







RT-Thread软件定时器用跳表判断超时的机制
RT-Thread 是一个广泛使用的嵌入式实时操作系统。其中的 timer 定时器可以用来在特定的时间间隔后执行特定的任务。下面我将简要介绍RT-Thread定时器的超时机制和如何在代码中实现它。
RT-Thread的定时器超时机制是通过系统的定时器服务来实现的。你可以通过
rt_timer_create来创建一个定时器,然后通过rt_timer_start来启动定时器。当定时器到达设定的超时时间时,它会自动调用预先设置的超时函数。
下面是一个简单的RT-Thread定时器创建和启动的示例代码:
#include <rtthread.h>
/* 定时器的超时函数 */
static void timeout(void *parameter)
{
rt_kprintf("timer timeout\n");
}
int timer_sample(void)
{
/* 定时器控制块 */
static rt_timer_t timer1;
/* 创建定时器 */
timer1 = rt_timer_create("timer1", /* 定时器名字 */
timeout, /* 超时时回调的函数 */
RT_NULL, /* 超时函数的入口参数 */
RT_TICK_PER_SECOND, /* 定时长度为1秒,即1000ms */
RT_TIMER_FLAG_PERIODIC); /* 定时器标志:周期性定时器 */
/* 启动定时器 */
if (timer1 != RT_NULL)
rt_timer_start(timer1);
return 0;
}
/* 导出到 msh 命令列表中 */
MSH_CMD_EXPORT(timer_sample, timer sample);
代码解析:
-
首先我们包含 rtthread.h 头文件,以便我们可以使用RT-Thread的API。
-
我们创建一个超时函数
timeout,当定时器超时时它会被调用。 -
在
timer_sample函数中,我们首先声明一个rt_timer_t类型的变量来存储定时器的控制块。 -
使用
rt_timer_create函数来创建一个定时器。我们为定时器指定一个名字,一个超时函数,超时函数的参数,超时时间(以系统时钟滴答为单位),和定时器的标志。 -
然后我们检查定时器是否创建成功,如果是,则使用
rt_timer_start函数来启动定时器。 -
最后,我们使用
MSH_CMD_EXPORT宏将timer_sample函数导出到MSH(Micro Shell)命令列表中,这样你就可以在RT-Thread的shell中运行此命令来测试定时器。
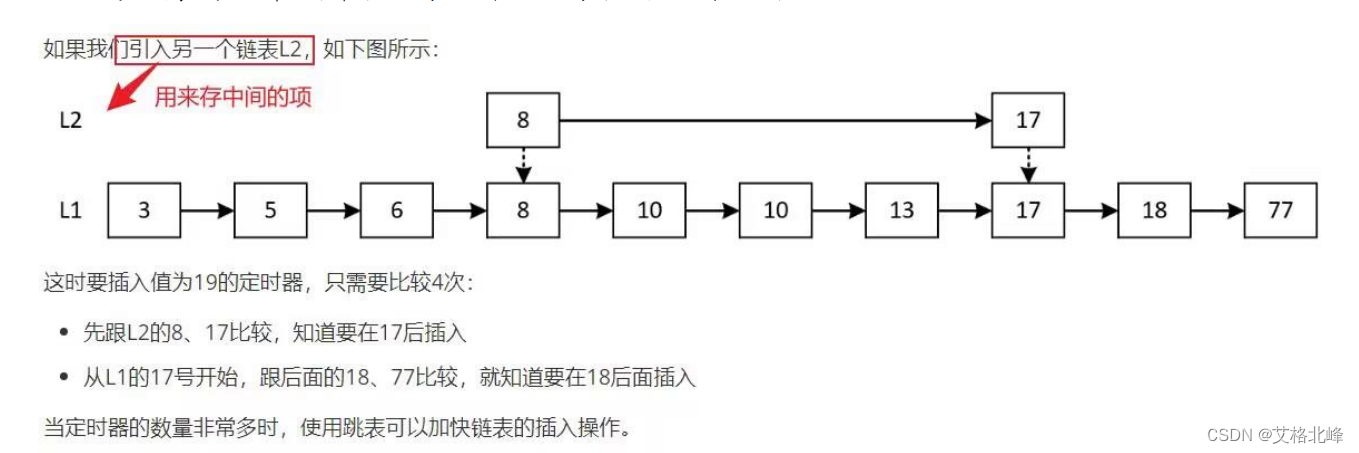
在 RT-Thread 操作系统中,定时器的超时判断和处理是一个核心功能。定时器超时机制主要依赖于系统时钟滴答(系统 tick)来追踪时间。每当时钟滴答发生时,RTOS 会更新所有活动定时器的内部计数器,并检查是否有任何定时器已超时。
RT-Thread 使用一种称为“跳表”(Skip List)的数据结构来管理和检测定时器的超时。这是一种随机化的数据结构,能够提供对数级别的搜索时间复杂度,同时也允许快速的插入和删除操作。
下面简要介绍一下跳表算法及其在定时器超时检测中的应用:
跳表简介
跳表是一个随机化的数据结构,由多个有序链表组成,可以提供对数时间复杂度的搜索、插入和删除操作。它是一种可以用来代替平衡树的数据结构。
跳表在 RT-Thread 定时器中的应用
在 RT-Thread 中,定时器对象会被插入到一个跳表中。这个跳表根据定时器的超时时间来排序定时器对象。每一个定时器对象都有一个超时时刻(timeout tick)。
下面我们详细讨论 RT-Thread 定时器如何使用跳表来检测超时:
-
插入操作
当创建并启动一个新的定时器时,它会被插入到跳表中的适当位置,以保持跳表的有序性。
-
超时检测
在每一个系统时钟滴答(系统 tick)中断服务例程(ISR)中,RTOS 会更新所有活动定时器的内部计数器。同时,它会检查跳表中的第一个定时器是否已经超时。如果第一个定时器已经超时,它将被从跳表中移除,并且其超时回调函数将被调用。这个过程将继续,直到找到一个还没有超时的定时器。
-
定时器停止或删除
当停止或删除一个定时器时,它将从跳表中被删除。
通过使用跳表,RT-Thread 能够以非常高效的方式管理和检测多个定时器的超时,这是嵌入式实时系统中一个非常重要的功能。
在 RT-Thread 操作系统中,定时器管理是一个核心功能,而跳表(Skip List)是一个能够高效管理定时器的数据结构。下面我们将详细探讨 RT-Thread 的源代码中跳表如何用于定时器的超时检测和管理。
首先,你会在 src/timer.c 文件中找到跳表的数据结构定义和相关的定时器管理函数。跳表的数据结构通常如下所示:
struct rt_timer_skip_list_level
{
struct rt_timer *head;
};
struct rt_timer_skip_list
{
