









小样本学习&元学习经典论文整理||持续更新
核心思想
本文提出一种应用于语义分割任务的小样本学习算法。首先我们介绍一下小样本语义分割任务,与分类任务相同,语义分割任务也包含支持集与查询集,目前的算法通常将网络分为两个分支,一个分支用于处理支持集图片,另一个分支用于处理查询集图片。例如,支持集图片中包含一辆摩托车和对应的分割图像,则查询集图片则包含另一辆摩托车,算法的目标就是根据支持集图片与查询集图片的关系,得到查询集图片中摩托车的分割图像。明确了任务之后,我们介绍下本文是如何实现小样本语义分割任务的。本文同样采用双分支的网络结构,但在此基础上增加了稠密比较模块(Dense Comparison Module,DCM),用于寻找支持集图片与查询集图片之间的联系,并且利用迭代优化模块(Iterative Optimization Module,IOM)以迭代的方式不断提高图像分割的效果。对于few-shot任务,本文利用注意力机制,有效地融合了多个样本的信息。为了进一步降低标注成本,本文可以利用只有目标框的支持集样本(与目标检测相同)进行学习,并得到分割结果。下面我们结合网络结构图,具体讲解本文的实现过程。
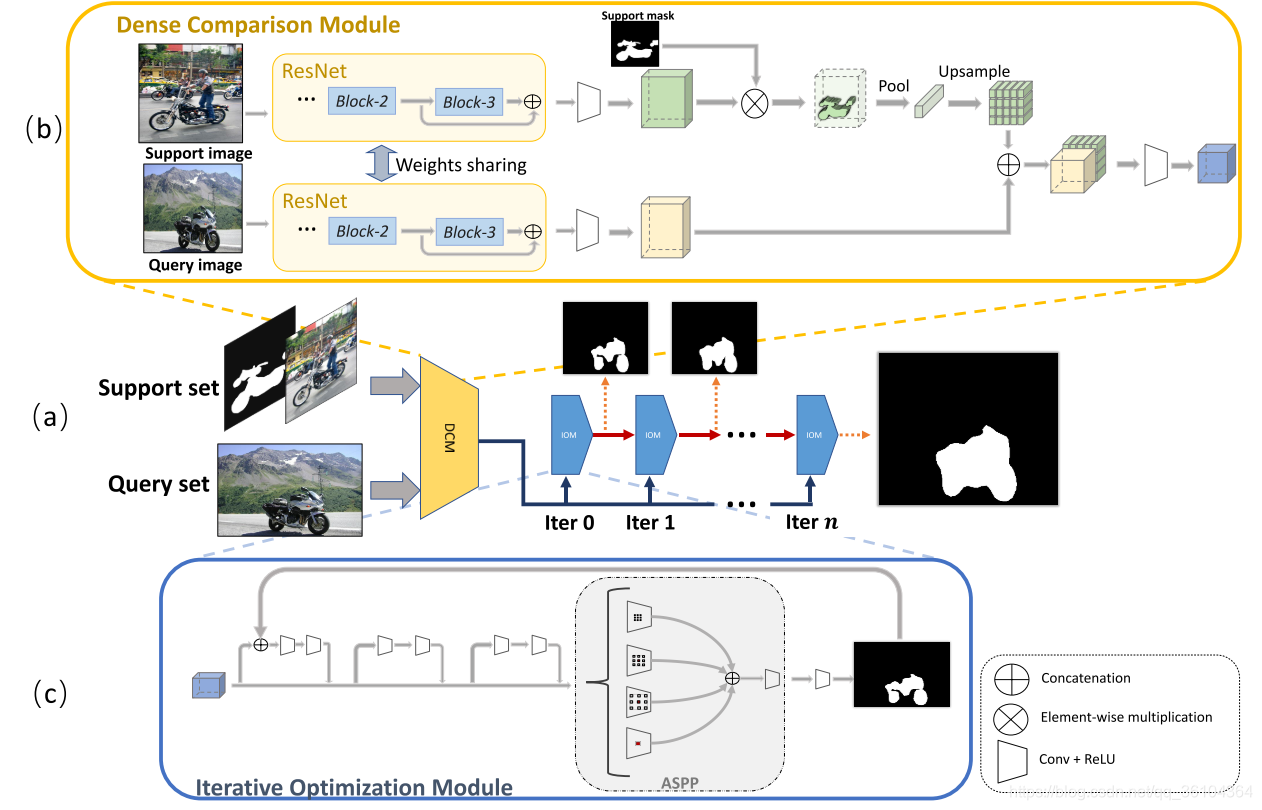
如图a所示,支持集图片与对应的分割图和查询集图片输入到DCM中。DCM的结构如图b所示,图像首先经过两个权重共享的特征提取模块,本文采用ResNet-50网络作为backbone,由于低层级网络通常提取一些通用性特征,如边缘和颜色,但查询集和支持集之间,即使是同类物体也存在外表上的差异;高层级网络通常提取一些抽象的特征,但这些特征泛化性能较差,无法应用与新类别物体。因此,本文选择中层级特征,用于比较查询集和支持集图片,具体而言,就是将ResNet-50中第二个残差块和第三个残差块输出的特征图级联起来,再利用3 * 3的卷积层编码为256个通道的特征图。所谓比较,就是比较查询集对应的特征图与支持集对应的特征图之间的相似性,如果采用逐像素比较的方式,那这个计算量是无法承受的。因此本文采用全局图像特征(Global image features),其实就是利用全局平均池化将支持集图片的每幅特征图压缩为一个值,最终得到一个长度为256的特征向量(这是语义分割领域常用的操作,目的是提取高度抽象化的语义特征)。当然本文并不是直接对支持集图片对应的特征图做全局平均池化,而是先利用分割图,对特征图进行了掩码操作,只保留目标图像的部分,排除其他背景信息的干扰。最后,用特征向量与查询集图像对应的特征图,进行逐像素的比较,目的是寻找到查询集图像中与目标语义特征相近的像素。为了提高计算效率,本文是将特征向量进行上采样恢复其空间尺寸,其实就是复制然后拼接堆叠而成,然后与查询集图像对应的特征图级联起来,经过一个卷积层得到相似性矩阵。
