






 文章介绍了使用YOLOv8深度学习算法对两轮车头盔进行实时检测的方法,包括数据集TWHD的收集、修改和划分,以及如何将VOC格式数据转换为YOLO所需的格式进行训练。
文章介绍了使用YOLOv8深度学习算法对两轮车头盔进行实时检测的方法,包括数据集TWHD的收集、修改和划分,以及如何将VOC格式数据转换为YOLO所需的格式进行训练。
实验结果展示
随着国家惩治行车不戴头盔违法行为的力度不断加大,双轮车(电动车与摩托车)头盔检测任务也越来越重要。为此,我们采用YOLOv8对头盔进行检测,从而有效遏制违法行为。


数据集
TWHD数据集
two wheeler helmet dataset 双轮车头盔检测数据集 原始数据集无法用于YOLOv8训练 因此,针对YOLOv8进行了针对性修改。修改后数据集链接:
数据集介绍
随着国家惩治行车不戴头盔违法行为的力度不断加大,双轮车(电动车与摩托车)头盔检测任务也越来越重要,为此我们收集数据并开源了TWHD(two wheeler helmet dataset),总计5448张图片,对图片中的双轮车与驾乘人员整体、未戴头盔的人头、戴头盔的人头进行定位与分类标注。按4:1的比例划分训练集与测试集。TWHD的数据集来自OSF dataset、bike helmet dataset以及网络爬虫,从OSF dataset随机抽取4710张图片并重新标注;此外为了丰富数据集背景、让神经网络区分自行车与双轮车(电动车、摩托车),还融合了来自bike helmet dataset以及网络爬虫的738张图片。
链接
https://gitee.com/bilibilee/TWHD
训练环境
训练环境采用YOLOv8
pip install Ultralytics
安装成功即可
主要代码
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
train: ../datasets/images/train # train images (relative to 'path') 4 images
val: ../datasets/images/val # val images (relative to 'path') 4 images
test: ../datasets/images/test # test images (optional)
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8-cls image classification model. For Usage examples see https://docs.ultralytics.com/tasks/classify
# Parameters
# Classes
#names:
# 0: without_helmet,
# 1: helmet,
# 2: two_wheeler
names:
0: 'without_helmet'
1: 'helmet'
2: 'two_wheeler'
from ultralytics import YOLO
model = YOLO('yolov8n.yaml') # build a new model from YAML
# Load a model
model = YOLO('yolov8n.pt') # load a pretrained model (recommended for training)
# Train the model
results = model.train(data=r'mydata.yaml', epochs=100, imgsz=640)
import xml.etree.ElementTree as ET
import os
import shutil
"""
完成操作:
读取每个集中的文件名
图片分类
标签 xml读取、解析、分类至TXT
"""
path_VOC_datasets = 'F:\DataSets\VOCdevkit\helmetdataset' # VOC格式数据集地址
path_train_set = 'ImageSets\\Main\\train.txt' # 训练集文件地址
path_val_set = 'ImageSets\\Main\\val.txt' # 验证集文件地址
path_test_set = 'ImageSets\\Main\\test.txt' # 测试集文件地址
path_labels = 'Annotations' # 标签信息地址
path_images = 'JPEGImages' # 图片信息地址
# 地址整合
path_train_set = os.path.join(path_VOC_datasets, path_train_set)
path_val_set = os.path.join(path_VOC_datasets, path_val_set)
path_test_set = os.path.join(path_VOC_datasets, path_test_set)
path_labels = os.path.join(path_VOC_datasets, path_labels)
path_images = os.path.join(path_VOC_datasets, path_images)
path_yolo_datasets = 'F:\DataSets\VOCdevkit\yolov8' # YOLO格式数据集地址
path_train_images = 'train\\images' # 训练集图片地址
path_train_labels = 'train\\labels' # 训练集标签地址
path_val_images = 'val\\images' # 验证集图片地址
path_val_labels = 'val\\labels' # 验证集标签地址
path_test_images = 'test\\images' # 测试集图片地址
path_test_labels = 'test\\labels' # 测试集标签地址
# 地址整合
path_train_images = os.path.join(path_yolo_datasets, path_train_images)
path_train_labels = os.path.join(path_yolo_datasets, path_train_labels)
