










日期
2023-5-29
论文标题
SAMLoc: Structure-Aware Constraints With Mutil-task Distillation for Long-term Visual Localization
摘要
Real-time and robust long-term visual localization is a key technology for autonomous driving. Season and illumination variance, as well as limited computing power make this problem more challenging. At present, most of the excellent visual localization algorithms cannot run in real-time on devices with limited computing power. In this paper, we propose SAMLoc, a self-supervised 6-DoF visual localization method with structure-aware and multi-task distillation. We integrate the structure-aware constraints into the hierarchical localization network of multi-task distillation, which greatly reduces the feature extraction time while ensuring localization accuracy, thus achieving real-time and robust large-scene localization on mobile devices. Our method takes both speed and accuracy into consideration, and extensive experiments have been conducted to validate the effectiveness of the proposed approach on several datasets. Our network is not only lightweight but also has excellent generalization ability, and still exhibits high localization accuracy even with challenging datasets.
引用信息(BibTeX格式)
@INPROCEEDINGS{10161033,
author={Ning, Jian and Zhang, Yunzhou and Zhao, Xinge and Coleman, Sonya and Li, Kunmo and Kerr, Dermot},
booktitle={2023 IEEE International Conference on Robotics and Automation (ICRA)},
title={SAMLoc: Structure-Aware Constraints With Multi-Task Distillation for Long-Term Visual Localization},
year={2023},
volume={},
number={},
pages={11719-11725},
doi={10.1109/ICRA48891.2023.10161033}}
本论文解决什么问题
实时、鲁棒的长期视觉定位是自动驾驶的关键技术。对视觉定位的精度和速度的要求也越来越高,特别是在一些具有挑战性的场景中,特别是在环境、季节和光照变化以及有限的计算能力。目前,大多数优秀的视觉定位算法都无法在计算能力有限的设备上实时运行。本文提出了一种具有结构感知和多任务蒸馏的自监督六自由度视觉定位方法SAMLoc,在保证定位精度的同时大大缩短了特征提取时间,从而实现了移动设备上实时、鲁棒的大场景定位。
已有方法的优缺点
目前传统的视觉定位方法有2D-2D、2D-3D等。与传统的视觉定位方法相比,基于深度学习的方法具有明显的优势。2D-2D视觉定位通常采用图像检索方法。这种方法通常构建深度学习的全局特征描述符并进行位置识别。然而,当场景相似或视角变化时,很难确定图像的位姿。最近的研究将语义和几何信息融合到2D-2D定位中,引入了领域自适应,这些方法显著提高了定位效果,但精细定位精度仍有待提高。
端到端方法与基于图像检索的方法相比有明显的改进,但这种方法只能从输入图像中获取信息。由于姿态估计过程没有几何约束,因此泛化性能通常不强,通常需要在新的场景中重新训练以适应它。此外,在真实的驾驶环境中,gound truth 通常很难获得,尤其是在具有挑战性的户外场景中。
