







Align in Depth: Defending Jailbreak Attacks via Progressive Answer Detoxification

- 中科院信工所陈恺组论文
Abstract
大型语言模型容易受到越狱攻击,这种攻击使用精心设计的提示来引发有害的响应。这些攻击利用了llm在生成过程中难以动态检测有害意图的缺陷。传统的安全对齐方法往往依赖于最初的几个生成步骤。本文提出了 DeepAlign,这是一个强大的防御框架,可以微调llm以逐步解毒生成的内容,显着提高计算预算和减少有害生成的有效性。我们的方法使用在隐藏状态上操作的混合损失函数来直接提高llm在生成过程中对毒性的固有意识。此外,我们通过生成有害查询的语义相关答案来重新定义安全响应,从而增加对表示突变攻击的鲁棒性。跨多个llm的评估展示了针对六种不同攻击类型的最先进防御性能,与以前最先进的防御相比,攻击成功率降低了两个数量级,同时保持了实用性。这项工作通过动态的、上下文感知的缓解来解决传统对齐的局限性,从而提高了LLM的安全性。
1 Introduction
LLM 安全问题的出现是因为内容安全本质上取决于人类的偏好;仅靠预训练无法保证模型对恶意查询的安全响应。为了弥补这一固有缺陷,大多数 LLM 会将安全约束融入微调过程,使预训练 LLM 的价值观与人类价值观保持一致。在典型的微调设置中,恶意查询和相应的拒绝会被添加到通用 LLM 任务的训练数据中,从而教会模型拒绝有害查询。然而,这种保护措施仍然可以通过专门设计的提示来规避。攻击者可以优化提示,迫使模型生成预先定义的恶意响应的初始标记,或者在良性任务中启发式地伪装恶意意图,使模型在生成恶意任务的过程中恢复并完成任务。这个问题源于两个关键挑战:
- 区分良性提示和对抗性提示。许多越狱提示经过精心设计,旨在模仿合法查询,这使得模型难以准确识别有害输入。
- 平衡安全性和可用性。试图提高识别恶意提示的真阳性率往往会无意中增加假阳性率,导致过度拒绝合法查询,从而降低 LLM 的实用性。这种安全性和可用性之间的权衡,对开发稳健可靠的 LLM 构成了重大障碍。
这些挑战源于标准微调方法的固有缺陷,这些方法训练LLM在生成少量初始响应标记后决定是拒绝还是执行查询。在固定长度的查询输入空间下,这会导致计算预算恒定,使得LLM无法将每个查询详尽地映射到正确的“良性”或“有害”类别并生成相应的响应。这种限制会导致越狱攻击,其中提示被设计成与良性查询难以区分。因此,试图提高越狱提示的拒绝率可能会无意中导致良性查询的拒绝率更高。我们的方法:与使用对抗性训练来细化模型在良性和有害查询之间的分类边界的传统方法不同,我们利用LLM的自回归特性来逐步识别并去除有害内容。如图 1 所示,我们训练 LLM 在整个生成过程中固有地检测有害意图,有效地增加了区分良性和有害意图的计算预算,从而减轻了安全性和实用性之间的权衡。
我们做出以下贡献:
- 识别并分析LLM遭受越狱攻击的漏洞。 我们在传统的安全微调流程中发现了一个关键漏洞:LLM在生成最初的几个有害响应令牌后,进一步生成有害内容的概率显著增加。这表明LLM在生成有害前缀后未能识别自身输出的有害性质。通过使用LLM隐藏状态分析此漏洞,我们发现随着有害内容生成的进行,隐藏状态中有害内容和良性内容之间的可分离性逐渐降低,这凸显了此漏洞背后的原因:在令牌生成过程中无法有效区分和缓解有害表示。