path_val_images = os.path.join(path_yolo_datasets, path_val_images)
path_val_labels = os.path.join(path_yolo_datasets, path_val_labels)
path_test_images = os.path.join(path_yolo_datasets, path_test_images)
path_test_labels = os.path.join(path_yolo_datasets, path_test_labels)
# 文件后缀名
f_image_ext = '.jpg'
f_xml_ext = '.xml'
f_txt_ext = '.txt'
# yaml文件中类别名和标号对应字典
dict_name_class = {
'without_helmet': 0,
'helmet': 1,
'two_wheeler': 2
}
# VOC格式标号读取
# filename:文件路径
def read_file(filename):
file = open(filename, 'r')
text_line = file.readlines()
for i in range(len(text_line)):
text_line[i] = text_line[i][:-1]
file.close()
return text_line
# 复制图片函数
# set:列表,读取到的文件标号
# file_extension:文件扩展名
# source:原数据集地址
# target_folder:目标文件夹
def copy_file(set, file_extension, source, target_folder):
for i in range(len(set)):
filename = os.path.join(source, set[i]) + file_extension
try:
shutil.copy(filename, target_folder)
except IOError as e:
print("Unable to copy file. %s" % e)
exit(1)
# source:xml原路径 target_folder:写入txt路径
# VOC格式xml文件读取,分析,转化为txt,并写入目标文件夹
# set:列表,读取到的文件标号
# xml_ext:文件扩展名
# source:原数据集地址
# target_folder:目标文件夹
# txt_ext:文件扩展名
def VOC_to_TXT(set, xml_ext, source, target_folder, txt_ext):
for i in range(len(set)):
xml_file = os.path.join(source, set[i]) + xml_ext
txt_file = os.path.join(target_folder, set[i]) + txt_ext
tree = ET.parse(xml_file)
root = tree.getroot()
width = float(root.find('size').find('width').text)
height = float(root.find('size').find('height').text)
all_objects = root.findall('object')
file = open(txt_file, 'w')
for child in all_objects:
print(child)
num = dict_name_class[child.find('name').text]
x_max = float(child.find('bndbox').find('xmax').text)
y_max = float(child.find('bndbox').find('ymax').text)
x_min = float(child.find('bndbox').find('xmin').text)
y_min = float(child.find('bndbox').find('ymin').text)
obj_x = (x_max + x_min) / width / 2.0
obj_y = (y_max + y_min) / height / 2.0
obj_width = (x_max - x_min) / width / 2.0
obj_height = (y_max - y_min) / height / 2.0
file.write(f'{num} {obj_x} {obj_y} {obj_width} {obj_height}\n')
file.close()
# 读取每个集中图片名称
train_set = read_file(path_train_set)
val_set = read_file(path_val_set)
test_set = read_file(path_test_set)
print("Read Name Finish!")
#复制图片
# copy_file(train_set, f_image_ext, path_images, path_train_images)
# copy_file(val_set, f_image_ext, path_images, path_val_images)
# copy_file(test_set, f_image_ext, path_images, path_test_images)
# print("Copy Images Finish!")
# 转化xml到txt
# 读取H W,读取object的name、xymin、xymax,转换、计算,写入txt
VOC_to_TXT(train_set, f_xml_ext, path_labels, path_train_labels, f_txt_ext)
VOC_to_TXT(val_set, f_xml_ext, path_labels, path_val_labels, f_txt_ext)
VOC_to_TXT(test_set, f_xml_ext, path_labels, path_test_labels, f_txt_ext)
print("Convert Labels Finish!")
