






前言
vLLM是用于LLM推理和服务的工具库。
vllm由以下几点突出的“快”:
最先进的服务吞吐量
PagedAttention
连续批处理传入请求
快速模型执行以CUDA/HIP graph
量化:GPTQ, AWQ, SqueezeLLM, FP8 KV缓存
优化CUDA内核
文档和代码:
https://docs.vllm.ai/en/stable/
https://github.com/vllm-project/vllm
本文主要给出一些重要的文档指导路由,以及如何用vllm自定义的部署llm,并用python进行服务化。
一、文档指导路由
主要需要仔细学习的doc有:
安装:https://docs.vllm.ai/en/latest/getting_started/installation.html
支持的模型:https://docs.vllm.ai/en/latest/models/supported_models.html
很多例子:https://docs.vllm.ai/en/stable/getting_started/examples/examples_index.html
起一个engine的各种参数说明:https://docs.vllm.ai/en/stable/models/engine_args.html
支持的量化:https://docs.vllm.ai/en/stable/quantization/supported_hardware.html
引擎服务的例子:https://github.com/vllm-project/vllm/blob/main/vllm/entrypoints/api_server.py
engine两个尤其要好好看的类
llm engine:https://github.com/vllm-project/vllm/blob/main/vllm/engine/llm_engine.py
engine的异步版本:https://github.com/vllm-project/vllm/blob/main/vllm/engine/async_llm_engine.py
1.1 安装
OS: Linux
Python: 3.8 – 3.11
GPU: compute capability 7.0 or higher (e.g., V100, T4, RTX20xx, A100, L4, H100, etc.)
pip install vllm1.2 支持的模型
 按照模型架构分的,很多常用的都在
按照模型架构分的,很多常用的都在
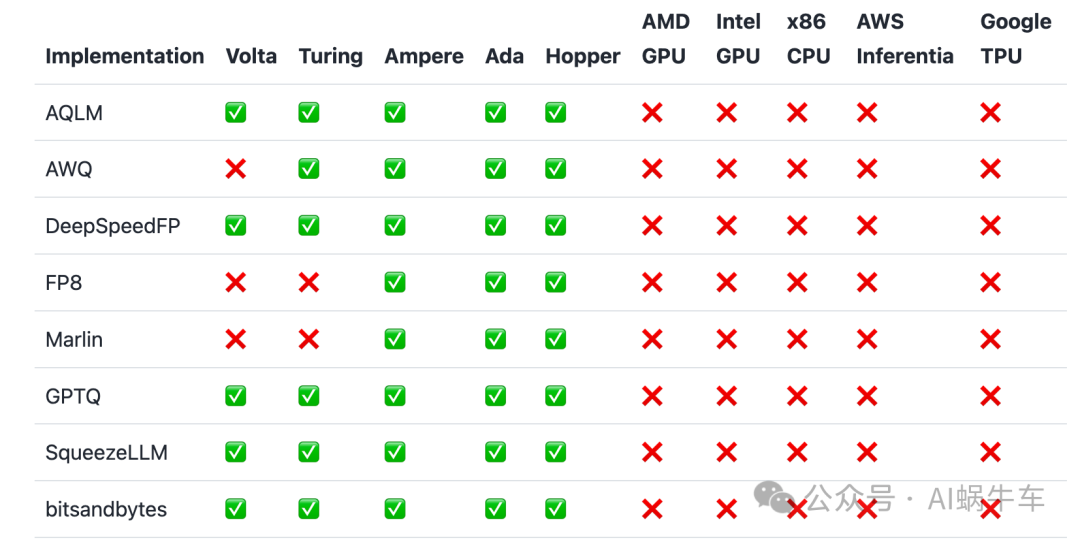
1.3 支持的量化方法
二、异步服务部署example
参考:https://github.com/vllm-project/vllm/blob/main/vllm/entrypoints/api_server.py
这个文件目前一直在更新,会有一些新的组件,或者代码的重新编排,我是按照当时情况来参考并创作这个example的,可能和后面大家看到这个链接的时候不一致,存在这种情况。
接下来和大家一起写一个对于vllm的异步小服务(基于flask).
