







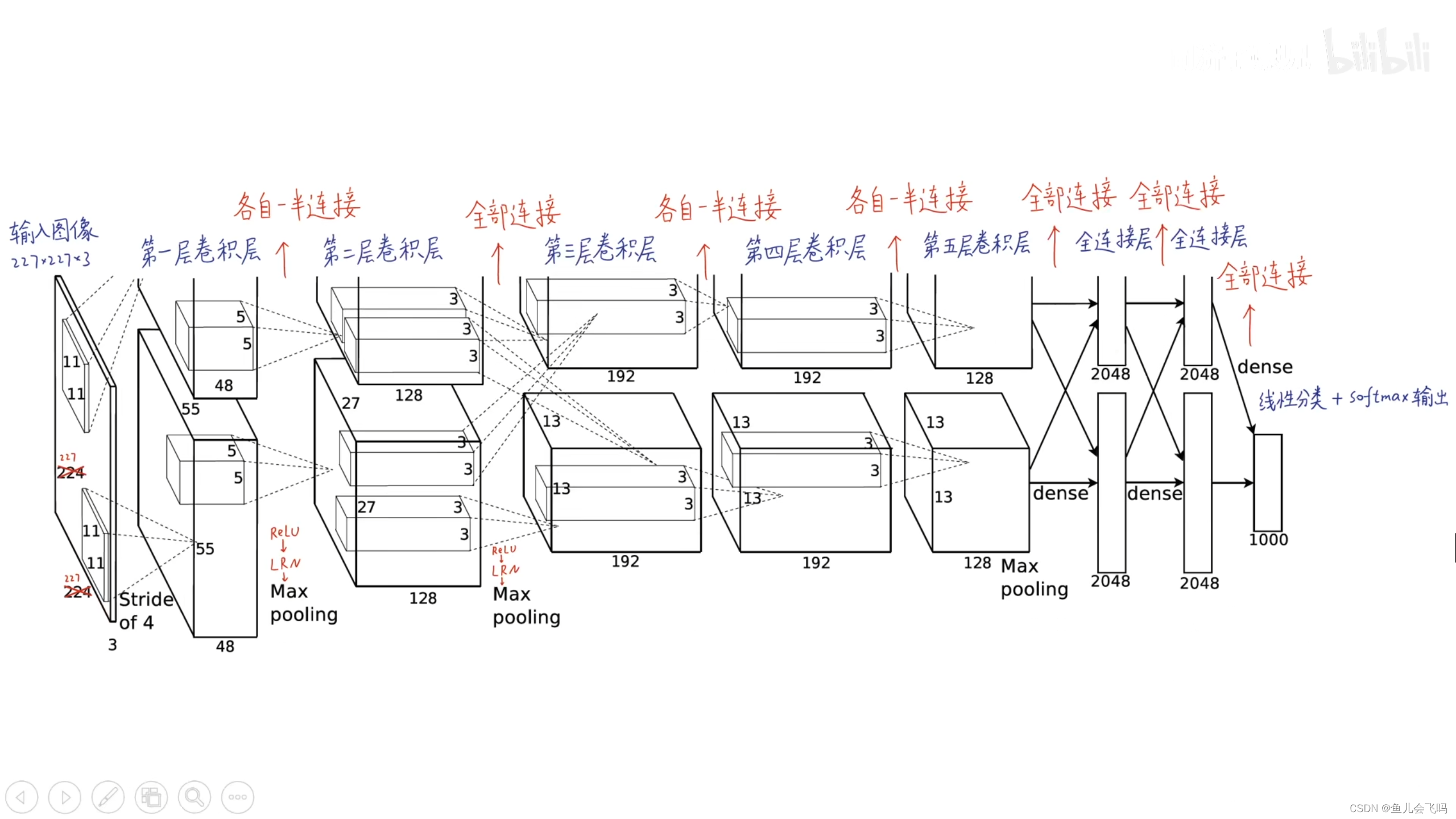
分析:因为在AlexNet2012年的时候,计算机的算力还不足以支持训练这么一个庞大深层的模型,所以AlexNet采取了一个折中的技巧,就是把模型并行的放在两个GPU上,每一个GPU各自拥有一半的神经元,上面是一个,下面是一个,这两个GPU只在这一层和全连接层,就是只在这些互相有连接的地方能够进行两个GPU之间的显存读取和通信,在其它层,每一个层只能接受上一个GPU传过来的独自这边的数据,所以这种模型并行的方法,也是他的一个特点,把神经元分别放在两个GPU上进行训练。
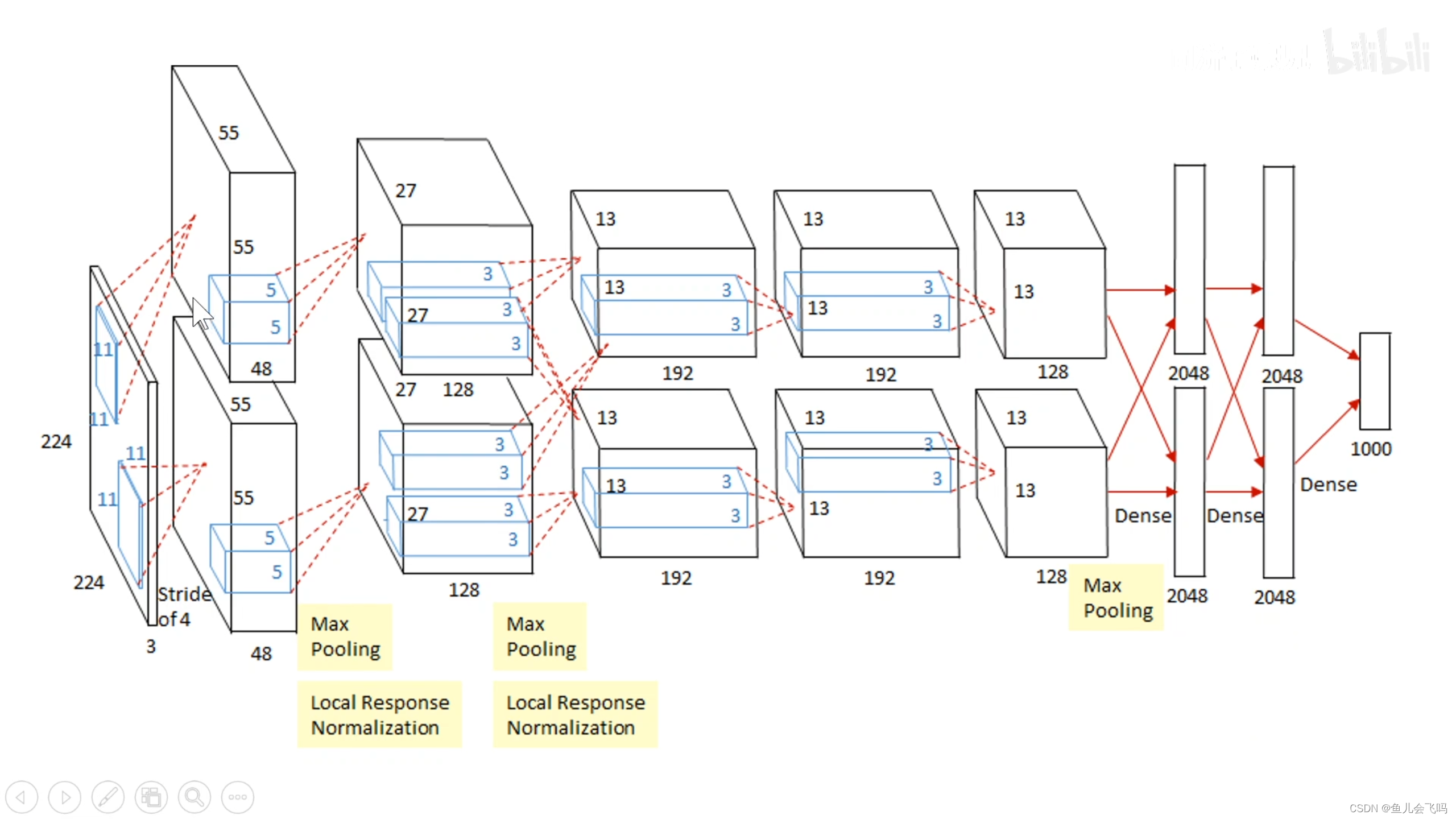
我们可以看到AlexNet输入的图像是227乘227乘3,当然原始论文里面写的是224乘224乘3,这是一个错误,应该是227乘227乘3,否则第一层的这个feature map的大小无法计算。
