









MobileNet v1 学习笔记
原文地址 MobileNets: Efficient Convolutional Neural Networks for Mobile Vision
Applications
摘要
作者提出了一类高效的的模型——MobileNets,可以用于移动和嵌入式端的视觉应用程序。MobileNets基于流线型架构,使用深度可分离卷积来构建轻量级的深度神经网络。引入了两个简单的全局超参数宽度乘数和分辨率乘数,它们可以有效地在实时性和准确性之间进行权衡。这些超参数允许模型构建器根据问题的约束条件为其应用程序选择合适大小的模型。提出了大量的资源和准确性权衡的实验,并显示了与其他流行的ImageNet分类模型相比的强大性能。然后,演示了MobileNets在广泛的应用程序和用例中的有效性,包括目标检测、精细颗粒分类、人脸属性和大规模地理定位。
MobileNet 的结构分析
MobileNet 是基于(depthwise separable convolutions)深度可分离卷积,这是一种卷积的分解形式,它将一个标准卷积分解为(depthwise convolution)深度卷积和( pointwise convolution)点卷积的1×1卷积。深度卷积对每个输入通道应用一个滤波器。点态卷积然后应用一个1×1的卷积来组合输出的深度卷积
1、基本结构分析
(1)标准卷积
-
结构
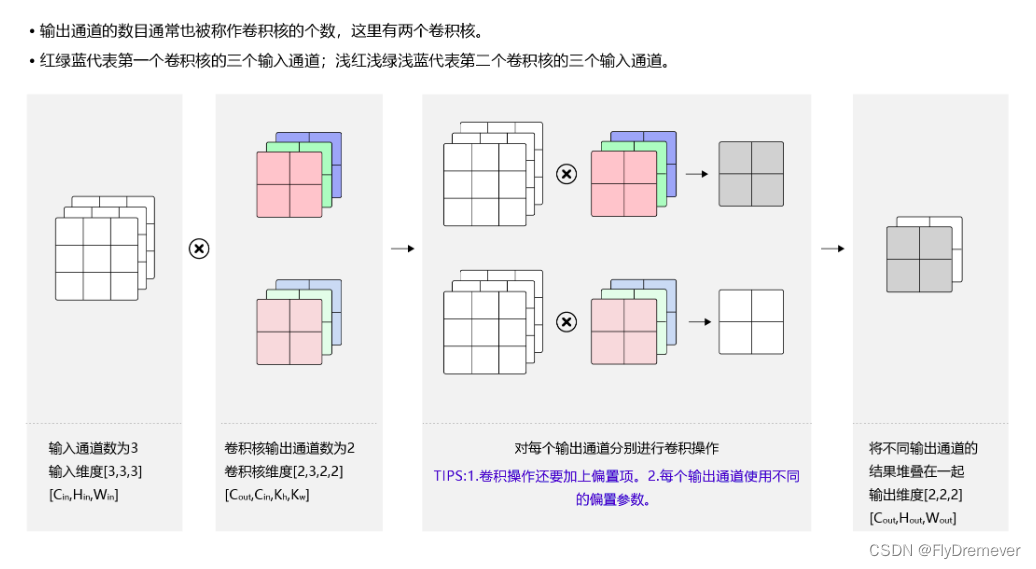
图片来自百度AI教程 -
参数量和计算量
参数量计算: ( C i n ∗ K h ∗ K w ) ∗ C o u t + b i a s , 其中 C o u t = b i a s (C_{in}*K_h*K_w) *C_{out} + bias,其中C_{out} = bias (Cin∗Kh∗Kw)∗Cout+bias,其中Cout=bias
计算量: ( K h ∗ K w ∗ C i n ) ∗ C o u t ∗ H o u t ∗ W o u t (K_h*K_w*C_{in})*C_{out} * H_{out}*W_{out} (Kh∗Kw∗Cin)∗Cout∗Hout∗Wout
论文中给出的公式 D k ∗ D k ∗ M ∗ N ∗ D F ∗ D F D_k*D_k*M*N*D_F*D_F Dk∗Dk∗M∗N∗DF∗DF D k D_k Dk卷积核尺寸, D F D_F DF 输出特征图尺寸, M , N M,N M,N,分别为输入输出通道数
(2)深度可分离卷积
- 结构
深度卷积 (depthwise convolution)
逐通道卷积
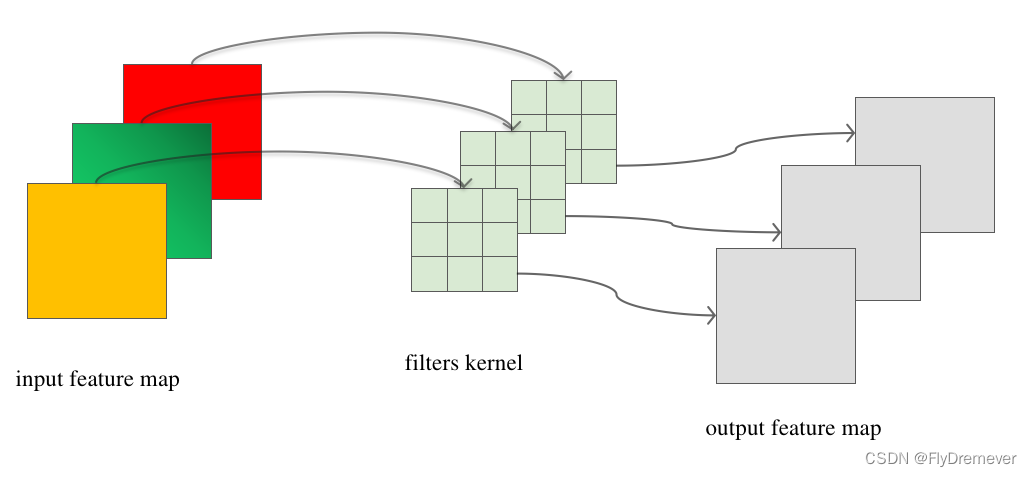
点卷积 (pointwise convolution)
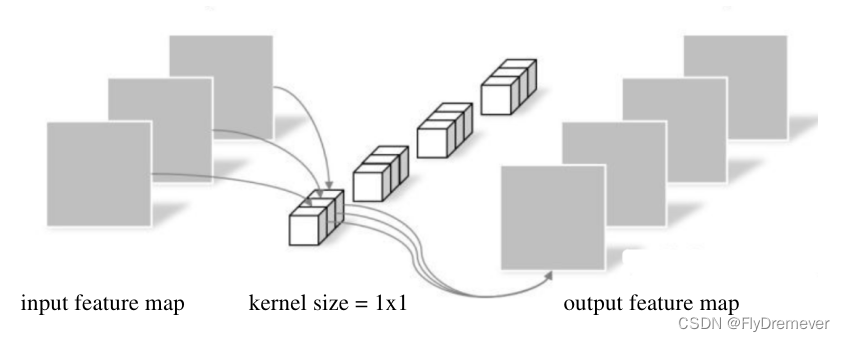
- 参数量和计算量
参数量计算: ( C i n ∗ K h ∗ K w ) + C i n ∗ C o u t ∗ ( 1 ∗ 1 ) (C_{in}*K_h*K_w) +C_{in}*C_{out}*(1*1) (Cin∗Kh∗Kw)+Cin∗Cout∗(1∗1)
计算量: [ ( K h ∗ K w ) ∗ H o u t ∗ W o u t ] ∗ C i n + [ ( 1 ∗ 1 ∗ C i n ) ∗ C o u t ∗ H o u t ∗ W o u t ] [(K_h*K_w) * H_{out}*W_{out}]*C_{in}+[(1*1*C_{in})*C_{out} * H_{out}*W_{out}] [(Kh∗Kw)∗Hout∗Wout]∗Cin+[(1∗1∗Cin)∗Cout∗Hout∗Wout]
论文中给出的公式
D k ∗ D k ∗ M ∗ D F ∗ D F + M ∗ N ∗ D F ∗ D F D_k*D_k*M*D_F*D_F+M*N*D_F*D_F Dk∗Dk∗M∗DF∗DF+M∗N∗DF∗DF D k D_k Dk卷积核尺寸, D F D_F DF 输出特征图尺寸, M , N M,N M,N,分别为输入输出通道数
计算量对比:
D
k
∗
D
k
∗
M
∗
D
F
∗
D
F
+
M
∗
N
∗
D
F
∗
D
F
D
k
∗
D
k
∗
M
∗
N
∗
D
F
∗
D
F
=
1
N
+
1
D
k
2
\frac{D_k*D_k*M*D_F*D_F+M*N*D_F*D_F}{D_k*D_k*M*N*D_F*D_F} = \frac{1}{N}+\frac{1}{D^2_k}
Dk∗Dk∗M∗N∗DF∗DFDk∗Dk∗M∗DF∗DF+M∗N∗DF∗DF=N1+Dk21
参数量对比
假设 不考虑偏置,
K
h
=
K
w
K_h=K_w
Kh=Kw
(
C
i
n
∗
K
h
∗
K
w
)
+
C
i
n
∗
C
o
u
t
∗
(
1
∗
1
)
(
C
i
n
∗
K
h
∗
K
w
)
∗
C
o
u
t
=
1
C
o
u
t
+
1
K
2