需要安装各种环境:
wget https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-py38_4.8.3-Linux-x86_64.sh --no-check-certificate
sh Miniconda3-py38_4.8.3-Linux-x86_64.sh
conda create -n ml python=3.9
pip install vllm
pip install transformers
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia以下中的model path要替换成自己的llm的路径
2.1 request类
llm大多数都是chat服务,所以这里主要模拟一个chat request
request_data.py
from transformers import AutoTokenizer
class ChatRequest(object):
def __init__(self):
self.messages = []
self.is_stream = False
self.model_args = {}
self.functions = []
self.model_name = None
def from_dict(self, request_dict):
self.messages = request_dict.get("messages", []) # Dict
self.model_name = request_dict.get("model_name") # str
self.is_stream = request_dict.get("stream", False)
self.functions = request_dict.get("tools", [])
temperature = request_dict.get("temperature")
if temperature is not None:
self.model_args["temperature"] = temperature
do_sample = request_dict.get("do_sample")
if do_sample is not None:
self.model_args["do_sample"] = do_sample
max_new_tokens = request_dict.get("max_new_tokens")
if max_new_tokens is not None:
self.model_args["max_new_tokens"] = max_new_tokens
top_p = request_dict.get("top_p")
if top_p is not None:
self.model_args["top_p"] = top_p
top_k = request_dict.get("top_k")
if top_k is not None:
self.model_args["top_k"] = top_k
return self
def is_success(self):
return self.model_name and self.messages != []
def get_prompt(self, tokenizer: AutoTokenizer):
print("memssage:", self.messages)
text = tokenizer.apply_chat_template(self.messages, tokenize=False, add_generation_prompt=True)
return text主要包含了一些常用的参数
temperature
top_p
top_k
messages 模型输入
...
通过对flask post请求的接收,对request data结构体进行解析结构化。
2.2 flask服务
vllm_server.py
import argparse
import json
import ssl
from typing import AsyncGenerator
import uvicorn
from fastapi import FastAPI, Request
from fastapi.responses import JSONResponse, Response, StreamingResponse
from vllm.engine.arg_utils import AsyncEngineArgs
from vllm.engine.async_llm_engine import AsyncLLMEngine
from vllm.sampling_params import SamplingParams
from vllm.utils import random_uuid
from request_data import ChatRequest
from transformers import AutoTokenizer
TIMEOUT_KEEP_ALIVE = 5 # seconds.
app = FastAPI()
engine = None
tokenizer = None
local_path = "model_path"
tokenizer = AutoTokenizer.from_pretrained(local_path, trust_remote_code=True)
@app.post("/chat")
async def chat(request: Request) -> Response:
request_dict = await request.json()
print(request_dict)
chat_request = ChatRequest()
chat_request.from_dict(request_dict)
model_args = chat_request.model_args
default_parameters = {
'use_beam_search': False,
"max_tokens": 1200,
"temperature": 0.2,
"top_k": 1,
"top_p": 0.6,
"do_sample": False,
}
default_parameters['max_tokens'] = model_args.get('max_new_tokens', default_parameters['max_tokens'])
default_parameters.update(model_args)
default_parameters.pop("max_new_tokens", None)
default_parameters.pop("do_sample")
print("default_parameters", default_parameters)
sampling_params = SamplingParams(**default_parameters)
request_id = random_uuid()
assert engine is not None
print("tokenizer:", chat_request.get_prompt(tokenizer))
results_generator = engine.generate(chat_request.get_prompt(tokenizer=tokenizer), sampling_params, request_id)
# Streaming case
async def stream_results() -> AsyncGenerator[bytes, None]:
async for request_output in results_generator:
prompt = request_output.prompt
text_outputs = [
prompt + output.text for output in request_output.outputs
]
ret = {"text": text_outputs}
yield (json.dumps(ret) + "\0").encode("utf-8")
if chat_request.is_stream:
return StreamingResponse(stream_results())
# Non-streaming case
final_output = None
async for request_output in results_generator:
if await request.is_disconnected():
