







Deep Learning Based Registration文章阅读(九)
本次文章是一篇arXiv上的短文《ViT-V-Net: Vision Transformer for Unsupervised Volumetric Medical Image Registration》,首次把Transformer用于3D医学图像配准中。Transformer作为NLP领域目前大放异彩的结构,自2020年10月被首次用到cv分类任务中后,现在在cv各个任务中,包括细粒度分类,目标检测,分割等都取得了比CNN更好的的结果。这篇文章首次将Transformer用于医学图像配准,代码的改动较小,且由于配准是一个Dense prediction的任务,而Transformer经过连续的下采样后,强调low-resolution的特征,这对于配准并不友好,所以这篇文章使用Transformer的Encoder结合CNN以及U-net结构,保证Dense prediction的flow field的生成。笔者的理解,这篇文章使用Transformer的Encoder来在CNN提取的高维特征再做一个embedding,然后再经过U-net的Decoder恢复feature size生成flow field。其中TransformerEncoder因为Self-attention的机制,可以建立patch间更大范围的联系,即不会像CNN一样由于kernel size的大小而限制感受野,这对于运动较大图像的配准具有重要意义。
Motivation
如前所述,Transformer在CV领域的细粒度分类、检测、分割等任务中均取得sota,自然的想法能否将Transformer用于配准中。但是Transformer经过连续的下采样强调的是low-resolution的特征,但是配准是Dense prediction的任务,所以需要结合CNN来恢复high-resolution的feature(flow field)。本文仍旧采取U-net的结构,在Encoder的最后一层的CNN提取的feature后使用Transformer的Encoder,利用self-attention捕获long range relation的能力,来进行一次embedding,然后再通过U-net的CNN的Decoder实现feature size的恢复,从而生成flow field。
Framework
图一是framework,需要特别提到的有两个地方,一个是橙色部分的Transformer,具体结构如图3所示;另一个是在conv或者upconv block中用到了instance normalization, 与batch normalization不同,instance normalization是在单张图像上做归一化,以2D图像为例,BN是在NHW维度上做归一化,而IN是在HW维度上做归一化。
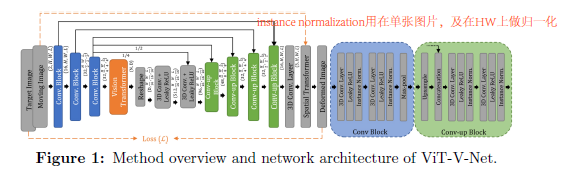
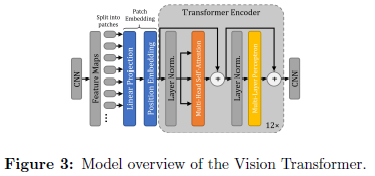
Transformer的结构如下图所示:
1、类比NLP中的word, 将图片划分为patch,然后将patch做embedding,与维度相同的position embedding直接相加。
2、然后送入Layer normalization,前面提到了BN和IN,这里又说了LN,LN是在CHW维度上做归一化。
3、MSA机制相比于SSA机制,采用多个Q,K,V,产生多个output向量Z,然后再经过一个LP(乘一个矩阵)恢复为一个head的输出尺寸,然后进入下一层的MLP(在Transformer的2017文章中是一个FC,更概括性的名称是叫做前馈网络)
4、MSA和MLP都设计为一个与ResNet类似的残差输出。本文中用到的Tranformer的Encoder是12层,即有12个MSA和MLP。
输出的embedding Z比input的feature patch的embedding尺寸会小。
这里附一个Transfome讲解r比较好的博客The Illustrated Transformer
Loss
loss就是最基本的loss
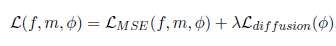

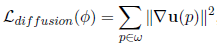
Dataset
In-house dataset not released:260 T1-weighted brain MRI scans。
Preprocess:affine registration,resampling using FreeSurfer; 29 anatomical structures were obtained using FreeSurfer for evaluation
Results
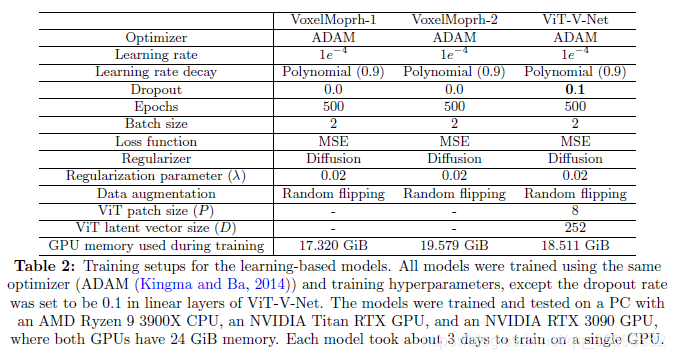
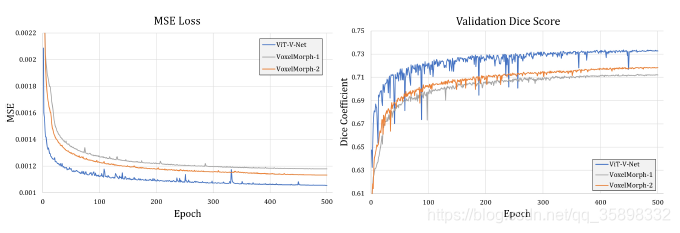
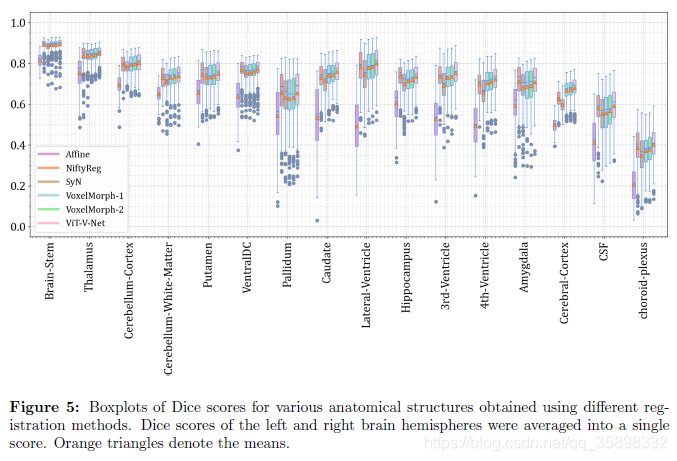
结果都很好理解,VoxelMorph-1和-2的不同是原始VoxelMorph文章中提到的最后U-net Decoder的最后三层upconv的channel数不同。不是代表loss中平滑正则项的系数,也不是代表微分同胚改进的VoxelMorph。




















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









