






AMASS数据集paper粗读

建立数据集的目的
- 研发基于标准运动捕捉系统(mocap)恢复人的shape和pose的方法,即一套由动捕设备的稀疏点还原3D人体的方法;
- 为相关领域(人体动作的计算机视觉和动画制作)提供一个最大的机器学习数据集;
简而言之,建立一个3D人体的行业标准;
面临问题
mocap的数据集很多,但是各家有各家的数据格式,没法统一使用,团队扩展了MoSh方法,使其可以适配更多的mocap数据集;
MoSh的逻辑
通过稀疏的动捕关键点(marker)恢复稠密的人体模型,其是通过大量的关键点和3D扫描的数据集训练出来的;
MoSh++与前作的区别
模型格式
MoSh输出的人体模型是SCAPE格式表示的,和最新的工业学术界不接轨,MoSh++改用SMPL格式表示;
人体模型以UV map格式给出;
软质衣物
有部分数据来穿了软质衣物的人体,MoSh++使用SMPL的一个衍生模型DMPL;
手部动作
MoSh++增加了手部的建模,使用了与SMPL兼容的MANO手部模型;
finetune
采集了一个marker和同步扫描人体的数据集((Synchronized Scans and Markers,SSM),加强训练;
SMPL的参数量
MoSh用了16个shape参数,MoSh++用了100个shape参数,所以效果更好;
数据集构成
采集场景
- 包含了15个已有mocap数据集,时长40小时,包含344个subjects和11265个动作;
- 采集自37-91个markers不等,并统一了格式;
数据格式
MoSh时期每一帧包含:
- 16个SMPL shape参数,β;
- 8个DMPL相关系数,Φ;
- 159个SMPL pose参数,θ;
文章中有时统称为SMPL模型,其实不是严格的SMPL,应该是SMPL官方称为SMPLH的版本加上AMASS团队自己提出的衣物blendshape方法(DMPL);
SMPL+DMPL
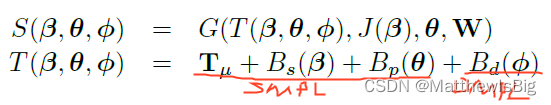
DMPL和SMPL原理一致,比其多一个贴身衣物的Blendshape;

输入输出的维度;
MoSh和MoSh++的训练
[不是暂时的关注点,或许后续更新]
效果
MoSh++总体建模效果

针对衣物的效果
MoSh
MoSh++
ground truth
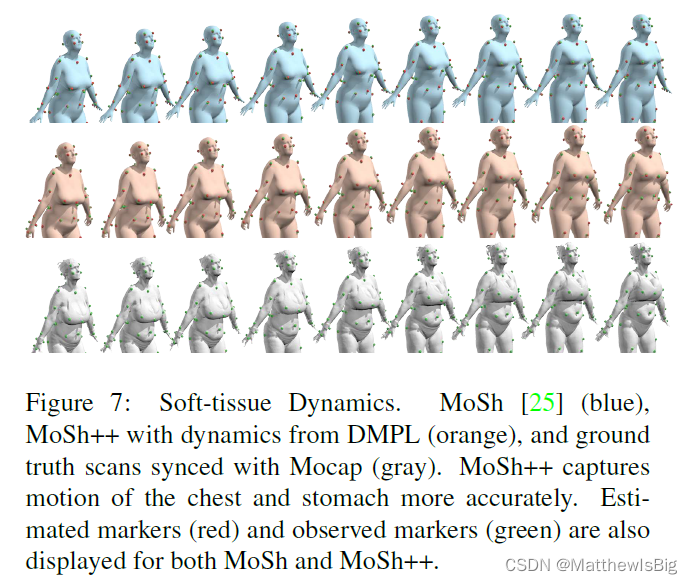
这个身材太棒了,我严重怀疑AMASS团队物化女性,哈哈
针对手部的效果
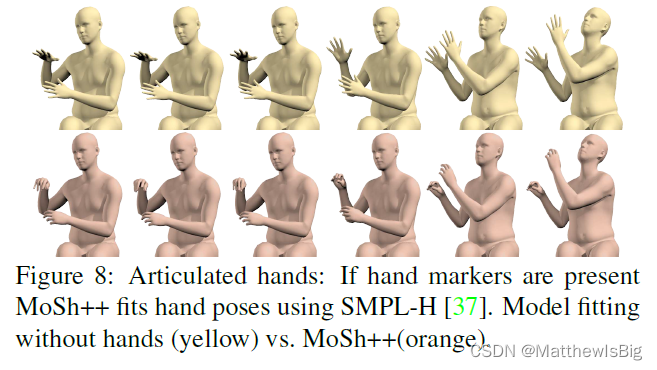

















 2211
2211

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