# Abort the request if the client disconnects.
await engine.abort(request_id)
return Response(status_code=499)
final_output = request_output
assert final_output is not None
prompt = final_output.prompt
print("final_output.outputs:", final_output.outputs)
print("outputs length:", len(final_output.outputs))
# text_outputs = [prompt + output.text for output in final_output.outputs]
single_output = final_output.outputs[0].text
message = {
"role": "assistant",
"content": single_output,
}
return JSONResponse(message)
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--host", type=str, default=None)
parser.add_argument("--port", type=int, default=8000)
parser.add_argument(
"--root-path",
type=str,
default=None,
help="FastAPI root_path when app is behind a path based routing proxy")
parser = AsyncEngineArgs.add_cli_args(parser)
args = parser.parse_args()
engine_args = AsyncEngineArgs.from_cli_args(args)
engine = AsyncLLMEngine.from_engine_args(engine_args)
app.root_path = args.root_path
uvicorn.run(app,
host=args.host,
port=args.port,
log_level="debug",
timeout_keep_alive=TIMEOUT_KEEP_ALIVE)流式infer和直接infer是不一样的链路
2.3 启动flask服务
import os
def main(local_path, tensor_parallel_size, max_model_len, port, dtype, router_path, gpu_util):
os.system(f"python ./vllm_demo/vllm_server.py --model={local_path} --trust-remote-code --tensor-parallel-size {tensor_parallel_size} --max-model-len {max_model_len} --port {port} --dtype {dtype} --root-path {router_path} --gpu-memory-utilization {gpu_util}")
if __name__ == '__main__':
main(local_path="model_path",
tensor_parallel_size=1,
max_model_len=4096,
port=5000,
router_path="/localhost",
dtype="float16",
gpu_util=0.9)参数说明:https://docs.vllm.ai/en/stable/models/engine_args.html
其中
--tensor-parallel-size 是一个node上显卡的个数
--pipeline-parallel-size 是node的数量
--max-model-len 模型的上下文长度
--dtype加载模型权重的数据类型
说明: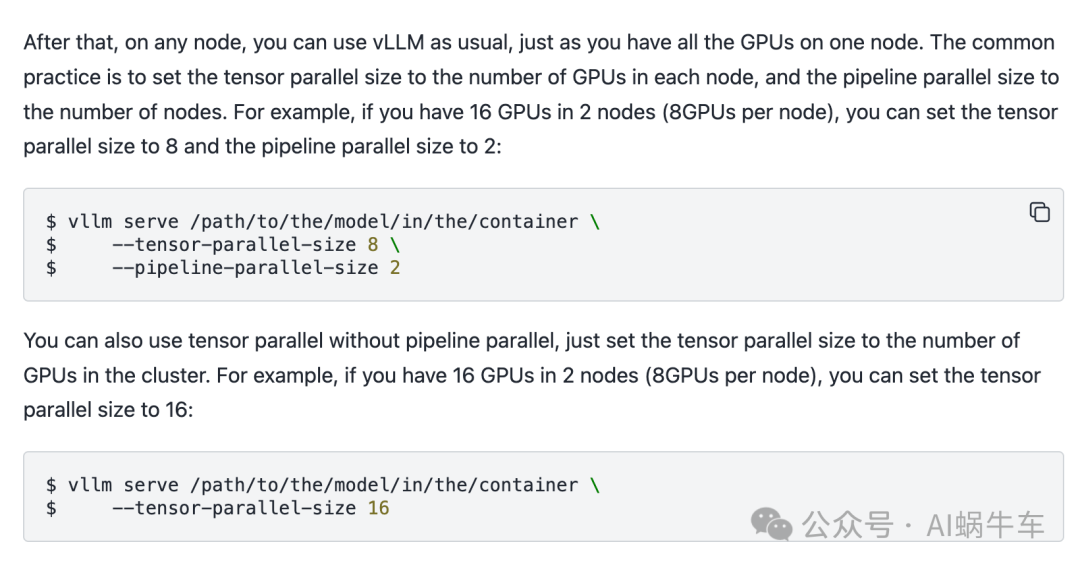
2.4 client
启动服务之后用client进行请求,即可 完成服务的client-server的测试
stream方式进行post请求:
import requests
import json
def stream_chat(url, data):
try:
with requests.post(url, data=data, stream=True) as response:
response.raise_for_status()
for line in response.iter_lines():
if line:
decoded_line = line.decode('utf-8')
if decoded_line.startswith('data:'):
# 提取JSON字符串并解析为Python字典
json_data = decoded_line.replace('data: ', '')
data = json.loads(json_data)
print(data) # 打印解析后的数据
except requests.exceptions.HTTPError as err:
print(f"HTTP error occurred: {err}")
except Exception as e:
print(f"An error occurred: {e}")
def get_test_final_prompt(file_path):
with open(file_path, 'r') as file:
prompt = file.read()
return prompt
def get_prompt_msg(file_path):
messages_str = get_test_final_prompt(file_path=file_path)
# 定义正则表达式进行匹配
pattern = messages_str.split("user:\n")
user_input = pattern[1]
system_content = pattern[0].split("system:\n")[1]
messages = [
{
"role": "system",
"content": system_content
},
{
"role": "user",
"content": user_input
}
]
return messages
if __name__ == '__main__':
sse_url = 'http://0.0.0.0:5000/localhost/chat'
msg_path = "test.txt"
message = get_prompt_msg(msg_path)
req_body = {
"model_name": "model_name",
"messages": message,
"max_new_tokens": 4096,
"temperature": 0.2,
"stream": True
}
stream_chat(sse_url, data=req_body)可能出现的问题
跑起来之后报错:Cannot use FlashAttention-2 backend because the flash_attn package is not found. Please install it for better performance.
