







如有需要,请关注微信公众号“笔名二十七画生”!
首先,介绍一下基本概念:
3D目标检测的目标是在三维空间中检测和定位物体。与传统的2D目标检测不同,3D目标检测需要提取目标在三维空间中的位置、姿态和尺寸等信息。3D目标检测因其在自动驾驶和机器人等领域的广泛应用而受到广泛关注。激光雷达传感器在自动驾驶汽车和机器人中被广泛采用,用于捕捉稀疏且不规则的点云形式的3D场景信息,这为3D场景感知和理解提供了重要线索。以下是一些用于3D目标检测的常见技术:
LiDAR与相机融合:通过将激光雷达(LiDAR)和相机数据进行融合,可以获得更为全面和准确的三维信息。这些传感器通常在自动驾驶汽车和机器人等领域中使用。
点云处理:将LiDAR扫描得到的点云数据用于建模和检测。常见的点云处理算法包括Voxel Grid滤波、点云聚类、特征提取等。
神经网络:使用深度学习模型,如卷积神经网络(CNN)和循环神经网络(RNN),来处理三维数据。PointNet和Frustum-PointNet是一些被广泛应用于3D目标检测的模型。
单目深度估计:使用单个摄像机的图像进行深度估计,结合其他传感器信息,从而实现对目标的三维检测。
多传感器融合:结合不同传感器(如相机、LiDAR、雷达)的信息,以提高检测的准确性和鲁棒性。
PV-RCNN文章摘要
作为3D目标检测框架之一,PointVoxel-RCNN(PV-RCNN)用于从点云中精确检测3D物体。该方法深度整合了3D体素卷积神经网络(CNN)和基于PointNet的集合抽象,以学习更具判别性的点云特征。它充分利用了3D体素CNN的高效学习和高质量提议,以及PointNet网络的灵活感受野。具体而言:
-
该方法通过一个体素集合抽象模块,将3D场景总结为一小组关键点,以节省后续计算并编码代表性的场景特征。
-
在获得体素CNN生成的高质量3D提议后,引入了RoI(Region of Interest)-grid池化,通过关键点集抽象以多个感受野的方式,从关键点到RoI-grid点抽象提取提案特定的特征。
-
与传统的池化操作相比,RoI-grid特征点为准确估计物体置信度和位置提供了更丰富的上下文信息。在KITTI数据集和Waymo Open数据集的实验表明,PV-RCNN能够取得显著优势。

