







DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
摘要
虽然采用扩散模型来生成高质量图像已经取得了巨大的进展,但是要通过该方法构建多分辨率图像还存在不小的困难。这主要是由于扩散模型需要消耗庞大的计算量才能达到理想效果,造成了非常严重的时间延迟问题,而此类应用在交互性方面具有核心作用。为解决这个难点,我们提出了 DistriFusion 模型以实现高效率处理。该模型首先将输入分片后再按 GPU 分配,但是由于无法考虑图像相邻层之间的关联性就可能导致丢失了原始信息并产生模糊度。为此我们推测了这些输入中间很多相邻图片之间存在高度重合,然后利用其交互性的特点实现了距离式并行化。 从而,可以解决不同 GPU 间敏捷处理问题和通信过程中需要消耗大量计算能力的难题,获得高达 6.1 倍的速度提升。我们还在该方法基础上构建了一个软件库并公开发布,可以访问 https://github.com/mit-han-lab/distrifuser。通过多种实验测试结果显示:该模型在与 Stable Diffusion XL 相关的应用中没有任何影响,而且可以将图像处理速度提高了 6.1 倍。
Overview

我们发明了DistriFusion,这是一种不需要训练的算法,可以通过将多个GPU合并起来快速推断透形模型,同时保持图像质量。在 (b) 方法中,由于没有对局部区域进行互动处理,因此会出现分割问题。本文的示例都是通过SDXL生成并以50步Euler样条采样器在1280×1920的分辨率下进行测试,并且运算性能被测量在A100 GPU上。