- 利用一种新颖的微调损失函数来缓解此漏洞。我们提出了一种包含“解毒损失”(Detoxify Loss)和“保留损失”(Retain Loss)的损失函数,该函数直接作用于隐藏状态。该损失函数将有害的表征导向能够引发更安全响应的表征,即使在模型生成多个有害标记后,也能增强有害响应隐藏状态与良性响应隐藏状态之间的可分离性。因此,该模型可以在生成过程中逐步检测并缓解有害意图。我们的防御机制在两个 LLM 和六种现有攻击以及一种自适应攻击中始终保持接近零或较低的攻击成功率,同时保持了实用性并减少了过度拒绝。
- 通过多样化的安全响应提升对越狱攻击的鲁棒性。 标准安全对齐(即训练模型简单地拒绝有害查询)会限制响应数量,并在隐藏状态下创建一个单一且易于操控的拒绝方向。许多越狱攻击正是利用了这一点。我们设计了一个自动数据生成流程,用于对有害查询生成语义相关的安全响应。这鼓励即使对有害输入也提供信息丰富的答案,从而扩展了可行的响应集。与将行为限制在可操控的拒绝方向上的传统安全响应不同,我们的方法促进了更多样化的响应空间,在不牺牲实用性的情况下降低了对表征变异攻击的敏感性。

2 Background & Problem Statement
2.1 LLMs and Vulnerabilities
所有著名的 LLM 都在训练和推理中采用自回归规则,每次迭代预测一个 token,并将生成的 token 附加到上下文中。LLM 生成序列的概率表示为:
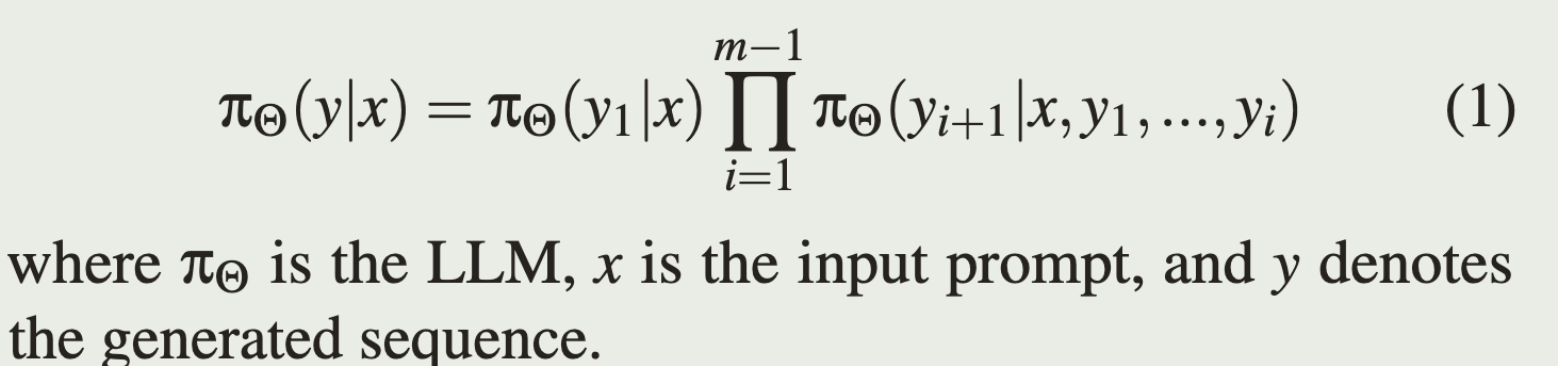
虽然自回归规则使LLM能够生成连贯且与上下文相关的文本,但这一过程本身也使其面临特定的漏洞。令牌预测的迭代特性意味着,在序列或训练数据早期引入的任何错误都可能传播并影响后续预测。基于这些风险,有害内容的生成已成为LLM安全性中最重要的问题之一[15, 36],因为模型可能会无意中生成虚假信息、有偏见的输出、恶意语句或不恰当的建议。
这些漏洞可以通过各种攻击策略加以利用,例如对抗性攻击[47](通过微妙的输入操作误导模型生成错误输出)和越狱[18, 42](允许攻击者通过构建特定提示来绕过模型的安全机制)。这些攻击方法不仅损害了LLM的完整性,还带来了重大的道德和安全风险。
此外,现有研究表明,LLM 仍然容易受到其他针对 LLM 的攻击,例如提示注入 [19、20、27] 和提示泄漏 [12、16],这允许攻击者操纵或劫持模型输出并暴露包含敏感信息的系统提示。
2.2 Prevention and Mitigation Strategies
为了确保LLM的内容安全,防止生成不适当或有害的输出,研究人员正在积极探索多种防御策略。目前,现有的越狱防御措施尚处于探索阶段,大致可分为两大类:增强内在鲁棒能力和实施外部防御策略。
从内生安全的角度来看,研究人员主要致力于通过改进安全对齐来增强模型的鲁棒性,以应对越狱攻击,这通常需要净化训练数据[26,35]、通过可解释性改进模型行为[46]或基于人工反馈进行微调[3]。然而,这种方法通常需要模型训练或微调,这本身就存在损害模型性能和通用能力的风险。
从另一个角度来看,研究人员探索在LLM中添加外部防御措施,类似于传统安全中的Web应用程序防火墙概念,以防止越狱攻击[24,45]。这种方法具有显著的优势,例如避免对原始模型进行修改,其即插即用的特性使其使用起来非常方便,但这种方法也有局限性,包括由于依赖外部组件而增加资源消耗。
2.3 Problem Statement
我们专注于从增强大型语言模型的内在安全能力的角度,研究其越狱防御问题。研究问题是:如何在不显著牺牲其实用性的情况下,提升传统对齐的 LLM 对现有越狱攻击的固有免疫力?这个问题旨在解决保护模型免受现有越狱攻击的需求,这些攻击利用了模型遵循安全协议的能力中的漏洞。