论文地址:
https://arxiv.org/pdf/1912.13192.pdf
代码地址:
https://github.com/open-mmlab/OpenPCDet
实验条件:
8 -32 块 GTX 1080 Ti GPUs(针对不同数据集)
MQ-Det前世今生
根据点云表示的不同,大多数现有的3D检测方法可以分为两类,即基于网格的方法和基于点的方法。基于网格的方法通常将不规则的点云转换为规则的表示形式,如3D体素[27, 41, 34, 2, 26]或2D鸟瞰地图[1, 11, 36, 17, 35, 12, 16],这可以通过3D或2D卷积神经网络(CNN)有效地进行处理,以学习用于3D检测的点特征。在PointNet及其变体的开创性工作的推动下[23, 24],基于点的方法[22, 25, 32, 37]直接从原始点云中提取判别性特征用于3D检测。通常而言,基于网格的方法在计算上更为高效,但不可避免的信息损失降低了细粒度定位的准确性,而基于点的方法计算成本更高,但通过点集抽象[24]可以轻松实现更大的感受野。然而,我们展示了一个统一的框架可以整合这两种方法的优势,并且以显著的优势超越以前的3D检测方法。
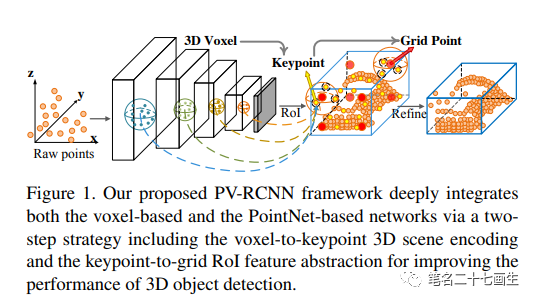
(文章方法的优势)PV-RCNN(见图1)通过结合基于点和基于体素的特征学习方法的优势,提升了3D检测性能。PV-RCNN的原则在于,基于体素的操作能够高效编码多尺度特征表示,并能生成高质量的3D提案,而基于PointNet的集合抽象操作保留了灵活感受野下的准确位置信息。两种特征学习框架的整合有助于学习更具判别性的特征,以实现准确的细粒度框精化。
(文章解决的问题)主要挑战在于如何有效地将这两种特征学习方案,即具有稀疏卷积的3D体素CNN[6, 5]和基于PointNet的集合抽象[24],融合成一个统一的框架。一种直观的解决方案是在每个3D提案内均匀采样多个网格点,并采用集合抽象来聚合围绕这些网格点的3D体素特征进行提案精化。然而,这种策略非常消耗内存,因为体素数量和网格点数量都可能相当大,以达到令人满意的性能。
因此,为了更好地整合这两种类型的点云特征学习网络,作者提出了一个两步策略,第一步是体素到关键点场景编码步骤,第二步是关键点到网格RoI特征抽象步骤。具体而言:
第一步是采用具有3D稀疏卷积的体素CNN进行体素特征学习和准确提案生成。为了缓解对编码整个场景需要过多体素的问题,通过最远点采样(FPS)选择了一小组关键点,以总结体素特征的整体3D信息。通过基于PointNet的集合抽象,通过将相邻体素特征进行分组,聚合每个关键点的特征以总结多尺度点云信息。这样,整体场景可以通过一小组关键点及其关联的多尺度特征进行有效且高效地编码。
第二步是关键点到网格RoI特征抽象步骤,针对每个框提议及其网格点位置,提出了一个RoI-grid池化模块,其中采用了具有多个半径的关键点集抽象层,用于每个网格点聚合具有多尺度上下文的关键点特征。然后,所有网格点的聚合特征可以共同用于后续提案的精化。
MQ-Det匠心独运
1.方法概述。
PV-RCNN框架有效地利用了基于体素和基于点的方法进行3D点云特征学习,从而提高了3D目标检测性能,并且内存消耗可控。
首先,原始点云被体素化,然后输入到基于3D稀疏卷积的编码器中,用于学习多尺度语义特征并生成3D物体提案。
然后,通过新颖的体素集合抽象模块,将多个神经层的学到的体素特征体积总结为一小组关键点。
最后,将关键点特征聚合到RoI(感兴趣区域)-grid点上,以学习提案特定的特征,用于精细的提案精化和置信度预测。

2.架构设计。
如下图所示为预测关键点权重模块的示意图。作者提出体素到关键点场景编码方案,通过体素集合抽象层将整个场景的多尺度体素特征编码到一小组关键点中。这些关键点特征不仅保留了准确位置,还编码了丰富的场景背景信息,显著提升了3D检测性能。

如下图所示为 RoI-grid池化模块的示意图。每个3D RoI的丰富上下文信息通过具有多个感受野的集合抽象操作进行聚合。作者提出的多尺度RoI特征抽象层通过具有多个感受野的关键点集抽象,从场景中聚合更丰富的上下文信息,以实现准确的框精化和置信度预测。

MQ-Det卓越性能
PV-RCNN方法在高度竞争的KITTI 3D检测基准[10]上以显著的优势胜过所有先前的方法,并在大规模的Waymo Open数据集上也以较大的优势超过先前的方法。
KITTI数据集:

Waymo Open数据集:

MQ-Det未来展望
PV-RCNN框架是一种从点云中准确检测3D物体的新颖方法。该方法通过新提出的体素集合抽象层将多尺度3D体素CNN特征和基于PointNet的特征集成到一小组关键点中,然后将关键点的学到的判别性特征聚合到具有多个感受野的RoI(感兴趣区域)-grid点上,以捕获更丰富的上下文信息,用于精细的提案精化。在KITTI数据集和Waymo Open数据集上的实验结果表明,作者提出的体素到关键点场景编码和关键点到网格RoI特征抽象策略与先前最先进的方法相比,显著提高了3D目标检测性能。
参考文献:
【1】Shi S, Guo C, Jiang L, et al. Pv-rcnn: Point-voxel feature set abstraction for 3d object detection[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 10529-10538.
如有需要,请关注微信公众号“笔名二十七画生”!















 1527
1527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









