











读完这篇论文,有两个比较意外的感受。第一,惊讶于如此基础性的内容,之前竟然没有相关研究。第二,作者的思路(包括网络构造、训练及评价指标)也比较简单。这篇论文获得了ICLR满分,并被评为Spotlight。可见,基础性的东西仍然存在研究的空间。这篇论文中,作者的研究虽然看起来简单,却非常需要对该领域较高的熟悉度。因为越是基础性的研究,越需要严谨准确的研究过程和方法。
一般来讲,我们的常规认识是:随着卷积层的增多,尤其是使用pooling层,导致图像中目标的位置信息都被丢弃了。
然而,事实上并不是会这样。这篇论文的研究成果告诉我们。位置信息没有丢失,只是跟语义信息共享特征了。我们之所以没有过多的去研究位置信息,只是因为目前的针对CNN的使用并没有迫切的需要使用位置信息。
这篇文章只回答了CNN存储了位置信息,但是并没有给出如何有效提取位置信息,只是告诉我们在图像中为增加zero-padding可以帮助CNN提取位置信息,或者说更关注位置信息。
灌入如何提取位置信息,在这一篇论文中,我也将其翻译出来了。
本博客 所翻译论文: How much Position Information Do Convolutional Neural Networks Encode
文章下载地址。
摘要
与全连接网络相比,卷积神经网络 (CNN) 通过学习与具有有限空间范围的局部滤波器相关联的权重来提高效率。这意味着滤波器可能知道它在看什么,但不知道它在图像中的位置。关于绝对位置的信息本质上是有用的,可以合理地假设,如果有办法的话,深度CNN可能会隐式地学习编码这些信息。在本文中,我们检验了这一假设,揭示了在常用神经网络中编码的绝对位置信息的惊人程度。一组全面的实验证明了这一假设的有效性,并阐明了这些信息是如何以及在何处被表示的,同时提供了从深层CNN中获取位置信息的线索。
1. Introduction
卷积神经网络(CNN)在许多计算机视觉任务中取得了最先进的成果,例如,目标分类(Simonyan&Zisserman,2014;He等人,2015)和目标检测(Redmon等人,2015;Ren等人,2015)、人脸识别(Taigman等人,2014)、语义分割(Long et al.,2015;Chen et al.,2018;Noh et al.,2015)和显著性检测(Cornia et al.,2018;Li et al.,2014)。然而,CNN在深度学习中因缺乏可解释性而面临一些批评(Lipton,2016)。
经典的CNN模型被认为是空间不可知的,因此胶囊(Sabour et al.,2017)或循环网络(Visin et al.,2015)已被用于建模学习特征层内的相对空间关系。目前尚不清楚CNN是否捕获了在位置相关任务(例如语义分割和显著目标检测)中非常重要的任何绝对空间信息。如图1所示,被确定为最显著的区域(Jia&Bruce,2018)倾向于靠近图像的中心。在检测裁剪后的图像的显著性时,即使视觉特征没有改变,最显著的区域也会移动。这有点令人惊讶,因为CNN滤波器的空间范围有限,通过它可以解释图像。在本文中,我们通过进行一系列随机试验来检验绝对位置信息的作用,假设CNN确实可以学习编码位置信息作为决策的线索。**我们的实验表明,位置信息是通过常用的填充操作(zero-padding)隐式学习的。**在应用卷积时,zero-padding被广泛用于保持相同的维数。然而,它在表征学习中的隐藏效应一直被忽略。这项工作有助于更好地理解CNN中学习到的特征的性质,并为未来的研究强调了一个重要的观察结果和富有成效的方向。