struct rt_timer_skip_list_level level[RT_TIMER_SKIP_LIST_LEVEL];
};
在 RT-Thread 中, 一个具体的跳表节点被定义为:
struct rt_timer
{
/* 用于链表的节点 */
struct rt_list_node list;
/* 定时器的状态 */
rt_uint8_t status;
/* 定时器超时值和初始超时值 */
rt_tick_t init_tick;
rt_tick_t timeout_tick;
/* 定时器的超时函数及其参数 */
void (*timeout_func)(void *parameter);
void *parameter;
/* ...其他字段 */
};
接下来,我们看如何通过跳表来检测定时器的超时:
1. 定时器的插入
在定时器启动时,它会被插入到跳表中。RT-Thread 在插入定时器时会确定其在跳表中的正确位置,使得定时器按其 timeout_tick 保持排序。插入操作的实现可能看起来像这样:
void rt_timer_insert(struct rt_timer *timer)
{
int i, level;
struct rt_timer *prev, *cur;
/* ... */
/* 从顶层开始,找到每一层的插入位置 */
for (i = RT_TIMER_SKIP_LIST_LEVEL - 1; i >= 0; i--)
{
/* ... 找到当前层的插入位置 */
/* 插入当前定时器 */
timer->list[i].next = prev->list[i].next;
prev->list[i].next = &timer->list[i];
}
/* ... */
}
2. 定时器的超时检测
在每个系统 tick 时,都会调用一个函数来检查是否有任何定时器超时。它会从跳表的最底层开始检查第一个节点,如果该定时器的 timeout_tick 小于或等于当前的系统 tick,则该定时器超时,并将调用其超时函数。检查超时的函数可能如下:
void rt_timer_check(void)
{
struct rt_timer *timer;
/* 获取当前的系统 tick */
rt_tick_t current_tick = rt_tick_get();
/* 取出跳表最底层的第一个定时器 */
timer = rt_timer_skip_list_first();
while (timer && timer->timeout_tick <= current_tick)
{
/* 从跳表中移除该定时器 */
rt_timer_remove(timer);
/* 调用定时器的超时函数 */
timer->timeout_func(timer->parameter);
/* 再次取出跳表最底层的第一个定时器 */
timer = rt_timer_skip_list_first();
}
}
注意:在实际源代码中,它会有更多的错误检查和优化以保证效率和稳定性。
RT-Thread 使用了跳表(skip list)数据结构来管理软件定时器(timer),确保插入、删除和查找操作具有更低的时间复杂度。在深入了解 RT-Thread 定时器的实现前,我们先简单了解一下跳表的概念和特点。
跳表是一个随机化的数据结构,用于取代平衡树。通过以概率方式保持元素的层次结构,跳表能够提供近似平衡树的搜索效率,而插入和删除操作通常更为简单高效。理论上,跳表的查找、插入、删除操作的时间复杂度均为 O(log N)。
在 RT-Thread 中,软件定时器的实现可以在 rt_timer.c 文件中找到。以下是基于跳表实现软件定时器的基本原理和源代码解析:
1. 跳表数据结构定义
首先,我们来看一下跳表节点和跳表数据结构的定义:
#define RT_TIMER_SKIP_LIST_LEVEL 0x10
struct rt_timer
{
/* run-list */
struct rt_list_node row[RT_TIMER_SKIP_LIST_LEVEL];
/* ...省略其他结构体成员... */
};
struct rt_timer_table
{
/* ...省略其他结构体成员... */
/* timer skip list */
struct rt_timer skip_list[RT_TIMER_SKIP_LIST_LEVEL];
};
在这里,rt_timer 结构体中的 row 数组用于存放跳表节点,而 rt_timer_table 结构体中的 skip_list 数组用于存放跳表头信息。
2. 软件定时器插入过程
软件定时器插入跳表的过程主要涉及到以下函数:
void rt_timer_init(void)rt_err_t rt_timer_start(rt_timer_t timer)static void _rt_timer_insert(rt_timer_t timer)
让我们详细探讨一下 _rt_timer_insert 函数的实现和它如何将一个定时器插入到跳表中。