仅仅通过稠密比较模块得到的相似性矩阵,只能粗略的表示目标物体所在的区域,并不能精确的描述目标物体的轮廓,因此要通过迭代优化模块逐步提高分割的效果。每个IOM模块的结构如图c所示,其中包含三个带有残差链接的卷积块和一个ASPP模块,最后再利用一个1 * 1的卷积得到分割掩码图。不仅如此为了提高分割的精度,将前一个IOM输出的掩码图与下一个IOM模块输入的特征图级联起来,再进行卷积,结果多次反复迭代后,输出最终的掩码分割图。
对于few-shot语义分割任务,支持集中可能包含多个样本图片,为了充分利用其信息,本文采用了注意力机制将信息融合起来。
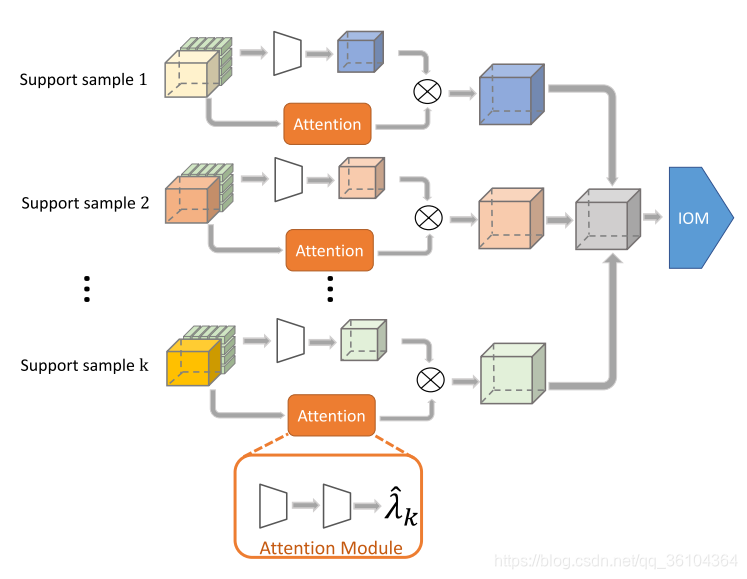
如图所示,在计算相似性矩阵时,增加一个注意力分支,用于计算权重值
λ
i
\lambda _i
λi,将每个样本对应的权重利用softmax函数进行归一化处理后得到
λ
^
i
\hat{\lambda} _i
λ^i
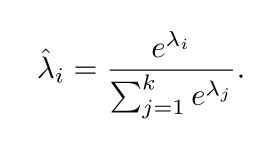
最后对所有样本对应的相似性矩阵进行加权求和得到最终的输出。
实现过程
网络结构
DCM中特征提取网络是采用ResNet-50结构,但只保留了第二和第三个残差块的输出,相似性度量网络采用的是3 * 3的卷积层。IOM中包含三个卷积块,每个卷积块都由两个3 * 3的卷积层构成,ASPP模块包含四个分支,扩展率分别为1,6,12和18,最终利用1 * 1的卷积层进行融合。注意力模块有两个3 *3的卷积层构成,第一个后面带有3 *3的最大值池化层,第二个后面带有全局平均池化层,用于计算权重 λ i \lambda _i λi。
损失函数
无介绍,通常语义分割任务采用交叉熵损失函数。
训练策略
需要注意的一点是在训练过程中,迭代优化部分并不是每次都将前一个IOM输出的分割掩码图输入到下一个IOM中,而是按照一定的概率选择输入一张空白的掩码图或者是分割掩码图。这一步操作可以看作是一种dropout的拓展,是为了防止过拟合的问题。
创新点
- 设计了稠密比较模块,用于初步确定目标物体所在位置
- 采用迭代优化模块,逐步提高语义分割的精度
- 引入注意力机制,充分融合多个样本中包含的信息,提高了分割效果
算法评价
本文采用的所有模块和设计方案,我们都不陌生,都谈不上非常的新颖,但将其综合利用,形成一个结构完整严谨的网络也着实不易,其中也采用了许多精巧的设计。本文是我读到的第一篇用于解决小样本语义分割任务的文章,因为该领域的研究刚刚起步,所以相关文献也较少,就结果而言本文的算法相对于之前的小样本语义分割算法,效果有了明显的提升。有意思的是,我们在上篇文章中曾提到在目标分类任务中,不断的增加分类的细粒度,有逐渐靠近语义分割任务的趋势,而在本文中却利用目标分类常用的全局平均池化方式来解决语义分割任务,有时候研究工作就是一个相互借鉴,相互趋同的过程。
如果大家对于深度学习与计算机视觉领域感兴趣,希望获得更多的知识分享与最新的论文解读,欢迎关注我的个人公众号“深视”。


















 9219
9219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











