









小样本学习&元学习经典论文整理||持续更新
核心思想
作者提出一种基于表征的度量学习方法用于解决小样本分类和目标检测问题。作者提出每个类别的样本,其在嵌入式空间(特征空间)中的分布都属于一种混合分布模型,而每个模型分量的众数mode(也就是概率密度函数最高点,峰值peak),就是该类样本的一个表征。通过度量输入图像对应的特征向量与各个类别对应表征之间的距离,预测输入图像的类别。网络结构如下图所示。
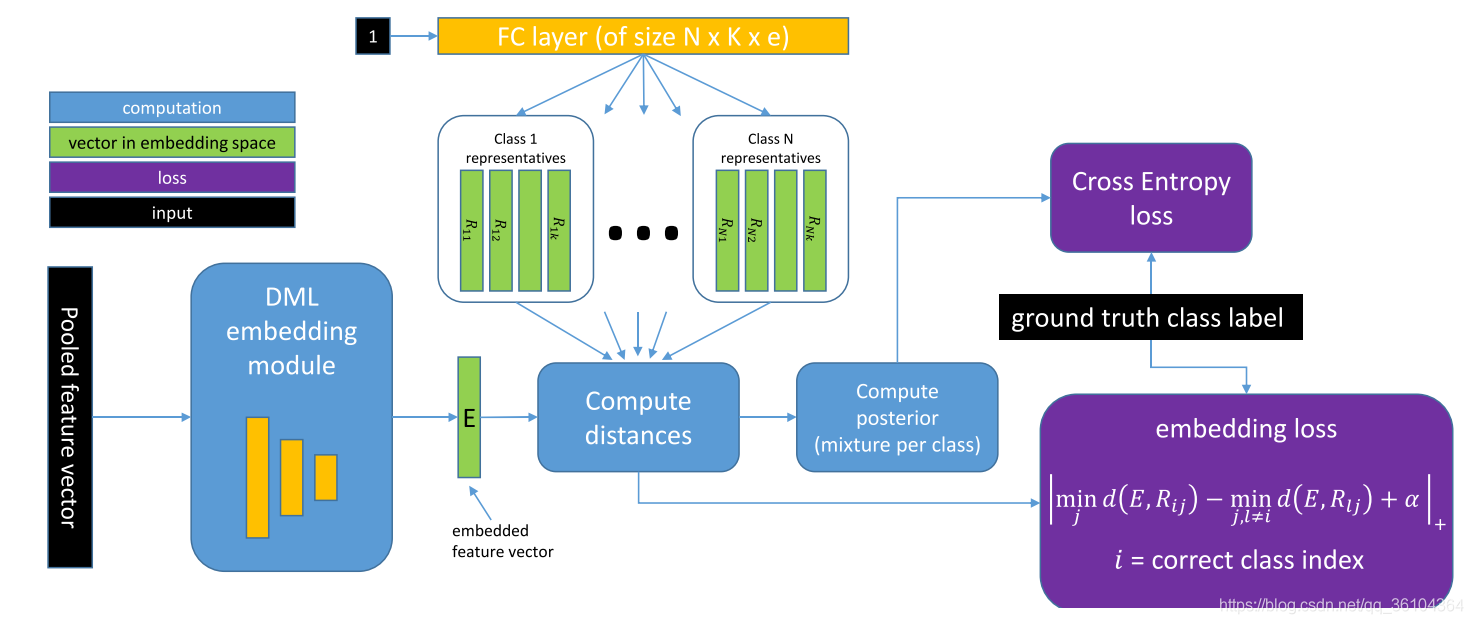
首先输入图像经过一个特征提取网络(如InceptionV3)得到特征向量,然后经过DML(Distance Metric Learning)嵌入模块,将其转化为一个嵌入特征向量
E
∈
R
e
E\in \mathbb{R}^e
E∈Re。另一方面,通过一个全连接层将一个输入标量“1”转化为各个类别的表征。具体而言,该全连接层有
N
×
K
×
e
N\times K\times e
N×K×e个单元,其中
N
N
N表示
N
N
N个类别,
K
K
K表示每个类别包含
K
K
K个表征(也就是混合分布中包含
K
K
K个分量),
e
e
e表示特征向量的长度,则将该全连接层的输出转为
N
×
K
×
e
N\times K\times e
N×K×e的张量就得到了表征
R
i
,
j
R_{i,j}
Ri,j(第
i
i
i各类别的第
j
j
j个表征分量)。因为全连接层只有一层,且输入为标量“1”,因此输出就等于权重,权重就等于输出。然后将表征
R
i
j
R_{ij}
Rij和输入图像对应的嵌入式特征向量
E
E
E输入距离度量网络中,输出对应的距离矩阵
d
i
,
j
=
d
(
E
.