Method
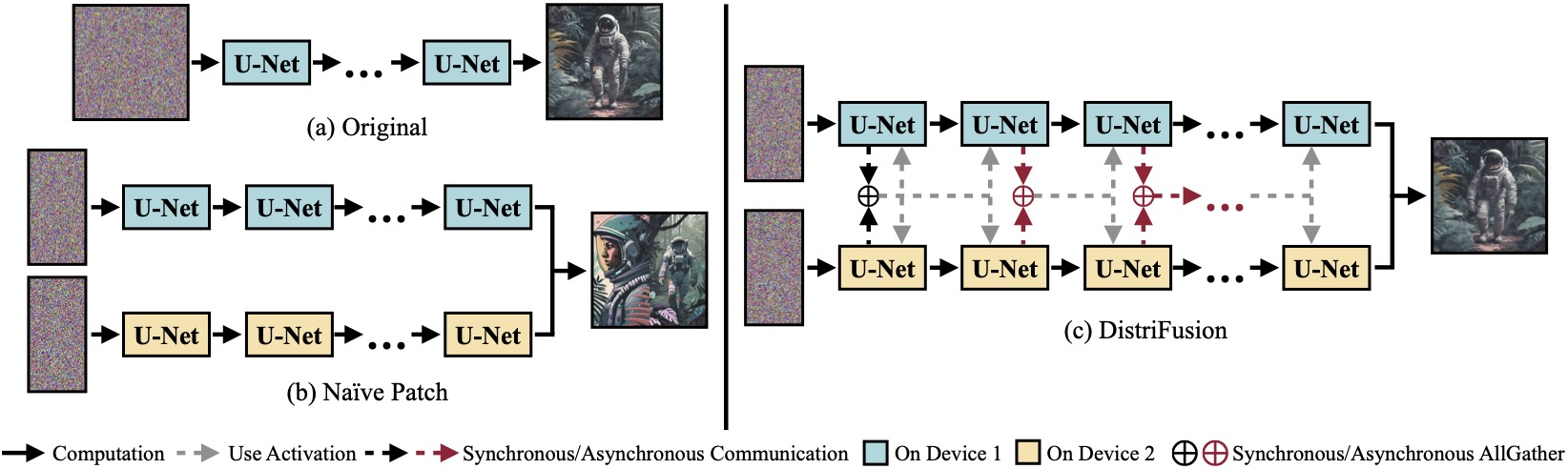
(a)在单个设备上运行的原始分布式模型。 (b)简易地将图像切割成2块,然后通过跨越2张GPU进行处理,那么就会有明显的边界线。(c)我们的DistriFusion采用同步通信与不同步通信的组合模式,在第一个操作中使用同步通信进行图片之间的交互,然后再利用非同步通信将前面的操作的活化值传递出去。这样可以隐藏带来的计算量和通讯量,从而使得通信瓶颈能够被包裹在处理过程中。
Speedups
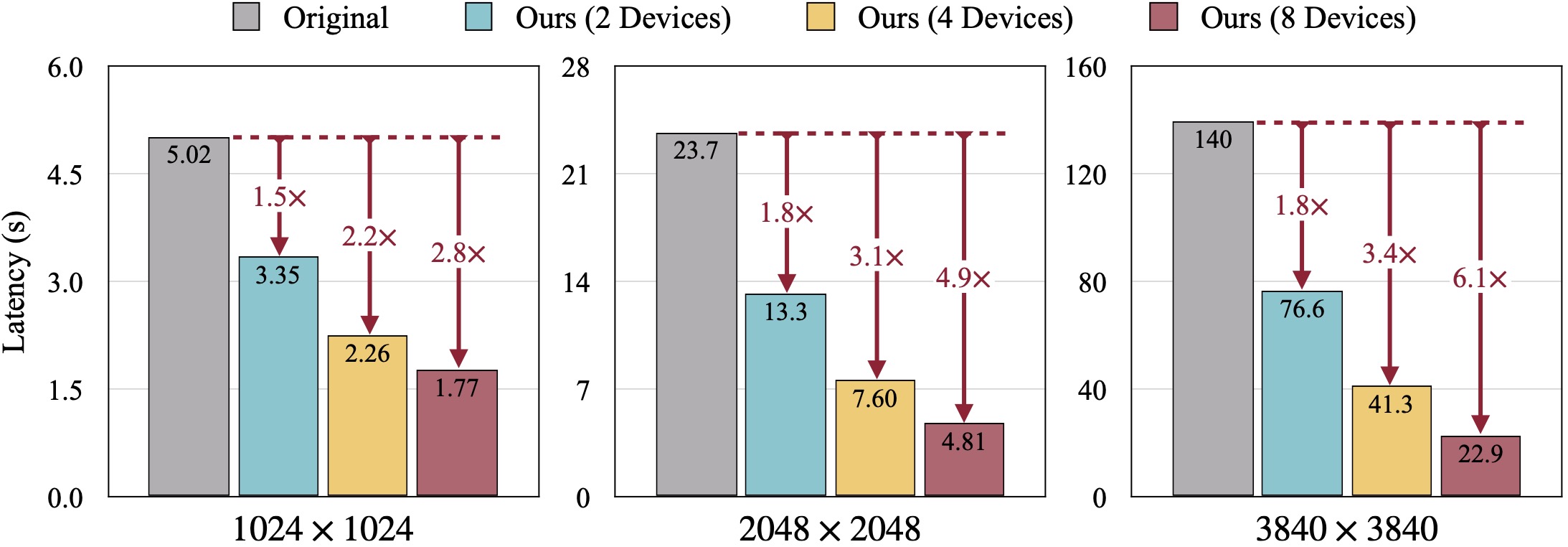
通过在NVIDIA A100 GPU上使用50步DDIM随机数发生器对DistriFusion进行测试,并将其与SDXL配合利用。当增加分辨率时,通过GPU设备更好地使用了显存设置。令人惊奇的是,在生成3840×3840像素的图片时,DistriFusion达到1.8倍、3.4倍和6.1倍的速度提升效果(分别为2个、4个和8个A100)。
Quality Results

分辨率图像的质量结果。 坦克队(TANK)检测器利用真实场景的图像进行计算,我们的 DistriFusion 技术可以通过调节使用设备数量来优化延迟,同时保持视觉精确性。



















 1043
1043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











