




 MobileNetV1是一种由Google提出的轻量级深度学习模型,它利用深度分离卷积降低参数量和计算时间,适用于资源受限的移动设备。模型主要特点是使用1x1卷积、全局平均池化和深度可分离卷积,以实现高效和高精度的图像分类。设计MobileNetV1的目的是在保持高准确率的同时减小模型大小和计算需求,使得模型能在移动设备上快速运行。
MobileNetV1是一种由Google提出的轻量级深度学习模型,它利用深度分离卷积降低参数量和计算时间,适用于资源受限的移动设备。模型主要特点是使用1x1卷积、全局平均池化和深度可分离卷积,以实现高效和高精度的图像分类。设计MobileNetV1的目的是在保持高准确率的同时减小模型大小和计算需求,使得模型能在移动设备上快速运行。

目录
MobileNetV1原理
MobileNet V1是一种轻量级的卷积神经网络,能够在保持较高准确率的情况下具有较少的参数量和计算时间。它是由Google的研究人员在2017年提出的,并成为当时最流行的轻量级模型之一。
MobileNet V1的核心思想是通过深度分离卷积来减少模型的参数量和计算时间。与标准卷积不同,深度分离卷积将空间卷积和通道卷积分为两个独立的卷积层,这使得网络更加高效。具体来说,在深度分离卷积中,首先使用一个空间卷积,然后使用一个通道卷积来提取特征。这与标准卷积相比可以减少参数数量并加速运算。
MobileNet V1的网络结构如下:
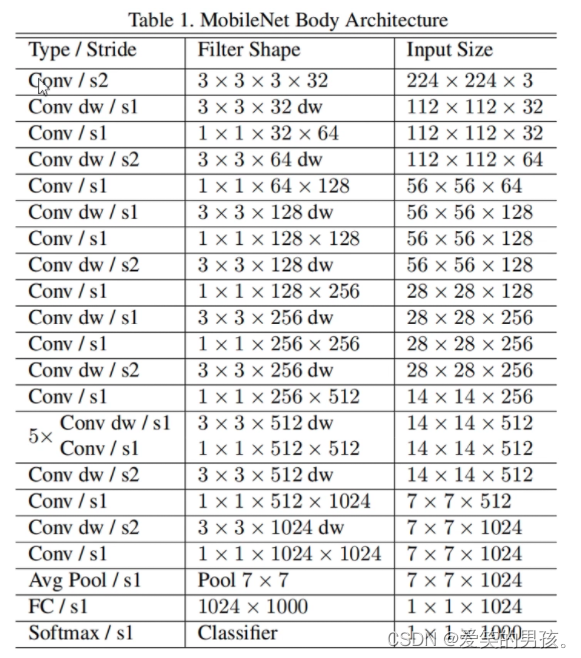
MobileNet V1由序列卷积和1x1卷积两个部分组成。序列卷积包括13个深度可分离卷积层,每个层都包括一个3x3的卷积和一个批量归一化层(BN层),并且在卷积之后使用了ReLU6激活函数。最后,1x1卷积层用于生成最终的特征向量,并使用全局平均池化来缩小特征图的大小。在最后一层之后,使用一个全连接层来进行分类。MobileNet V1可以根据需要使用不同的输入分辨率,其超参数取决于输入分辨率和需要的精度。
为什么要设计MobileNet:
Mobilenetv1是一种轻量级的深度神经网络模型,设计的目的是在保持较高的精度的同时减小模型的大小和计算量,使其适合于移动设备的推理任务。在过去,大部分深度神经网络模型都是基于卷积神经网络(CNN)进行设计的,这些模型往往非常庞大(比如VGG16/VGG19),因此不能直接应用于手机或其他嵌入式设备上。同时,运行这些大型模型所需要的计算资源也很昂贵。
为了解决这个问题,Google Brain团队提出了Mobilenetv1。Mobilenetv1是基于深度可分离卷积(depthwise separable convolution)的设计,它将标准的卷积层分成深度卷积层和逐点卷积层两个部分,用较少的参数和计算量达到了相当不错的准确率。具体来说,深度卷积层用于在每个通道上执行空间卷积,而逐点卷积层(Pointwise Convolution)用于在不同通道之间执行线性变换。这种设计可以减少计算量和模型大小,并使得Mobilenetv1在移动设备上能够运行得更快。
除此之外,Mobilenetv1还使用了其他一些技巧来进一步缩小模型。例如,通过扩张系数(expansion factor)来控制输出通道数和输入通道数之间的关系,从而精细控制模型的大小和复杂度;通过残差连接(Residual Connection)来提高信息流动,从而提高模型的准确性和训练速度。
综合来说,Mobilenetv1是一种非常出色的深度神经网络模型,它在保持较高精确度的同时,大大减小了模型大小和计算量,使得它更容易嵌入到移动和嵌入式设备中。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1446
1446





 到【灌水乐园】发言
到【灌水乐园】发言









