







V2VNet: Vehicle-to-Vehicle Communication for Joint Perception and Prediction
文章目录
背景
一些研究提出联合执行感知和运动预测的方法,称为感知和预测(P&P),在计算效率上比经典的两步流程更高的同时进一步提高了准确性
在本文中,我们考虑车对车(V2V)通信设置,其中每辆车可以向 / 从附近车辆(在 70 米半径内)广播和接收信息。请注意,根据现有通信协议 [21],这个广播范围是合理的
[21]Kenney, J.B.: Dedicated short-range communications (dsrc) standards in the united states. Proceedings of the IEEE (2011)
为了在实现强大的感知和运动预测性能的同时满足现有硬件传输带宽能力,我们应该发送感知和预测神经网络的压缩中间表示。

这个图表明了协同感知的重要性
创新点
网络架构
因此,我们推导出一种新的感知和预测模型,称为 V2VNet,它利用一种空间感知图神经网络(GNN)来聚合从所有附近自动驾驶车辆接收到的信息,使我们能够智能地组合来自场景中不同时间点和视角的信息
数据集
数据集介绍
为了评估我们的方法,我们需要一个包含多辆自动驾驶车辆处于同一局部交通场景的数据集。
不幸的是,这样的数据集不存在。因此,我们的第二个贡献是一个新的数据集,称为 V2V - Sim(见图 1,右),它模拟了有多辆自动驾驶车辆在该区域行驶的设置。
数据集来源
我们使用一个高保真激光雷达模拟器 [33],它使用从真实世界数据构建的大量静态 3D 场景和动态对象目录,为给定的交通场景模拟逼真的激光雷达点云。
利用这个模拟器,我们可以重现从真实世界记录的交通场景,并模拟它们,就好像网络中的一部分车辆是自动驾驶车辆一样
2. 相关工作
联合感知和预测
一些研究将自动驾驶的 3D 检测和运动预测统一起来,获得了两个关键优势:
(1)共享两个任务的计算可实现高效的内存使用和快速的推理时间;
(2)联合对检测和运动预测进行推理可提高准确性和鲁棒性
车对车感知:
对于感知任务,先前的工作利用了编码三种类型数据的消息:原始传感器数据、输出检测结果或包含车辆信息(如位置、航向和速度)的元数据消息
其他常用的方法:
[34, 38] 将接收到的 V2V 消息与本地传感器的输出相关联。
[8] 从其他车辆聚合激光雷达点云,然后通过一个深度网络进行检测。
[35, 44] 通过一个深度网络处理传感器测量值,然后为跨车辆数据共享生成感知输出
本文方法
相比之下通过传输一个压缩的中间表示来利用深度网络的能力
先前的工作在有限数量的简单和不现实的场景中展示了结果,但我们在一个多样化的大规模自动驾驶 V2V 数据集上展示了我们模型的有效性。
多信念聚合:
其他方法
直接方法
对来自不同车辆的特征执行置换不变操作,如池化 [10, 40]
缺点: 这种策略忽略了跨车辆关系(空间位置、航向、时间),并且无法联合对来自发送方和接收方的特征进行推理
图神经网络
关于图神经网络(GNNs)的工作在处理图结构数据方面取得了成功。[15, 18, 26, 46]
MPNN [17] 用一个消息传递框架抽象出了 GNNs 的共性
GGNN [27] 在传播步骤中为节点更新引入了一个门控机制
图神经网络在自动驾驶中也很有效:[3, 25] 提出了一种空间感知 GNN 和一个交互变换器来对自动驾驶场景中的目标交互进行建模
[41] 使用 GNNs 来估计地图节点的价值函数并共享车辆信息以进行协调的路线规划
本文认为 GNNs 适合 V2V 通信,因为每辆车都可以是图中的一个节点。
V2VNet 利用 GNNs 来聚合和组合来自其他车辆的消息
主动感知
主动感知专注于决定智能体应该采取什么行动来更好地感知环境
主动感知在定位和映射 [13, 22]、基于视觉的导航 [14]、作为学习信号 [20, 48] 以及各种其他机器人应用 [9] 中都很有效。
在这项工作中,我们考虑一个更现实的场景,即多辆 SDV 有自己的路线但目前在同一地理区域,通过共享感知消息使 SDV 能够看得更好,而不是主动操纵 SDV 以获得更好的视角并向其他车辆发送信息
3.利用多辆车感知世界(具体方法)