训练结果
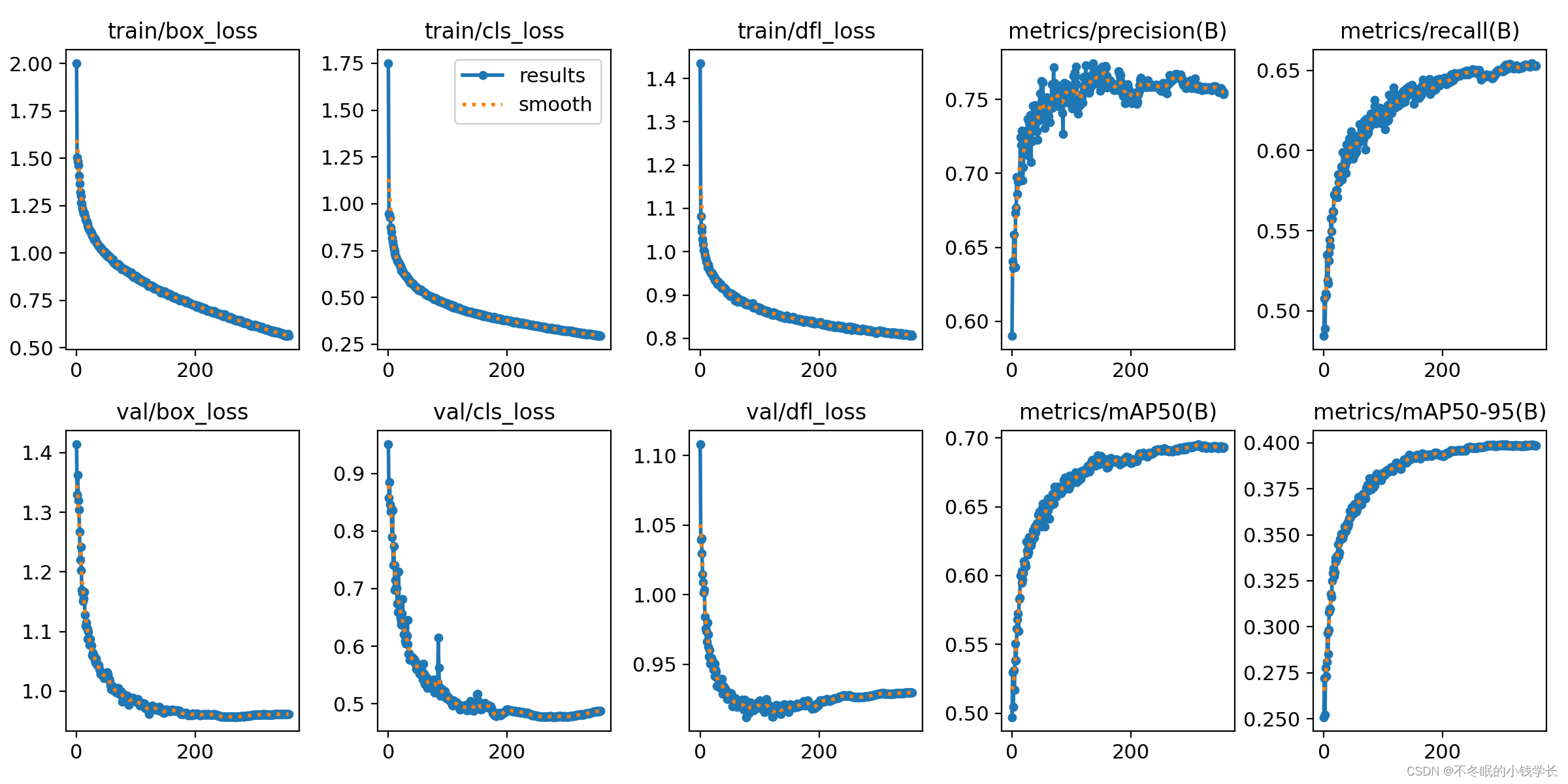
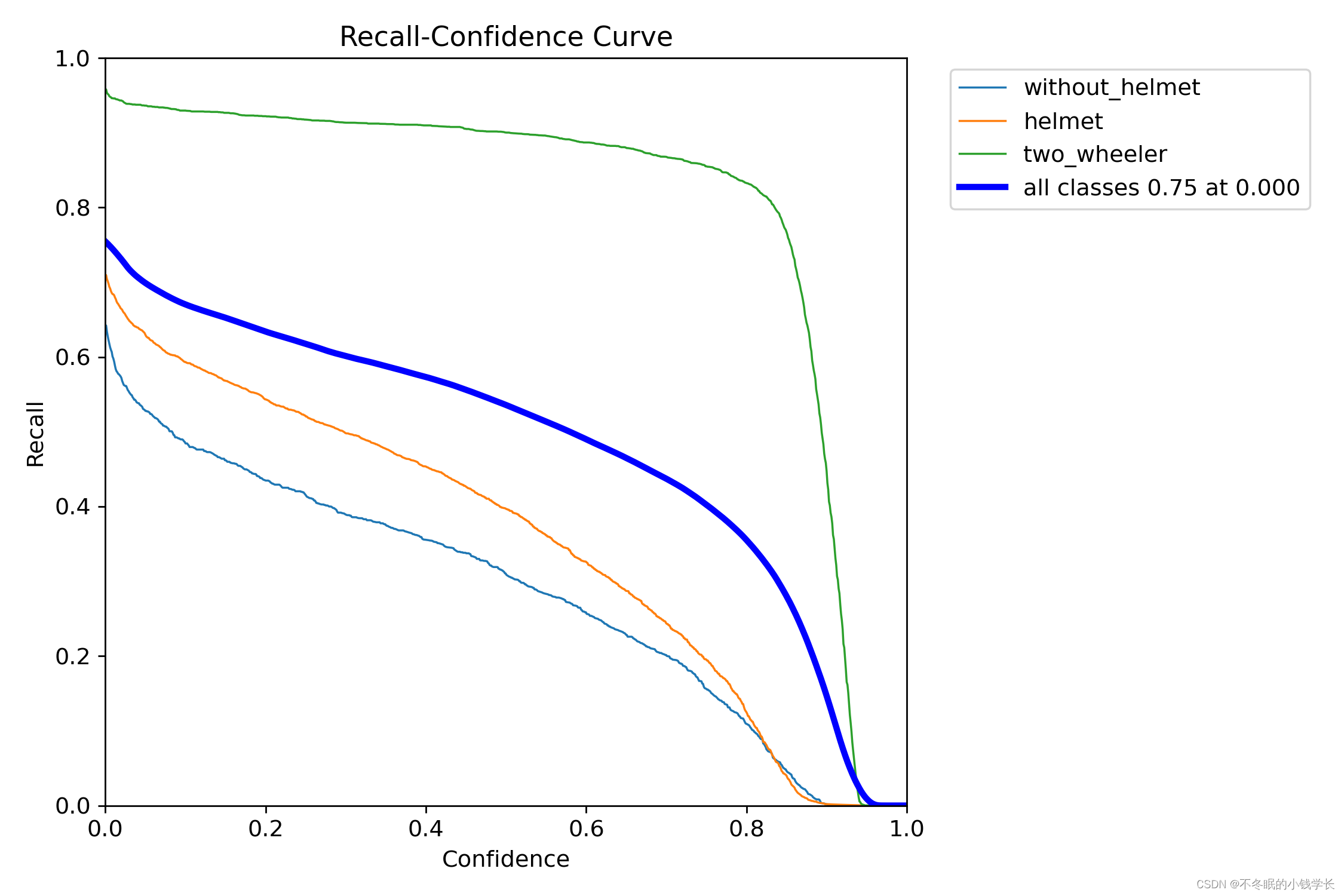