经过第一层卷积层,第二层卷积层,第三层卷积层,第四层卷积层,第五层卷积层,之后把得到的feature map拉平成一个长向量,把这个长向量喂到第一个全连接层里面,第一个全连接层有4096个神经元,两个GPU各自有2048个神经元,第二个全连接层也有4096个神经元,两个GPU各自有2048个神经元。
最后到这个输出层,这个输出层是1000个神经元,这1000个神经元是一个线性分类层,并没有非线性的激活函数,每一个神经元输出的是它对应的某一个类别的logits分数,这1000个神经元就对应着ImageNet1000个类别的分数,对这1000个分数进行softmax归一化,把它变成了1000个概率,这1000个概率相加和为1,每一个概率都是0到1之间的。
这样就得到了我们的图像分类模型,把一个图片变成了一个1000维的向量,1000维的向量就表示这个图片的类别是这1000个中的哪一个,我们从里面挑出来最大的一个,或者是5个,作为预测结果,就完成了图像分类的作用。
在这个网络中所有的神经元,所有非线性的神经元都使用ReLU激活函数,在第一层和第二层还有一个局部响应归一化LRN层。
在第二层卷积层和第三层卷积层之间,两个GPU完全能够全部连接,在全连接层和最后一个卷积层之间,也是全部连接的,在其它层里面,每一个神经元都只能接受同一个GPU从上一层传来的数据。
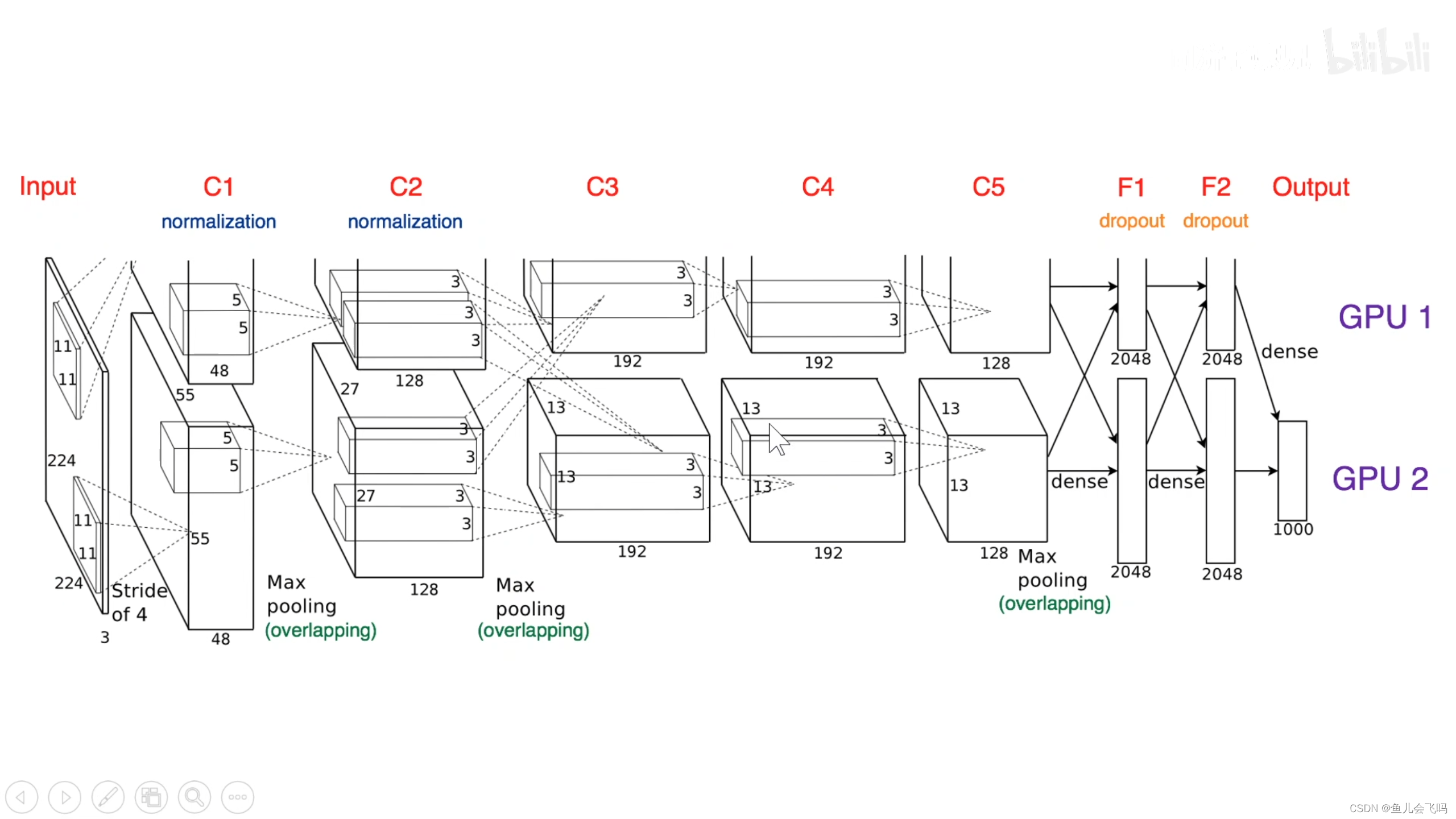
最大池化是重叠的最大池化
参考:
同济子豪兄AlexNet图像分类论文精读














 8250
8250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