遵循联合感知和预测算法 [3, 5, 30, 31](我们称之为 P&P)的成功经验,我们将我们的方法设计为一个联合架构来执行这两项任务
大体流程
本文设计的 P&P 模型来执行以下操作:给定传感器数据,自动驾驶车辆应该
(1)处理这些数据
(2)广播它
(3)纳入从附近其他自动驾驶车辆接收到的信息,然后(4)生成所有交通参与者在 3D 空间中的位置以及他们预测的未来轨迹的最终估计值。
两个关键问题
在车对车(V2V)设置中出现了两个关键问题:
(i)每辆车应该广播什么信息,以便在保留所有重要信息的同时最小化所需的传输带宽?
(ii)每辆车应该如何纳入从其他车辆接收到的信息,以提高其感知和运动预测输出的准确性?
总结:发什么,怎么收
3.1 问题一:应该传输什么信息
一辆自动驾驶车辆(SDV)可以选择广播三种类型的信息:(i)原始传感器数据
(ii)其 P&P 系统的中间表示
(iii)输出检测结果和运动预测轨迹
本文发送 P&P 网络的中间表示可达到两者的最佳平衡
有两个优点:
(1)深度网络中的中间表示可以很容易地被压缩 [11, 43],同时保留对下游任务重要的信息;
(2)它具有较低的计算开销,因为来自其他车辆的传感器数据已经经过了预处理
3.2 利用多辆车
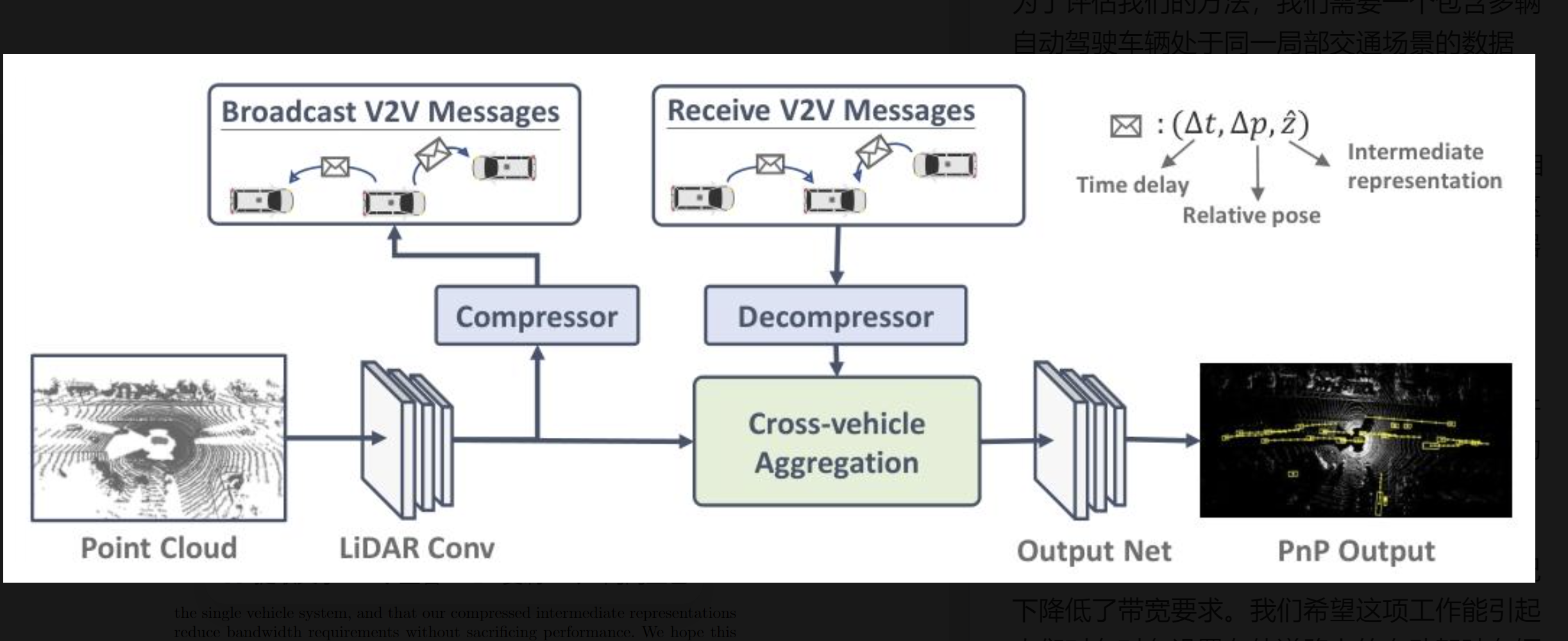
V2VNet 有三个主要阶段:
(1)一个卷积网络块,它处理原始传感器数据并创建一个可压缩的中间表示;
(2)一个跨车辆聚合阶段,它将从多辆车接收到的信息与车辆的内部状态(从其自身的传感器数据计算得出)聚合,以计算一个更新的中间表示;
(3)一个输出网络,它计算最终的感知和预测(P&P)输出。
3.2.1 激光雷达卷积块
遵循 [45] 中的架构,我们从激光雷达数据中提取特征并将它们转换为鸟瞰图(BEV)
[45]. Yang, B., Luo, W., Urtasun, R.: Pixor: Real-time 3d object detection from point clouds. In: CVPR (2018)
具体来说,我们将过去五次激光雷达点云扫描体素化为 15.6cm³ 的体素,应用几个卷积层,并输出形状为 H×W×C 的特征图,其中 H×W 表示 BEV 中的场景范围,C 是特征通道的数量。
我们使用 3 层 3×3 卷积滤波器(步长为 2、1、2)来产生一个 4 倍下采样的空间特征图。这就是我们然后压缩并广播给其他附近自动驾驶车辆(SDV)的中间表示
3.2.2 压缩
现在描述每辆车在传输之前如何压缩其中间表示。
我们采用 Balle 等人的变分图像压缩算法 [2] 来压缩我们的中间表示;一个卷积网络在一个学习到的超先验的帮助下学习压缩我们的表示。潜在表示然后通过熵编码被量化并无损地用很少的位进行编码。请注意,我们的压缩模块是可微的,因此是可训练的,允许我们的方法学习如何在最小化带宽的同时保留特征图信息。
3.2.3 跨车辆聚合
我们对比特流应用熵解码并应用一个解码器 CNN 来提取解压后的特征图。然后我们将从其他车辆接收到的信息聚合以产生一个更新的中间表示。
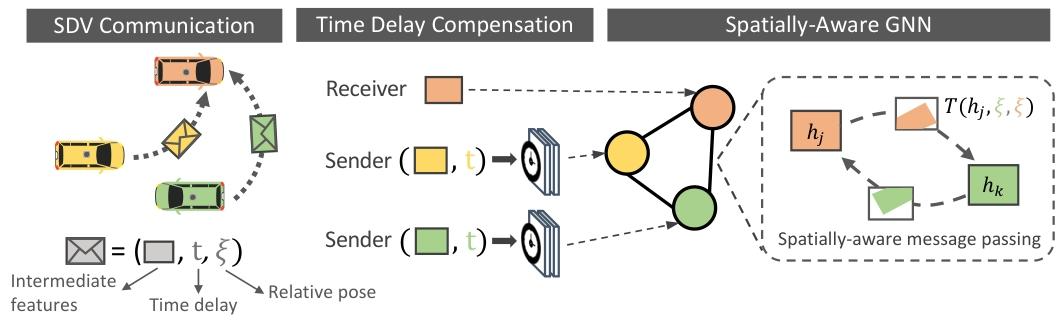
我们的聚合模块必须处理这样一个事实,即由于激光雷达传感器的滚动快门以及每辆车传感器的不同触发,不同的自动驾驶车辆(SDV)位于不同的空间位置并且在不同的时间戳看到目标。这一点很重要,因为中间特征表示是具有空间感知的(要对准空间信息)
为了实现这个目标,每辆车使用一个全连接图神经网络(GNN)[39] 作为聚合模块,其中 GNN 中的每个节点是场景中一辆自动驾驶车辆(SDV)的状态表示,包括它自己(见图 3)。每辆自动驾驶车辆(SDV)根据哪些自动驾驶车辆在范围内(即 70 米)维护自己的本地图。图神经网络(GNN)是一个自然的选择,因为它们处理在车对车(V2V)设置中出现的动态图拓扑。
图神经网络是为图结构数据量身定制的深度学习模型:每个节点维护一个状态表示,并且对于固定数量的迭代,节点之间发送消息,并且节点状态根据使用神经网络聚合的接收到的信息进行更新。
请注意,图神经网络(GNN)的消息与自动驾驶车辆(SDV)发送 / 接收的消息不同:图神经网络的计算是由自动驾驶车辆在本地完成的。我们设计我们的图神经网络(GNN)来临时扭曲并空间变换接收到的消息到接收者的坐标系。
我们现在描述接收车辆执行的聚合过程.读者可参考算法 1 获取伪代码。

