的方法是一个相对较新的研究课题,近年来受到更多的关注。
4.1、同质的域适配
4.4.1、基于差异的方法
Yosinski等人证明,通过深度网络学习的可转移特征由于脆弱的协同适应和表示特异性而存在局限性,而微调可以提高泛化性能(图4)。微调(也可以看作是一种基于离散的深度DA方法)是用源数据训练一个基网络,然后直接重用前n层进行目标网络。对目标网络的剩余层进行随机初始化和基于差异的损失训练。在训练过程中,目标网络的前n层可以根据目标数据集的大小及其与源数据集的相似性进行微调或冻结。表4给出了导航这4种主要场景的一些通用经验规则。
- 分类标准
在深度数据挖掘中,类准则是最基本的训练损失。使用源数据对网络进行预训练后,目标模型的其余层以类标签信息为指导对网络进行训练。因此,假设目标数据集中的一小部分标记样本是可用的。理想情况下,类标签信息在有监督的DA中直接给出。大多数工作通常使用地基真值类的负对数似然,softmax作为他们的训练损失,![]()
![]() (
(![]() 表示类概率的模型的softmax预测是什么),为了扩展这一点,Hinton等人将softmax函数修改为软标签损失:
表示类概率的模型的softmax预测是什么),为了扩展这一点,Hinton等人将softmax函数修改为软标签损失:

其中![]() 为每个类计算logit输出,T是在标准softmax中通常设置为1的温度,但它需要一个更高的值来产生在类上的软概率分布。通过使用它,许多关于学习函数的信息,驻留在非常小的概率的比率,可以得到。例如,在识别数字时,2的一个版本可能获得
为每个类计算logit输出,T是在标准softmax中通常设置为1的温度,但它需要一个更高的值来产生在类上的软概率分布。通过使用它,许多关于学习函数的信息,驻留在非常小的概率的比率,可以得到。例如,在识别数字时,2的一个版本可能获得![]() 是3的概率和
是3的概率和![]() 是7的概率;换句话说,这个版本的2看起来更像3而不是7。]受到Tzeng等人的启发,同时最小化域混淆损失(属于基于反向的方法,将在4.1.2节中介绍)和软标签损失,从而对网络进行微调。使用软标签而不是硬标签可以保持域间类之间的关系。Gebru等人对现有的基于自适应算法进行了改进,在细粒度类级
是7的概率;换句话说,这个版本的2看起来更像3而不是7。]受到Tzeng等人的启发,同时最小化域混淆损失(属于基于反向的方法,将在4.1.2节中介绍)和软标签损失,从而对网络进行微调。使用软标签而不是硬标签可以保持域间类之间的关系。Gebru等人对现有的基于自适应算法进行了改进,在细粒度类级![]() 和属性级
和属性级![]() 上使用了软标签损失(图5)。除了softmax损失,还有其他方法可以作为训练损失,以微调目标模型的监督DA。在深度网络中嵌入度量学习是另一种可以使来自不同区域的相同标签的样本距离更近,不同标签的样本距离更远的方法。深度迁移度量学习由Hu等提出的,采用边际Fisher分析准则和MMD准则(在统计准则中描述)来最小化它们的分布差异:
上使用了软标签损失(图5)。除了softmax损失,还有其他方法可以作为训练损失,以微调目标模型的监督DA。在深度网络中嵌入度量学习是另一种可以使来自不同区域的相同标签的样本距离更近,不同标签的样本距离更远的方法。深度迁移度量学习由Hu等提出的,采用边际Fisher分析准则和MMD准则(在统计准则中描述)来最小化它们的分布差异:

其中![]() 、
、![]() 和
和![]() 和正则化系数,
和正则化系数,![]() 和
和![]() 是网络第m层的权重和偏置。
是网络第m层的权重和偏置。![]() 是源域和目标域的MMD。
是源域和目标域的MMD。![]() 和
和![]() 定义了类内紧凑度和类间分离度。
定义了类内紧凑度和类间分离度。
但是,如果在目标域中没有直接的类标签信息,我们可以做什么?我们都知道,人类只能通过高层次的描述来识别看不见的类。例如,当提供“高大、棕色、长脖子的动物”的描述时,我们就能认出长颈鹿。假定![]() 是类c的属性表示,它具有固定长度的二进制值,在所有类中有m个属性。在测试阶段,每个目标类y以确定性的方式获得其属性向量
是类c的属性表示,它具有固定长度的二进制值,在所有类中有m个属性。在测试阶段,每个目标类y以确定性的方式获得其属性向量![]() ,例如,
,例如,![]() 。通过贝叶斯法则,
。通过贝叶斯法则,![]() ,测试类的后验可计算如下:
,测试类的后验可计算如下:

Gebru等人从这些作品中得到灵感,利用属性来提高DA细粒度识别的性能。有多个独立的softmax损失,同时执行属性和类级别,以微调目标模型。为了防止独立分类器获得属性级和类级冲突的标签,还实现了属性一致性损失。
偶尔,在无监督DA中对网络进行微调时,可以根据最大后验概率初步得到目标数据的一个标签,即伪标签。Yan等利用源数据初始化目标模型,然后通过目标模型的输出定义后验概率![]() 类,通过目标模型的输出。利用
类,通过目标模型的输出。利用![]() ,它们通过
,它们通过![]() ,对
,对![]() 分配伪标签
分配伪标签![]() 。
。
两个不同的网络对未标记的样本分配伪标签,另一个网络利用样本进行训练,得到目标识别表示。deep transfer network (DTN)使用支持向量机(SVMs)和MLPs等基本分类器获取目标样本的伪标签,估计目标样本的条件分布,并将边缘分布和条件分布与MMD准则进行匹配。[32]在将分类器自适应转换到残差学习框架时,使用伪标签构建条件熵![]() ,保证目标分类器f t很好地适应目标特有的结构。
,保证目标分类器f t很好地适应目标特有的结构。
- 统计标准
尽管一些基于离散的方法搜索伪标签、属性标签或其他替代标记目标数据,但更多的工作集中在通过最小化无监督DA中的域分布差异来学习域不变表示。MMD是一种通过核二样本检验比较两个数据集分布的有效度量方法[76]。给定s和t两个分布,MMD定义如下:

其中,![]() 表示将原始数据映射到再生核希尔伯特空间(RKHS)的核函数,
表示将原始数据映射到再生核希尔伯特空间(RKHS)的核函数,![]() 在
在![]() 的单位球中定义了一组函数。
的单位球中定义了一组函数。



在此基础上,Ghifary等人提出了一种将MMD度量引入单层隐层前馈神经网络的模型。为了减少潜在空间的分布不匹配,在每个域的表示之间计算了烟雾md度量。MMD的经验估计如下:

随后,Tzeng et al.和Long et al.将MMD扩展到一个深度CNN模型,并取得了巨大的成功。Tzeng等人提出的深度域混淆网络(deep domain confusion network, DDC)使用两个CNNs作为源域和目标域,权值共享。该网络在源域的分类损失得到优化,而域的差异是由一个适应层与MMD度量。
![]()
其中超参数![]() 是一个惩罚参数,
是一个惩罚参数,![]() 表示可获得标签数据
表示可获得标签数据![]() 和标签
和标签![]() 上的分类损失。
上的分类损失。![]() 代表源域和目标域数据之间的距离。DDC只适应网络的一层,导致降低了多层的可转让性。Long等人提出了深度适应网络(DAN),在条件分布保持不变的前提下,通过增加多个适应层和探索多个核来匹配边缘分布的跨域移动(图6),而不是使用单层线性MMD。然而,这一假设在实际应用中相当适用;换句话说,源分类器不能直接在目标域中使用。为了使其更加一般化,联合自适应网络(JAN)[37]根据联合最大平均差异(JMMD)准则对多个领域特定层中输入特征和输出标签的联合分布的位移进行对齐(图6)。Zhang等提出了基于MMD的边缘分布和条件分布匹配的DTN(图6)。共享特征提取层学习一个子空间来匹配源样本和目标样本的边缘分布,辨别层通过分类器转换来匹配条件分布。残余转移网络(RTNs)除了使用MMD适应特征外,还增加了一个门控残余层用于分类器自适应。最近,Yan等人提出了一种加权MMD模型,当目标域中的类权重与源域中的类权重不同时,该模型为源域中的每个类引入一个辅助权重。
代表源域和目标域数据之间的距离。DDC只适应网络的一层,导致降低了多层的可转让性。Long等人提出了深度适应网络(DAN),在条件分布保持不变的前提下,通过增加多个适应层和探索多个核来匹配边缘分布的跨域移动(图6),而不是使用单层线性MMD。然而,这一假设在实际应用中相当适用;换句话说,源分类器不能直接在目标域中使用。为了使其更加一般化,联合自适应网络(JAN)[37]根据联合最大平均差异(JMMD)准则对多个领域特定层中输入特征和输出标签的联合分布的位移进行对齐(图6)。Zhang等提出了基于MMD的边缘分布和条件分布匹配的DTN(图6)。共享特征提取层学习一个子空间来匹配源样本和目标样本的边缘分布,辨别层通过分类器转换来匹配条件分布。残余转移网络(RTNs)除了使用MMD适应特征外,还增加了一个门控残余层用于分类器自适应。最近,Yan等人提出了一种加权MMD模型,当目标域中的类权重与源域中的类权重不同时,该模型为源域中的每个类引入一个辅助权重。
如果![]() 是一种有特征的内核(即(高斯核或拉普拉斯核),MMD将比较统计矩的所有阶数。与MMD相比,CORAL学习了一种线性变换,该变换将域之间的二阶统计量对齐。Sun和Saenko用非线性变换将珊瑚扩展到深度神经网络(deep CORAL)。
是一种有特征的内核(即(高斯核或拉普拉斯核),MMD将比较统计矩的所有阶数。与MMD相比,CORAL学习了一种线性变换,该变换将域之间的二阶统计量对齐。Sun和Saenko用非线性变换将珊瑚扩展到深度神经网络(deep CORAL)。
![]()
其中![]() 表示Frobenius范数的平方矩阵。通过对高斯核函数的泰勒展开,可以将多模态分解看作是所有原始矩加权和之间的距离的最小值[78]。将MMD解释为矩匹配程序促使Zellinger等人[79]匹配域分布的高阶矩,我们称之为中心矩差异(CMD)。关于激活空间域差异的CMD度量的经验估计
表示Frobenius范数的平方矩阵。通过对高斯核函数的泰勒展开,可以将多模态分解看作是所有原始矩加权和之间的距离的最小值[78]。将MMD解释为矩匹配程序促使Zellinger等人[79]匹配域分布的高阶矩,我们称之为中心矩差异(CMD)。关于激活空间域差异的CMD度量的经验估计![]() 给出:
给出:

其中![]() 是所有第k阶样本中心动量的向量,并且
是所有第k阶样本中心动量的向量,并且![]() 是经验期望。Haeusser提出的association loss L assoc是一种可选的差异度量,通过使两步往返概率abaij类似于类标签的均匀分布,它加强了源数据和目标数据之间的统计关联。
是经验期望。Haeusser提出的association loss L assoc是一种可选的差异度量,通过使两步往返概率abaij类似于类标签的均匀分布,它加强了源数据和目标数据之间的统计关联。
- 结构标准
还有一些方法对网络结构进行优化,使分布差异最小化。这种适应行为可以在大多数深度DA模型中实现,比如监督和非监督设置。Rozantsev等人[47]认为对应层中的权重不共享,而是通过权重调节器r w(·)进行关联,以考虑两个域之间的差异(图7)。权值调节器![]() 可以表示为指数损失函数:
可以表示为指数损失函数:


式中,![]() 和
和![]() 分别为源模型和目标模型的第j层参数。为了进一步放宽这一限制,它们允许一个流中的权重进行线性变换:
分别为源模型和目标模型的第j层参数。为了进一步放宽这一限制,它们允许一个流中的权重进行线性变换:
![]()
其中![]() 和
和![]() 是编码线性变换的标量参数。惩罚项
是编码线性变换的标量参数。惩罚项![]() 控制参数的相关度:
控制参数的相关度:
![]()
其中![]() 分别为源域和目标域第l层的参数。Li等人假设类相关知识存储在权重矩阵中,而领域相关知识由批处理标准化(BN)层的统计数据表示。BN对每个单独的特征通道的平均值和标准偏差进行标准化,这样每一层接收到的数据来自一个相似的分布,不管它是来自源还是目标域。因此,Li等人使用BN对分布进行对齐,重新计算目标域中的均值和标准差。
分别为源域和目标域第l层的参数。Li等人假设类相关知识存储在权重矩阵中,而领域相关知识由批处理标准化(BN)层的统计数据表示。BN对每个单独的特征通道的平均值和标准偏差进行标准化,这样每一层接收到的数据来自一个相似的分布,不管它是来自源还是目标域。因此,Li等人使用BN对分布进行对齐,重新计算目标域中的均值和标准差。
 \
\
其中![]() 和
和![]() 是由目标数据获得的参数,而分别为每个特征通道独立计算的平均值和标准偏差为
是由目标数据获得的参数,而分别为每个特征通道独立计算的平均值和标准偏差为![]() 和
和![]() 。赋予BN层一组对齐参数,可自动学习,并可决定深度网络不同层次所需的特征对齐程度。此外,Ulyanov等人发现,用实例归一化(IN)层替换BN层时,对于每个通道和每个样本,分别计算出了独立的
。赋予BN层一组对齐参数,可自动学习,并可决定深度网络不同层次所需的特征对齐程度。此外,Ulyanov等人发现,用实例归一化(IN)层替换BN层时,对于每个通道和每个样本,分别计算出了独立的![]() 和
和![]() ,可以进一步提高DA的性能。偶尔,神经元并不是对所有的区域都有效,因为存在区域偏差。例如,在识别人员时,目标域通常包含以最小背景杂乱为中心的一个人,而源数据集包含许多杂乱的人。因此,捕捉他人特征和杂乱的神经元是无用的。Domain-guided dropout是Xiao等为解决多区域da问题而提出的一种方法,它对每个domain不相关的神经元进行抑制。它不是用一个特定的丢失率来分配丢失,而是依赖于当神经元被移除时每个神经元在域样本上的丢失函数的增益:
,可以进一步提高DA的性能。偶尔,神经元并不是对所有的区域都有效,因为存在区域偏差。例如,在识别人员时,目标域通常包含以最小背景杂乱为中心的一个人,而源数据集包含许多杂乱的人。因此,捕捉他人特征和杂乱的神经元是无用的。Domain-guided dropout是Xiao等为解决多区域da问题而提出的一种方法,它对每个domain不相关的神经元进行抑制。它不是用一个特定的丢失率来分配丢失,而是依赖于当神经元被移除时每个神经元在域样本上的丢失函数的增益:
![]()
其中L为softmax损失函数,g (x) \ i为将第i个神经元的响应设为零后的特征向量。每个源域被分配不同的参数,![]()
![]() ,其中
,其中![]() 是一个域通用的模型,并且
是一个域通用的模型,并且![]() 领域特定偏差项,训练好低秩参数化的CNN后,
领域特定偏差项,训练好低秩参数化的CNN后,![]() 可以作为目标域的分类器。
可以作为目标域的分类器。
- 几何标准
几何标准通过对从源域到目标域的几何路径上的中间子空间进行积分,从而减轻了域的位移。构造了一个几何流曲线,将源域与目标域连接起来。源和目标子空间是格拉斯曼流形上的点。通过沿着测地线对固定的[86]或无限的[87]子空间进行采样,我们可以形成中间子空间,以帮助找到域之间的相关性。然后将源数据和目标数据投影到得到的中间子空间中,对分布进行对齐。受几何路径的中间表示的启发,Chopra等人[50]提出了一种称为深度学习的DA在域间插值(DLID)模型。DLID生成中间数据集,从所有源数据样本开始,逐步将源数据替换为目标数据。每个数据集是源和目标域之间插入路径上的单个点。一旦中间数据集被产生,一个使用预测稀疏分解的深层非线性特征提取器被训练在无监督的方式。
4.1.2、基于监督的方法
最近,GAN方法取得了巨大的成功,该方法通过对抗过程估计生成模型。GAN包括两个模型:生成模型G,提取数据分布;判别模型D,通过预测二进制标签来区分样本是G还是训练数据集。以最小最大的方式训练网络的标签预测损失:同时优化G使损失最小化,同时训练D使分配正确标签的概率最大化:
![]()
在DA中,这个原则被用来确保网络不能区分源域和目标域。Tzeng等人提出了一种基于反向的方法的统一框架,并根据是否使用生成器、使用哪个损失函数、或是否跨域共享权值对现有方法进行了总结(图8)。在本文中,我们只将基于对抗性的方法分为两个子类:生成模型和非生成模型。

