







前言:本博客汇总当前AI生成图像检测领域用到的数据集及相关链接。
⚠️:除标注「未公开」数据集,其余数据集均已开源。
2020
- CNNSpot
https://github.com/peterwang512/CNNDetection
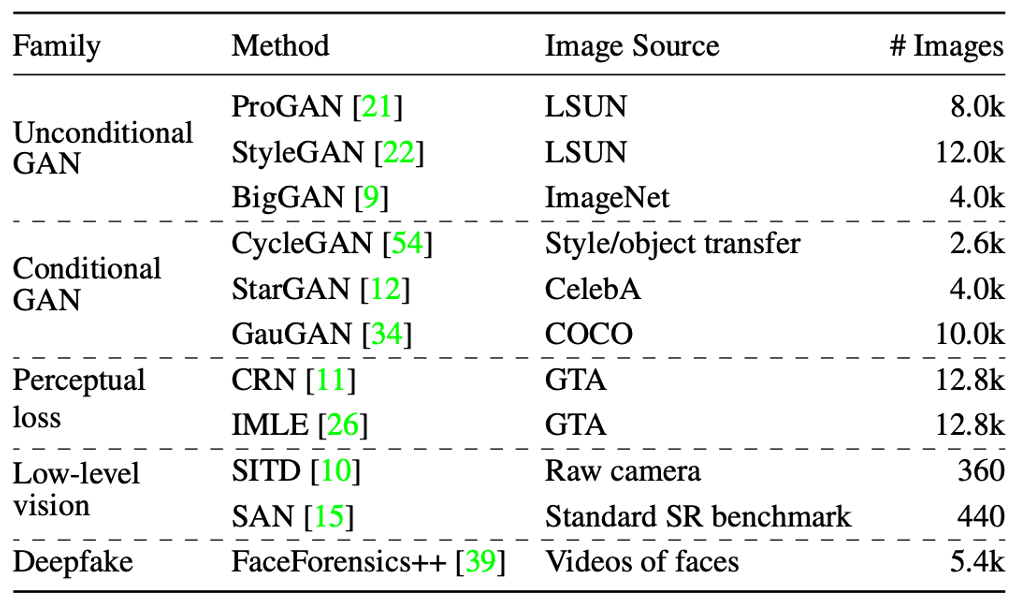
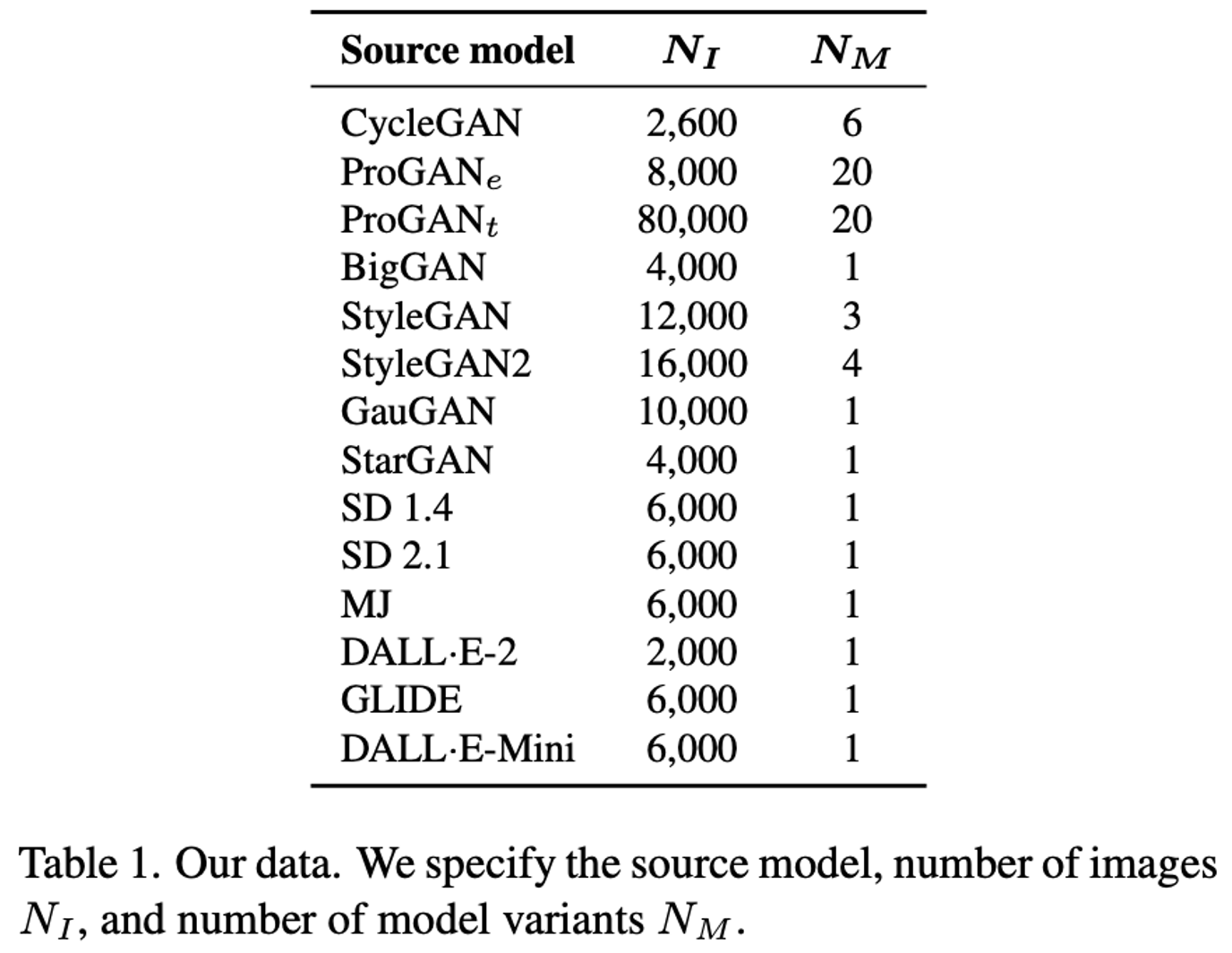
Testset: The zip file contains images from 13 CNN-based synthesis algorithms, including the 12 testsets from the paper and images downloaded from whichfaceisreal.com. Images from each algorithm are stored in a separate folder. In each category, real images are in the 0_real folder, and synthetic images are in the 1_fake folder.
Note: ProGAN, StyleGAN, StyleGAN2, CycleGAN testset contains multiple classes, which are stored in separate subdirectories.
