







Depth Anything V2是个单目深度估计模型
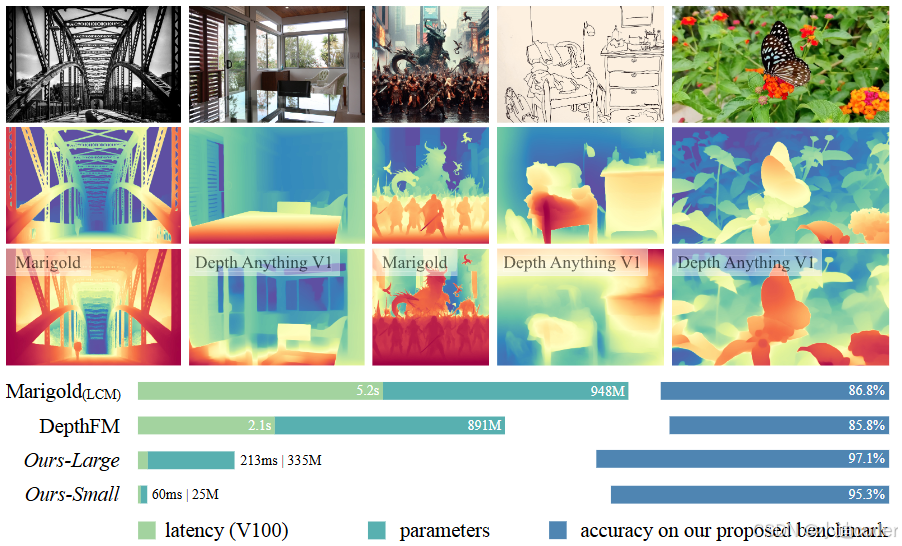
Depth Anything V2相比基于SD的模型,推理速度更快,更少的参数,更高的精度。
SD模型是指基于Stable Diffusion技术的模型,该技术用于图像生成、图像修复和其他视觉任务。

与DeepAnything V1 模型相比,Marigold模型在细节呈现上更胜一筹。

根据表格可以看出,不论精度还是细节方面,Deep Anything V2更胜一筹。
单目深度估计(Monocular depth estimation)MDE模型常用于3D重建,导航和自动驾驶领域。
从模型架构上单目深度估计分为两类:
1. 基于判别模型,如BEiT和DINOv2。代表模型是Marigold.
2. 基于生成模型,如Stable Diffusion。代表模型是Depth Anything

高效的判别模型同样能生成非常精细的细节,关键点在于数据,训练数据应该替换为精准的合成数据。通过快打在合成图像上训练的教师模型规模,然后通过大规模的伪标注的真实图像来训练较小的学生模型。
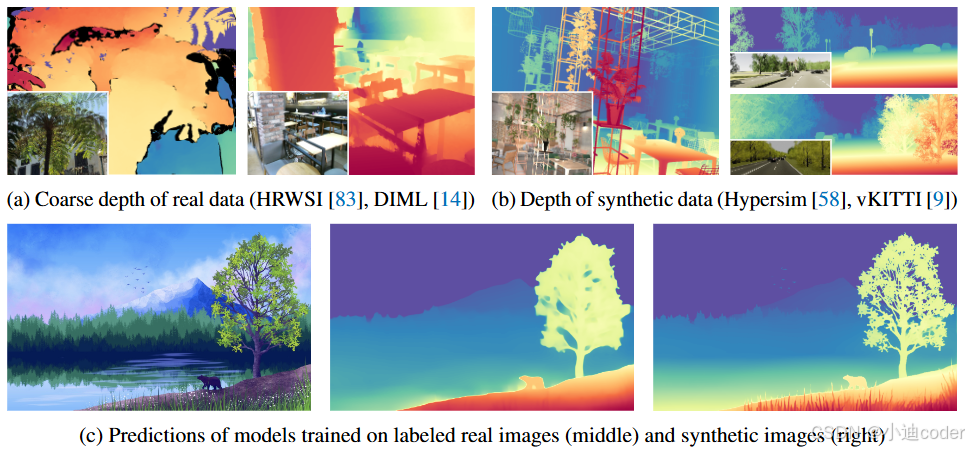
由上图可知,合成数据上训练的效果更好。
使用合成数据遇到的挑战(待解决的问题):
1. 合成图像和真实图像之间存在分布偏移
2. 合成图像的场景覆盖范围有限。

不同视觉编码器在合成到真实图像迁移上的定性比较。只有 DINOv2-G 给出了令人满意的预测。

最强 DINOv2-G 模型在仅用合成图像训练时的失败案例。左:天空应该是超远的。右:头部的深度与身体不一致。
使用合成图像和真实图像的组合训练集会出现真实图像的粗略深度会破坏精细的预测的情况。
收集更多的合成图像是不现实的。
本论文提出了适合任何模型规模的方案。
方案:首先MDE模在基于DINOv2-G的合成图像上进行训练,然后改模型为无标签的真实图像分配伪深度标签。最后,我们的新模型仅在大规模且精确伪标签的图像上进行训练。
方案的具体流程如下图所示:

由于分布偏移,从合成训练图像直接迁移到真实测试图像是不行的,为了让模型更好地适应真实世界的数据分布,与手工标注的图像相比,我们自动生成的伪标签要更加精细和完整。
训练 Depth Anything V2 的流程包括三个步骤:
• 基于 DINOv2-G,仅在高质量的合成图像上训练一个可靠的教师模型。
• 在大规模未标注的真实图像上生成精确的伪深度标签。
• 在伪标注的真实图像上训练最终的学生模型,以实现强大的泛化能力。

噪声对模型的影响较大。
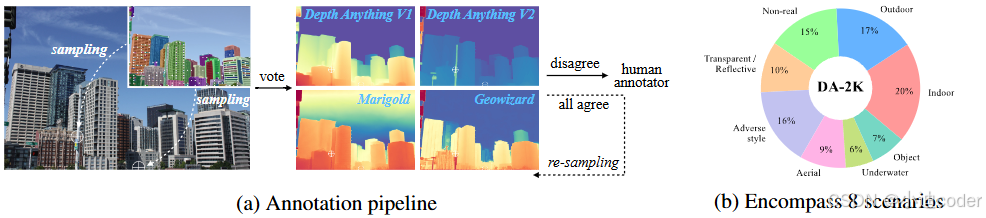
相对深度的标注流程:
1. SAM模型预测图像中每个点的掩码,基于这些预测结果来选择要标注的点。
2. 拿这些标注点问专家模型,如果各个模型对一个点的深度预测值差异较大,需人工标注。

















 1068
1068

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