图1:输入图像(左)的突出区域的样本预测,以及略微裁剪的版本(右)。裁剪导致在相对于中心的特征的位置转移。值得注意的是,尽管没有明确的位置编码和输入到输入中的位置,但是对被视为突出的区域的输出和决定具有显着影响。
以前的工作试图将学习到的feature map可视化,以揭开CNN如何工作的神秘面纱。一个简单的想法是计算损失函数并将其向后传递到输入空间,以生成能够最大化给定单元激活的模式图像(Hinton et al.,2006;Erhan et al.,2009)。但是,当层的数量增加时,很难对这种关系进行建模。最近的工作(Zeiler&Fergus,2013)提出了一种非参数可视化方法。利用反卷积网络Deconvolutional Networks(Zeiler et al.,2011)将学习的特征映射回输入空间,其结果揭示了特征映射实际学习的模式类型。另一项工作(Selvaraju et al.,2016)提出将像素级梯度与加权类激活映射相结合,以定位最大化特定类激活的区域。作为可视化策略的替代方案,一项实证研究(Zhang et al.,2016)表明,一个简单的网络可以在噪声标签上实现零训练损失。我们同意应用随机测试来研究CNN学习特征的类似想法。然而,我们的工作不同于现有的方法,因为这些技术仅呈现有趣的可视化或理解,但无法揭示CNN模型编码的空间关系。
总之,CNN已成为一种处理端到端全连接网络所带来的大量权重的方法。由此产生的一个折衷结果是,卷积核及其学习的权重只能看到图像的一小部分。这似乎意味着网络更依赖于纹理和颜色等线索而不是形状的解决方案(Baker等人,2018年)。然而,位置信息为物体可能出现在图像中的位置(例如天空中的鸟)提供了强有力的线索。可以想象,网络可能充分依赖于这样的线索,即它们隐式地编码空间位置以及它们所代表的特征。我们的假设是,深层神经网络的成功部分是通过学习事物的内容和位置。本文对这一假设进行了检验,并提供了令人信服的证据,证明CNN确实在很大程度上依赖并学习了图像中的空间定位信息,这一点超出了人们的预期。
2. position information in CNNs

