









说在前面
- 主板:未知x99
- cpu:E5 2666v3
- 显卡:Mi 50 32G
- 系统:ubuntu 22.04
准备工作
- 挂载磁盘(可选)
由于我的系统装在U盘上,访问文件系统会比较慢,这里挂载一下其他磁盘,使用lsblk查看当前可用磁盘
在lele@lele-X99M-Gaming:/mnt/e$ lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS sda 8:0 0 465.8G 0 disk ├─sda1 8:1 0 233G 0 part ├─sda2 8:2 0 1K 0 part └─sda5 8:5 0 232.8G 0 part sdb 8:16 0 238.5G 0 disk ├─sdb1 8:17 0 499M 0 part ├─sdb2 8:18 0 99M 0 part ├─sdb3 8:19 0 16M 0 part ├─sdb4 8:20 0 99.4G 0 part └─sdb5 8:21 0 138.5G 0 part sdc 8:32 0 119.2G 0 disk ├─sdc1 8:33 0 976M 0 part /boot ├─sdc2 8:34 0 1K 0 part ├─sdc3 8:35 0 19.1G 0 part /home ├─sdc4 8:36 0 84G 0 part / └─sdc5 8:37 0 15.3G 0 part [SWAP] nvme0n1 259:0 0 119.2G 0 disk ├─nvme0n1p1 259:1 0 300M 0 part /boot/efi ├─nvme0n1p2 259:2 0 16M 0 part └─nvme0n1p3 259:3 0 118.9G 0 part/mnt目录下创建文件夹,将对应磁盘挂载上去,例如将nvme0n1p3挂载到/mnt/e上cd /mnt sudo mkdir e sudo mount /dev/nvme0n1p3 e/ - 准备Qwen3模型