- 生成模型
带有ground truth注释的合成目标数据是解决缺乏训练数据问题的一个很有吸引力的选择。首先,在源数据的帮助下,生成器呈现无限数量的合成目标数据,这些目标数据与合成源数据配对共享标签,或者看起来好像它们是在维护标签时从目标域采样的,或者其他东西。然后,使用带标签的合成数据来训练目标模型,就像不需要DA一样。具有生成模型的基于对抗性的方法能够以一种基于GAN的无监督方式学习这种转换。CoGAN的核心思想是生成与合成源数据配对的合成目标数据(图9)。它由一对GANs组成:用于生成源数据的GAN 1和用于生成目标数据的GAN 2。生成模型中前几层的权重与判别模型中最后几层的权重是绑定的。这种权重共享约束允许CoGAN在没有对应监督的情况下实现域不变特征空间。经过训练的CoGAN可以将输入的噪声向量调整到来自两个分布的成对图像上,并共享标签。因此,可以利用合成目标样本的共享标签来训练目标模型。
更多的工作集中在生成与目标数据相似的合成数据,同时维护注释。Yoo等人利用GANs将源域的知识转移到像素级目标图像。一个域鉴别器保证了内容对源域的不变性,一个真/假鉴别器监督生成器产生与目标域相似的图像。Shrivastava等人开发了一种用于模拟+无监督(S + U)学习的方法,该方法结合了最小化对抗性损失和自正则化损失的目标,其目标是使用未标记的真实数据提高合成图像的真实性。与其它工作中只对噪声矢量或源图像设置条件的生成器不同,Bousmalis等人提出了一种利用对噪声矢量或源图像均设置条件的GANs的模型(图10)。训练分类器预测源图像和合成图像的类标签,训练鉴别器预测目标图像和合成图像的领域标签。此外,为了期望从相同的源图像得到具有相似前景和不同背景的合成图像,使用内容相似性来惩罚源和合成图像之间的巨大差异,仅通过一个掩蔽的双均方误差。网络的目标是通过求解优化问题来学习G, D, T:
![]()
其中,![]() 、
、![]() 和
和![]() 是控制损失之间权衡的参数。
是控制损失之间权衡的参数。![]() 、
、![]() 和
和![]() 分别为对抗性损失、softmax损失和内容相似损失。
分别为对抗性损失、softmax损失和内容相似损失。

- 非生成模型
深度数据挖掘的关键是从源样本和目标样本中学习领域不变表示。有了这些表示,两个域的分布可以足够相似,即使分类器是在源样本上训练的,也可以被愚弄并直接用于目标域。因此,表示形式是否混乱是知识传递的关键。受GAN的启发,引入鉴频器产生的域混淆损失,以提高无发生器深度DA的性能。领域对抗性神经网络(DANN)将一个梯度反转层(GRL)集成到标准架构中,以确保两个领域上的特征分布相似(图11)。该网络由共享特征提取层和两个分类器组成。DANN通过使用GRL将域混淆损失最大化,同时最小化域混淆损失(对于所有样本)和标签预测损失(对于源样本)。与上述方法相比,ADA通过解权值考虑了独立的源和目标映射,目标模型的参数由预先训练好的源初始化(图12)。这更加灵活,因为可以学习更多特定于领域的特性提取。ADDA通过迭代最小化以下函数来最小化源和目标表示距离,这与最初的GAN最相似:


其中映射![]() 和
和![]() 是从源和目标数据
是从源和目标数据![]() 和
和![]() 中学习的。C表示在源域上工作的分类器。第一个分类损失函数
中学习的。C表示在源域上工作的分类器。第一个分类损失函数![]() 通过使用标记的源数据训练源模型来优化。最小化第二个函数
通过使用标记的源数据训练源模型来优化。最小化第二个函数![]() 来训练鉴别器,同时第三个函数
来训练鉴别器,同时第三个函数![]() 学习一个域不变的表示。
学习一个域不变的表示。
Tzeng等人提出增加一个执行二进制域分类的域分类层,并设计了一个域混淆损失,以鼓励其预测尽可能接近二进制标签上的均匀分布。与以往匹配整个源和目标域的方法不同,Cao等人引入了选择性对敌网络(SAN)来解决大域到小域的部分转移学习,该方法假设目标标签空间是源标签空间的一个子空间。同时通过滤除离群源类来避免负转移,通过将域鉴别器分割成多个逐类域鉴别器来匹配共享标签空间中的数据分布,从而促进正转移。Motiian等人对域标签和类标签进行编码,生成四组对,并将典型的二值对抗性鉴别器替换为四类鉴别器。Volpi等训练了一个特征生成器(S)在源特征空间中进行数据增强,并通过对S中的特征进行极大极小博弈得到了一个域不变量特征。受Wasserstein GAN的启发,Shen等人利用判别器估计源样本与目标样本之间的经验Wasserstein距离,并优化特征提取器网络以对抗的方式使距离最小。在[97]中,我们将两个分类器作为鉴别器,训练它们最大化差异来检测源支持范围之外的目标样本,而训练一个特征提取器通过在支持范围附近生成目标特征来最小化差异。
4.1.3、基于重建的方法
在数据挖掘中,源样本或目标样本的数据重构是一项辅助任务,它同时关注于创建两个域之间的共享表示,并保持每个域的单个特征。