2.1 POSITION ENCODING NETWORK

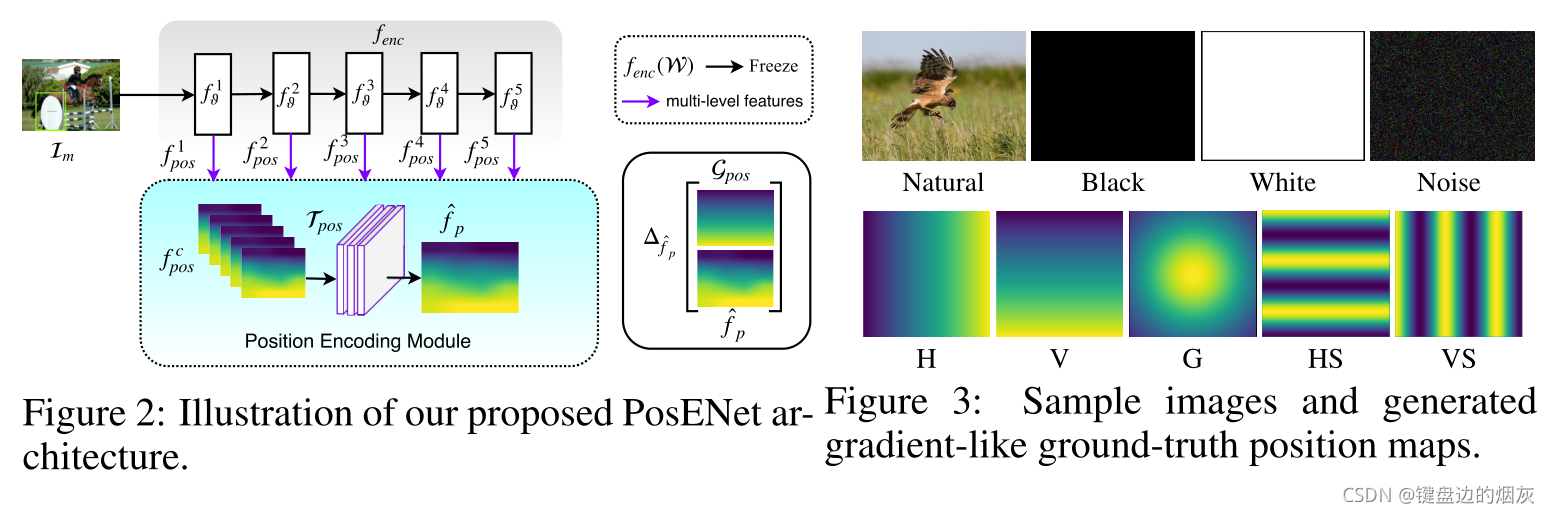

编码模块的主要目标是验证在分类标签上训练时是否隐式学习位置信息。此外,位置编码模块对隐藏位置信息和梯度状ground-truth掩模之间的关系进行建模。如果feature map中没有编码位置信息,则输出预计为随机输出,反之亦然(忽略图像内容的任何指导)。
2.2 合成数据和ground-truth生成
为了验证网络中位置信息的存在,我们通过将归一化的类似梯度的position map分配为图 3 所示的ground-truth来实现随机化测试。我们首先在水平 (H) 和垂直 (V) 方向中生成类似梯度的掩码。同样,我们应用高斯滤波器来设计另一种类型的ground-truth图,高斯分布 (G)。生成这三种模式的主要动机是验证模型是否可以学习一个或两个轴上的绝对位置。此外,我们还创建了两种类型的重复模式,水平和垂直条纹(HS,VS)。无论方向如何,多级特征中的位置信息都可能通过编码模块fpem的转换进行建模。我们设计的梯度ground-truth可以看作是一种随机标签,因为输入图像和ground-truth之间没有位置相关性。由于位置信息的提取与图像内容无关,因此可以选择任何图像数据集。同时,我们还构建了合成图像,例如黑、白和高斯噪声来验证我们的假设。
2.3 训练网络