基于2d - 3d的方法仍然是流行的视觉定位方法,尽管目前已经出现了许多定位系统,具有良好的定位精度。然而,当背景环境变得非常大时,匹配过程可能需要很长时间。在计算资源有限的计算设备中,大多数模型受到2D-3D匹配过程中大量参数和庞大计算量的限制。Sarlin 提出了一种分层定位和多任务蒸馏模型,既保证了模型的准确性,又在移动设备上保持了高效率。
目前,视觉定位方法的精度很高,但速度有待提高。多任务蒸馏方法可以大大提高特征提取的速度,但在一定程度上也存在精度上的损失。边缘特征可以准确提取场景中的结构信息,边缘信息既可用于相机定位,以提高姿态估计的精度,也可将边缘特征与光流估计融合来求解边界流连续帧的估计问题。
本文采用什么方法及其优缺点
设计了场景特征提取的结构感知模块(structure-aware module),并将其与基于多任务蒸馏的分层定位网络相结合,实现实时鲁棒的视觉定位。
A. Structure-Aware Constraint (结构感知模块)
受到Dexined 的启发并对其网络进行改进,图像像素会随着光照和季节因素而变化,但房屋、路灯等物体的轮廓信息是稳定不变的,因此边缘信息非常可靠,同时为了完成多层蒸馏任务,提出了局部结构感知约束和全局结构感知约束的概念,用于知识精馏的多任务精馏分层定位网络。我们将网络分为两部分,第一部分用于获取详细的结构纹理,第二部分用于捕获场景的结构信息。如下图:
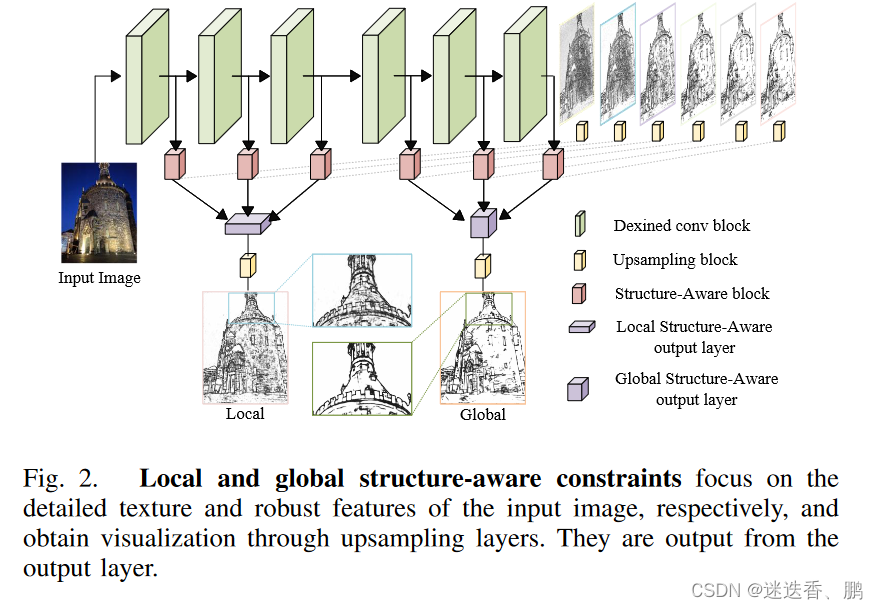
改进如下:
1、在每侧输出的上采样块之前加入一个侧结构感知模块(side structure-aware module),以提高网络的结构感知。它由1×1卷积层和上采样组成。
2、将网络的前三块和后三块的输出端口分别通过1×1卷积作为结构感知约束的输出,然后通过上采样获得局部结构感知和全局结构感知的可视化图像。
3、去掉了原网络的最后一层融合层,因为它降低了结构感知模块的训练影响,并对损失函数进行了修改,损失函数如下:
L
=
(
∑
i
=
1
6
α
i
L
o
u
t
p
u
t
i
(
W
,
w
i
)
)
+
β
C
r
o
s
s
E
n
t
r
o
p
y
(
Y
,
Y
^
p
r
e
d
l
)
+
γ
C
r
o
s
s
E
n
t
r
o
p
y
(
Y
,
Y
^
p
r
e
d
g
)