- 编码器和解码器重建
自编码器的基本框架是一个前馈神经网络,包括编码和解码过程。自动编码器首先将输入编码为一些隐藏的表示,然后将这个隐藏的表示解码为重建的版本。基于编码器-解码器重构的DA方法通常通过共享编码器学习域不变表示,并通过在源和目标域中丢失重构来维护域特殊表示。Glorot等人提出了基于堆叠去噪自动编码器(SDA)提取高级表示。通过在同一网络中重构各域数据的并集,高级表示可以同时表示源域和目标域数据。因此,在源域标记数据上训练的线性分类器可以用这些表示对目标域数据进行预测。尽管它们取得了显著的结果,但SDAs受到其高计算成本和缺乏高维特性的可伸缩性的限制。为了解决这些关键的限制,Tsai和Chien提出了边缘化SDA (mSDA),它通过线性去噪来边缘化噪声;因此,参数可以以封闭形式计算,而不需要随机梯度下降。[60]中提出的深度重构分类网络(DRCN)学习一种共享的编码表示,该表示为跨域目标识别提供了有用的信息(图13)。DRCN是一种CNN架构,它结合了两个管道和一个共享编码器。在编码器提供一个表示之后,第一个管道(即CNN)使用源标签进行监督分类,而第二个管道(即反卷积网络)使用目标数据进行非监督重建。
![]()
其中,![]() 是一个超参数用来控制分类和重建之间的权衡。
是一个超参数用来控制分类和重建之间的权衡。![]() 、
、 ![]() 和
和![]() 分别表示编码器、解码器和源分类器的超参数。
分别表示编码器、解码器和源分类器的超参数。![]() 是分类的交叉熵损失,
是分类的交叉熵损失,![]() 是平方损失
是平方损失![]() 用来进行重建,其中
用来进行重建,其中![]() 是x的重建值。域分类网络(DSNs)显式地和联合地对域表示的私有和共享组件建模。此外,共享解码器通过私有和共享表示来学习重构输入样本。然后,在共享表示上训练分类器。通过这样划分空间,共享的表示将不会受到特定于领域的表示的影响,从而可以获得更好的传输能力。通过在分离网络和自适应网络中引入混合对抗学习,发现分离损失很简单,且仅用于DSNs的重构加强了这种损失。Zhuang等人提出了使用深度自动编码器(TLDA)进行迁移学习,TLDA由两个编码层组成。嵌入编码层利用KL发散最小域间分布的距离,利用标签编码层的软最大损失对源域的标签信息进行编码。Ghifary等人将autoencoder扩展为一个模型,该模型联合学习来自相关领域的两种类型的数据重建任务:一种是自域重建,另一种是域间重建。
是x的重建值。域分类网络(DSNs)显式地和联合地对域表示的私有和共享组件建模。此外,共享解码器通过私有和共享表示来学习重构输入样本。然后,在共享表示上训练分类器。通过这样划分空间,共享的表示将不会受到特定于领域的表示的影响,从而可以获得更好的传输能力。通过在分离网络和自适应网络中引入混合对抗学习,发现分离损失很简单,且仅用于DSNs的重构加强了这种损失。Zhuang等人提出了使用深度自动编码器(TLDA)进行迁移学习,TLDA由两个编码层组成。嵌入编码层利用KL发散最小域间分布的距离,利用标签编码层的软最大损失对源域的标签信息进行编码。Ghifary等人将autoencoder扩展为一个模型,该模型联合学习来自相关领域的两种类型的数据重建任务:一种是自域重建,另一种是域间重建。
- 对抗重建
双学习首先由He等人提出,用于减少自然语言处理中对标记数据的要求。双元学习训练了两个“对立”的语言翻译者,如A到B和B到A。两个翻译者代表一个原对偶对,评估翻译的句子属于目标语言的可能性有多大,而闭环则衡量重构的句子与原译文之间的差异。受对偶学习的启发,利用对偶甘斯算法在深度数据挖掘中采用对偶重构。Zhu等人提出了一种循环GAN,在没有任何成对训练示例的情况下,可以将一个图像域的特征转换为另一个图像域(图14)。与对偶学习相比,cycle GAN使用了两个生成器而不是翻译器,它们学习映射G: X→Y和逆映射F: Y→X。两个鉴别器,D D X和Y,衡量实际生成的图像(G (X)≈Y或G (Y)≈X)由一个敌对的损失和原始的输入是如何重建后的序列两代(F (G (X))≈X或G (F (Y))≈Y)通过一个周期的一致性损失(损失重建)。因此,G (X)(或F (Y))的图像分布与Y(或X)的分布是不可区分的。

式中,![]() 为判别器D Y对映射函数G: X→Y产生的对抗性损失。
为判别器D Y对映射函数G: X→Y产生的对抗性损失。![]() 为范数重建损失。dual GAN和disco GAN同时提出,其核心思想与cycle GAN相似。在dual GAN中,生成器在镜像下采样层和上采样层之间配置了跳跃连接,使其成为一个u形网络来共享低级信息(例如,物体形状、纹理、杂乱等等)。对于鉴别器,采用Markovian patch-GAN架构来捕获局部高频信息。在disco GAN中,可以使用均方误差(MSE)、余弦距离、铰链损耗等各种形式的距离函数作为重构损耗,利用网络对图像进行平移,改变指定的属性,包括头发颜色、性别、方向等,同时保持其他所有分量。
为范数重建损失。dual GAN和disco GAN同时提出,其核心思想与cycle GAN相似。在dual GAN中,生成器在镜像下采样层和上采样层之间配置了跳跃连接,使其成为一个u形网络来共享低级信息(例如,物体形状、纹理、杂乱等等)。对于鉴别器,采用Markovian patch-GAN架构来捕获局部高频信息。在disco GAN中,可以使用均方误差(MSE)、余弦距离、铰链损耗等各种形式的距离函数作为重构损耗,利用网络对图像进行平移,改变指定的属性,包括头发颜色、性别、方向等,同时保持其他所有分量。