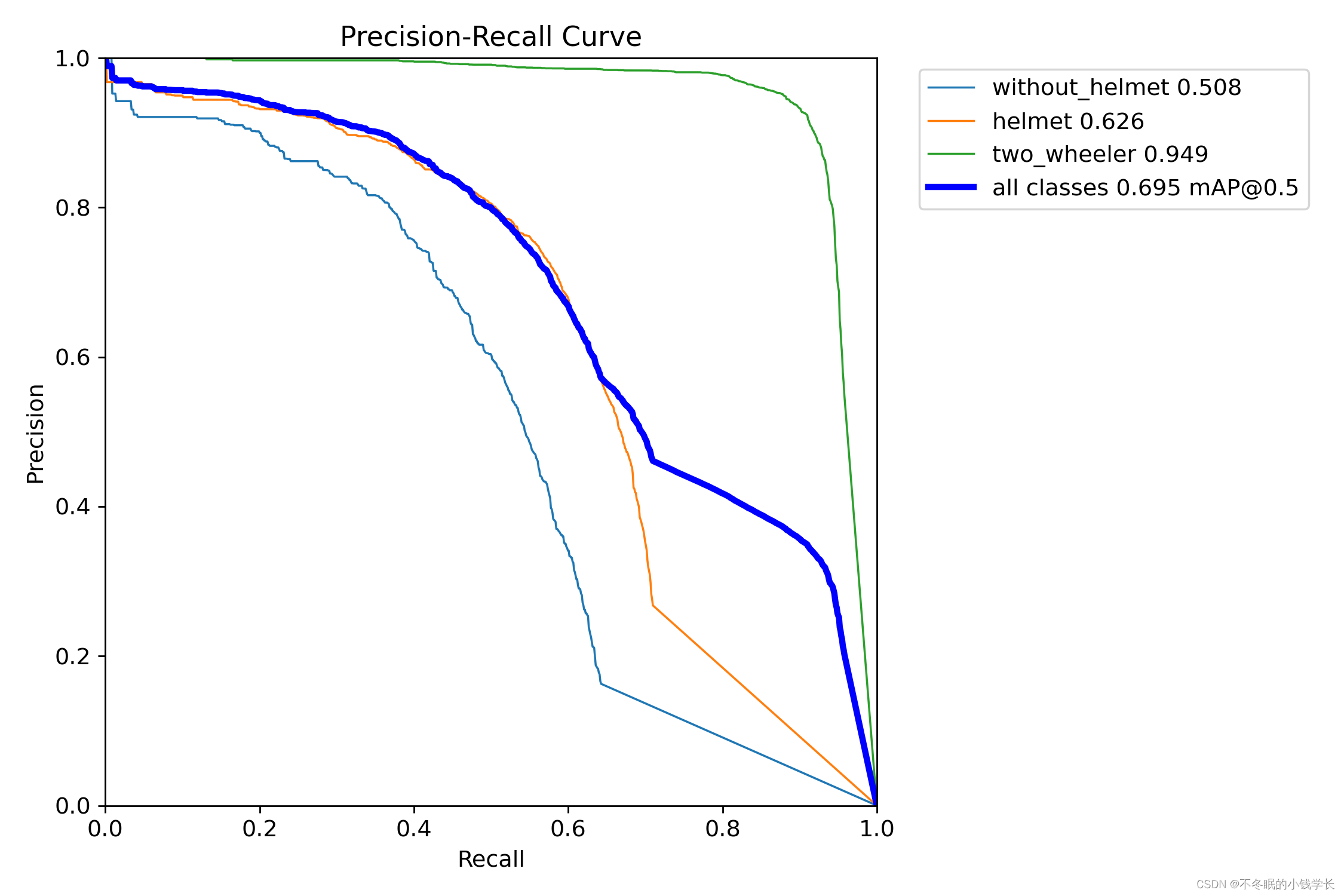
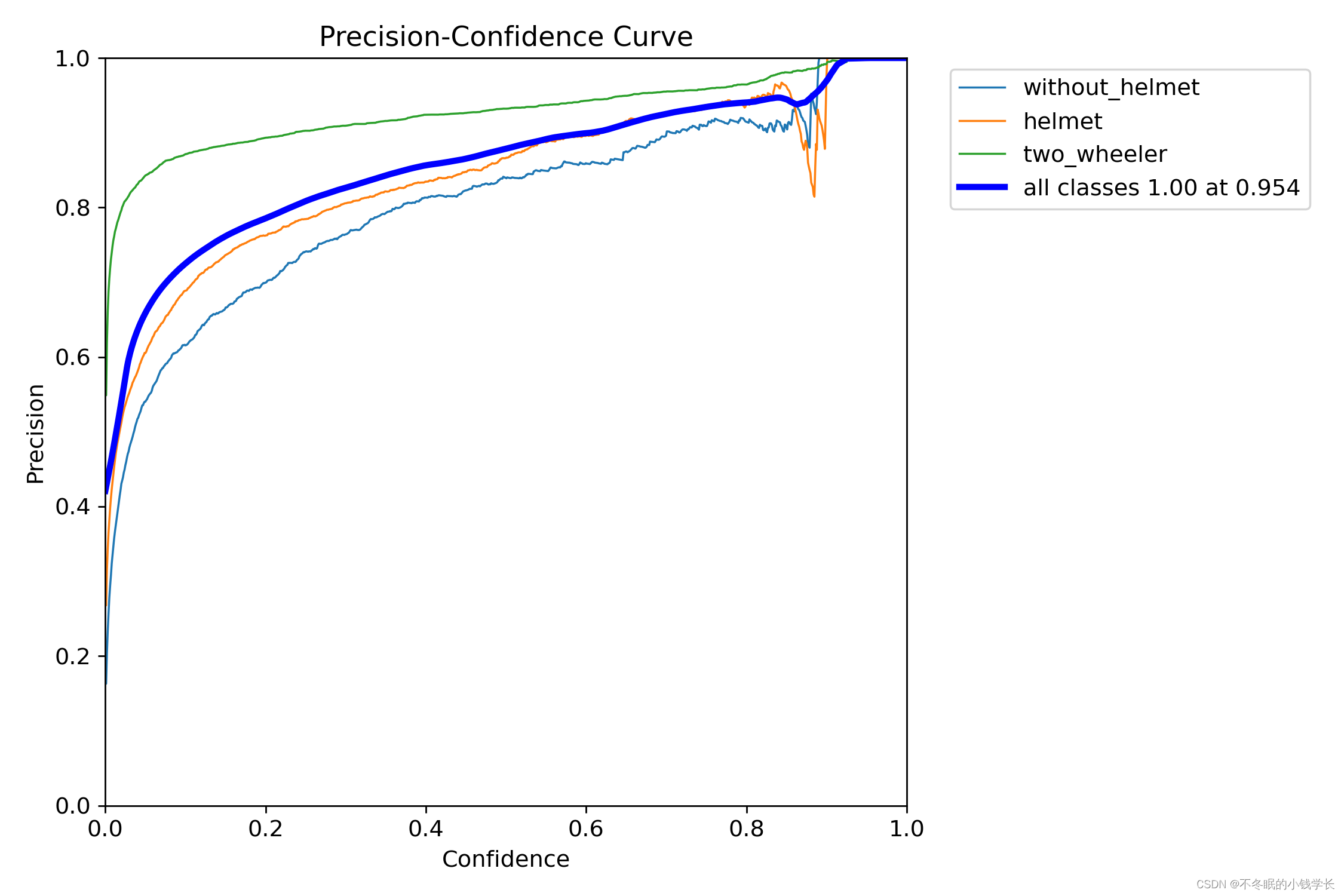