接下来的代码解读选自
第2-4行
为每个节点创建一个初始状态。representation通过一个CNN进行时间延迟补偿后,与0拼接以增加节点状态的容量,从而汇总从其他车辆收到的信息。
第5-9行
第7行:首先通过双线性插值(T)对发送节点的特征状态进行空间转换和重采样,其中ξi→k 是一个相对空间变换用来转换第i个节点的中间特征,使其与第k个节点空间对齐。然后,使用一个CNN对两个节点的空间对齐的特征图进行融合。Mi→k用于屏蔽掉非重叠区域,确保了只考虑重叠的视场。
第8行:在每个节点上通过mask-aware permutation-invariant(置换不变)函数ϕM聚集接收到的所有信息(ϕM是平均运算符),并通过ConvGRU更新节点状态(门控机制能够根据接收SDV的当前所需对累积的接收信息进行选择),其中j∈N(i)是节点i的网络中的相邻节点。
第11行
一个多层感知器MLP基于所有的特征状态计算输出最终的中间representation
车辆信息聚合过程
 接下来我们进行图神经网络(GNN)消息传递。关键的见解是,因为其他自动驾驶车辆(SDV)在同一局部区域,节点表示将有重叠的视野。如果我们智能地变换这些表示,并在视野重叠的节点之间共享信息,我们就可以增强自动驾驶车辆对场景的理解,并产生更好的感知和预测(P&P)输出。
接下来我们进行图神经网络(GNN)消息传递。关键的见解是,因为其他自动驾驶车辆(SDV)在同一局部区域,节点表示将有重叠的视野。如果我们智能地变换这些表示,并在视野重叠的节点之间共享信息,我们就可以增强自动驾驶车辆对场景的理解,并产生更好的感知和预测(P&P)输出。