4.4.1、混合方法
为了获得更好的性能,一些上述方法被同时使用。Tzeng等人结合了域混淆损失和软标签损失,而使用了统计量(MMD)和架构标准(残差函数适应分类器)来进行无监督DA。Yan等将伪标签分配的类特异性辅助权重引入到原始MMD中。在DSN, encoder-decoder重建方法单独表示到私有和共享表示,虽然多准则或域混乱有助于使共享表示类似的损失和软子空间正交约束确保私有和共享表征之间的不同。Rozantsev等人使用了学习源和目标表示之间的MMD,并允许相应层的权重不同。Zhuang等人学习了通过编码器-解码器重构方法和KL散度的域不变表示。
4.2、异构的域适配
在异构DA中,源域和目标域的特征空间并不相同,![]() ,而且特征空间的维数也可能不同。根据特征空间的发散性,可以将异质性DA进一步划分为两种场景。在一个场景中,源和目标域都包含图像,特征空间的发散主要是由不同的感官设备(如可见光vs.近红外(NIR)或RGB vs. depth)和不同的图像风格(如草图vs.照片)引起的。在另一个场景中,源和目标领域中存在不同类型的媒体(例如,文本和图像以及语言和图像)。显然,第二个场景的跨域差距要大得多。采用浅层方法的异构数据挖掘主要分为对称变换和非对称变换两大类。对称变换学习特征变换,将源和目标特征投影到公共子空间上。异构特征增强(Heterogeneous feature augmentation, HFA)首先分别使用投影矩阵P和Q将源数据和目标数据转换成公共子空间,然后提出了两个新的特征映射函数:
,而且特征空间的维数也可能不同。根据特征空间的发散性,可以将异质性DA进一步划分为两种场景。在一个场景中,源和目标域都包含图像,特征空间的发散主要是由不同的感官设备(如可见光vs.近红外(NIR)或RGB vs. depth)和不同的图像风格(如草图vs.照片)引起的。在另一个场景中,源和目标领域中存在不同类型的媒体(例如,文本和图像以及语言和图像)。显然,第二个场景的跨域差距要大得多。采用浅层方法的异构数据挖掘主要分为对称变换和非对称变换两大类。对称变换学习特征变换,将源和目标特征投影到公共子空间上。异构特征增强(Heterogeneous feature augmentation, HFA)首先分别使用投影矩阵P和Q将源数据和目标数据转换成公共子空间,然后提出了两个新的特征映射函数:
![]()
![]()
![]()
用原始特征和零来扩充转换后的数据。利用标准支持向量机在线性和非线性情况下都能找到这些投影矩阵,并提出了一种交替优化算法来同时求解对偶支持向量机和寻找最优变换。Wang和Mahadevan将每个输入域视为一个由拉普拉斯矩阵表示的流形,并使用标签而不是对应来对齐流形。非对称转换转换源特性和目标特性中的一个以使其与另一个一致。Zhou等人提出了一种稀疏且类不变的特征变换矩阵,将学习到的分类器的权向量从源域映射到目标域。非对称正则化跨域传输(ARCt)利用在高斯RBF核空间中学习的非对称非线性转换将目标数据映射到源域。从[109]开始,ARC-t进行了基于度量学习的非对称转换,通过正则化器的变化在具有不同维度的领域间传递知识。由于我们关注的是深度DA,我们将感兴趣的读者推荐给[20],它总结了异构DA的浅层方法。然而,对于深层方法,到目前为止还没有太多的工作集中在异构DA上。非均质深层数据挖掘尚未提出特殊而有效的方法,非均质深层数据挖掘仍与一些均质深层数据挖掘方法相似。
4.2.1、基于不符的方法
在基于离散的方法中,网络通常共享或重用源域和目标域之间的前n层,从而将输入的特征空间限制在同一维。然而,在异构数据挖掘中,源域特征空间的维数可能与目标域特征空间的维数不同。在异构数据挖掘的第一种场景中,不同区域的图像可以直接调整为相同的维数,因此类准则和统计准则仍然是有效的,并被主要使用。例如,给定RGB图像及其配对深度图像,Gupta等利用CNN学习的中层表示作为监控信号,对CNN进行深度图像的再训练。将RGB对象探测器转换成RGB-D探测器不需要完成RGB-D数据,霍夫曼等。[111]首先训练一个RGB网络使用标记RGB数据从所有类别和整合网络与部分类别标签的深度数据,然后结合中层表示RGB和深度在fc6将模式到最终的对象类的预测。Mittal等人首先使用大型照片面部数据库对网络进行训练,然后使用小型合成草图数据库对其进行微调;Liu等人[113]以同样的方式将VIS深度网络传输到近红外域。在第二种情况下,不同介质的特征不能直接调整成相同的尺寸。因此,如果没有额外的过程,基于差异的方法就无法工作。Shu等人[81]提出了弱共享DTNs来跨异构域传输标记信息,特别是从文本域到图像域。DTNs将成对的数据(如文本和图像)作为两个sae的输入,然后是顶部的弱参数共享网络层。Chen等人[114]提出了传输神经树(TNTs),它由两个流网络组成,用于学习每个模态的领域不变特征表示。然后,使用转移神经决策森林(transfer - ndf)[115,116]和随机剪枝来适应预测层中的代表性神经元。
4.2.2、基于对抗的方法
使用生成模型可以在向异构目标数据传输源域信息的同时生成异构目标数据。Taigman等人采用复合损失函数,该函数由一个多类GAN损失、一个正则化分量和一个f-常性分量组成,将未标记的人脸照片转换为表情符号图像。为了生成基于文本的鸟和花图像,Reed等人[118]训练了一种基于混合字符级卷积-递归神经网络编码的文本特征的GAN。Zhang等人提出了带有条件增强的堆叠生成对抗网络(StackGAN),用于从文本中合成逼真的图像(图15)。它将综合问题分解为几个草图-细化过程。StageI GAN绘制出物体的原始形状和基本颜色,生成低分辨率图像,而Stage-II GAN完成物体的细节,生成高分辨率逼真图像。
4.2.3、基于重建的方法
对抗性重构同样适用于异构数据挖掘。例如,cycle GAN、dual GAN和disco GAN使用了两个生成器![]() 和
和![]() ,分别从照片生成草图和从草图生成照片。基于cycle GAN, Wang等人提出了一种多对抗式网络,通过利用生成子网络中隐含的不同分辨率的特征图来避免面部照片草图合成的伪影。
,分别从照片生成草图和从草图生成照片。基于cycle GAN, Wang等人提出了一种多对抗式网络,通过利用生成子网络中隐含的不同分辨率的特征图来避免面部照片草图合成的伪影。
5、多步域适配
对于多步骤数据挖掘,中间域的选择是问题特有的,不同的问题可能有不同的策略。
5.1、手工设计的方法
有时候,中间域可以通过经验来选择,即预先确定。例如,当源域是图像数据,而目标域是由文本数据组成时,一些标注过的图像显然会被抓取为中间域数据。基于夜间光强可以作为经济活动的代理这一常识,Xie等[65]利用一些夜间光强信息作为中间域,将白天卫星图像中的知识转移到贫困预测中。
5.1、基于实例的方法
在其他中间候选域较多的问题中,需要考虑一些自动选择准则。与Pan和Yang提出的实例转移方法类似,由于源域的样本不能直接使用,将源和目标数据的某些部分混合使用可以用于构建中间域。Tan等人提出了远域转移学习(DDTL),即远域不能仅通过一个中间域转移知识,而可以通过多个中间域进行关联。DDTL通过对源域和中间域中选定的实例和目标域中所有实例同时最小化重构误差,逐步从中间域中选择未标记数据。去除不相关的源数据后,所选择的中间域从源域逐渐向目标域靠拢:

其中![]() 、
、![]() 和
和![]() 是源数据
是源数据![]() 的重建,目标数据
的重建,目标数据![]() 和最终的数据
和最终的数据![]() 分别基于自编码器。
分别基于自编码器。![]() 和
和![]() 分别是编码器和解码器的参数。
分别是编码器和解码器的参数。![]() 和
和![]() ,
,![]()
![]() 分别为第i个源和中间实例的选择因子。
分别为第i个源和中间实例的选择因子。![]() 是一个正则化项,它避免了所有的
是一个正则化项,它避免了所有的![]() 和
和![]() 为零。在4.1.1节(几何准则)中提到的DLID模型[50]用源和目标域的子集构造中间域,其中源样本逐渐被目标样本取代。
为零。在4.1.1节(几何准则)中提到的DLID模型[50]用源和目标域的子集构造中间域,其中源样本逐渐被目标样本取代。

5.3、基于重建的方法
基于表示的方法冻结之前训练过的网络,并使用它们的中间表示作为新网络的输入。Rusu等人介绍了循序渐进的网络,它有能力在一系列经验中积累知识并将知识转移到新的领域(图16)。为了避免目标模型失去解源域的能力,他们为每个域构造了一个新的神经网络,同时通过横向连接以前学习的网络的特征来实现传输。在此过程中,对最新网络中的参数进行冻结,以记住中间域的知识。
6、深度域适配的应用
近年来,深度DA技术已成功应用于许多实际应用中,包括图像分类、目标识别、人脸识别、目标检测、风格转换等。在本节中,我们将介绍使用各种可视化深DA方法的不同应用示例。由于中提供了评估性能常用数据集的详细信息,所以本文不作介绍。
6.1、图像分类
由于图像分类是计算机视觉应用的一项基本任务,上述大部分算法最初都是为了解决这类问题而提出的。因此,我们不重复讨论这个应用程序,但我们展示了深度DA方法可以给图像分类带来多少好处。由于不同的文献在预处理步骤中使用不同的参数、实验协议和调优策略,很难直接对所有方法进行公平的比较。因此,与Pan和Yang的工作类似,我们展示了所提出的深度DA方法与仅使用深度网络的非自适应方法之间的比较结果。列出简单的实验从一些深DA提出了论文发表在表5。在[37],[79],[26],作者使用了Office-31数据集1的评价数据集,如图1所示(一个)。办公室的数据集是一个计算机视觉与图像分类数据集从三个不同的领域:亚马逊(A),数码单反相机(D),摄像头(W)。最大的领域是Amazon,它有2817张带标签的图片和31个相应的类,这些类包含在办公设置中经常遇到的对象。通过使用这个数据集,前面的工作可以显示方法在所有6个可能的DA任务中的性能。Long等[37]对标准AlexNet[8]、DANN方法[55]、MMD算法及其变体DDC[39]、DAN[38]、JAN[37]、RTN[32]进行了对比实验。Zellinger等人[79]评价了他们提出的CMD算法,并将其与其他基于离散的方法(DDC、deep CROAL[41]、DLID[50]、AdaBN[44])和基于对立的方法DANN进行了比较。Tzeng et al.[26]提出了一种结合软标签丢失和域混淆丢失的算法,并将其与DANN和DLID在监督DA设置下进行了比较。在[58]中,MNIST 2 (M), usps3 (U)和SVHN 4 (S)数字数据集。16. 采用渐进网络架构[66](如图1 (b)所示)进行跨域手写数字识别任务,实验给出了一些基于反向的方法的比较结果,如DANN、CoGAN[51]和ADDA[58],其中基线为VGG-16[12]。
6.2、人脸识别
当测试图像中出现训练图像中没有的变化时,人脸识别的性能会显著下降。数据集的移动可能由姿势、分辨率、光照、表情和模态引起。Kan等人提出了一种双移位自动编码器网络(BAE),用于跨视角、种族和成像传感器的人脸识别。BAE将源域样本移到目标域,利用目标域的几个局部邻域进行稀疏重构以保证其校正,反之亦然。[122]中的单样本每人域适应网络(Single sample per person domain adaptive network, SSPP-DAN)通过生成不同姿态的合成图像来增加源域的样本数量,并在现实人脸识别中通过GRL对敌训练来弥补合成图像和源域之间的差距(图17)。Sohn等人对大规模未标记视频、标记静止图像和合成图像使用了一种基于逆反的方法,提高了视频人脸识别的性能。考虑到年龄差异是微笑检测的困难问题,以及基于当前基准训练的网络在幼儿身上表现不佳,Xia等人[123]将DAN[38]和JAN[37](在4.1.1节中提到)应用于两个基线深度模型,即、AlexNet和ResNet,将成年人的知识传递给婴儿。
6.3、目标检测
近年来,基于区域的卷积神经网络(R-CNNS, Fast R-CNNs和Faster R-CNNs)推动了目标检测的进展。它们由窗口选择机制和分类器组成,分类器使用从网络神经网络中提取的特征预先训练标记的边界框。在测试时,分类器判断滑动窗口获得的区域是否包含该对象。虽然R-CNN算法是有效的,但是训练每个检测类别需要大量的边界盒标记数据。为了解决缺少标记数据的问题,考虑到窗口选择机制是域独立的,可以在分类器中使用深度DA方法来适应目标域。