在 RT-Thread 操作系统中,定时器对象(rt_timer_t 类型)在插入时会按照其超时时刻(timeout_tick)进行排序插入到跳表中,确保第一个定时器就是最快要超时的定时器。现在让我们更深入地看一下 _rt_timer_insert 函数的实现:
static void _rt_timer_insert(rt_timer_t timer)
{
int i;
struct rt_list_node *list = RT_NULL, *prev = RT_NULL;
rt_tick_t value;
/* ...省略其他代码... */
/* insert timer to skip list */
value = timer->timeout_tick;
for (i = RT_TIMER_SKIP_LIST_LEVEL - 1; i >= 0; i--)
{
list = &rt_timer_skip_list[i];
prev = list;
for (; list->next != list; list = list->next)
{
rt_timer_t t;
t = rt_list_entry(list->next, struct rt_timer, row[i]);
if (t->timeout_tick > value)
{
break;
}
prev = list->next;
}
/* insert timer, only insert level 0 */
rt_list_insert_after(prev, &timer->row[i]);
if (i == 0) break;
}
/* ...省略其他代码... */
}
在函数中:
-
我们首先获得定时器的
timeout_tick值,这是定时器预定超时的时刻。 -
通过一个外层循环,我们从跳表的最高层开始查找,直到到达层0。在每一层,我们都从头开始遍历,寻找合适的插入位置。
-
对于每一层,我们都使用一个内层循环来查找插入点。我们通过比较当前节点的
timeout_tick值和定时器的timeout_tick值来找到合适的插入位置。如果当前节点的timeout_tick值大于定时器的timeout_tick值,我们就找到了插入点。我们保持prev指针总是指向我们已经访问过的最后一个节点。 -
找到插入点后,我们在
prev指针和它的下一个节点之间插入新的定时器。 -
我们重复这个过程,直到我们为定时器找到在所有层的位置。注意,虽然我们为定时器找到了所有层的位置,但我们实际上只在0层插入它。这是因为跳表的其他层是用来加速查找的,而所有的节点都必须出现在0层。

通过这种方式,跳表允许我们在 O(log N) 时间复杂度内插入新的定时器,而不是简单链表的 O(N) 复杂度,这大大提高了插入操作的效率,特别是在有大量定时器的情况下。
3. 定时器超时检查
在系统时钟中断服务程序中会调用 void rt_timer_check(void) 函数来检查是否有定时器超时,代码如下:
void rt_timer_check(void)
{
struct rt_list_node *list;
rt_timer_t t;
rt_base_t level;
/* ...省略其他代码... */
/* disable interrupt */
level = rt_hw_interrupt_disable();
for (list = rt_timer_skip_list[0].next; list != &rt_timer_skip_list[0];)
{
t = rt_list_entry(list, struct rt_timer, row[0]);
/* remove timer */
if (t->timeout_tick > rt_tick_get())
{
break;
}
/* move list pointer to next */
list = list->next;
/* remove timer from list */
_rt_timer_remove(t);
/* ... 省略其他代码 ... */
}
/* enable interrupt */
rt_hw_interrupt_enable(level);
/* ... 省略其他代码 ... */
}
在 rt_timer_check() 函数中,我们只检查跳表最底层(0层)的超时定时器。如果找到超时的定时器,我们将其从跳表中移除,并根据定时器的配置执行相应的回调函数。
跳表降低时间复杂度的方式
利用跳表可以降低时间复杂度的主要方式是通过空间换时间的策略来减少检查定时器超时所需的比较次数。在跳表中,高层链表中的节点是底层链表节点的一个子集,这意味着我们可以快速跳过多个节点,从而减少搜索时间。这使得我们可以在O(log N)时间复杂度内完成定时器的插入、删除和查找操作,而不是传统链表的O(N)时间复杂度。
















 709
709











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