3. EXPERIMENTS
3.1 数据集和评估指标
Dataset: 我们使用DUT-S数据集Wang et al.(2017)作为我们的训练集,其中包含10533张训练图像。遵循Zhang等人(2017)使用的通用训练协议;Liu&Han(2017),我们在DUT-S的训练集上训练模型,并评估PASCAL-S Li等人(2014)数据集的自然图像上是否存在位置信息。如第2.2节所述,也使用合成图像(白色、黑色和高斯噪声)。注意,我们遵循显著性检测中使用的公共设置,只是为了确保训练集和测试集之间没有重叠。然而,由于位置信息相对独立于内容,任何图像都可以用于我们的实验。
Evaluation Metrics: 由于位置编码测量是一个新的方向,因此没有通用的度量标准。我们使用两种不同的自然选择度量(Spearmen相关性(SPC)和平均绝对误差(MAE))来测量位置编码性能。SPC定义为ground-truth和预测位置map之间的斯皮尔曼相关性。为了便于解释,我们将SPC分数保持在[-1,1]范围内。MAE是预测位置map和ground-truth梯度位置map之间的平均像素差异。
3.2 实施细节
我们使用为ImageNet分类任务预训练的网络初始化架构。位置编码分支中的新层由xavier initialization Glorot&Bengio(2010)初始化。我们使用随机梯度下降法对网络进行了15个阶段的训练,动量为0.9,权重衰减为0.0001。在训练和推理过程中,我们将每个图像的大小调整为224×224的固定大小。由于多层次特征的空间范围不同,我们将所有特征映射对齐为28×28的大小。我们报告如下基线的实验结果:VGG表明PosENet基于从VGG16模型中提取的特征。类似地,ResNet表示ResNet-152和PosENet的组合。PosENet单独表示仅应用PosENet模型直接从输入图像学习位置信息。H、 V、G、HS和VS分别代表五种不同的ground-truth模式:水平和垂直梯度、二维高斯分布、水平和垂直条纹。
3.3 EXISTENCE OF POSITION INFORMATION
预训练模型中的位置信息:我们首先通过实验验证了在预训练模型中编码的位置信息的存在性。按照相同的协议,我们对基于VGG和ResNet的网络进行每种类型的ground-truth训练,并在表1中报告实验结果。我们还报告了只训练PosENet而不使用任何预训练模型来证明位置信息不是由对象的先验知识驱动的结果。我们的实验并不关注在指标上实现更高的性能,而是验证CNN模型编码了多少位置信息,或者PosENet提取这些信息有多容易。注意,在本实验中,我们只使用了一个卷积核大小为3×3的卷积层,而没有在PosENet中进行任何填充。
如表1所示,PosENet(VGG和ResNet)可以很容易地从预训练的CNN模型中提取位置信息,尤其是基于ResNet的PosENet模型。然而,单独训练PosENet(PosENet)可以在不同的模式和源图像中获得更低的分数。这一结果意味着很难单独从输入图像中提取位置信息。
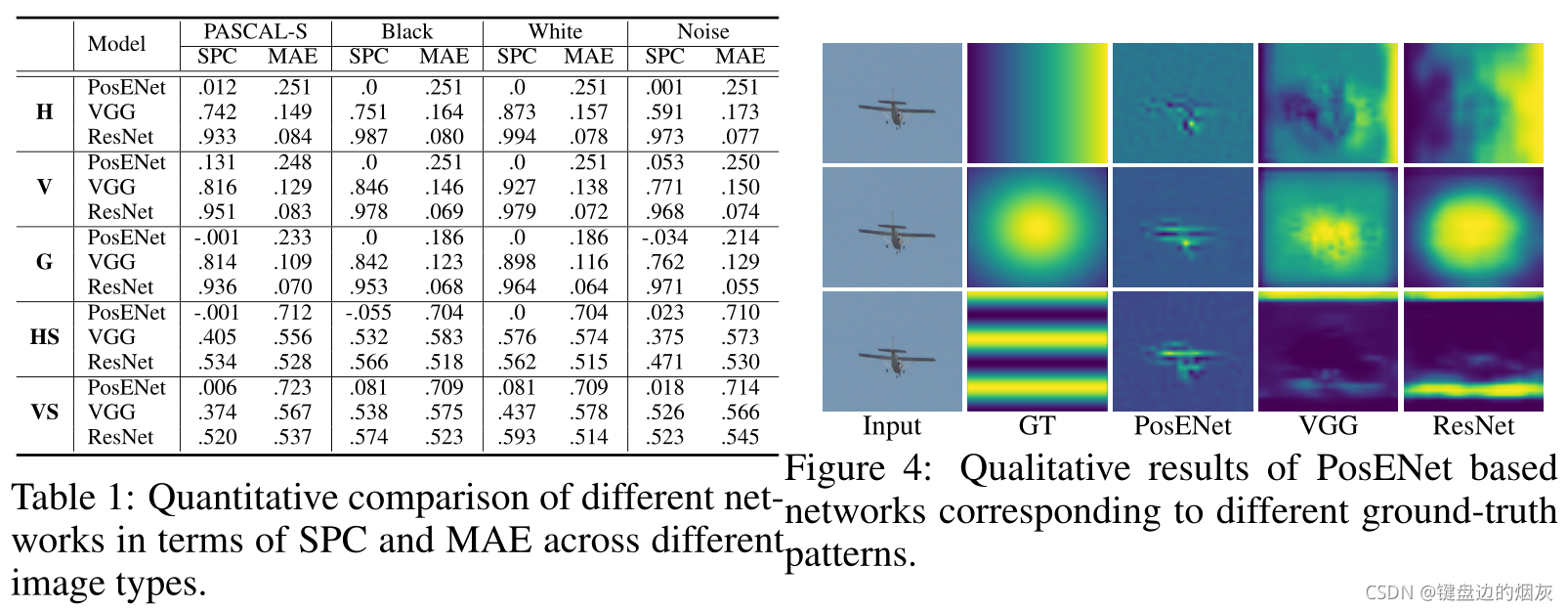
