







说在前面
- Dify版本:1.0.1(官网在线版本)
- LLM API:阿里QWEN
- go代码预处理:这里,使用链接里这行的函数
配置API Key
- 这里使用的是阿里云百炼,创建账号也是会送一些Token使用量,在控制台右上角选择API-KEY新建即可
- 没有使用DeepSeek是因为现在好像还没有embedding模型
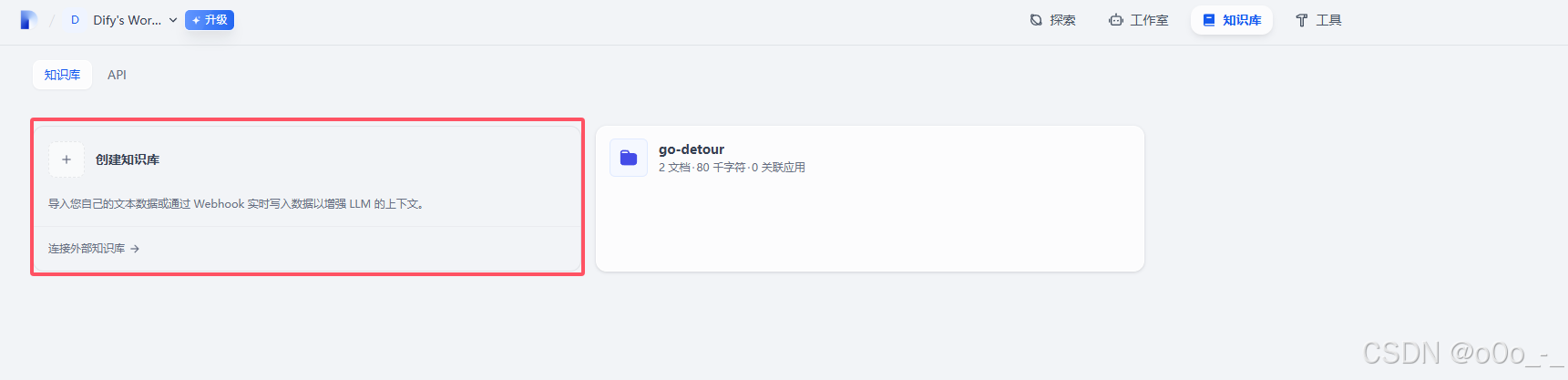
创建知识库
- 创建还是比较简单的,在知识库页签选择创建
- 选择文件上传
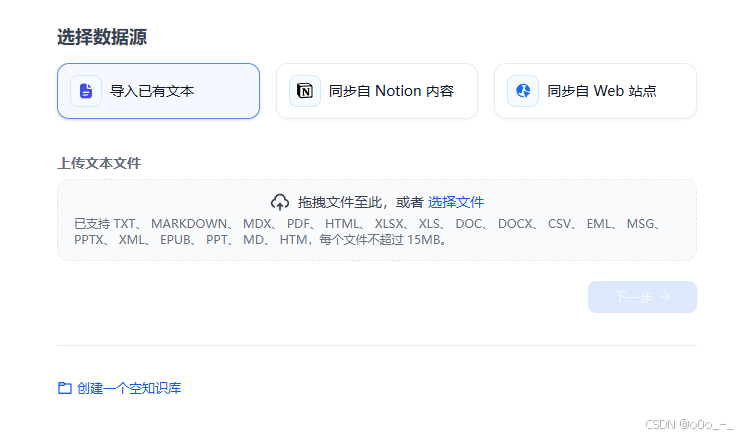
不过看起来并不支持各种代码文件 - 我这里选择的是预处理过的go代码文件,文件格式如下
使用####DtTestMerge(path []detour.DtPolyRef, npath, maxPath int, visited []detour.DtPolyRef, nvisited int) int { return