3.2.4 输出网络
利用Inception 来捕捉多尺度上下文

3.3 训练


4. V2V-Sim:一个用于V2V通信的数据集
为了解决这些缺陷,我们使用一个高保真激光雷达模拟器,LiDARsim,来生成我们大规模的 V2V 通信数据集,我们称之为 V2V - Sim
LiDARsim 是一个模拟系统,它使用一个由真实世界数据收集构建的大型 3D 静态场景和动态对象目录来模拟新的场景。
给定一个场景(即场景、车辆资产及其轨迹),LiDARsim 应用光线投射,然后通过一个深度神经网络为场景中的每一帧生成一个现实的激光雷达点云
利用在现实世界 ATG4D 数据集 [45] 中捕获的交通场景来生成我们的模拟。我们在 LiDARsim 的虚拟世界中重新创建这些片段,使用 ATG4D 中提供的真实 3D 轨迹。通过使用相同的场景布局和从现实世界记录的目标轨迹,我们可以复制现实的交通。特别是,在每个时间步,我们根据现实世界的标签将目标 3D 资产放入虚拟场景中,并生成从不同候选车辆看到的模拟激光雷达点云
将候选车辆定义为在记录现实世界片段的车辆的 70 米广播范围内的非停车车辆
V2V - Sim 平均每个样本有 10 个可能在 V2V 网络中的候选车辆,最多有 63 个,方差为 7,展示了交通多样性
5. 实验评估
物体检测
对于物体检测,我们计算在交并比(IoU)阈值为 0.7 时的平均精度(AP)和精确率 - 召回率(PR)曲线
运动预测
对于运动预测,我们计算在未来时间戳(预测时域为 3 秒,间隔为 0.5 秒)上真正例检测的物体中心位置的绝对位移误差
超参数设置
将 IoU 阈值设置为 0.5,召回率设置为 0.9(如果无法达到 0.9,则选择最高召回率)以获得真正例。选择这些值是为了检索到大多数物体,这对于自动驾驶的安全至关重要
轨迹碰撞率(TCR)
计算轨迹碰撞率(TCR),定义为检测到的物体的预测轨迹之间的碰撞率,当两辆车相互重叠超过特定的 IoU(即碰撞阈值)时发生碰撞
基线
单车
激光雷达融合
激光雷达融合通过车辆之间的相对变换将所有接收到的来自其他车辆的激光雷达扫描扭曲到接收者的坐标框架,并进行直接聚合
使用最先进的激光雷达压缩算法 Draco [1] 来压缩激光雷达融合消息
输出融合
每辆车发送后处理的输出,即带有置信度分数的边界框和经过非最大抑制(NMS)后的预测未来轨迹。在接收端,所有边界框和未来轨迹首先被变换到自车坐标系,然后在车辆之间进行聚合。然后再次应用 NMS 以产生最终结果
NMS介绍
非极大抑制NMS:非极大抑制的基本思想就是筛选出一定区域内属于同一种类得分最大的框。


















 380
380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









