







 本文详细介绍了混合精度训练中使用FP16的优势,包括减少显存和加速训练。然而,FP16可能导致精度下降,主要因上溢出和舍入误差。文章提出了损失缩放和FP32权重备份的解决方案,确保模型在保持精度的同时有效利用FP16进行训练。
本文详细介绍了混合精度训练中使用FP16的优势,包括减少显存和加速训练。然而,FP16可能导致精度下降,主要因上溢出和舍入误差。文章提出了损失缩放和FP32权重备份的解决方案,确保模型在保持精度的同时有效利用FP16进行训练。
为什么要用 FP16
如果我们在训练过程中将 FP32 替代为 FP16,有以下两个好处:
1. 减少显存占用:FP16 的显存占用只有 FP32 的一半,这使得我们可以用更大的 batch size;
2. 加速训练:使用 FP16,模型的训练速度几乎可以提升 1 倍。
2.3 为什么只用 FP16 会有问题
如果我们简单地把模型权重和输入从 FP32 转化成 FP16,虽然速度可以翻倍,但是模型的精度会被严重影响。原因如下:
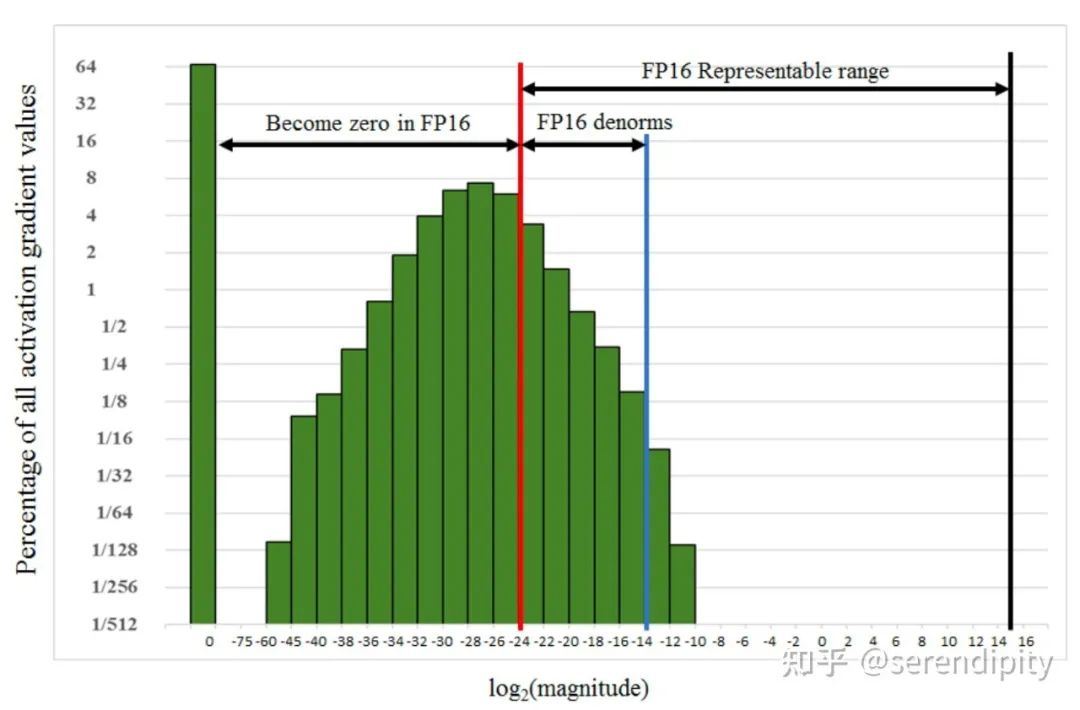
上/下溢出:FP16 的表示范围不大,超过 的数字会上溢出变成 inf,小于 的数字会下溢出变成 0。下溢出更加常见,因为在网络训练的后期,模型的梯度往往很小,甚至会小于 FP16 的下限 ,此时梯度值就会变成 0,模型参数无法更新。下图为 SSD 网络在训练过程中的梯度统计,有 67% 的值下溢出变成 0。
舍入误差:就算梯度不会上/下溢出,如果梯度值和模型的参数值相差太远,也会发生舍入误差的问题。假设模型参数 weight ,学习率 ,梯度 gradient ,weight weight gradient 。
2.4 解决方案
损失缩放 (Loss Scaling)
为了解决下溢出的问题,论文中对计算出来的 loss 值进行缩放 (scale),由于链式法则的存在,对 loss 的缩放会作用在每个梯度上。缩放后的梯度,就会平移到 FP16 的有效范围内。这样就可以用 FP16 存储梯度而又不会溢出了。此外,在进行更新之前,需要先将缩放后的梯度转化为 FP32,再将梯度反缩放 (unscale) 回去。
注意这里一定要先转成 FP32,不然 unscale 的时候还是会下溢出。
缩放因子 (loss_scale) 一般都是框架自动确定的,只要没有发生 inf 或者 nan,loss_scale 越大越好。因为随着训练的进行,网络的梯度会越来越小,更大的 loss_scale 可以更加充分地利用 FP16 的表示范围。
FP32 权重备份
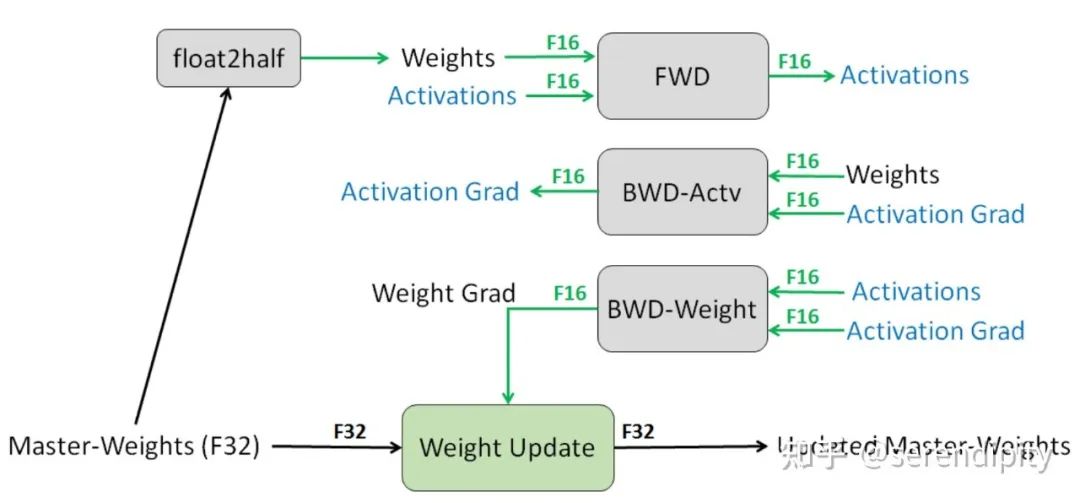
为了实现 FP16 的训练,我们需要把模型权重和输入数据都转成 FP16,反向传播的时候就会得到 FP16 的梯度。如果此时直接进行更新,因为梯度 * 学习率的值往往较小,和模型权重的差距会很大,可能会出现舍入误差的问题。
所以解决思路是:将模型权重、激活值、梯度等数据用 FP16 来存储,同时维护一份 FP32 的模型权重副本用于更新。在反向传播得到 FP16 的梯度以后,将其转化成 FP32 并 unscale,最后更新 FP32 的模型权重。因为整个更新过程是在 FP32 的环境中进行的,所以不会出现舍入误差。
FP32 权重备份解决了反向传播的舍入误差问题。


















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











