




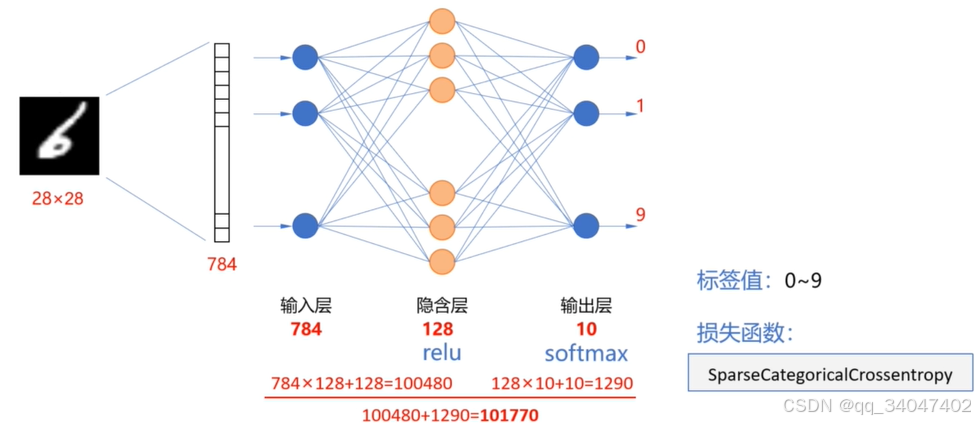
1.keras的minist中有6万条训练集以及1万条测试集。其中每条都是28x28的手写数字。下图所示。可以使用如下的神经元结构进行训练识别。
Sequential模型,使用时的步骤如下:
a.建立模型:
Model = tf.keras.Sequential()
model.add()
b.查看摘要 model.summary()
c.配置训练方法;model.complile()
d.训练模型:model.fit()
e.使用模型:model.predict.
2.代码
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
mist = tf.keras.datasets.mnist
(train_x,train_y),(test_x,test_y)=mist.load_data()
X_train=tf.cast(train_x/255.0,tf.float32)
X_test = tf.cast(test_x/255.0, tf.float32)
y_train =tf.cast(train_y,tf.int16)
y_test = tf.cast(test_y,tf.int16)
#1.建立模型
model=tf.keras.Sequential()
model.add(tf.keras.layers.Flatten(input_shape=(28,28)))
model.add(tf.keras.layers.Dense(128,activation='relu'))
model.add(tf.keras.layers.Dense(10,activation='softmax'))
#2.查看
model.summary()
#3.配置训练方法
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',
metrics=['sparse_categorical_accuracy'])
#4.训练
model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
#评估
model.evaluate(X_test,y_test,verbose=2)
#5.应用
y_pred = np.argmax(model.predict(X_test[0:4]),axis=1)
for i in range(4):
plt.subplot(1,4,i+1)
plt.axis('off')
plt.imshow(test_x[i],cmap='gray')
plt.title("y="+str(test_y[i])+"\n y_pred:"+str(y_pred[i]))
plt.show()

summary输出的内容如下:显示有101770个参数。

3.如果需要保存所有模型以及参数。
可以使用model.save来保存模型以及参数。比如
model.save("testmodel.h5")
使用时如下文所示,这样就不需要搭建模型以及训练了。
model = tf.keras.models.load_model("testmodel.h5")
【备注】
Metrics可选:
'acuracy', 则y_和y都是数值,y_=[1], y=1
'categorical_accuracy':则y_和y都是独热码(概率分布),y_=[0,1,0]之类
'sparse_categorical_accuracy':则y_是数值(标准),y都是独热码(概率分布)-计算结果
【附录2】解决keras.datasets 在loaddata时,无法下载的问题
或者将下载好的imdb.npz文件放在主目录下的 .keras/datasets文件夹下
C:\Users\Administrator\.keras\datasets



















 8655
8655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