\begin{aligned}L&=(\sum_{i=1}^6\boldsymbol{\alpha}_iL_{output}^i(W,w^i))+\boldsymbol{\beta}CrossEntropy(Y,\hat{Y}_{pred}^l)\\&+\boldsymbol{\gamma}CrossEntropy(Y,\hat{Y}_{pred}^g)\end{aligned}
L=(i=1∑6αiLoutputi(W,wi))+βCrossEntropy(Y,Y^predl)+γCrossEntropy(Y,Y^predg)
其中:
δ
=
∣
Y
−
∣
/
∣
Y
+
∣
\boldsymbol{\delta}=|Y^-|/|Y^+|
δ=∣Y−∣/∣Y+∣
Y
+
和
Y
−
分别表示边缘像素和非边缘像素
Y^+ 和 Y^- 分别表示边缘像素和非边缘像素
Y+和Y−分别表示边缘像素和非边缘像素
f
(
y
j
=
1
∣
X
;
W
,
w
i
)
=
s
i
g
m
o
i
d
(
a
j
i
)
f(y_{j}=1|X;W,w^{i})=sigmoid(a_j^i)
f(yj=1∣X;W,wi)=sigmoid(aji)
Y
^
p
r
e
d
l
和
Y
^
p
r
e
d
g
分别表示局部结构感知和全局结构感知的预测输出,
α
,
β
和
γ
是我们用来调整权重的超参数。
\hat{Y}_{pred}^l 和 \hat{Y}_{pred}^g 分别表示局部结构感知和全局结构感知的预测输出,α, β和γ是我们用来调整权重的超参数。
Y^predl和Y^predg分别表示局部结构感知和全局结构感知的预测输出,α,β和γ是我们用来调整权重的超参数。
B.Multi-task Distillation and Hierarchical Localization(多任务蒸馏和分层定位)
分层定位(Hierarchical Localization)的大部分时间都花在了特征提取上,对此,为了在保持模型定位精度的同时大幅提高定位速度,我们采用了基于dexine和HFNet的结构感知多任务蒸馏相结合的方案。多任务蒸馏通过信息共享来识别多个目标,提高了效率,而结构感知约束提高了预测精度。
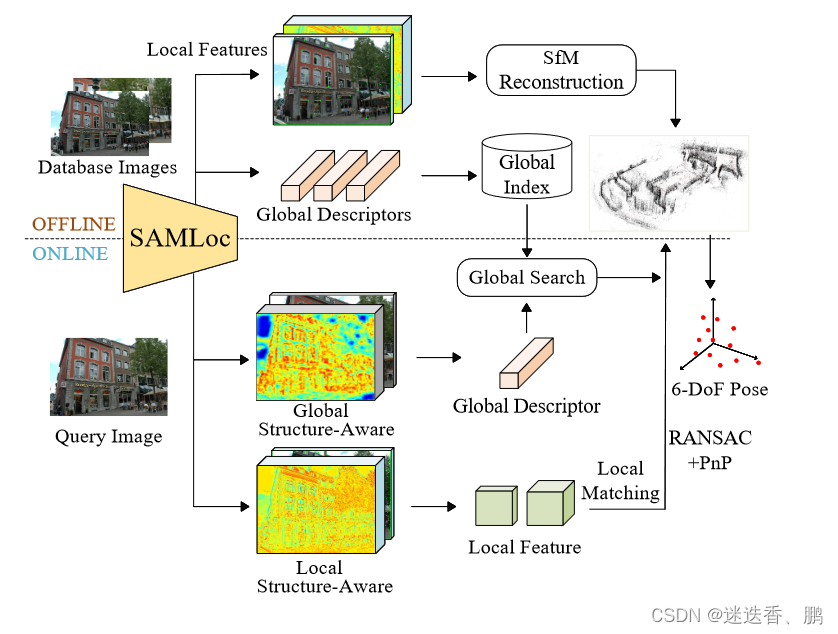
分层定位方法分为离线地图构建和在线视觉定位两部分。
首先,通过SAMLoc的方法提取局部和全局特征,sfm 是通过得到的局部特征,线下构建地图。同时,数据库图像的全局描述符(the global descriptors)被构建到全局索引(global index)中。