R
i
,
j
)
d_{i,j}=d(E.R_{i,j})
di,j=d(E.Ri,j)。最后根据距离计算,图像属于某个类别的概率
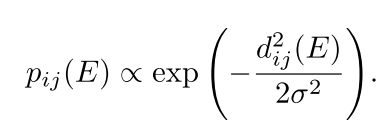
本文假设每个类别的分布是一个各向同性的多分量高斯混合分布,
σ
2
\sigma^2
σ2为方差。对于小样本分类问题,输入
X
X
X属于类别
i
i
i的概率为
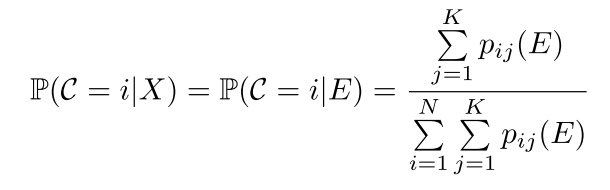
对于目标检测问题,输入
X
X
X属于类别
i
i
i的概率为
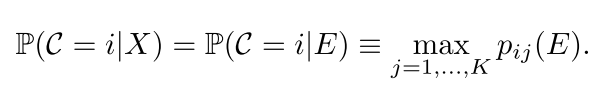
实现过程
网络结构
DML嵌入模块是由两个全连接层构成,第一层有2048个单元,且带有BN层和ReLU层,第二层有1024个单元,且只有线性激活层,对于输出的嵌入特征向量进行L2正则化。距离度量网络没有介绍?
损失函数
损失函数包含两个部分:分类损失和嵌入损失。分类损失就是简单的交叉熵损失函数,嵌入损失计算方式如下
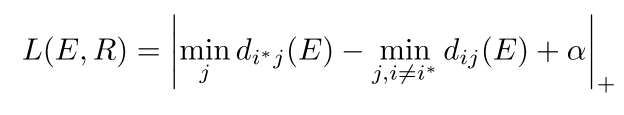
式中
i
∗
i^*
i∗表示正确的类别,上式要求嵌入特征向量
E
E
E与正确类别的表征之间的最近距离,要比与其他错误类别的表征之间的最近距离小
α
\alpha
α,否则会受到惩罚。
训练策略
算法推广
将标准两级目标检测网络中FPN输出的该兴趣区域ROI作为输入,用本文设计的分类网络取代RCNN分类器的部分,就能够实现小样本目标检测任务。在该任务中需要增加背景类别的预测,其概率预测为
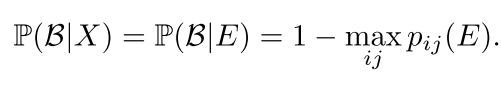
创新点
- 采用基于表征的度量学习方法,实现了小样本分类任务
- 将分类网络取代目标检测模型中的分类器部分,实现了小样本的目标检测任务
算法评价
本文采用基于表征的度量学习方法,假定每个类别在特征空间中都符合混合高斯分布,那么混合高斯分布中每个组成分量的众数就对应着该类别的一个表征,通过度量表征与输入图像特征向量之间的距离,得到输入图像属于某个类别的概率。文中有许多细节问题我并没有完全搞懂,首先在计算每个类别的表征时,只采用一个全连接层,且输入是固定的标量,这意味着类别的表征学习全部依赖于损失信息对于权重值的更新(理想状态是每个类别的样本只会激活其中的几个特定的单元),这种方式在处理未见过的少量新样本时能否及时更新,且不出现过拟合的问题呢?此外,如果全连接层的结构确定了,那么预测的类别数量 N N N也就固定了,如果测试中类别数量改变了,就需要更改全连接层的参数,那么所谓的端到端训练也只是对嵌入模块和距离度量网络进行训练。对于度量学习中的关键部分——距离度量网络,作者并没有仔细的介绍,这也是本文的一大缺憾。但本文是我读到的第一篇实现小样本目标检测问题的,这一方向将成为下一步学习的重点。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。
















 2175
2175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