到国内魔塔社区下载即可
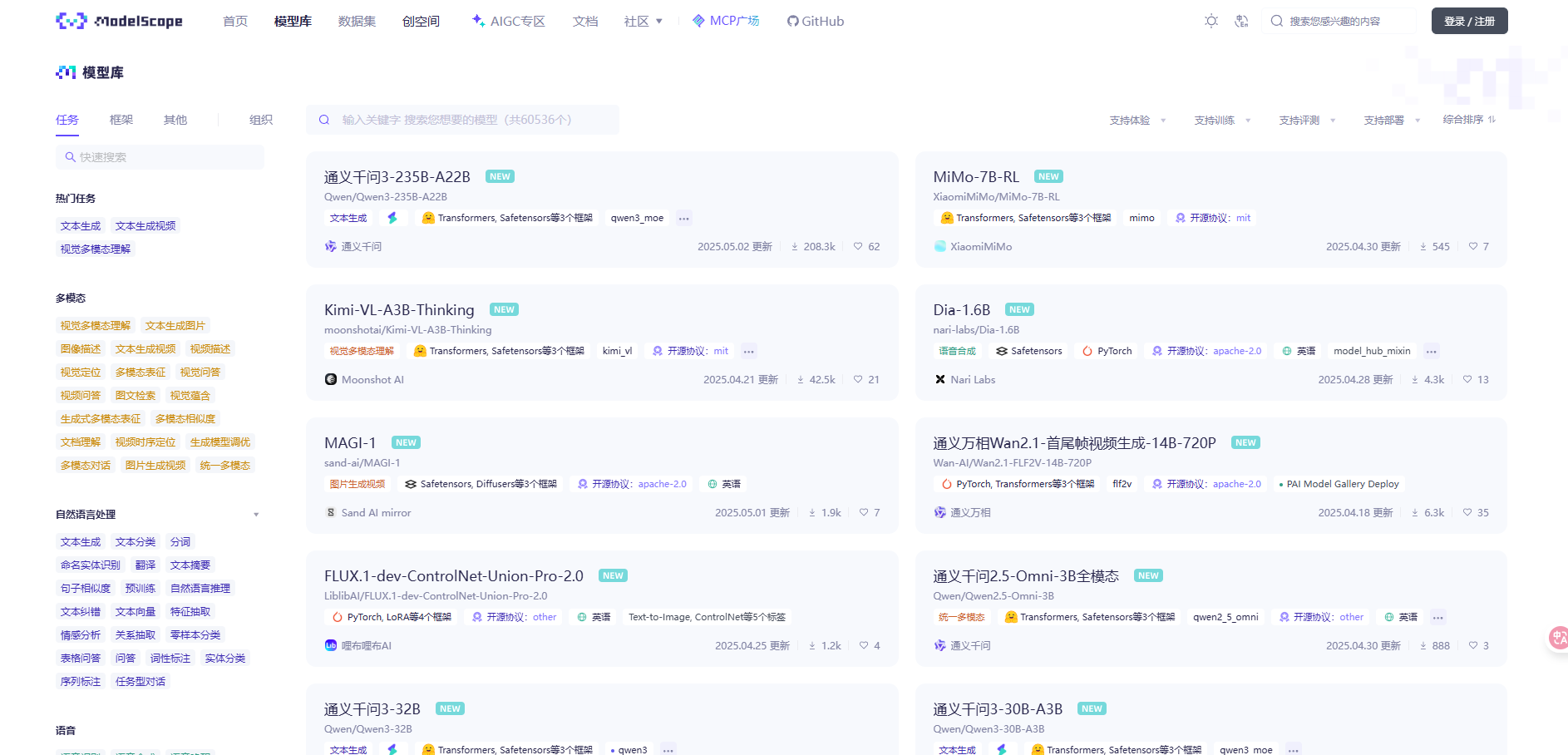
这里选择Unsloth的32B Q6量化模型
编译llama.cpp
- 安装必要依赖
sudo apt install build-essential sudo apt install cmake git libcurl4-openssl-dev libstdc++-12-dev - 下载源代码
官网
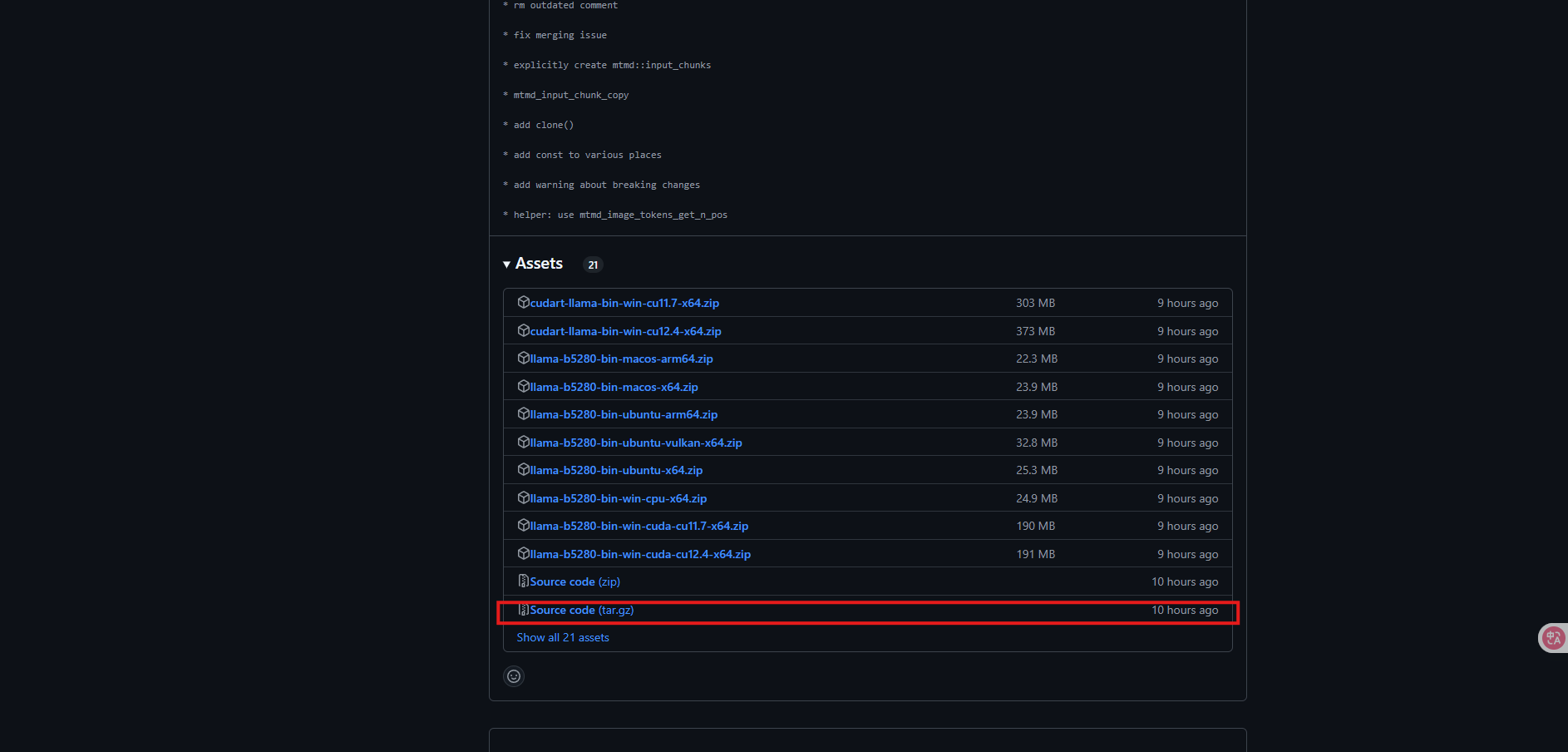
在release界面选择最新版本的源码 - 解压
tar -xvf llama.cpp-master.tar.gz cd llama.cpp-master - 使用
cmake
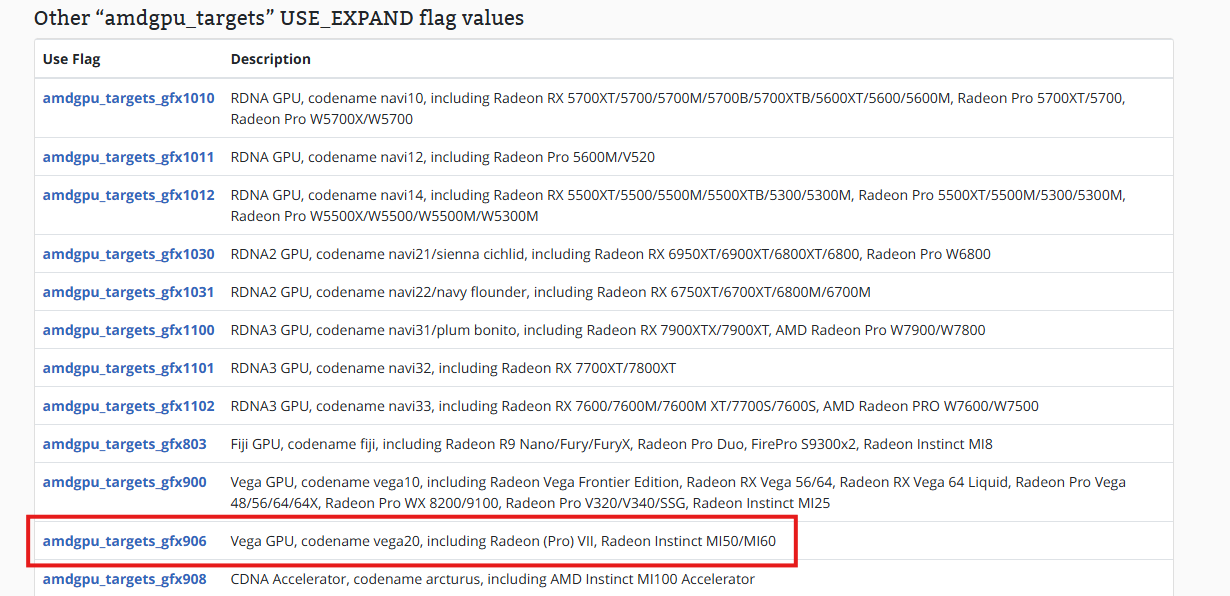
官网的编译实例使用的是gfx1030,我们到这个网站看mi50对应的是什么HIPCXX="$(hipconfig -l)/clang" HIP_PATH="$(hipconfig -R)" \ cmake -S . -B build -DGGML_HIP=ON -DAMDGPU_TARGETS=gfx906 -DCMAKE_BUILD_TYPE=Release
cmake成功之后直接编译即可cmake --build build --config Release -- -j 16
运行Qwen3系列
4B Q4
- 目录结构如下
lele@lele-X99M-Gaming:~$ tree -L 1 . ├── amdgpu-install_6.0.60001-1_all.deb ├── llama.cpp-master └── Qwen3-4B-UD-Q4_K_XL.gguf - 执行命令