dtMergeCorridorStartShortcut(path, npath, maxPath, visited, nvisited) } ###dtcrowd/DtTestMerge####分割父文本,###分割子文本 - 导入文件后选择分段设置,这里使用的是父子分段
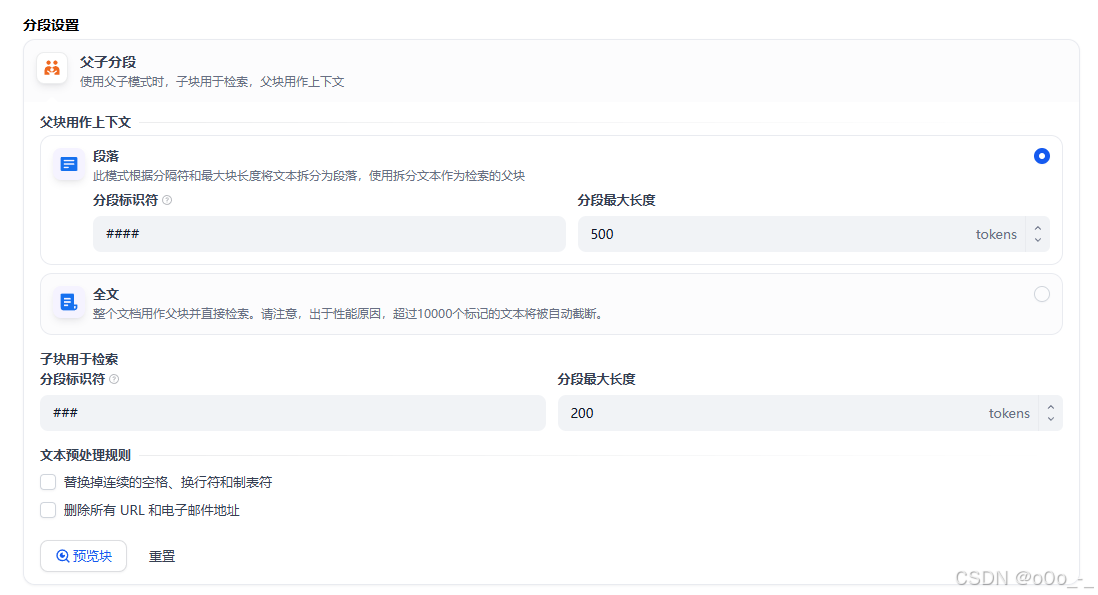
父块是实际要使用的文本内容,子块用于检索查询。
正常来讲,这样设置后的结果是这样的,以下为父块:
以下为子块:DtTestMerge(path []detour.DtPolyRef, npath, maxPath int, visited []detour.DtPolyRef, nvisited int) int { return dtMergeCorridorStartShortcut(path, npath, maxPath, visited, nvisited) }
但是它的分段标识符似乎没有生效,在切割的时候还是用的默认的dtcrowd/DtTestMerge\n\n以及\n。 - 选择embedding模型,随便选一个