\frac{(C_{in}*K_h*K_w) +C_{in}*C_{out}*(1*1)}{(C_{in}*K_h*K_w) *C_{out} } = \frac{1}{C_{out}}+\frac{1}{K^2}
(Cin∗Kh∗Kw)∗Cout(Cin∗Kh∗Kw)+Cin∗Cout∗(1∗1)=Cout1+K21
- 基于pytorch 的深度可分离卷积的实现
在编程实现中,深度可分离卷积基于分组卷积实现
分组卷积详解
class ConvNormActivation(torch.nn.Sequential):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: int = 3,
stride: int = 1,
padding:int = None,
groups: int = 1,
norm_layer: torch.nn.Module = torch.nn.BatchNorm2d,
activation_layer: torch.nn.Module = torch.nn.ReLU,
dilation: int = 1,
inplace: bool = True,
) -> None:
if padding is None:
padding = (kernel_size - 1) // 2 * dilation
layers = [torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding,
dilation=dilation, groups=groups, bias=norm_layer is None)]
if norm_layer is not None:
layers.append(norm_layer(out_channels,momentum=0.9))
if activation_layer is not None:
layers.append(activation_layer(inplace=inplace))
super().__init__(*layers)
self.out_channels = out_channels
class DepthwiseSeparable(nn.Module):
def __init__(self, in_channels, out_channels1, out_channels2, num_groups,
stride, scale):
super(DepthwiseSeparable, self).__init__()
self._depthwise_conv = ConvNormActivation(in_channels,
int(out_channels1 * scale),
kernel_size=3,
stride=stride,
padding=1,
groups=int(num_groups *
scale))
self._pointwise_conv = ConvNormActivation(int(out_channels1 * scale),
int(out_channels2 * scale),
kernel_size=1,
stride=1,
padding=0)
def forward(self, x):
x = self._depthwise_conv(x)
x = self._pointwise_conv(x)
return x
2、模型构成
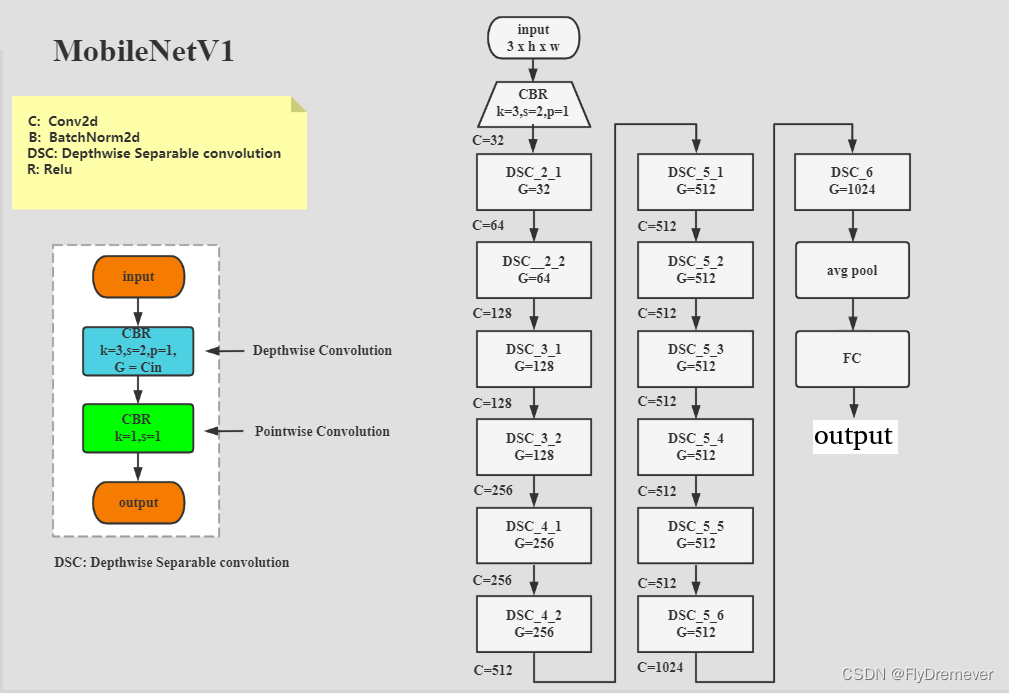
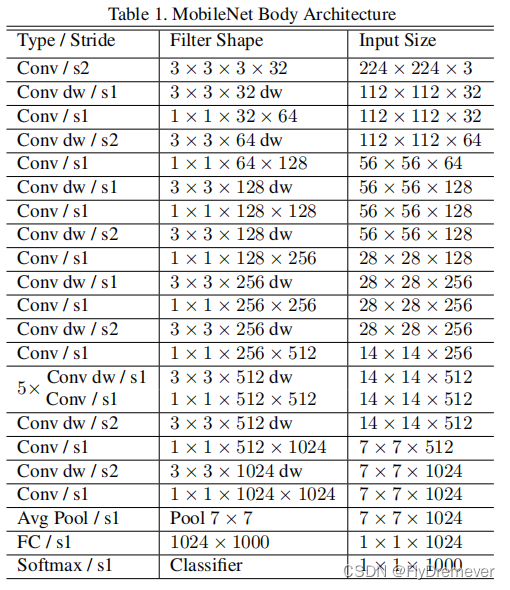
超参数宽度乘数和分辨率乘数
宽度乘数
尽管基本的 MobileNet 架构已经很小且低延迟,但特定用例或应用程序可能需要模型更小、更快。为了构建这些更小且计算成本较低的模型,引入了一个非常简单的参数 α,称为宽度乘数。宽度乘数 α 的作用是在每一层均匀地细化网络。对于给定的层和宽度乘数α,输入通道的数量M变为αM,输出通道的数量N变为αN。具体实现如上述代码中的scale参数,就是起到宽度乘数α的作用。
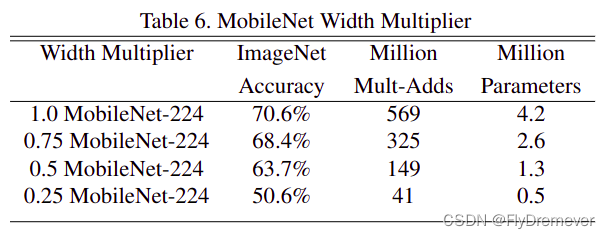
分辨率乘数
降低神经网络计算成本的第二个超参数是分辨率乘数ρ。我们将此应用于输入图像,实际上,通过设置输入分辨率从而隐式地设置ρ。
MobileNet 的优点
- MobilenetV1提出了深度可分离卷积(Depthwise Convolution),它将标准卷积分解成深度卷积以及一个1x1的卷积即逐点卷积,大幅度减少了运算量和参数量
- 模型结构简单,可以用于嵌入式和移动端,在保证实时性的同事精度只有小幅度的下降。
- 模型可扩展,也可以用于多种视觉任务。
参考代码
'''
Descripttion:
version:
Author: tjk
Date: 2022-12-20 17:11:00
LastEditors: Please set LastEditors
LastEditTime: 2023-02-06 15:51:42
'''