PosENet仅在与深度编码器网络耦合时才能提取与ground-truth位置图一致的位置信息。如前所述,鉴于Zhang等人(2016)忽略了与输入的相关性,生成的ground-truth map可视为一种随机化测试。然而,测试集在不同的ground-truth模式上的高性能表明,该模型不是盲目地过度拟合噪声,而是提取真实位置信息。然而,与其他模式相比,我们观察到重复模式(HS和VS)的性能较低,这是由于模型的复杂性,特别是ground-truth和绝对位置之间缺乏相关性(表1的最后两行)。H模式可视为正弦波的四分之一,而条纹模式(HS和VS)可视为正弦波的重复周期,这需要更深入的理解。
图4显示了跨不同模式的几种体系结构的定性结果。我们可以看到与H、G和HS模式对应的预测和ground-truth位置map之间的相关性,这进一步揭示了这些网络中位置信息的存在。定量和定性结果有力地验证了我们的假设,即位置信息隐式编码在每个体系结构中,没有任何明确的监督。
此外,单独的 PosENet 没有显示出基于合成数据输出梯度图的能力。我们在第 4.1 节中进一步探讨了图像语义的影响。有趣的是,注意到不同体系结构之间的性能差距,特别是基于ResNet的模型比基于VGG16的模型实现了更高的性能。这背后的原因可能是架构中使用了不同的卷积核,或者语义内容的先验知识程度不同。我们将在下一个实验中进行烧蚀研究,以便进一步研究。在本文的其余部分中,我们只关注自然图像、PASCAL-S数据集和三种代表性模式H、G和HS。
3.4 分析PoseNet
在本节中,我们通过强调两个关键的设计选择来进行消融研究,以检查提出的位置编码网络的作用。(1) 改变卷积核大小在位置编码模块中的作用以及(2)我们添加卷积层的层数,以从多级特征中提取位置信息。
Impact of Stacked Layers: 表1中的实验结果表明存在从对象分类任务中学习到的位置信息。在本实验中,我们改变了PosENet的设计,以检验是否有可能更准确地提取隐藏位置信息。先前实验(表1)中使用的PosENet只有一个卷积层,其内核大小为3×3。在这里,我们将一组不同长度的卷积层应用于PosENet,并在表2(a)中报告实验结果。尽管堆栈大小不同,但我们的目标是保留一个相对简单的PosENet,只允许有效读取位置信息。如表2所示,我们在堆叠多层时将内核大小固定在3×3。在PosENet中应用更多层可以改善所有网络位置信息的读出。一个原因可能是堆叠多个卷积滤波器允许网络具有更大的有效接收场,例如,两个3×3卷积层在空间上等于一个5×5卷积层Simonyan&Zisserman(2014)。另一种可能性是,位置信息的表示方式可能需要一阶以上的推断(例如,线性读数)。
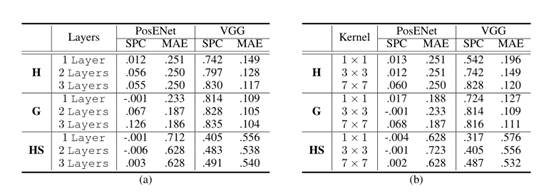
表2: PASCAL-S数据集在SPC和MAE方面的定量比较(a)层数和(b)卷积核大小不同。注意,(a)卷积核大小固定为3×3,但PosENet中使用了不同数量的卷积层。(b) 层数固定为一层,但我们在PosENet中使用不同的内核大小。
不同卷积核大小的影响:我们仅使用一个具有不同尺寸的卷积核的卷积层来进一步验证PosENet,并在表2(b)中报告了实验结果。**从表2(b)中,我们可以看到,与尺寸较小的卷积核相比,较大的卷积核可能捕获更多的位置信息。**这一发现意味着位置信息可能在空间上分布在层内和特征空间中,因为更大的感受野可以更好地解析位置信息。
在图5中,我们进一步展示了不同的层数和卷积核的大小对学习位置信息的视觉影响。