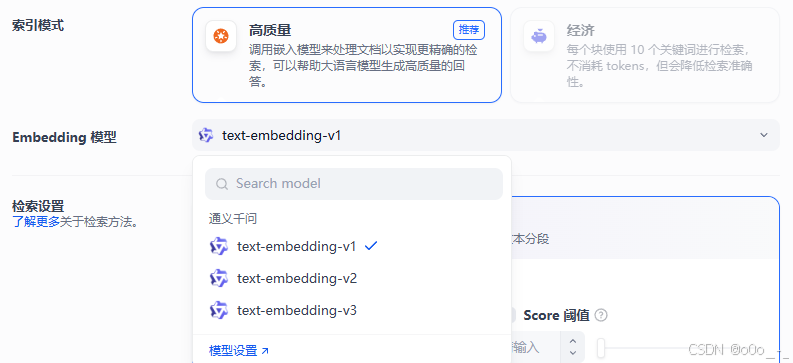
- 点击保存后等待状态变为可用
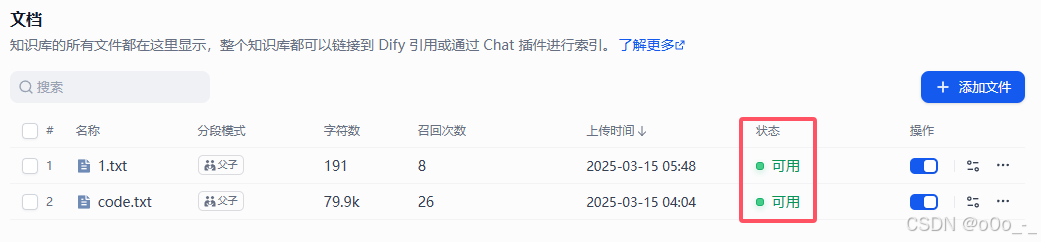
- 在阿里后台可以看到调用次数,测试的时候文件不要太多

创建代码理解工作流
-
在
工作室页签选择创建空白应用
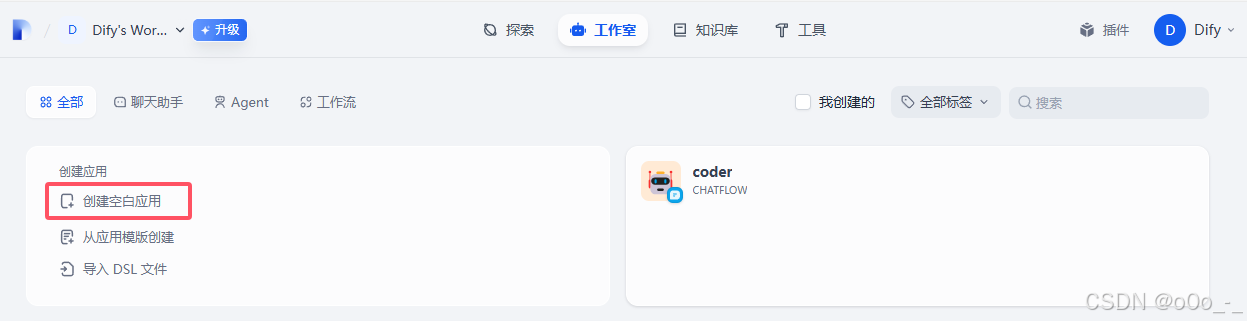
-
选择
工作流,起个响亮的名字
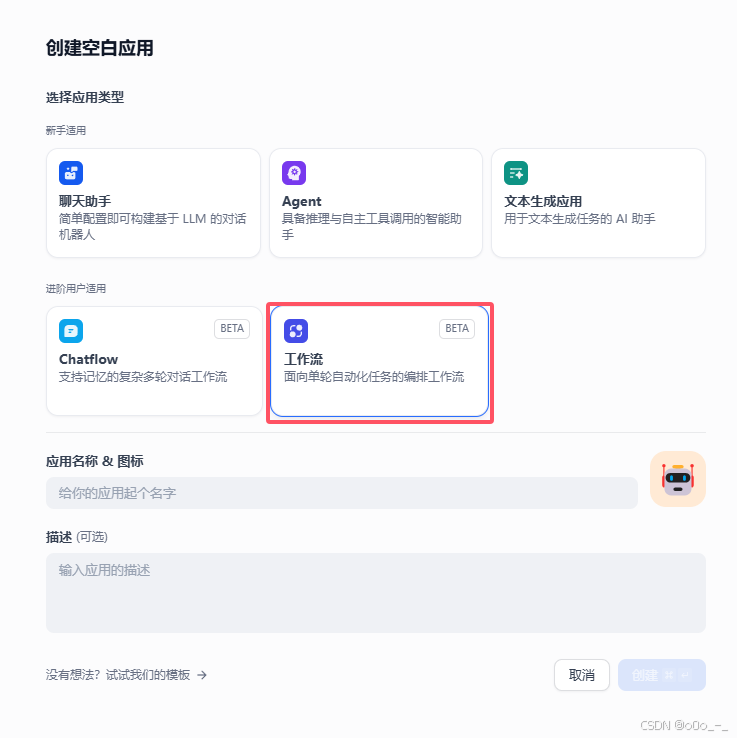
-
ok,一个空荡荡的
工作流就出现了
-
点击开始的
+号,选择问题分类器
-
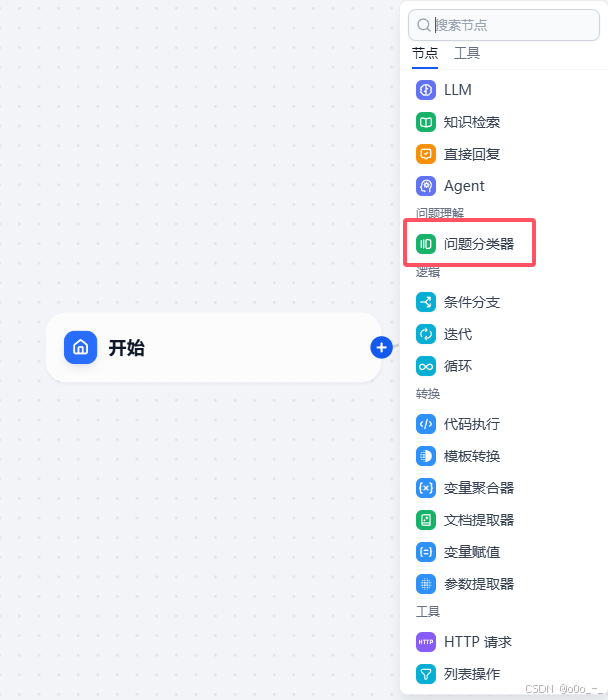
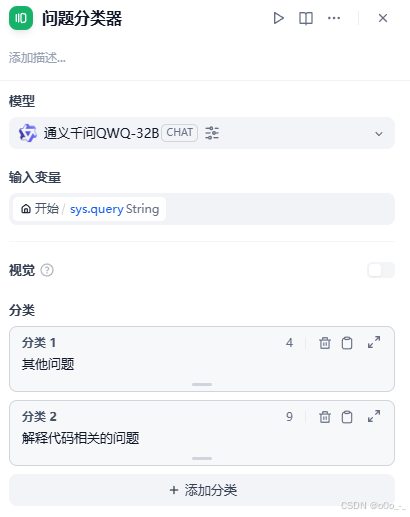
在右侧窗口填入对应参数,模型选择我们配置好的QWEN;输入变量
sys.query代表的是用户对话输入的文本;分类1我们填入其他问题,分类2填入解释代码相关的问题。如果对某些参数不理解,可以点击右上方的书本按钮(三个点左侧按钮)查看相应的教程