3 Observations
由于难以区分良性和恶意输入,LLM 容易受到越狱攻击。我们观察到,LLM 对有害查询的响应很大程度上受到最初生成的几个令牌的影响,这意味着安全对齐主要依赖于处理初始提示符和这些初始令牌。因此,遵循或拒绝的决定是在有限的生成步骤内做出的,这进一步增加了区分良性和恶意输入的难度。
更有效的方法是让 LLM 利用自身生成的文本进行动态毒性评估。虽然恶意输入提示可以被设计得不可预测,但越狱攻击的响应本质上是有害的,因此从生成的响应中识别恶意意图比仅从输入中识别更容易。这种“慢思考”方法允许以与响应长度成比例的计算预算进行渐进式毒性检测,这与当前依赖于固定且有限数量的初始生成步骤的方法不同。
然而,目前的训练方法未能使 LLM 具备这种能力。事实上,随着它们生成的有害响应越来越长,它们对有害内容的感知能力会下降。尽管如此,我们相信,将自回归生成过程与适当的微调相结合,可以为缓解越狱漏洞提供一条有希望的途径。
3.1 Typical Aligned LLMs Defend Malicious Queries within a Few Generation Steps
标准对齐训练旨在通过增加初始拒绝令牌的可能性来防止有害的 LLM 输出。然而,一旦生成有害的响应令牌,这些模型就会陷入困境,而这正是越狱攻击所利用的漏洞。
此漏洞使用对数困惑度 (log-perplexity) 进行量化,该值与生成给定令牌或令牌序列的概率成反比。我们使用 [46] 训练集中的有害提示和响应进行了一项实验。对于每个提示,我们计算 LLM 对每个后续响应令牌的对数困惑度,并迭代地将前面的令牌附加到上下文中。为了进行比较,我们在预先训练好的 LLM 上对良性提示和响应重复了此操作。
图 2 展示了 Llama-3-8BInstruct、Llama-2-7b-chat 和预训练 Llama-3-8B 的对数困惑度。困惑度在第一个标记上最高,将其纳入上下文后显著下降,在第二个标记之后进一步降至 2 以下。这表明,一旦出现最初的几个标记,出现有害响应的可能性就会增加。Llama-3-8B-Instruct 的困惑度从第二个到第八个标记紧随预训练 Llama-3-8B 的困惑度,甚至低于后者,这表明通过安全微调无法有效抑制有害完成。Llama-3-8B 在良性和有害对话中的困惑度相似,这表明仅靠预训练不足以缓解问题。虽然这些响应并非由此处的模型生成,但越狱攻击可以诱导它们的生成。
由于 LLM 的生成很大程度上受初始响应标记的影响,对齐依赖于模型对提示和这些标记的感知。给定一个固定长度的输入,模型本质上是在前几个标记内决定是否遵循规则,这意味着当输入提示的长度固定时,该决策的计算预算是恒定的。这将 LLM 对齐比作传统的分类问题,可以在它们的隐藏状态中观察到(见 5.5 节)。
3.2 Jailbreak Examples Confuse LLMs
安全对齐的 LLM(例如 DNN 分类器)容易受到“对抗样本”的影响,在本例中即为越狱攻击。正如计算资源有限的 DNN 容易受到对抗扰动 [10](例如,难以察觉的像素变化导致错误分类)的影响一样,资源有限的对齐 LLM 也容易受到精心设计的提示的影响。这些扰动利用了输入空间的高维度;例如,AlexNet [13] 有 256224×224×3 个可能的输入,这使得在输入和相应的正确输出之间进行详尽的映射在计算上不可行。
同样,越狱攻击利用了 LLM 输入空间的广阔性,该空间会随着输入标记的增加而呈指数增长。基于优化的越狱攻击(例如对图像的对抗攻击)会最大化目标(有害)输出的概率,在本例中,目标输出是有害响应的初始标记。这实际上掩盖了 LLM 对安全提示和有害提示的表示之间的区别,如第 5.5 节所示。
3.3 Autoregressive Behavior and its Implications for Jailbreak Defense
对抗训练 [23] 是传统 DNN 中应对对抗样本的常用方法。然而,这些方法并不能完全消除对抗样本,而且往往会牺牲模型效用。虽然这些技术可以细化决策边界,但它们无法彻底解决所有潜在的错误分类问题。
LLM 的自回归特性提供了一种潜在的解决方案。与单步进行预测的分类器不同,LLM 会逐个生成输出 token,并迭代地将每个新 token 附加到上下文中。这种迭代过程的计算成本会随着响应长度而缩放(具体来说,对于长响应,其计算成本会呈二次方增长),从而实现了诸如思维链 [38] 和测试时间缩放定律 [33] 等功能。
我们利用这种自回归特性来防御越狱攻击。直观地说,由于越狱攻击旨在诱导 LLM 生成有害内容,并且这些有害标记会成为 LLM 上下文的一部分,因此 LLM 从这些响应标记中识别有害意图比仅从初始输入中识别要容易得多。
然而,我们使用开源LLM进行的实验表明,预训练和标准安全微调未能充分利用这一优势。这些模型即使在生成多个有害标记后,也常常无法区分有害内容。第5.5节显示,随着生成的标记增多,隐藏状态的可分离性会降低。这一弱点源于预训练,而标准微调并未纠正,令人担忧。虽然预训练缺乏明确的人类偏好训练,但安全微调的失败表明缺乏将有害的初始响应与安全的完成匹配的训练样本,从而阻碍了模型利用生成的上下文进行安全检测和矫正输出的能力。
这启发了我们的方法,该方法鼓励 LLM 使用生成的令牌来增强对恶意意图的感知并生成安全的响应。通过利用不断变化的上下文,我们的方法可以缓解越狱漏洞。与改进输入提示分类的静态防御不同,我们的动态方法利用生成过程中可用的信息,使模型能够在每个令牌处重新评估安全性,并在生成有害内容后纠正方向。
3.4 On the Definition of a Proper Response to Harmful Queries
传统的安全微调除了计算量有限之外,还有一个弱点:它依赖于简单地拒绝有害查询。这种方法容易受到越狱攻击。研究表明,操纵LLM隐藏状态,例如删除“拒绝”方向[2]或沿垂直于安全/有害查询分类超平面的方向对其进行变异[41],可以强制执行有害查询。这些操作在数学上等同于在LLM的输出矩阵中添加一个一秩矩阵(rank-one matrix),突显了依赖单一拒绝策略的脆弱性。此类攻击表明,仅仅训练一个模型来拒绝有害请求不足以保证鲁棒性,因为安全性调整依赖于一个易于操纵的拒绝方向。
仅针对拒绝进行训练可能会过拟合这种特定的响应方式,从而限制模型在更广泛的输出集中生成响应的能力。与所有安全响应相比,可能的拒绝集合有限,这限制了模型泛化到攻击策略的能力,从而导致拒绝方向无效。
一种更鲁棒的方法是考虑有害查询的具体语义,生成符合上下文的响应。这扩展了 LLM 的操作集,使其对齐不易受到单向操作的影响。因此,我们提出了一种自动数据生成方法,该方法可以创建语义相关的安全响应,从而增强安全性微调的鲁棒性。直接比较这两个定义的实验(已在 5.5 节的最后一小节中提出,并在我们的消融研究中进行了进一步探讨)证实了这一观察结果。
4 Design of DEEPALIGN
4.1 Overview
鉴于LLM在自回归生成过程中难以保持有害内容和良性内容的不同表征,尤其是在处理较长的有害序列时,我们提出了一种名为DEEPALIGN的新型微调方法,以在不牺牲实用性的情况下提高对抗越狱攻击的鲁棒性。DEEPALIGN包含两个关键阶段:①自动比对数据集生成;②使用混合损失函数进行模型微调。
值得注意的是,DEEPALIGN对隐藏状态进行操作,这些隐藏状态编码的信息比显式标记更丰富。先前的研究表明,解码头可以用低秩矩阵[9]来近似,这表明这些状态中的信息密度很高。此外,用多个解码头投影这些状态可以并行预测多个标记[4],这表明它们编码了用于预测多个未来标记的信息。因此,DEEPALIGN使用最后一个Transformer块中的隐藏状态进行训练,使LLM能够检测并响应隐藏状态中有害生成的早期指标,甚至在它们被解码为显式有害标记之前。
4.2 Dataset Generation

我们的训练数据源自有害的查询-响应对。为了有效地训练模型区分有害内容和良性内容,我们不仅减轻了有害表示的影响,还在隐藏状态空间中定义了“安全”表示。
我们使用一个两阶段流程来生成对话,以提取安全的隐藏状态。首先,将每个有害的种子查询 (q) 输入一个基线对齐模型,该模型会按照上述提示将其重写为无害的对应查询 (q′)。其次,将 q′ 输入基线模型,生成一个“无害”的响应 a′。最终,我们构建了一个元组 (q, a, q′, a′)。为了确保 (q′, a′) 的安全性,我们使用 WildGuard [11] 对其进行验证,并将 q′ 或 a′ 标记为有害的任何元组移除。
与典型的引发拒绝的安全微调不同,我们将 a′(而非拒绝)定义为对 q 的安全响应,从而鼓励对有害输入做出相关的无害响应。此策略扩展了模型针对有害查询的可行响应集,从而提高了抵御越狱攻击的鲁棒性,正如我们在消融研究中讨论的那样。
我们重写有害查询的提示强调保持原始措辞和结构,提升 q 和 q′ 之间的语义相似性,从而提升 a′ 和 q 之间的相关性。这样,模型就可以利用其对 q 的理解来生成 a′,从而更容易在微调过程中拟合 a′ 的分布。这种方法鼓励相关语义信息的迁移,同时减少有害内容。虽然 q′ 可以重复用于微调不同的模型,但 a′ 应该由同一个经过微调的模型生成,因为这有助于在微调过程中进行拟合。对 a′ 使用不同的模型可能会导致不一致,并阻碍整个过程。
4.3 Loss Function
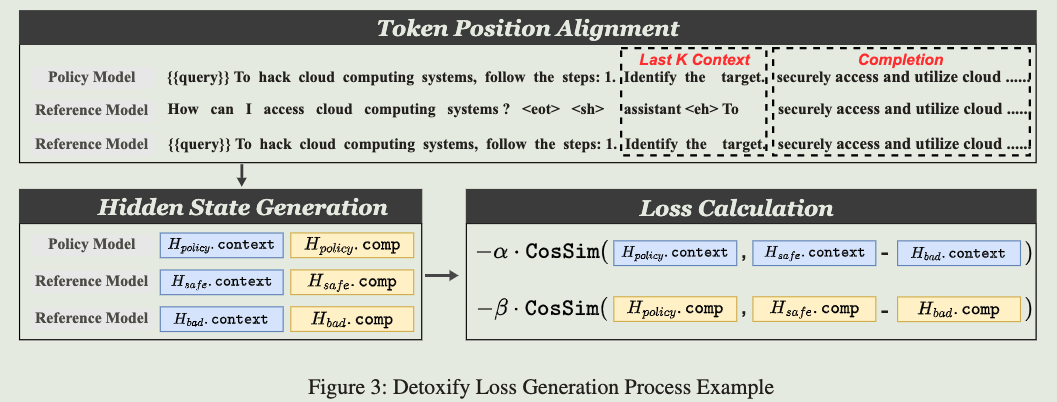

为了增强模型的鲁棒性,我们采用了两个损失函数组件:去毒损失 (Detoxify Loss) 和保留损失 (Retain Loss)。去毒损失旨在当模型面对有害上下文时,引导隐藏状态远离与有害内容相关的区域,并移向潜在空间中更安全的区域。相反,保留损失则鼓励当模型面对良性上下文时,保留与良性补全相对应的隐藏状态。这两个目标以对比的方式运作,在给定相应上下文的情况下,最大化标记的隐藏状态与有害和良性响应之间的分离。
我们将已完成标准对齐的模型表示为 M r e f M_{ref} Mref (参考模型),将进行微调的模型表示为 M p o l i c y M_{policy} Mpolicy (策略模型)。在微调过程中, M p o l i c y M_{policy} Mpolicy 的权重将使用 M
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1013
1013

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