因为R-CNNs在区域上的分类器就像分类一样,弱标记数据(如图像级类标签)对检测器是直接有用的。大部分工作学习的是有限边界框标记数据和大量弱标记数据的检测器。LSDA (large-scale detection through adaptive, LSDA)针对目标域训练一个分类层,然后使用预先训练好的源模型和输出层自适应技术直接更新目标分类参数。Rochan和Wang利用词向量建立弱标记源对象与目标对象之间的语义相关性,然后根据源对象的相关性将边界框标记的信息转移到目标对象。Tang等[128]在[126]和[127]的基础上,将视觉(基于LSDA模型)和语义相似(基于工作向量)转移到弱标记类别上训练目标检测器。Chen等人[129]在faster R-CNN中加入了图像级和实例级的自适应组件,并基于对抗性训练将域差异最小化。通过使用源域的边界框标记数据和目标域的弱标记数据[130],逐步对带有域转移样本和伪标记样本的预训练模型进行微调。
6.4、语义分割
用于稠密预测的全卷积网络模型(FCNs)在评估语义分割方面已经被证明是成功的,但在域移位的情况下,其性能也会下降。因此,一些工作也在探索使用弱标签来提高语义分割的性能。Hong等人使用了一种新颖的带注意力模型的编解码器架构,在源域传输弱类标记知识,而传输弱目标定位知识。语义切分中的深度无监督DA也受到了广泛的关注。Hoffman等人首先介绍了它,使用基于逆反训练的FCNs进行全局域对齐,利用类感知约束多实例丢失实现空间布局转移(图18)。Zhang等利用虚拟图像提高了对真实图像的分割性能。该算法利用图像的全局标签分布丢失和目标域中的地标超像素的局部标签分布丢失,有效地规范了语义分割网络的微调。Chen等提出了跨城市语义分割的框架。该框架对目标域内的像素/网格分配伪标签,并通过域对抗式学习联合使用全局对齐和类对齐来最小化域偏移。目标引导的蒸馏模块通过模仿预训练的源网络来适应真实图像的风格,空间感知适应模块利用固有的空间结构来减少领域的发散。不是在特征空间上操作一个简单的敌对目标,[138]使用GAN来处理域转移,即生成器将特征投射到图像空间,识别器在这个投影的图像空间上操作。

6.5、图像到图像翻译
近年来,随着深度数据挖掘技术的发展,图像到图像的翻译取得了很大的成功,并应用于风格转换等各种任务中。特别地,当源图像和目标图像的特征空间不一致时,需要采用异构DA进行图像到图像的转换。更多的图像到图像的转换方法使用成对的图像数据集,并将DA算法纳入生成网络。Isola等人提出了pix2pix框架,它使用一个条件GAN来学习从源图像到目标图像的映射。在PR2机器人中,Tzeng等人利用域混淆损失和成对损失使仿真数据适应于真实数据。然而,其他一些方法也解决了非配对设置,如CoGAN , cycle GAN, dual GAN和disco GAN。通过微调深度网络来匹配统计分布是实现图像到图像转换的另一种方法。Gatys等对CNN进行了微调,通过total loss来实现DA, total loss是内容和风格loss之间的线性组合,使目标图像按照保留内容的源图像的风格渲染。内容损失使原始图像和上层生成图像的特征表示的均方差最小,而风格损失使原始图像和上层生成图像的特征表示的各元素间的均方差最小。[46]证明了匹配特征映射的Gram矩阵等价于最小化MMD。与MMD不同的是,Li等人[42]提出了一种深度生成相关比对网络(DGCAN),该网络通过将内容和珊瑚损失应用于不同的层,将CAD合成图像和真实图像之间的域差异连接起来。
6.6、行人再识别
在社会上,重新识别身份(re-ID)变得越来越流行。当给定一个人的视频序列时,AAA识别这个人是否在另一个摄像机中,以弥补固定设备的限制。最近,当在一个数据集上训练的模型直接用于另一个数据集时,深层DA方法被用于re-ID。Xiao et al.提出了域引导的dropout算法来剔除无用的神经元,用于同时在多个数据集中重新识别人员。受cycle GAN和Siamese网络的启发,相似度保留生成对抗网络(SPGAN)以无监督的方式将标记的源图像转换到目标域,保持自相似度和域异度,然后利用监督特征学习方法对翻译后的图像进行Re-ID模型训练。
6.7、图像描述
近年来,图像字幕技术是计算机视觉和自然语言处理领域面临的新挑战。由于缺乏成对的图像-句子训练数据,DA利用其他源域的不同类型的数据来解决这一挑战。Chen等人提出了一种新的对抗训练程序(captioner v.s. critics),用于使用成对的源数据和未成对的目标数据进行跨域图像字幕。一种是对句子风格从源语域到目的语域的调整,而两种批评家,即领域批评家和多模态批评家,则是为了区分它们。Zhao等人利用双重学习机制对目标域中有限数据的预训练源模型进行了微调。
7、结论
从广义上讲,深度DA是利用深度网络来提高DA的性能,如利用深度网络提取特征的浅DA方法。在狭义上,深度数据挖掘是基于深度学习架构设计的数据挖掘和优化反向传播。在这篇综述论文中,我们关注这个狭义的定义,并且回顾了关于可视化分类任务的深度DA技术。深度DA分为同质DA和异构DA,并进一步分为监督、半监督和非监督设置。第一种设置是最简单的,但通常由于需要标记数据而受到限制;因此,大多数以前的工作集中在无监督的情况下。半监督深度DA是一种混合方法,结合了监督和非监督设置的方法。此外,考虑到源域和目标域之间的距离,深度数据挖掘方法可以分为一步数据挖掘和多步数据挖掘。当距离较小时,可以根据训练损失使用一步数据挖掘。它包括基于差异的方法、基于对立的方法和基于重构的方法。当源域和目标域没有直接关联时,可以使用多步骤(或传递)DA。多步骤数据挖掘的关键是对中间域的选择和利用,因此可以分为三类:手工选择机制、基于特征的选择机制和基于表示的选择机制。虽然深度DA最近取得了成功,但仍有许多问题有待解决。首先,现有的算法大多集中于同构深度数据挖掘,假设源域和目标域之间的特征空间是相同的。然而,这一假设在许多应用中可能并不正确。我们希望在没有这种严重限制的情况下传递知识,并利用现有数据集来帮助完成更多任务。异构深度数据挖掘在未来可能会受到越来越多的关注。此外,深度DA技术已成功应用于许多实际应用中,包括图像分类和风格转换。我们还发现,只有少数论文在分类和识别之外解决了自适应问题,如目标检测、人脸识别、语义分割和人的再识别。如何在没有或非常有限的数据量的情况下完成这些任务,可能是深度DA在未来几年应该解决的主要挑战之一。最后,由于现有的深度DA方法以对齐边缘分布为目标,它们通常假定源域和目标域共享标签空间。但是,在实际的场景中,源和目标域的映像可能来自不同的类别集,或者只有少数感兴趣的类别是共享的。















 1645
1645











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