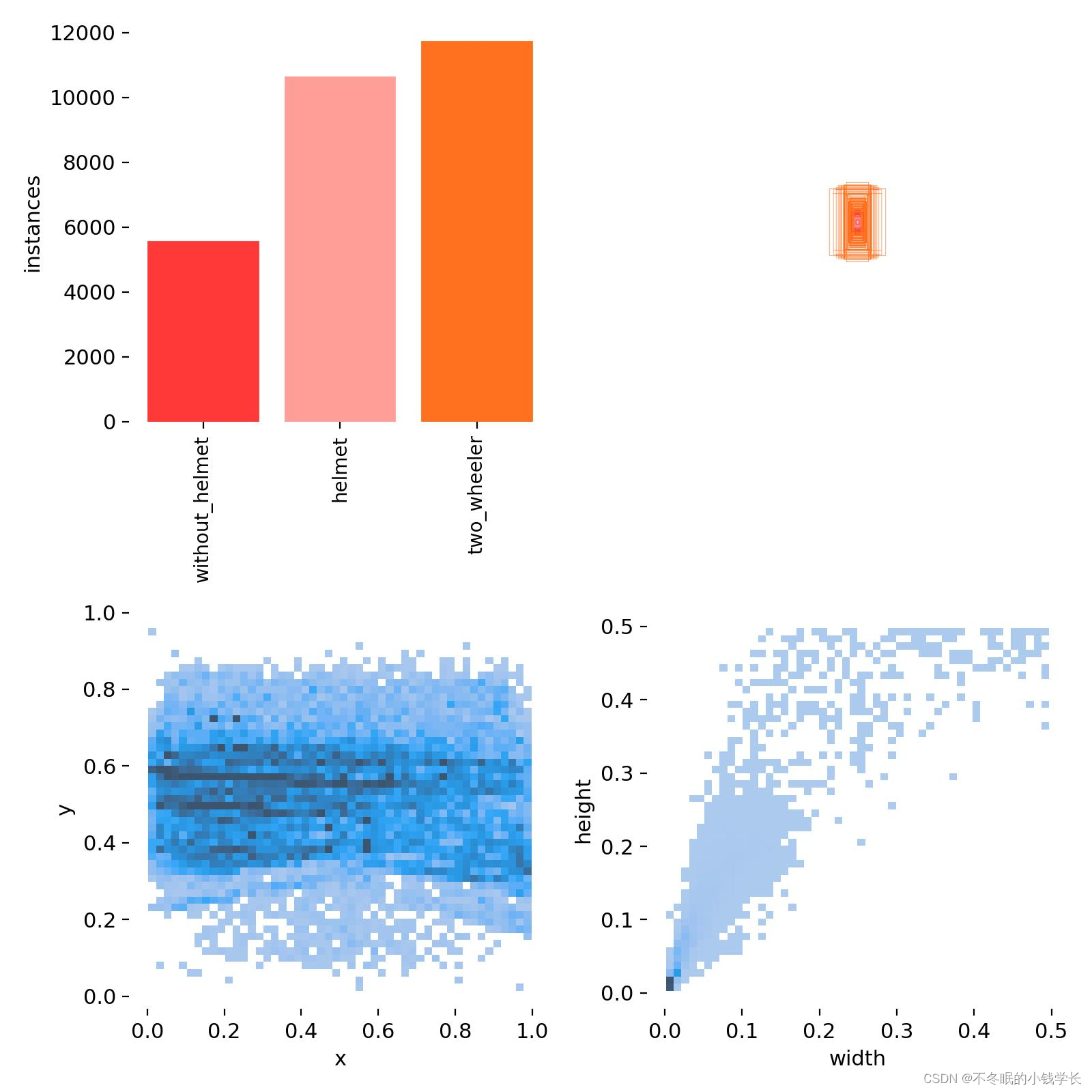
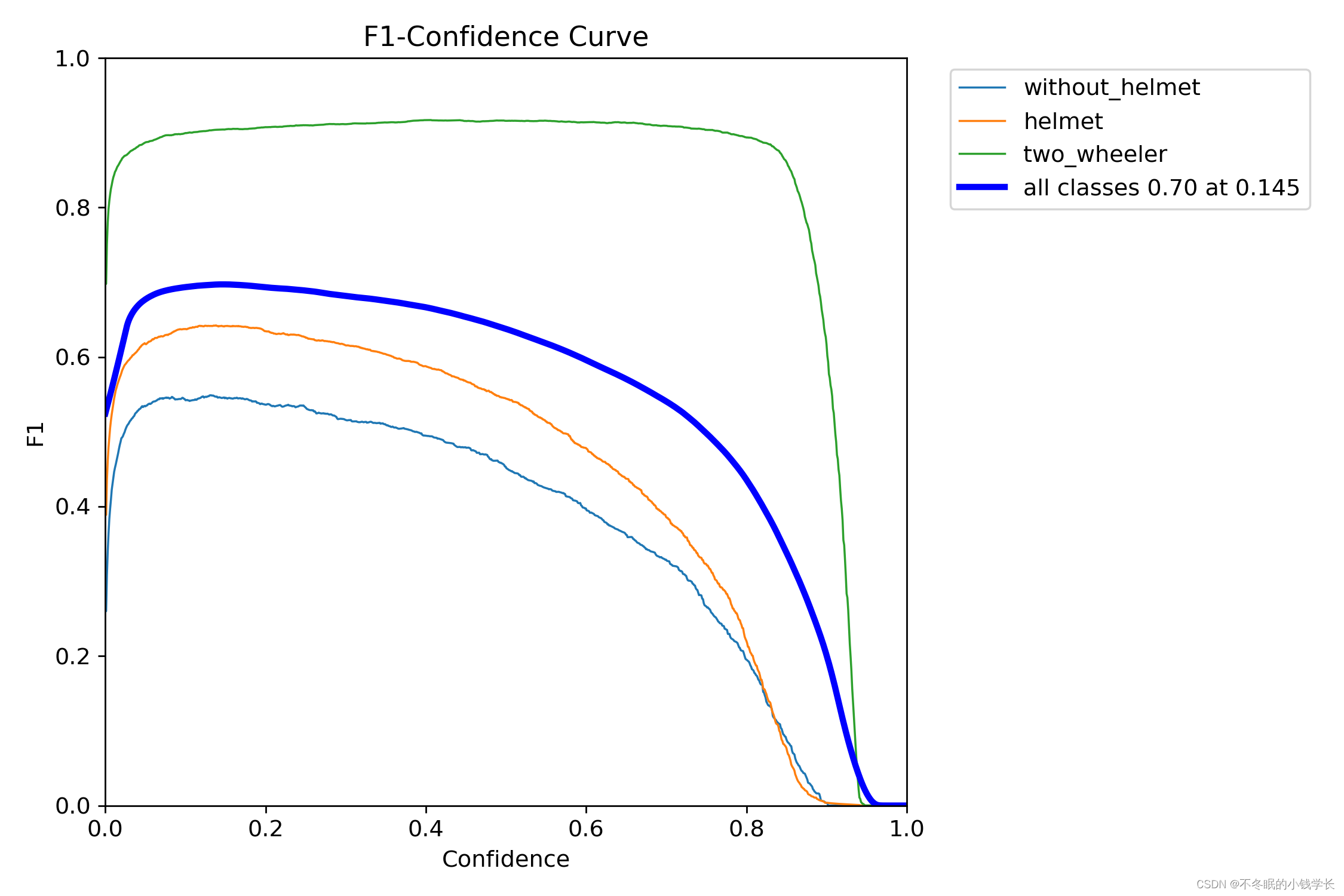
关键词
YOLOv8, 头盔检测, 两轮车安全, 实时对象检测, 深度学习, 计算机视觉, YOLOv8头盔检测算法, 两轮车头盔佩戴检测, 基于YOLOv8的安全监控, 摩托车头盔自动检测, 使用深度学习进行头盔识别, 智能交通系统中的头盔检测, 基于计算机视觉的安全装备检测, 如何使用YOLOv8检测头盔, YOLOv8在交通安全中的应用, 提高两轮车驾驶安全的技术, 深度学习如何帮助交通规则执行, 最新的头盔检测技术是什么


















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