-
然后点击其他问题对应的
+号,添加一个直接回复
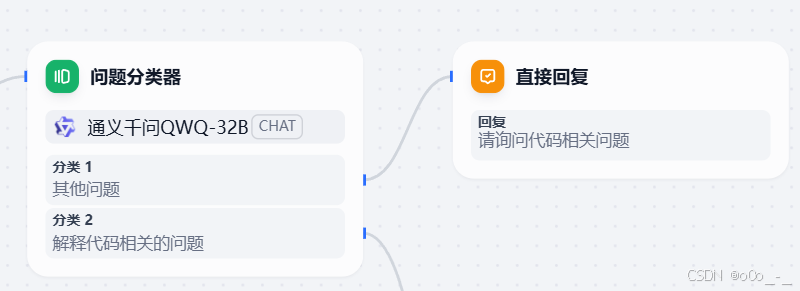
里面可以填入我们写死的回复
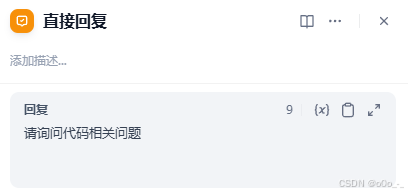
-
然后点击右上角的会话变量图标(如下),我们先添加一个会话变量,就叫
code_rag
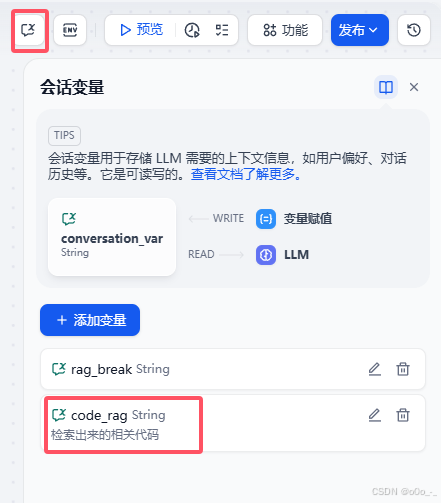
-
点击分类2的
+号,添加一个变量赋值节点
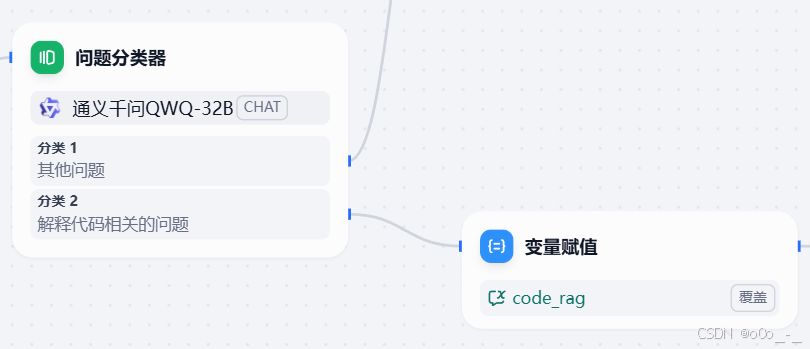
我们将sys.query变量的值赋给我们刚刚新建的会话变量code_rag
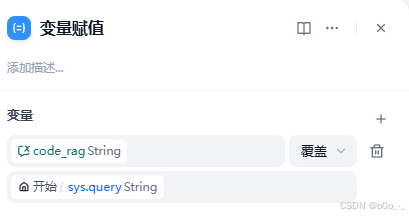
-
添加一个
知识检索节点
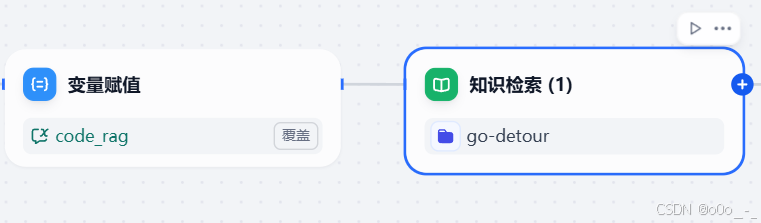
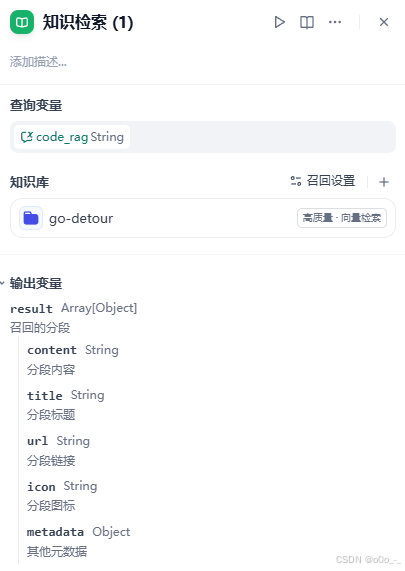