./llama.cpp-master/build/bin/llama-cli -m Qwen3-4B-UD-Q4_K_XL.gguf -ngl 99 - 测试
> 你好 <think> 嗯,用户发来了一条简单的“你好”,看起来是打招呼。我需要先回应一下,保持友好和亲切。用户可能只是想测试一下我的反应,或者真的需要帮助。我应该先确认他们是否需要帮助,或者只是闲聊。 接下来,我需要考虑用户可能的意图。他们可能是在开始一段对话,或者有具体的问题需要解决。比如,他们可能想询问某个问题,或者只是想聊天。作为AI助手,我应该保持开放和欢迎的态度,同时准备好提供帮助。 然后,我需要确保我的回应既友好又专业。避免使用过于机械的语言,而是用自然的口语化中文。比如,用“您好!”来回应,然后询问他们需要什么帮助,这样既礼貌又主动。 另外,用户可能没有明确说明他们的需求,所以需要进一步引导他们说出具体的问题。比如,可以提到我可以帮助解答问题、提供信息,或者进行闲聊。这样用户可以选择他们需要的类型。 还要注意用户的潜在需求。可能他们遇到了某个问题,或者想分享一些信息。我需要保持耐心,鼓励他们详细说明,以便提供更有针对性的帮助。 最后,确保回应简洁明了,不带任何不必要的复杂性。让用户觉得轻松,愿意继续对话。 </think> 您好!我是您的AI助手,随时为您解答问题、提供帮助或进行闲聊。您有什么需要我协助的吗? 😊
32B Q6
-
执行命令
./llama.cpp-master/build/bin/llama-cli -m Qwen3-32B-UD-Q6_K_XL.gguf -ngl 99 -
测试
mi50 32G Qwen3
B站
温度
- 实际使用的时候,4B的温度其实不高,32B Q6的温度有80多度(室温较低,夏天用的那种大风扇对着吹的情况下),所以散热一定要做好
rocm-smi ======================================== ROCm System Management Interface ======================================== ================================================== Concise Info ================================================== Device [Model : Revision] Temp Power Partitions SCLK MCLK Fan Perf PwrCap VRAM% GPU% Name (20 chars) (Edge) (Socket) (Mem, Compute) ================================================================================================================== 0 [0x0834 : 0x01] 90.0°C 87.0W N/A, N/A 930Mhz 800Mhz 30.2% auto 225.0W 63% 100% Radeon Instinct MI50 ================================================================================================================== ============================================== End of ROCm SMI Log ===============================================

















 580
580

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