图5:左:在PoseNet中应用更多层(左七层)和不同卷积核大小(右七层)的效果。(左→ 右图):GT(G)、PosENet(L=1,KS=1)、PosENet(L=2,KS=3)、PosENet(L=3,KS=7)、VGG(L=1,KS=1)、VGG(L=2,KS=3)、VGG(L=3,KS=7)。
PS:L表示卷积层的数量,KS表示卷积核的尺寸。
4.5 存储的位置信息在哪里?

4. 位置信息来自哪里?

图6:Zero-padding对高斯模式的影响。从左到右:GT(G),Pad=0(.286.186),Pad=1(.227.180),Pad=2(.473.169),VGG Pad=1(.928.085),VGG Pad=0(.405.170)。
4.1 个案研究


图7: PosENet(1strow)、VGG(2ndrow)和ResNet(3rdrow)的误差热图。
4.2 Zero-padding驱动位置信息


表5:VGG模型(a)SOD和(b)语义分割使用和不使用Zero-padding
我们相信,在这两项任务上预训练的CNN模型比分类任务能学到更多的位置信息。为了验证这一假设,我们将在ImageNet上预训练的VGG模型作为基线。同时,我们从零开始训练了两个用于语义分割和显著性检测的VGG模型,分别表示为VGG-SS和VGG-SOD。然后,我们按照第3.3节中使用的协议对这三个VGG模型进行微调。从表6中,我们可以看到VGG-SS和VGG-SOD模型的性能大大优于VGG。这些实验进一步揭示了Zero-padding策略在位置相关任务中起着重要作用,这一观察在视觉问题的神经网络解决方案中长期被忽略。
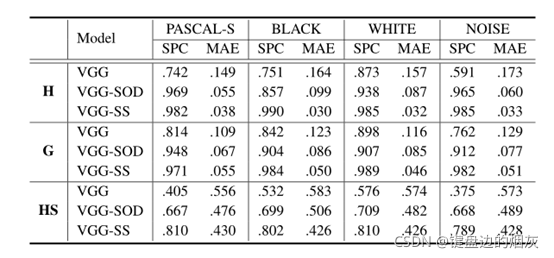
表6:分类、SOD和语义分割预训练的VGG模型比较。
5. CONCLUSION
本文探讨了卷积神经网络中绝对位置信息隐式编码的假设。实验表明,位置信息在很大程度上是可用的。更详细的实验表明,更大的感受野或位置信息的非线性读出进一步增强了绝对位置的读出,从一个简单的单层3×3 PosENet中已经非常强大。实验还表明,当不存在语义线索时,这种恢复是可能的,并且来自语义信息的干扰表明对what(语义特征)和where(绝对位置)进行联合编码。结果表明,Zero-padding和边界作为锚定,空间信息从中衍生出来,并随着空间抽象的发生最终传播到整个图像。这些结果证明了CNN的一个基本特性,这是迄今为止未知的,需要进一步探索。
博客总结,分析论文
这篇论文是关于CNN提取图形中目标绝对位置的初探工作。通过大量的定量和定性的分析,作者给出了下面的结论:
首先,他们做了啥:作者选择使用VGG和ResNet作为基础模型,所提出的位置编码网络(PosENet)就是基于这两个深度网络模型的。用他们的话说就是:我们使用基于ResNet和VGG的框架结构,通过删除平均池化层和分类层来构建编码器网络,也就是说:他们用VGG或ResNet提取图像的feature map。然后在使用双线性插值把每一个卷积层的feature map的尺寸统一,然后给弄成包含位置信息的特征。
具体的结论:
- 第一:在冻结预训练的VGG和ResNet的卷积参数,而单独训练他们提出的PosENet模型的参数时,他们发现这样做完全无法提取位置信息。然后他们的接论是位置信息是无法被单独提取的。然后他们进一步思考了可能会影响位置信息的一些特征,比如卷积核的尺寸和卷积层的深度,以及padding的使用数量,是一圈padding还是两圈padding。
- 第二,进一步做实验,证明了卷积核的大小和卷积层的堆叠数量对提取位置信息的影响很大,至少他们之间存在关系。很显然,卷积核越大它的感受野越大,自然包含了位置信息。作者总结的结果是:这一发现意味着位置信息可能在空间上分布在层内和特征空间中,因为更大的感受野可以更好地解析位置信息。关于卷积层的多少,他们发现了卷积层的数量对提取位置信息影响很大。但是他们总结的原因可能不是那么理想:在PosENet中应用更多的卷积层可以改善所有网络位置信息的读出。一个原因可能是堆叠多个卷积滤波器允许网络具有更大的有效接收场,例如,两个3×3卷积层在空间上等于一个5×5卷积层Simonyan&Zisserman(2014)。也就是说,他们还是把多层卷积的功劳归结到卷积核的尺寸上了。
- 第三,关于padding的影响:总的来讲就是,padding圈数增加,提取位置的效果就会更好。

















 63
63

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