然后在输入查询图像(query image)时,通过结构感知模块(structureaware module)获得全局特征(global features)和局部特征(local feature)。我们通过使用KNN (k -最近邻)和数据库索引匹配来使用全局特征进行粗匹配。然后利用获得的局部特征和SfM地图,通过RANSAC 和PnP方法进行2D-3D匹配。最终,得到了6DoF姿态。
编码器(encoder) 使用MobilenetV3-Large 作为骨干网络,我们分别使用Superpoint 和NetVLAD 作为局部特征和全局特征 teacher models,如下图:
Superpoint设计了一种自监督网络模型,通过编码和解码同时提取像素级精确的特征点和描述符,并设计了一种增强重复提取特征点的策略——同形自适应,其泛化效果良好。NetVLAD在图像检索领域有着广泛的应用,它以卷积神经网络作为基本特征提取结构,通过NetVLAD层输出全局描述子,在图像检索方面具有很大的优势。但是,它有大量的参数和计算损耗。
局部特征提取模块位于Mobilenet的第7层,而全局特征提取模块位于Mobilenet的第18层。我们还在网络的第4层和第11层添加了局部和全局结构感知约束(structure-aware constraints),并保持骨干网络的结构不变,从而最大限度地提高了特征提取的速度。
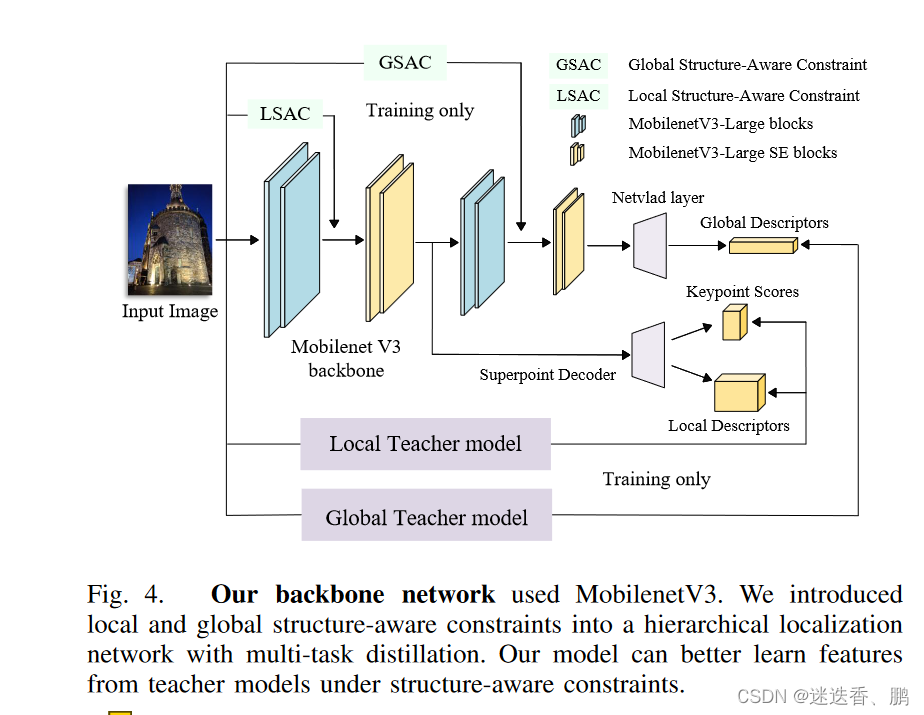
我们将结构感知和多任务蒸馏的损失函数分为局部损失和全局损失。
L
l
o
c
a
l
=
e
w
1
∥
d
s
l
−
d
t
1
l
∥
2
2
+
e
w
2
e
w
1
+
e
w
3
∥
s
s
l
−
s
t
1
l
∥
2
2
+
e
w
3
C
r
o
s
s
E
n
t
r
o
p
y
(
k
s
,
k
t
3
)
L
g
l
o
b
a
l
=
e
w
4
∥
d
s
g
−
d
t
1
g
∥
2
2
+
e
w
5
e
w
1
+
e
w
3
+
e
w
4
∥
s
s
g
−
s
t
1
g
∥
2
2
L
=
L
l
o
c
a
l
+
L
g
l
o
b
a
l
+
∑
i
n
w
i