它的输入是我们要查询的文本,它会通过相似度匹配算法从我们创建的知识库中索引对应的文本;查询变量选择code_rag,由于刚刚我们把用户输入赋给了code_rag,所以这一步的作用实际上就是根据用户输入的文本查询对应的代码。
-
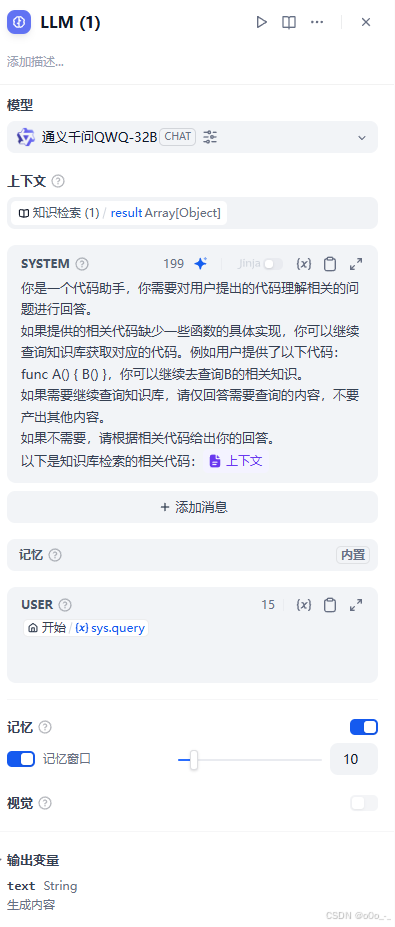
然后添加一个LLM节点,将我们查询的代码让大模型帮我们去理解

这个节点相对复杂,首先是模型,我们还是选择QWEN;上下文就是我们刚刚知识检索的结果,这个数据要发给模型。SYSTEM是系统提示词,这里需要耗点脑子想下怎么写。
-
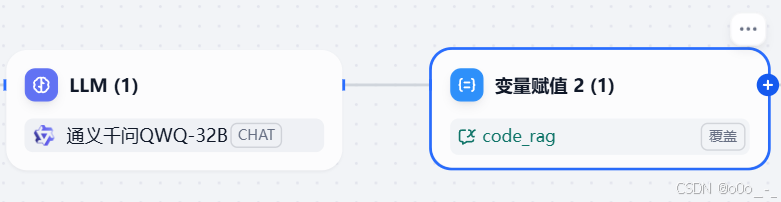
再添加一个变量赋值节点,将LLM的输出结果赋给
code_rag
-
添加一个问题分类器,根据
code_rag的内容让模型决定需不需要再次查询知识库
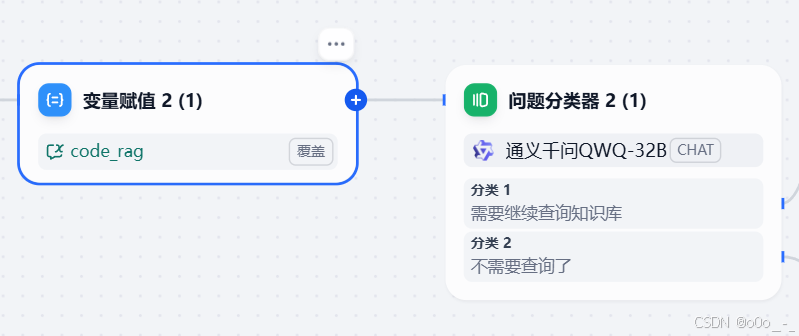
-
如果需要继续查询,那我们再添加个查询流程;如果不需要,那我们直接返回模型的输出

试试效果
- 点击预览
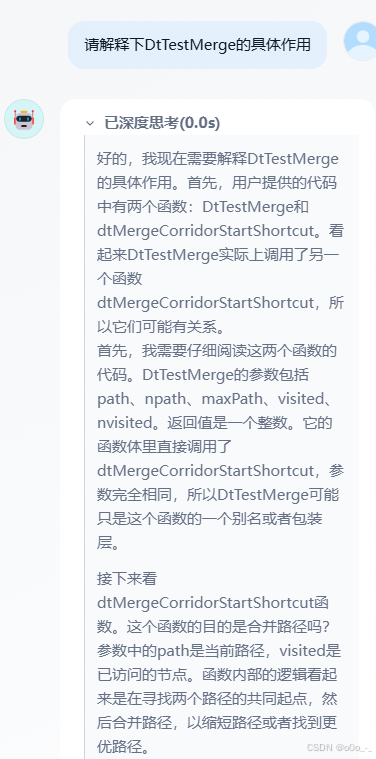
- 输入问题,
DtTestMerge的作用是什么?DtTestMerge(path []detour.DtPolyRef, npath, maxPath int, visited []detour.DtPolyRef, nvisited int) int { return dtMergeCorridorStartShortcut(path, npath, maxPath, visited, nvisited) }DtTestMerge是我手动加的一个测试函数,里面直接调用另一个函数,看看会不会去查询另一个函数的实现
其他
- 在查询知识库的时候额外用了一个
code_rag的变量,这是因为之前考虑查询知识库→LLM这个流程是可以循环的 Dify用起来似乎还行?主要是拖拖拽拽就可以了,挺方便的,而且做出来的东西直接可以给别人用,不用再找个前端

















 2836
2836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









