







NLP进阶之(二)Chatbot评估指标
1. 基于检索模型
在这篇文章中,我们将实现一个基于检索的机器人。基于检索的模型具有可以使用的预定义响应的存储库,这与生成模型不同,后者可以生成他们以前从未见过的响应。更正式地说,基于检索的模型的输入是一个上下文C(到目前为止的对话)和一个潜在的响应[R。模型输出是响应的分数。要找到一个好的回答,您将计算多个回答的得分,并选择得分最高的回答。
但是,如果可以构建生成模型,为什么还要构建基于检索的模型呢?生成模型似乎更灵活,因为它们不需要预定义响应的存储库,对吧?
问题是生成模型在实践中不能很好地工作。至少还没有。因为他们在如何应对方面拥有如此多的自由,因此生成模型往往会产生语法错误并产生不相关的,通用的或不一致的反应。他们还需要大量的培训数据,难以优化。今天绝大多数生产系统都是基于检索的,或者是基于检索和生成的组合。谷歌的智能回复就是一个很好的例子。生成模型是一个活跃的研究领域,但我们尚未完全实现。如果你想今天建立一个会话代理,你最好的选择很可能是一个基于检索的模型。
问题输入:“现在”、“我”、“在”、“努力学习”、“英文”、“,”、“我”、“想”、“成为”、“一名”、“翻译”、“。”
回输出:“嗯”、“,”、“你”、“是”、“大有”、“前途”、“的”、“。”、“追逐”、“你”、“的”、“梦想”、“,”、“永不”、“放弃”、“。”
1.1 Ubuntu对话语料库
在这篇文章中,我们将使用Ubuntu Dialog Corpus 文章及代码,Ubuntu Dialog Corpus(UDC)是可用的最大公共对话数据集之一。它基于公共IRC网络上Ubuntu频道的聊天记录,数据下载地址。
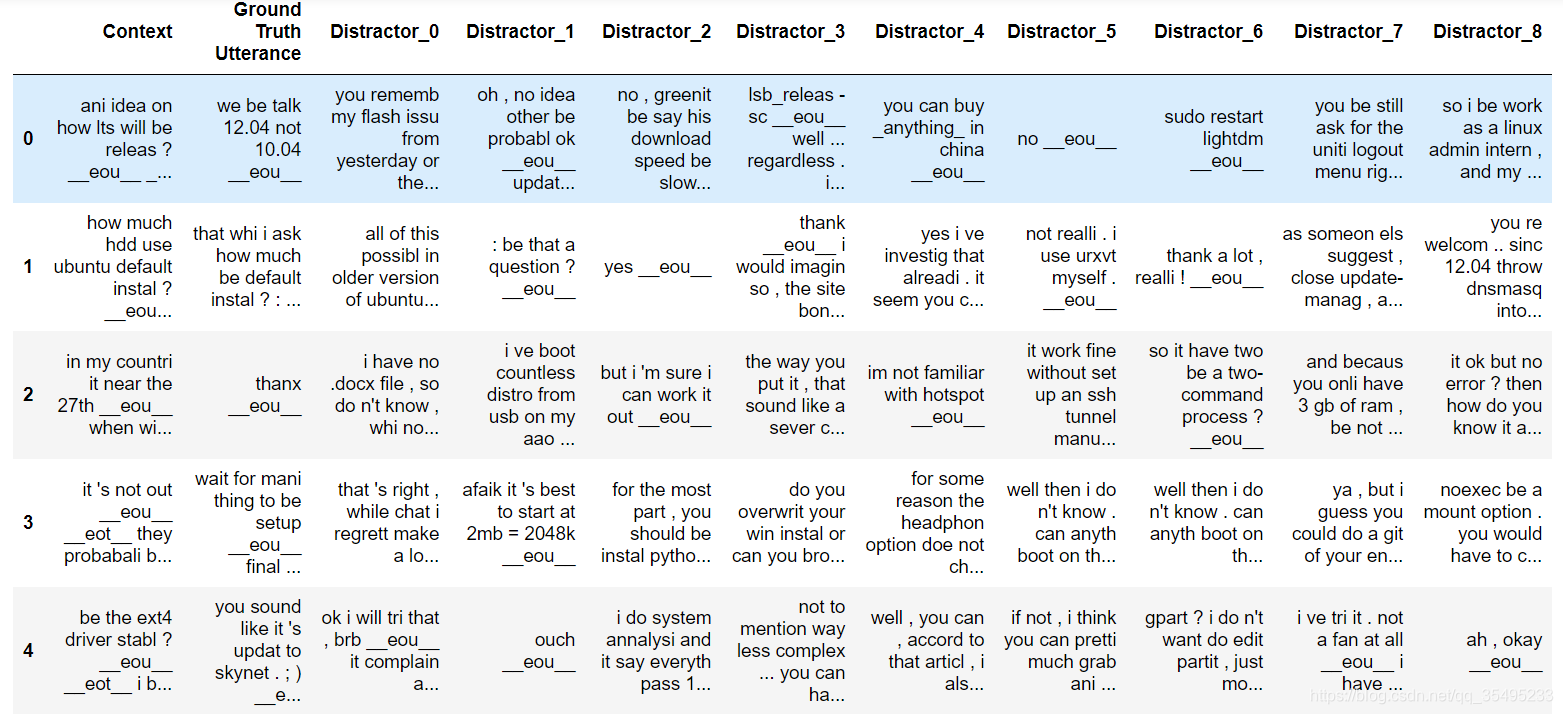
培训数据包括1,000,000个例子,50%正样本(标签1)和50%负样本(标签0)。每个例子都包含一个上下文,到此为止的对话,一个话语,一个对上下文的回应。正面标签意味着话语是对上下文的实际响应,负面标签意味着话语不是 - 它是从语料库中的某个地方随机选取的。这是一些示例数据。
需要注意的是数据集生成脚本已经做了一堆预处理对我们的-它已经经过NLTK处理。该脚本还使用特殊标记替换了名称,位置,组织,URL和系统路径等实体。这种预处理并不是绝对必要的,但它可能会将性能提高几个百分点。平均上下文长86个字,平均话语长17个字。查看Jupyter笔记本以查看数据分析。
对train.csv数据进行head(),后可以得到:

对valid.csv数据进行head(),后可以得到:
对train.csv数据进行describe(),后可以得到:

对valid.csv数据进行describe(),后可以得到:

使用文章所描述模型:
1.2 Baseline评估指标
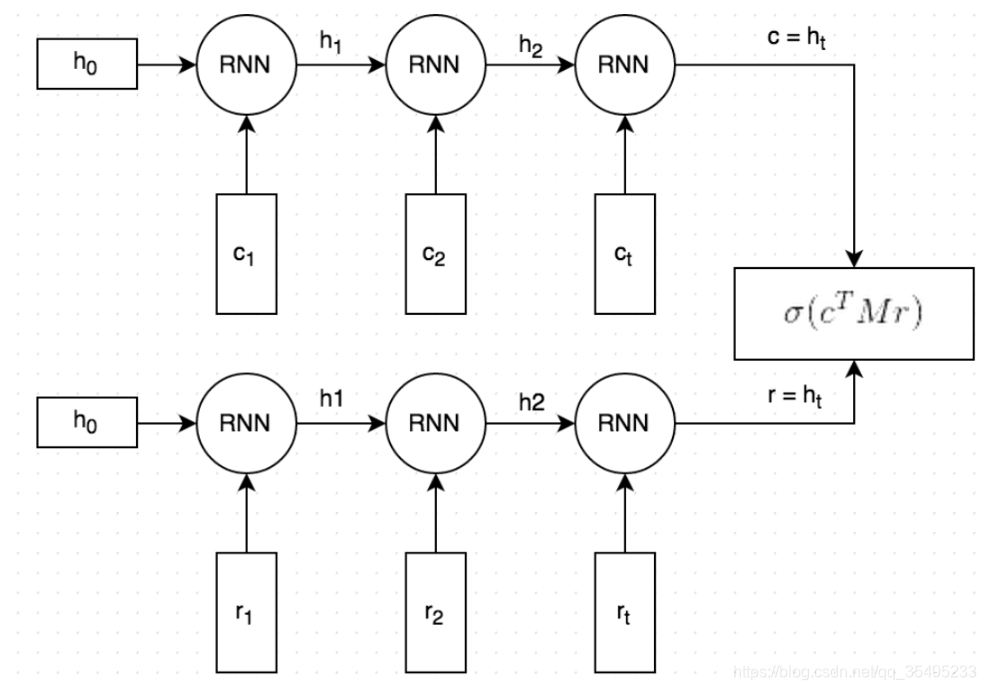
编码器的作用是把一个不定长的输入序列变换成一个定长的背景变量 c \boldsymbol{c} c,并在该背景变量中编码输入序列信息。常用的编码器是循环神经网络。
让我们考虑批量大小为 1 的时序数据样本。假设输入序列是 x 1 , … , x T x_1,\ldots,x_T x1,…,xT,例如 x i x_i xi 是输入句子中的第 i i i 个词。在时间步 t t t,循环神经网络将输入 x t x_t xt 的特征向量 x t \boldsymbol{x}_t xt 和上个时间步的隐藏状态 h t − 1 \boldsymbol{h}_{t-1} ht−1 变换为当前时间步的隐藏状态 h t \boldsymbol{h}_t ht。我们可以用函数 f f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1705
1705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









