






一、整体流程
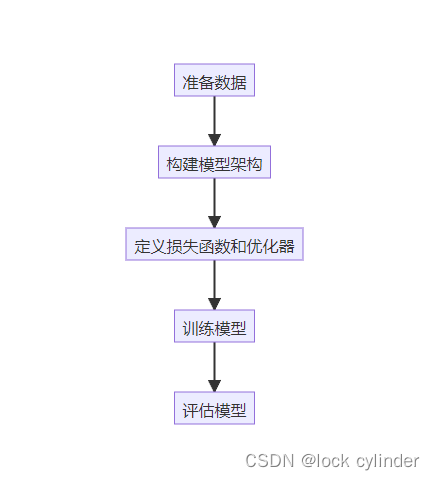
二、 详细步骤
1. 准备数据
在构建自然语言处理模型之前,首先需要准备数据。可以使用PyTorch提供的Dataset和DataLoader类来加载和处理数据。
# 导入必要的库
import torch
from torch.utils.data import Dataset, DataLoader# 定义自定义Dataset类
class MyDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return self.data[idx]# 准备数据集
data = [...] # 数据集
dataset = MyDataset(data)
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
2. 构建模型架构
接下来,需要定义模型的架构。可以使用PyTorch提供的nn.Module类来构建模型。
# 导入必要的库
import torch.nn as nn# 定义模型类
class MyModel(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
# 定义模型层
self.fc = nn.Linear(in_features, out_features)
def forward(self, x):
# 模型前向传播
x = self.fc(x)
return x# 实例化模型
model = MyModel()
3. 定义损失函数和优化器
在训练模型之前,需要定义损失函数和优化器。常用的损失函数包括交叉熵损失函数,优化器可以选择Adam或者SGD。
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
4. 训练模型
训练完成后,可以对模型进行评估,比如计算准确率等指标。
# 评估模型
correct = 0
total = 0
with torch.no_grad():
for data in dataloader:
inputs, labels = data
outputs = model(inputs)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()accuracy = correct / total
print(f'Accuracy: {accuracy}')
结论
通过以上步骤,你可以成功地使用PyTorch构建自然语言处理模型了。希望这篇教程能帮助你入门和理解深度学习模型的构建过程。如果有任何疑问,欢迎随时向我提问。加油!















 718
718











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