安装:flash attention:https://github.com/Dao-AILab/flash-attention
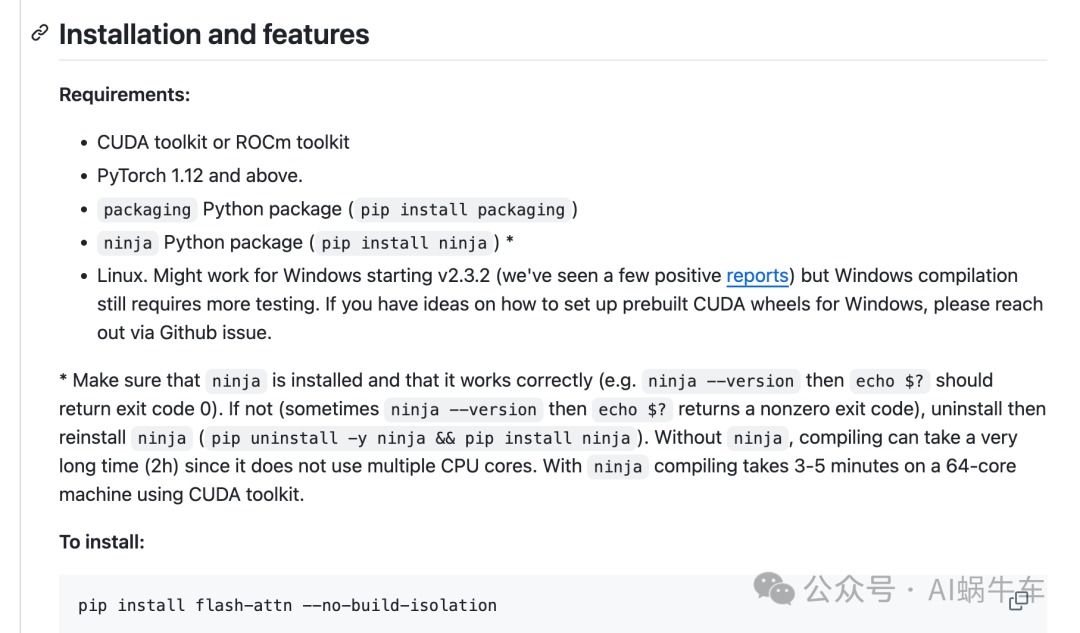
跑出来依然报错:Cannot use FlashAttention backend for Volta and Turing GPUs. (but FlashAttention v1.0.9 supports Turing GPU.
查了一下vllm的issue:[Feature]: Cannot use FlashAttention backend for Volta and Turing GPUs. (but FlashAttention v1.0.9 supports Turing GPU.)
https://github.com/vllm-project/vllm/issues/4246
是不兼容的问题, v2还没有支持部分显卡使用,可以换成能用的显卡,或者应用FlashAttention v1.0.9。
之后解决 运行可能出现:ValueError: Bfloat16 is only supported on GPUs with compute capability of at least 8.0. Your Tesla V100 GPU has compute capability 7.0. You can use float16 instead by explicitly setting thedtype flag in CLI, for example: --dtype=half
因为有的显卡不支持 dtype=bfloat16,这里只能退而求其次换成float16,在某些模型上可能会有些差异。
以上的问题都是在我24年初学习使用vllm初学阶段产生的问题,可能目前已经 被解决,或者依然存在,理性看待~
推荐阅读:
公众号:AI蜗牛车
保持谦逊、保持自律、保持进步

发送【蜗牛】获取一份《手把手AI项目》(AI蜗牛车著)
发送【1222】获取一份不错的leetcode刷题笔记
发送【AI四大名著】获取四本经典AI电子书

















 4843
4843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