import torch
import torch.nn as nn
import torchvision
# from torchvision.ops.misc import ConvNormActivation
class ConvNormActivation(torch.nn.Sequential):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: int = 3,
stride: int = 1,
padding:int = None,
groups: int = 1,
norm_layer: torch.nn.Module = torch.nn.BatchNorm2d,
activation_layer: torch.nn.Module = torch.nn.ReLU,
dilation: int = 1,
inplace: bool = True,
) -> None:
if padding is None:
padding = (kernel_size - 1) // 2 * dilation
layers = [torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding,
dilation=dilation, groups=groups, bias=norm_layer is None)]
if norm_layer is not None:
layers.append(norm_layer(out_channels,momentum=0.9))
if activation_layer is not None:
layers.append(activation_layer(inplace=inplace))
super().__init__(*layers)
self.out_channels = out_channels
class DepthwiseSeparable(nn.Module):
def __init__(self, in_channels, out_channels1, out_channels2, num_groups,
stride, scale):
super(DepthwiseSeparable, self).__init__()
self._depthwise_conv = ConvNormActivation(in_channels,
int(out_channels1 * scale),
kernel_size=3,
stride=stride,
padding=1,
groups=int(num_groups *
scale))
self._pointwise_conv = ConvNormActivation(int(out_channels1 * scale),
int(out_channels2 * scale),
kernel_size=1,
stride=1,
padding=0)
def forward(self, x):
x = self._depthwise_conv(x)
x = self._pointwise_conv(x)
return x
class MobileNetV1(nn.Module):
def __init__(self, scale=1.0, num_classes=1000, with_pool=True):
super(MobileNetV1, self).__init__()
self.scale = scale
self.dwsl = []
self.num_classes = num_classes
self.with_pool = with_pool
# 第一个卷积块
bn1 = nn.BatchNorm2d(num_features=32)
self.conv1 = ConvNormActivation(in_channels=3,
out_channels=int(32 * scale),
kernel_size=3,
stride=2,
padding=1)
self.model = nn.Sequential()
self.model.add_module("conv2_1",DepthwiseSeparable(in_channels=int(32 * scale),
out_channels1=32,
out_channels2=64,
num_groups=32,
stride=1,
scale=scale))
# self.dwsl.append(dws21)
self.model.add_module("conv2_2",DepthwiseSeparable(in_channels=int(64 * scale),
out_channels1=64,
out_channels2=128,
num_groups=64,
stride=2,
scale=scale))
# self.dwsl.append(dws22)
self.model.add_module("conv3_1",DepthwiseSeparable(in_channels=int(128 * scale),
