







 超级会员免费看
超级会员免费看

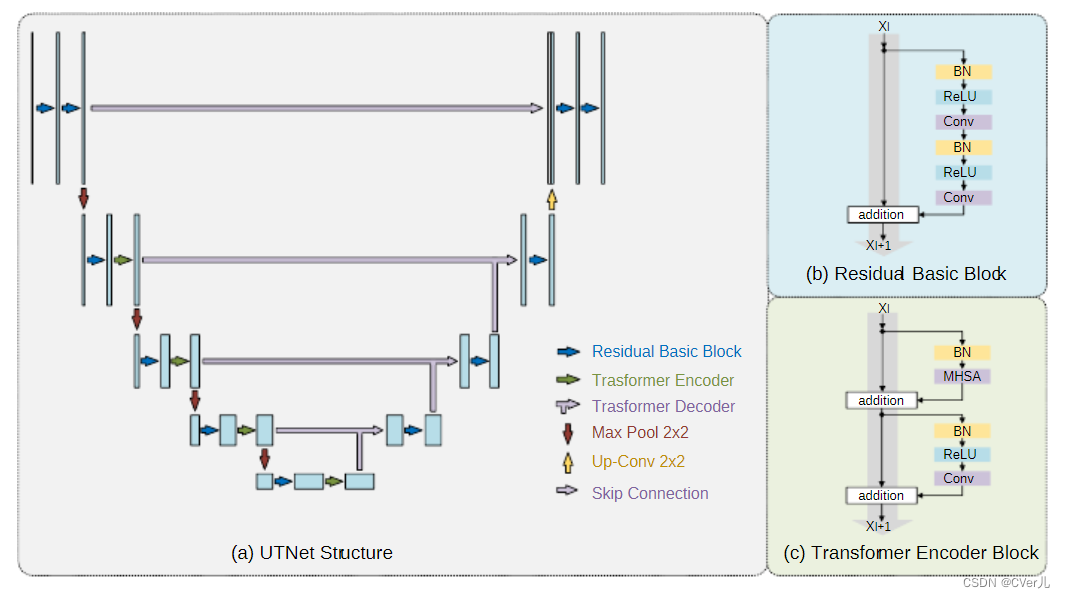
 UTNet是一种将Transformer的self-attention与CNN相结合的混合架构,用于提升医学图像分割的性能。它引入了高效自注意力机制,降低了计算复杂度,并结合相对位置编码以捕获全局依赖。UTNet在小规模数据集上表现优秀,无需预训练,尤其适用于细节丰富的医学图像分割任务。
UTNet是一种将Transformer的self-attention与CNN相结合的混合架构,用于提升医学图像分割的性能。它引入了高效自注意力机制,降低了计算复杂度,并结合相对位置编码以捕获全局依赖。UTNet在小规模数据集上表现优秀,无需预训练,尤其适用于细节丰富的医学图像分割任务。
原文link
Abstract
Transformer已被广泛用于NLP领域的诸多任务,但是将Transformer应用于图像领域还有很大的探索空间。本文提出一种简洁高效的混合Transformer框架-UTNet,将self-attention与CNN结合在一起用于提升医学图像分割的性能。
UTNet在encoder和decoder部分均引入了self-attention模块,以最小的开销捕获不同尺度的长程依赖关系。
为此,本文提出了一种有效的结合了相对位置信息编码的自注意力机制,可以将自注意力的时间复杂度从O(n^2)降到O(n);并提出了一种新的自注意力解码器,可以从skip connection中恢复encoder中的细粒度特征。
本文的意义在于解决了目前Transformer应用的困境:即需要从大量的训练数据中学习归纳偏执。UTNet中的混合层(

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1222
1222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