Training set: The training set used in the paper can be downloaded here (Try alternative links 1,2 if the previous link does not work). All images are from LSUN or generated by ProGAN, and they are separated in 20 object categories. Similarly, in each category, real images are in the 0_real folder, and synthetic images are in the 1_fake folder.
Validation set: The validation set consists of held-out ProGAN real and fake images, and can be downloaded here. The directory structure is identical to that of the training set.
2022
-
IEEE VIP Cup(2022 IEEE Video and Image Processing Cup | Synthetic Image Detection Challenge)
https://grip-unina.github.io/vipcup2022/ -
SAC
https://github.com/JD-P/simulacra-aesthetic-captions
数据集中图像命名,包含生成所需的提示词,如:0_An_artwork_of_a_broken_wine_bottle_in_the_medium_of_dry_pigments_1.png43044_…png
此外,该数据集也被用于美学质量评价。
2023
-
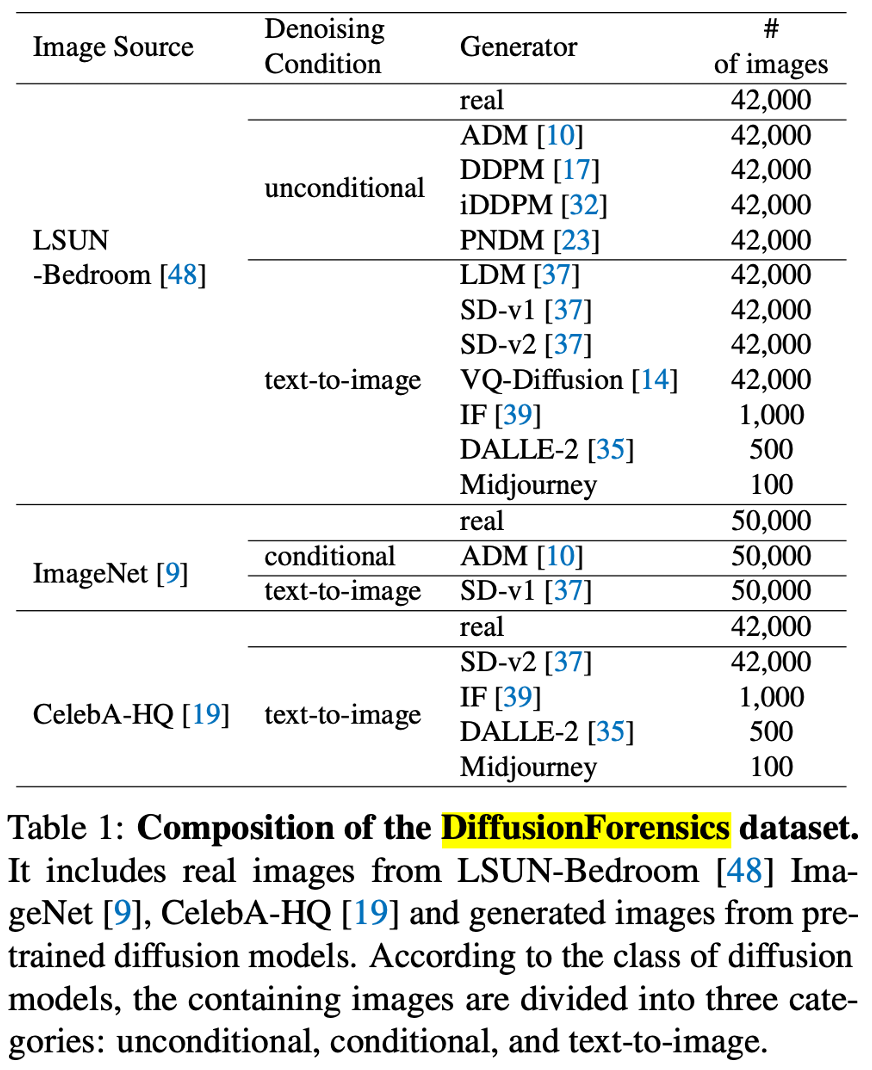
DiffusionForensics
https://github.com/ZhendongWang6/DIRE
-
DMimageDetection
https://github.com/grip-unina/DMimageDetection/tree/main/training_code
https://luminohope.org/pub/publication/arxiv_diffusion_detection_2022/ -
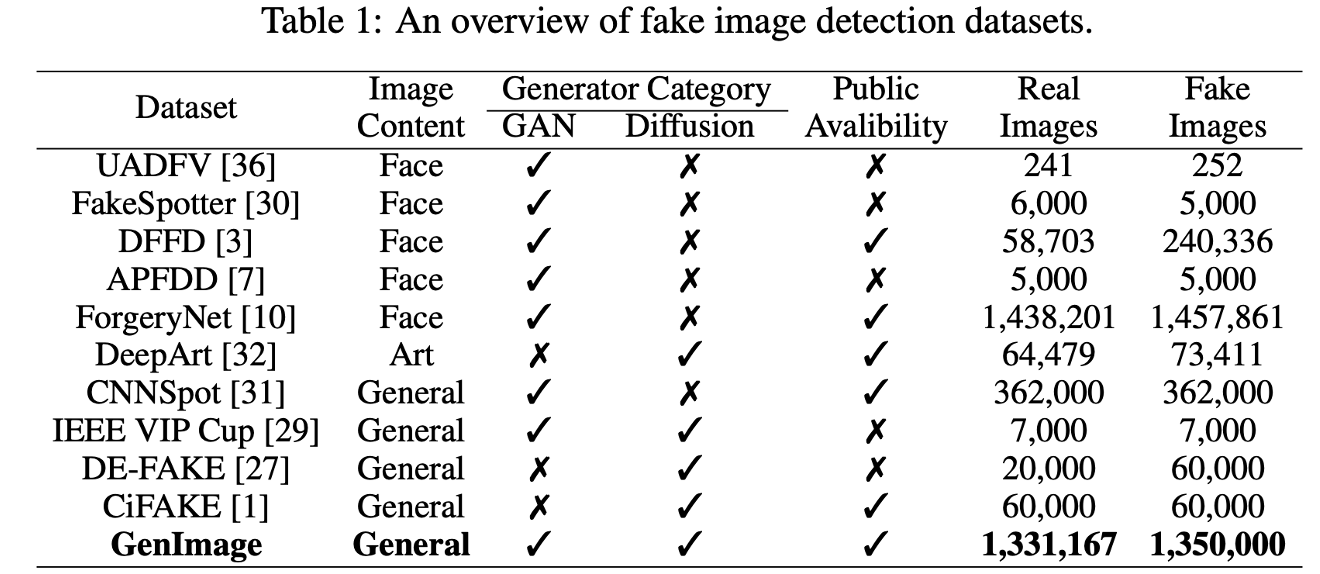
GenImage
https://github.com/GenImage-Dataset/GenImage
We employ eight generative models for image generation, namely BigGAN [2], GLIDE [21], VQDM [8], Stable Diffusion V1.4 [25], Stable Diffusion V1.5 [25], ADM [5], Midjourney [20], and Wukong [35].
-
Fake2M
https://arxiv.org/pdf/2304.13023
We constructed 3 training fake datasets with about 2M images, named Fake2M, and 11 validation fake datasets with about 257K images using different latest modern generative models, which contain the SOTA Diffusion models (Stable Diffusion [46], IF [4]), the SOTA GAN model (StyleGAN3 [31]), the SOTA autoregressive model (CogView2 [19]), and the SOTA generative model (Midjounrey [6]), as shown in Tab. 2. We describe the details of our datasets in the following subsections.

-
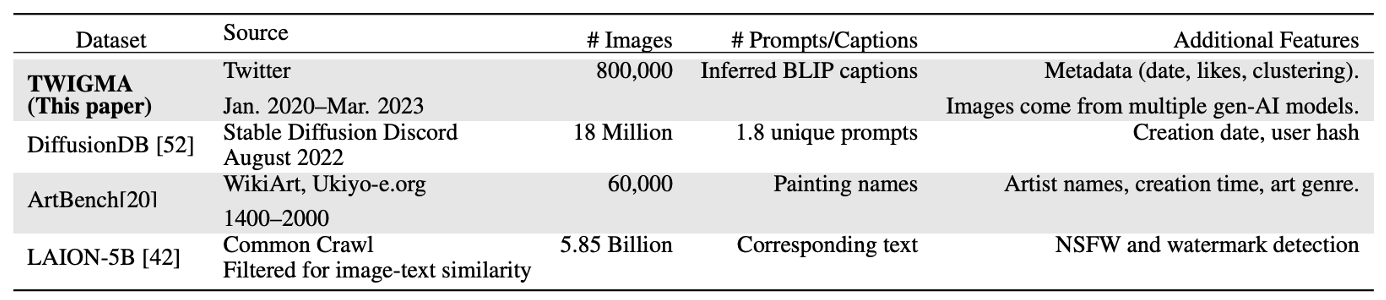
TWIGMA
https://yiqunchen.github.io/TWIGMA/index.html#dataset
-
ArtiFact
https://github.com/awsaf49/artifact
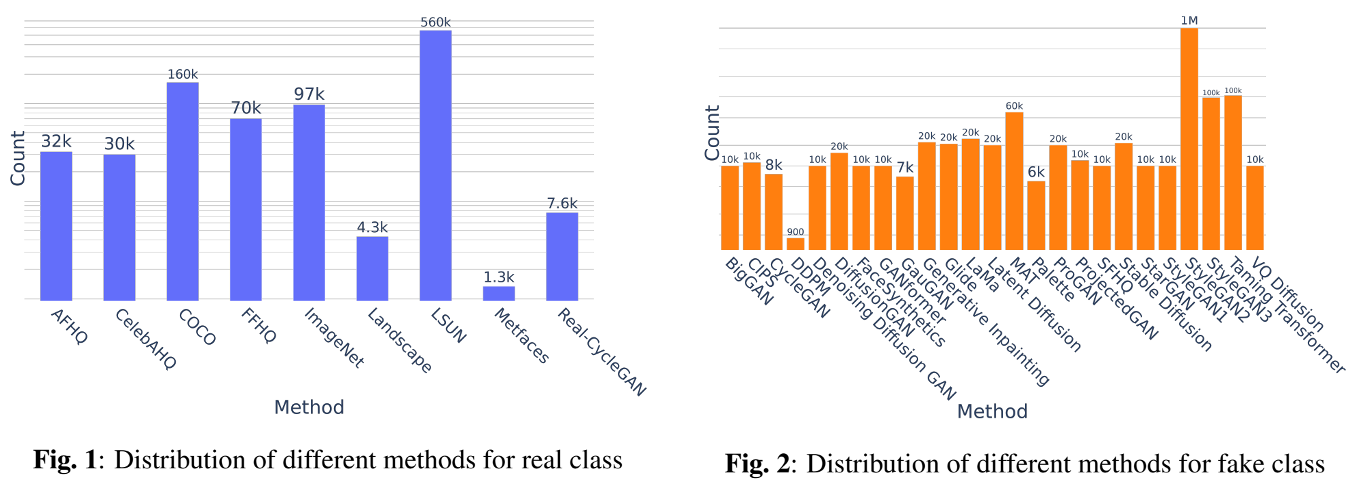
To include a diverse collection of real images from multiple categories, including Human/Human Faces, Animal/Animal Faces, Places, Vehicles, Art, and many other real-life objects, the proposed dataset utilizes 8 sources [7], [14]–[16] that are carefully chosen. Additionally, to inject diversity in terms of generators, the proposed dataset synthesizes images from 25 distinct methods [7]–[9], [14]–[24]. Specifically, it includes 13 GANs, 7 Diffusion, and 5 other miscellaneous generators. On the other hand, in terms of syntheticity, there are 20 fully manipulating and 5 partially manipulating generators, thus providing a broad spectrum of diversity in terms of generators used. The distribution of real and fake data with different sources is shown in Fig.1 and Fig.2, respectively. The dataset contains a total of 2,496,738 images, comprising 964,989 real images and 1,531,749 fake images. The most frequently occurring categories in the dataset are Human/Human Faces, Animal/Animal Faces, Vehicles, Places, and Art.
13GANs: BigGAN, CycleGAN, Denoising Diffusion GAN, Diffusion GAN, FaceSynthetics, GANformer, GauGAN, ProGAN, ProjectedGAN, StarGAN, StyleGAN1, StyleGAN2, StyleGAN3
7DMs: DDPM, Glide, LaMa, Latent Diffusion, Stable Diffusion, Taming Transformer, VQDiffusion
5 Others: CIPS, Generative Inpainting, MAT, Palette, SFHQ
-
Synthbuster
https://github.com/qbammey/polardiffshield

-
UniversarialFakeDetect
https://github.com/WisconsinAIVision/UniversalFakeDetect
11GANs + 7 DMs + 1 其他 -
DiffusionDB
https://github.com/poloclub/diffusiondb
We construct DIFFUSIONDB (Fig. 2) by scraping user-generated images from the official Stable Diffusion Discord server. We choose Stable Diffusion as it is currently the only open-source large text-to-image generative model, and all generated images have a CC0 1.0 license that allows uses for any purpose -
CiFAKE
https://github.com/jordan-bird/CIFAKE-Real-and-AI-Generated-Synthetic-Images
CIFAKE is a dataset that contains 60,000 synthetically-generated images and 60,000 real images (collected from CIFAR-10). For the FAKE images, we generated the equivalent of CIFAR-10 with Stable Diffusion version 1.4 -
LASTED
https://github.com/HighwayWu/LASTED
训练集生成模型:ProGAN,Lexica(Stable Diffusion)
测试集:DreamBooth, Midjourney, NightCafe, StalbeAI, YiJian(蚁鉴) -
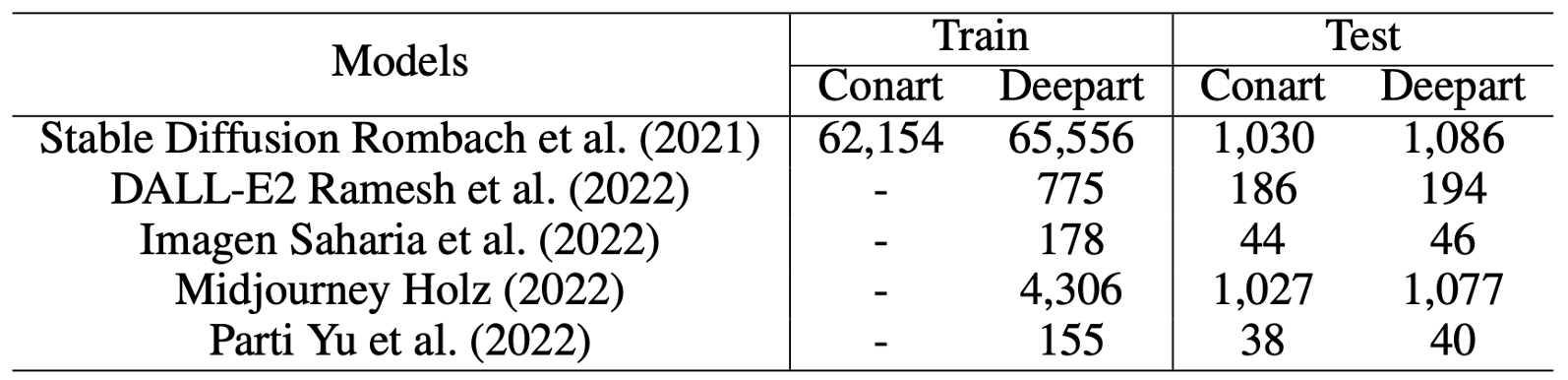
DDDB 未公开
https://arxiv.org/abs/2302.14475
-
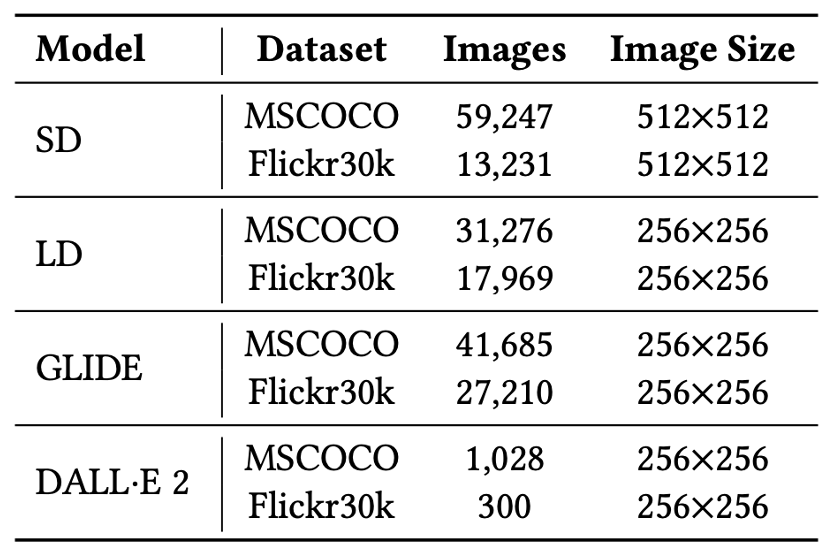
DeepArt 未公开
https://export.arxiv.org/pdf/2312.10407

-
DEFAKE 未公开
https://github.com/zeyangsha/De-Fake
20k real image for training + 10k real images for testing
2024
- COCOFake
https://github.com/aimagelab/COCOFake
COCOFake, containing about 1.2 million images generated from the original COCO image–caption pairs using two recent text-to-image diffusion models, namely Stable Diffusion v1.4 and v2.0.
- FOSID
https://github.com/mever-team/fosid
https://zenodo.org/records/13648239

- D^3
https://aimagelab.ing.unimore.it/imagelab/page.asp?IdPage=57
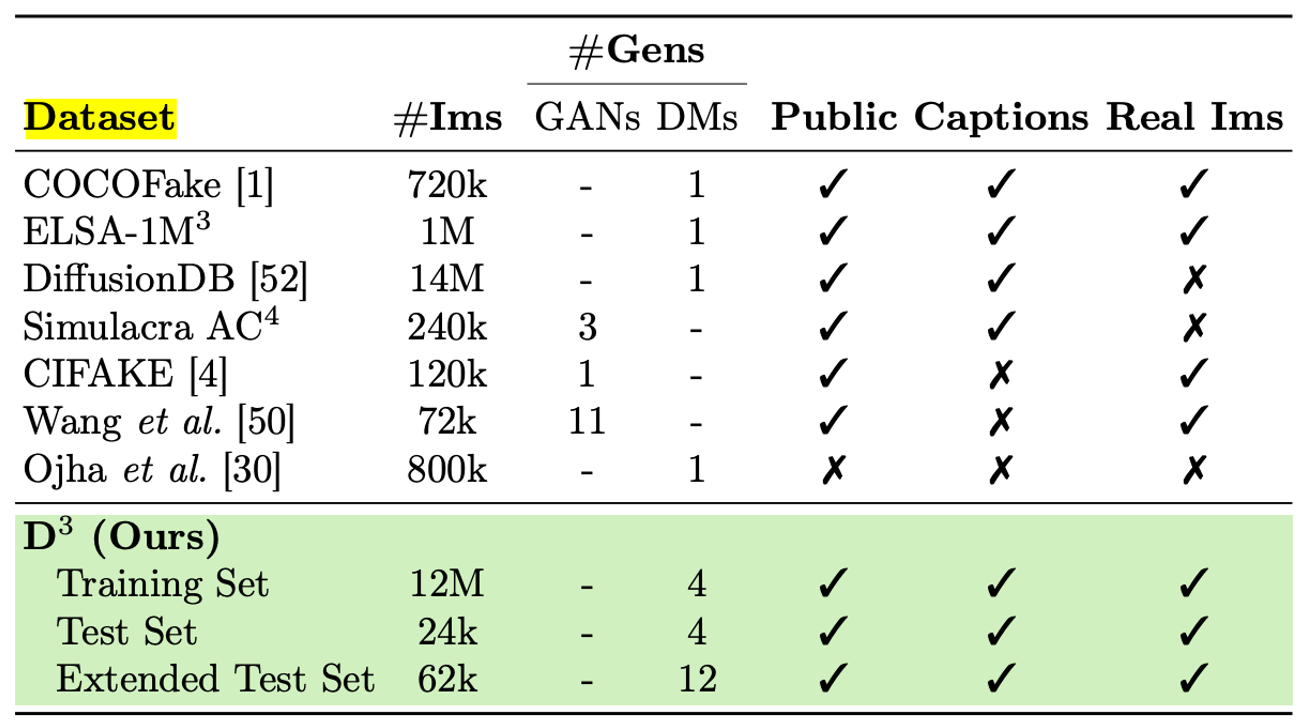
The Diffusion-generated Deepfake Detection (D3) Dataset is a comprehensive collection designed for large-scale deepfake detection. It includes 9.2 million generated images, created using four state-of-the-art diffusion model generators. Each image is generated based on realistic textual descriptions from the LAION-400M dataset.
We generate a comprehensive dataset that focuses on images generated by diffusion models and encompasses a collection of 9.2 million images produced by using four different generators.
Generators: Stable Diffusion 1.4, Stable Diffusion 2.1, Stable Diffusion XL, and DeepFloyd IF
Consequently, we generate and release the Diffusion-generated Deepfake Detection (D3 ) dataset containing 2.3 million records, each composed of a real image coming from LAION-400M [44] dataset and images from four generators, for a total of 9.2 million generated images. To verify the generation capabilities of deepfake detection methods to unseen generators, we also collect a challenging test set composed of 4.8k real images, each paired with 12 fake images generated by as many diffusion-based generators.
With the aim of increasing the variance of the dataset, images have been generated with different aspect ratios, i.e. 256x256, 512x512, 640×480, and 640×360. Moreover, to mimic the distribution of real images, we also employ a variety of encoding and compression methods (BMP, GIF, JPEG, TIFF, PNG). In particular, we closely follow the distribution of encoding methods of LAION itself, therefore favoring the presence of JPEG-encoded images.
-
ImagiNet
https://github.com/delyan-boychev/imaginet
https://huggingface.co/datasets/delyanboychev/imaginet
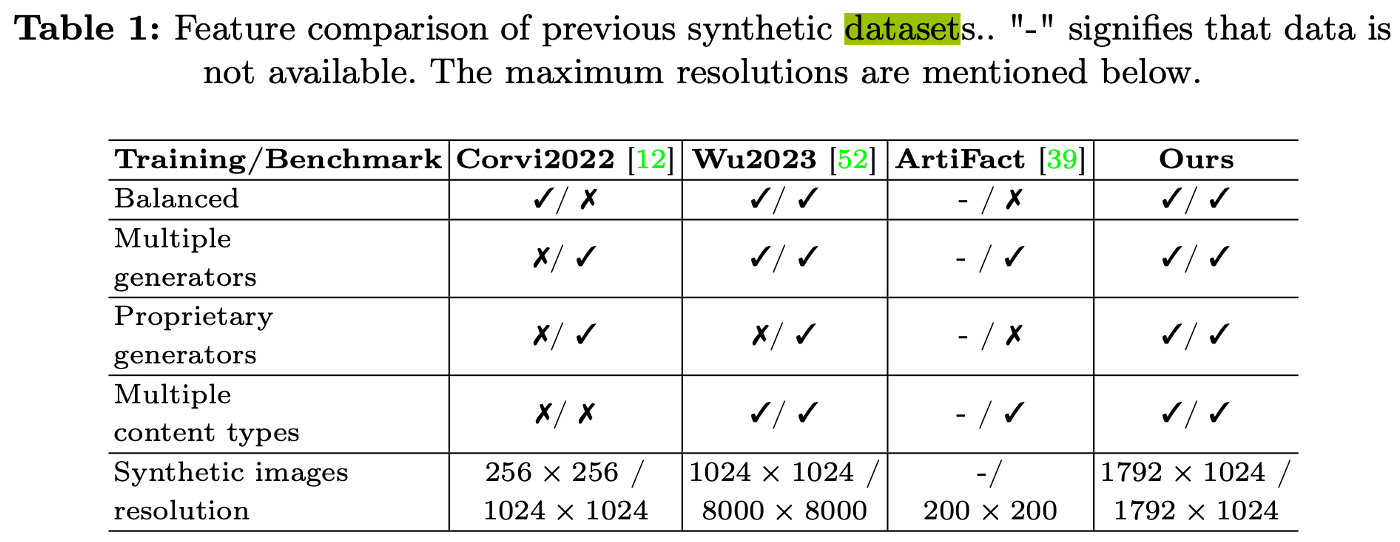
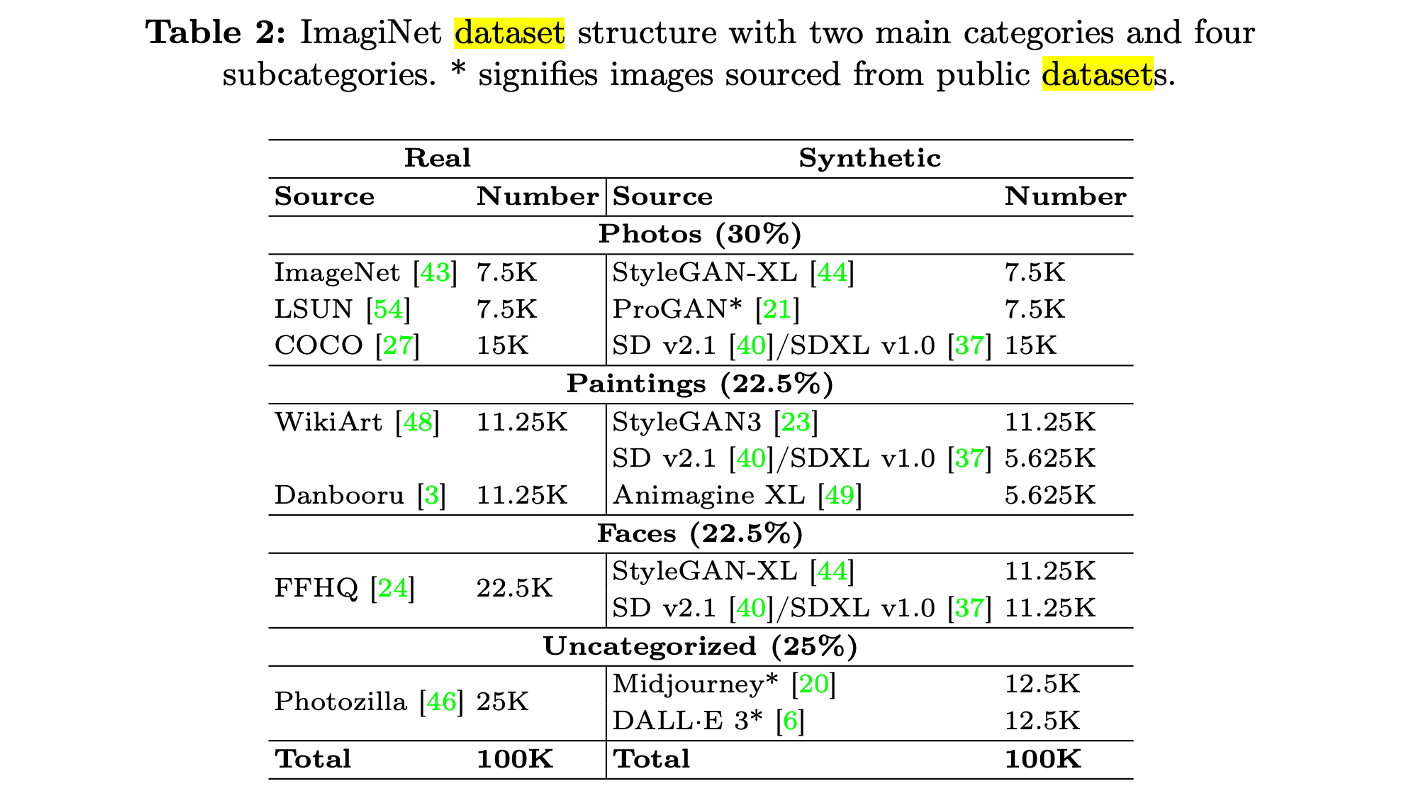
To support the development of defensive methods, we introduce ImagiNet, a high-resolution and balanced dataset for synthetic image detection, designed to mitigate potential biases in existing resources. It contains 200k examples, spanning four content categories: photos, paintings, faces, and uncategorized. Synthetic images are produced with open-source and proprietary generators, whereas real counterparts of the same content type are collected from public datasets.
-
AntifakePrompt
https://github.com/nctu-eva-lab/AntifakePrompt
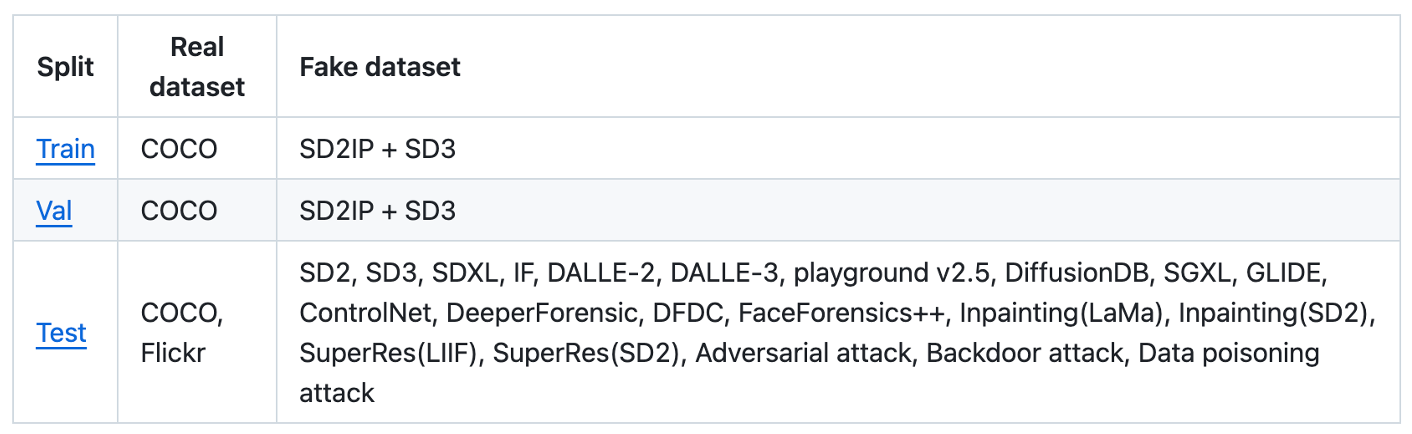
We conduct full-spectrum experiments on datasets from a diversity of 3 held-in and 20 held-out generative models, covering modern text-to-image generation, image editing and adversarial image attacks.
Real datasets. We use Microsoft COCO (COCO) (Lin et al. 2014) dataset and Flickr30k (Young et al. 2014) dataset. In our work, we selected 90K images, with shorter sides greater than 224, from COCO dataset for the real images in the training dataset. Moreover, to assess the generalizability of our method over various real images, we additionally select 3K images from Flickr30k dataset to form a held-out testing dataset, adhering to the same criterion of image size. (93k)
Fake image for training: 150k;for testing:3k*21 = 63k
-
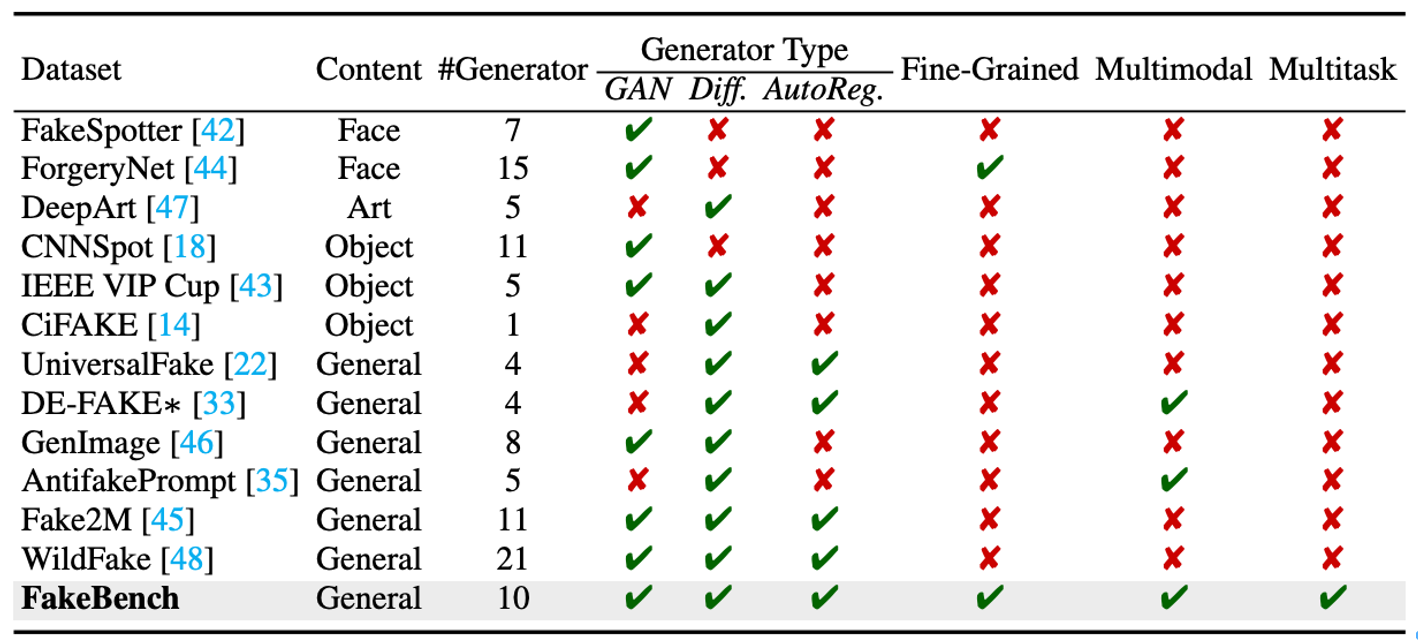
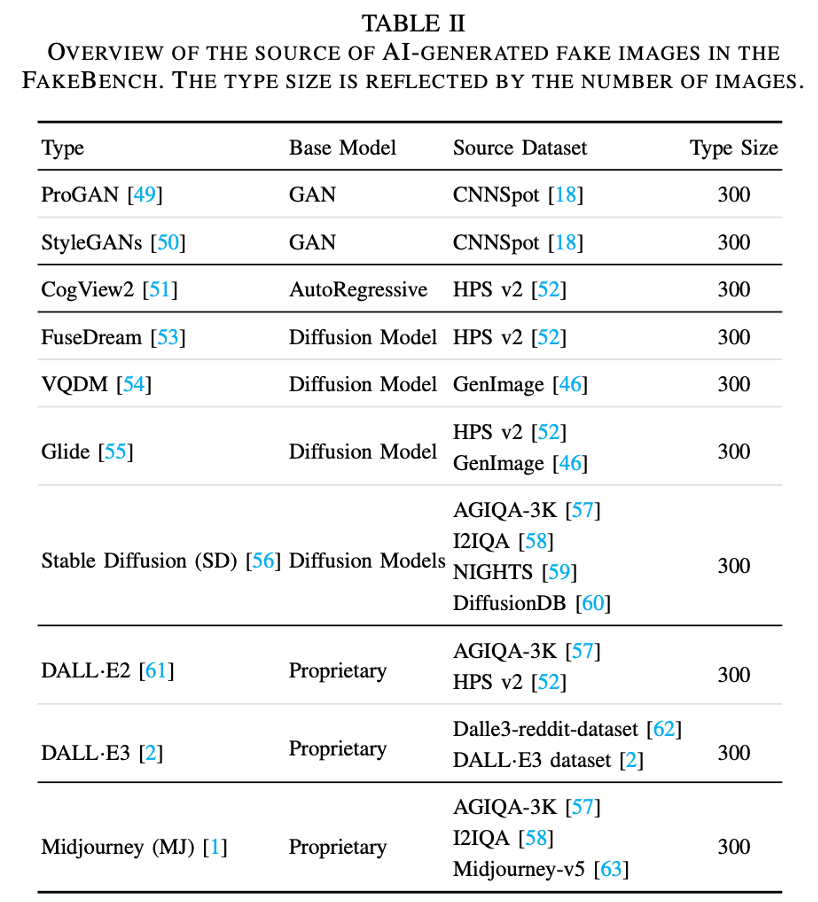
FakeBench
https://arxiv.org/abs/2404.13306
Regarding the genuine images, we sample 3,000 images from ImageNet [76] and DIV2K dataset [77].
-
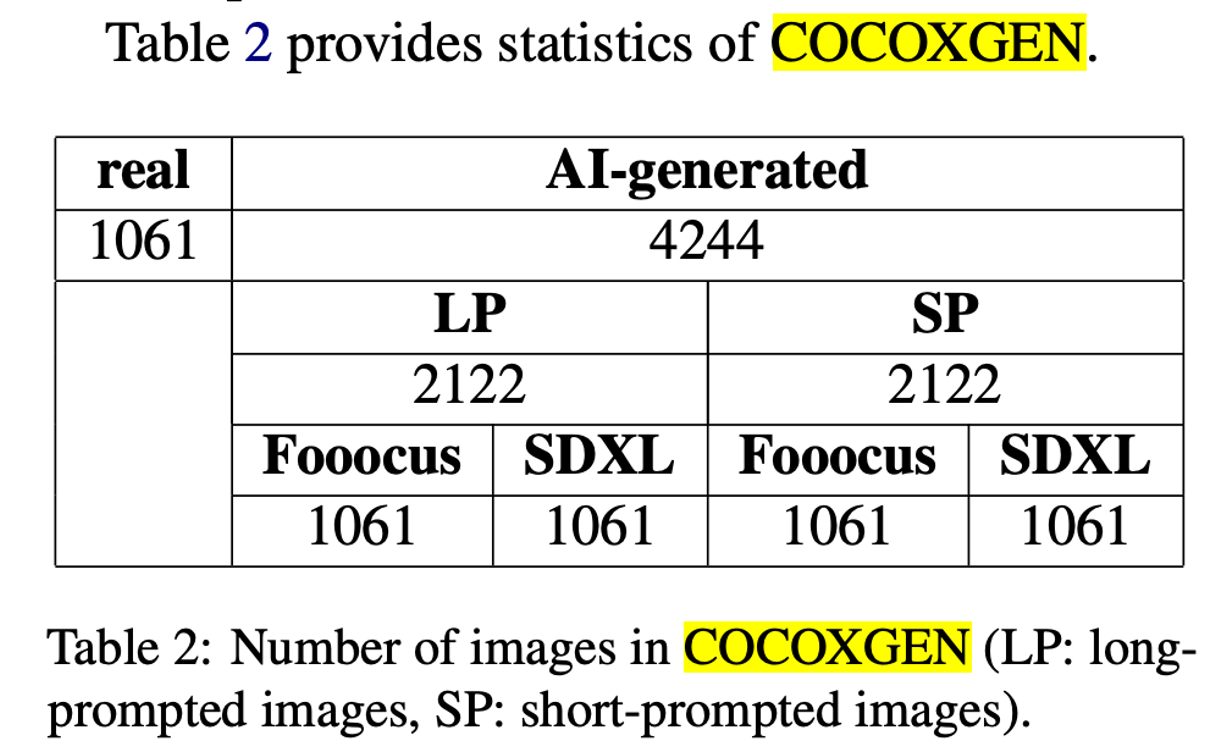
COCOXGEN
https://github.com/heikeadel/cocoxgen
COCOXGEN(COCO Extended With Generated Images), which consists of real photos from the COCO dataset as well as images generated with SDXL and Fooocus using prompts of two standardized lengths.
-
WildRF
https://github.com/barcavia/RealTime-DeepfakeDetection-in-the-RealWorld
We propose to improve deepfake evaluation and align it with real-world settings by introducing WildRF, a realistic benchmark consisting of images sourced from popular social platforms. Specifically, we manually collected real images and fake images using keywords and hashtags associated with the suitable content. Our protocol is to train on one platform (e.g., Reddit) and test the detector on real and fake images from other unseen platforms (e.g., Twitter and Facebook).

-
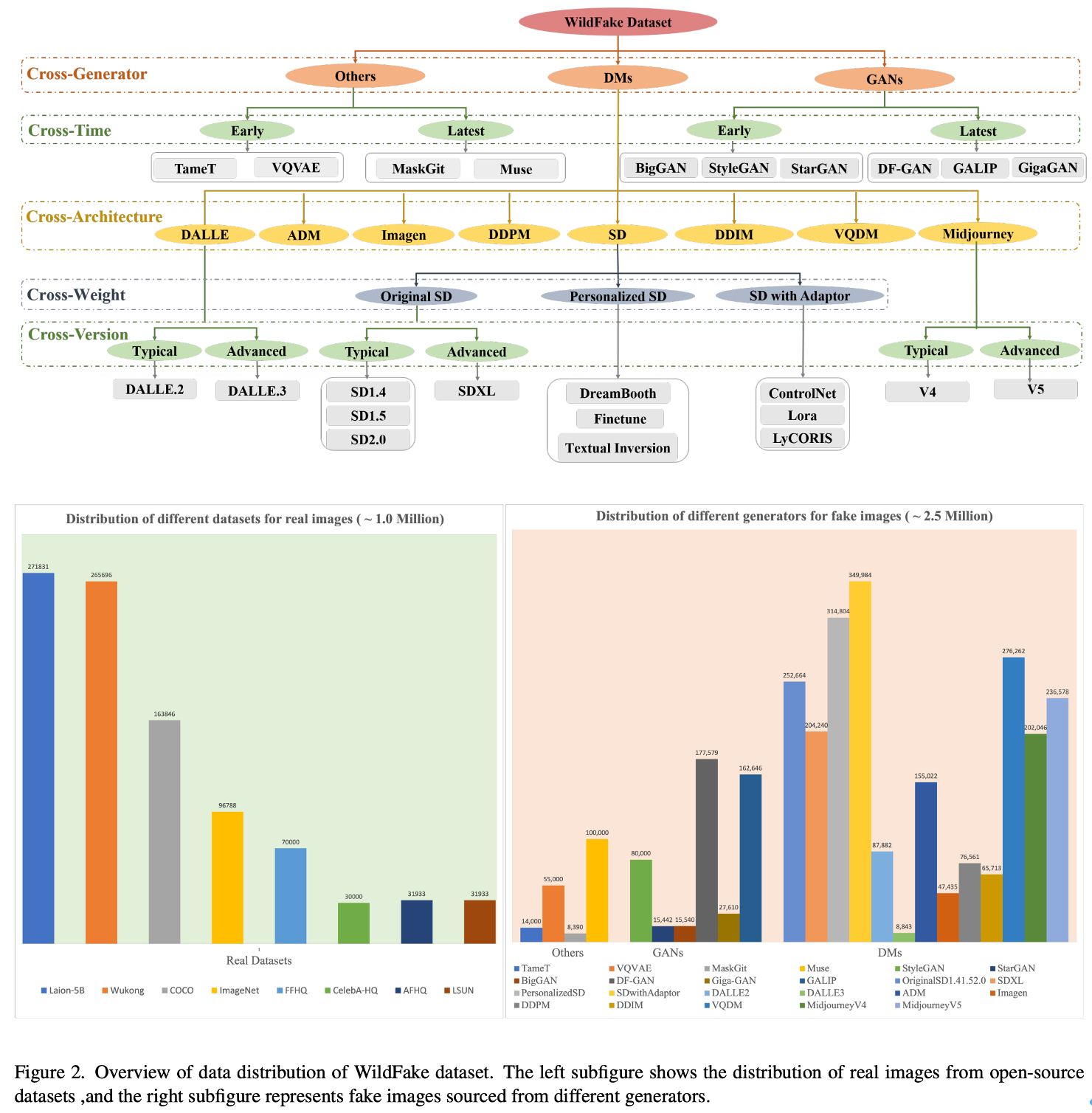
WildFake 未公开
https://arxiv.org/pdf/2402.11843

-
LSUNDB
https://github.com/jonasricker/diffusion-model-deepfake-detection
The main dataset used in this work is hosted on Zenodo. In total, the dataset contains 50k samples (256x256) for each of the following generators trained on LSUN Bedroom, divided into train, validation, and test set (39k/1k/10k).



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