out_channels1=128,
out_channels2=128,
num_groups=128,
stride=1,
scale=scale))
# self.dwsl.append(dws31)
self.model.add_module("conv3_2",DepthwiseSeparable(in_channels=int(128 * scale),
out_channels1=128,
out_channels2=256,
num_groups=128,
stride=2,
scale=scale))
# self.dwsl.append(dws32)
self.model.add_module("conv4_1",DepthwiseSeparable(in_channels=int(256 * scale),
out_channels1=256,
out_channels2=256,
num_groups=256,
stride=1,
scale=scale))
# self.dwsl.append(dws41)
self.model.add_module("conv4_2",DepthwiseSeparable(in_channels=int(256 * scale),
out_channels1=256,
out_channels2=512,
num_groups=256,
stride=2,
scale=scale))
# self.dwsl.append(dws42)
for i in range(5):
self.model.add_module("conv5_" + str(i + 1),DepthwiseSeparable(
in_channels=int(512 * scale),
out_channels1=512,
out_channels2=512,
num_groups=512,
stride=1,
scale=scale))
self.model.add_module("conv5_6",DepthwiseSeparable(
in_channels=int(512 * scale),
out_channels1=512,
out_channels2=1024,
num_groups=512,
stride=2,
scale=scale))
self.model.add_module("conv6",DepthwiseSeparable(
in_channels=int(1024 * scale),
out_channels1=1024,
out_channels2=1024,
num_groups=1024,
stride=1,
scale=scale))
if with_pool:
self.pool2d_avg = nn.AdaptiveAvgPool2d(1)
if num_classes > 0:
self.fc = nn.Linear(int(1024 * scale), num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.model(x)
if self.with_pool: # pooling 后可以不固定图片的尺寸
x = self.pool2d_avg(x)
if self.num_classes > 0:
x = torch.flatten(x,1)
x = self.fc(x)
return x
def _mobilenet(arch, pretrained=False, **kwargs):
model = MobileNetV1(**kwargs)
# if pretrained:
# assert arch in model_urls, "{} model do not have a pretrained model now, you should set pretrained=False".format(
# arch)
# weight_path = get_weights_path_from_url(model_urls[arch][0],
# model_urls[arch][1])
# param = paddle.load(weight_path)
# model.load_dict(param)
return model
def mobilenet_v1(pretrained=False, scale=1.0, **kwargs):
"""MobileNetV1 from
`"MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications" <https://arxiv.org/abs/1704.04861>`_.
Args:
pretrained (bool, optional): Whether to load pre-trained weights. If True, returns a model pre-trained