\begin{gathered} L_{\mathrm{local}}= e^{w_1}\left\|d_s^l-d_{t_1}^l\right\|_2^2+\frac{e^{w_2}}{\sqrt{e^{w_1}+e^{w_3}}}\left\|s_s^l-s_{t_1}^l\right\|_2^2 \\ +e^{w_3}CrossEntropy\left(k_s,k_{t_3}\right) \\ L_{\mathrm{global~}}=e^{w_4}\left\|d_s^g-d_{t_1}^g\right\|_2^2+\frac{e^{w_5}}{\sqrt{e^{w_1}+e^{w_3}+e^{w_4}}}\left\|s_s^g-s_{t_1}^g\right\|_2^2\\L=L_{\mathrm{local~}}+L_{\mathrm{global~}}+\sum_{i}^nw_i\end{gathered}
Llocal=ew1
dsl−dt1l
22+ew1+ew3ew2
ssl−st1l
22+ew3CrossEntropy(ks,kt3)Lglobal =ew4
dsg−dt1g
22+ew1+ew3+ew4ew5
ssg−st1g
22L=Llocal +Lglobal +i∑nwi
使用的数据集和性能度量
Active Search (AS)
City Scale Localization (CSL)
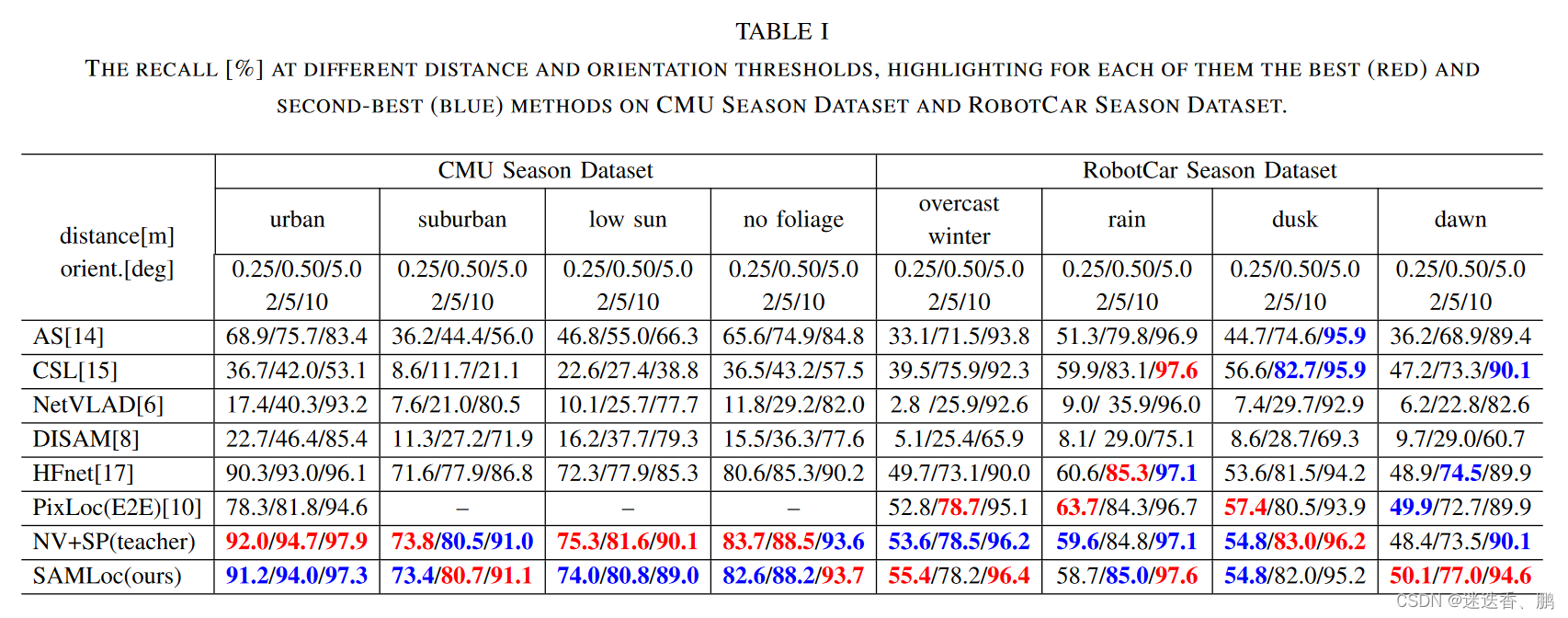
不同距离和方向阈值下的召回率[%]下的比较
a.在不同季节和天气变化以及不同场景的对比结果
the CMU Season dataset 和 the RobotCar Season dataset
可视化结果:

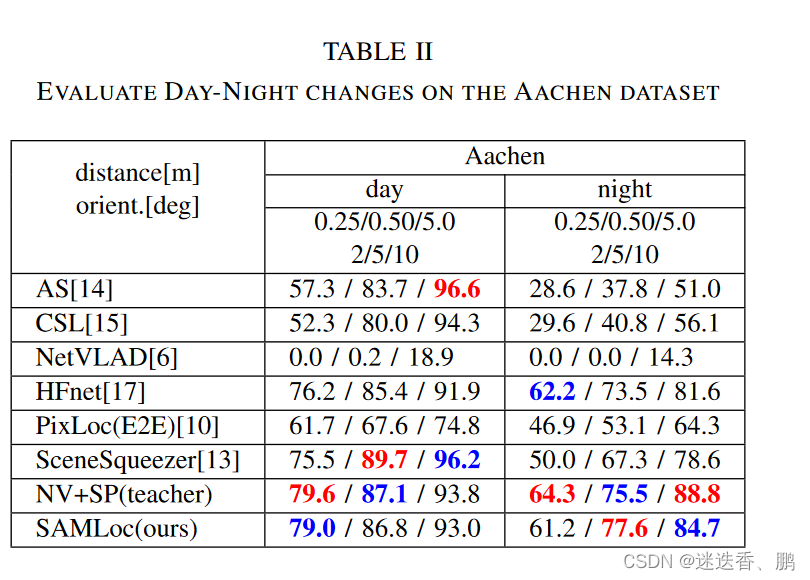
b.昼夜变化的实验
Aachen Day-Night dataset
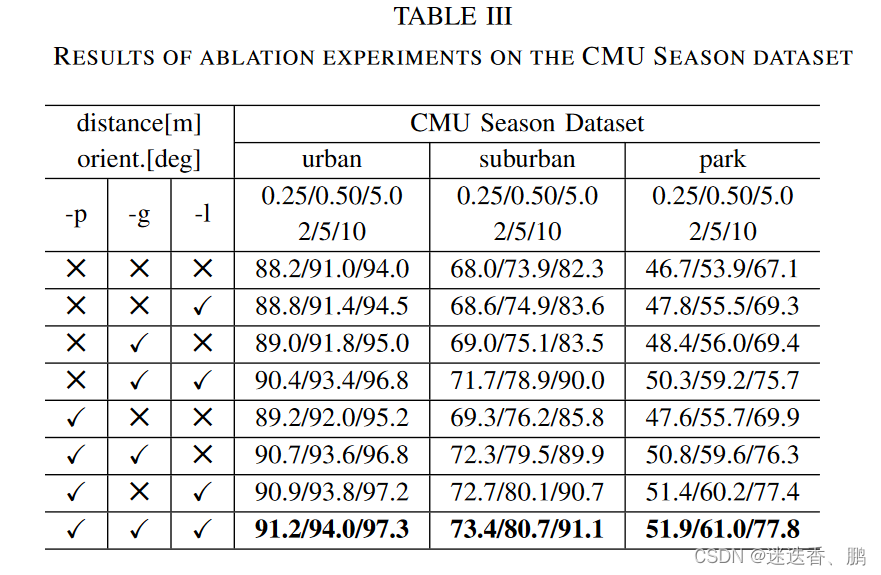
c.评估结构感知模块和预训练模型的影响
the CMU dataset
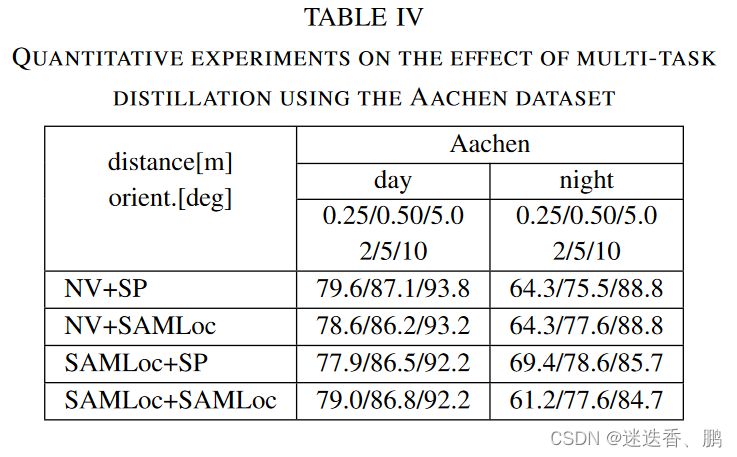
d.多任务蒸馏的定量评价
the Aachen dataset
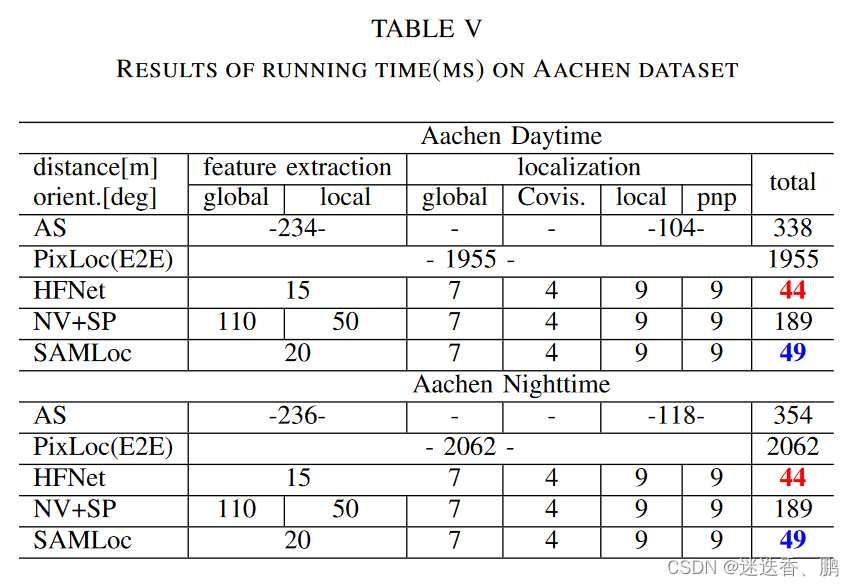
f.运行时时间评估
the Aachen dataset















 2499
2499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