on ImageNet. Default: False.
scale (float, optional): Scale of channels in each layer. Default: 1.0.
**kwargs (optional): Additional keyword arguments. For details, please refer to :ref:`MobileNetV1 <api_paddle_vision_MobileNetV1>`.
Returns:
:ref: An instance of MobileNetV1 model.
"""
model = _mobilenet('mobilenetv1_' + str(scale),
pretrained,
scale=scale,
**kwargs)
return model
if __name__=="__main__":
x = torch.rand([5,3,224,224])
model = mobilenet_v1()
out = model(x)
print(model)
print(out.shape)
打印输出
MobileNetV1(
(conv1): ConvNormActivation(
(0): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(model): Sequential(
(conv2_1): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv2_2): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64, bias=False)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv3_1): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv3_2): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=128, bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv4_1): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256, bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv4_2): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=256, bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv5_1): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv5_2): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv5_3): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv5_4): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv5_5): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv5_6): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=512, bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
(conv6): DepthwiseSeparable(
(_depthwise_conv): ConvNormActivation(
(0): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024, bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
(_pointwise_conv): ConvNormActivation(
(0): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.9, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
)
)
)
(pool2d_avg): AdaptiveAvgPool2d(output_size=1)
(fc): Linear(in_features=1024, out_features=1000, bias=True)
)
torch.Size([5, 1000])
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











