









论文解读:(TransE)Translating Embeddings for Modeling Multi-relational Data
表示学习是深度学习的基石,正式表示学习才能让深度学习可以自由的挖掘更深层次的特征。自word embedding(词嵌入表示)的提出,一种对结构化信息的三元组的表示学习也进入研究视野。TransE模型正是一种基于深度学习的知识表示方法,也是Trans系列的开山之作,虽然至今已有四五年,但仍然是学习知识表示的重要切入点。本文将分析TransE。
一、简要信息
| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 模型名称 | TransE |
| 2 | 所属领域 | 自然语言处理 |
| 3 | 研究内容 | 知识表示 |
| 4 | 核心内容 | knowledge embedding |
| 5 | GitHub源码 | https://github.com/thunlp/KB2E |
| 6 | 论文PDF | http://www.thespermwhale.com/jaseweston/papers/CR_paper_nips13.pdf) |
二、摘要与引言
我们思考了关于多元关系数据的实体和关系嵌入到低维度向量空间的问题。我们的目标是提出一个容易训练的简易模型,包括降低参数数量,且可以适用大规模数据集。由此我们提出TransE方法,可以将对关系的建模在低维度的实体表征空间上视为一种翻译操作。尽管这样很简单,这种假设证明是有效的,在两个知识库上的链接预测广泛的实验表明TransE模型超越了最佳模型。另外,它还可以成果的在大规模数据集上进行训练,包括1M个实体,25k个关系,超过17m个训练样本。
Multi-relational data(多元关系数据)是指有向图中包括头实体
h
h
h 、尾实体
t
t
t以及两者之间的关系类
l
l
l ,表示为三元组
(
h
,
l
,
t
)
(h,l,t)
(h,l,t) 。以这种三元组结构的任务有社交网络(social network)、推荐系统(recommender systems)、知识库(knowledge bases)。我们的任务则是聚焦于对知识库(WordNet、FreeBase)中多元关系数据进行建模,同时提供一种高效的工具用于知识补全,不需要额外的知识。
(1)构建多元关系数据:通常关系数据包括单一关系数据(single-relational data)和多元关系数据(multi-relational data)。单一关系通常是结构化的,可以直接进行简单的推理;多元关系则依赖于多种类型的实体和关系,因此需要一种通用的方法能够同时考虑异构关系。
(2)关系可以作为嵌入空间之间的翻译:我们提出一种基于能量机制的模型来训练低维度实体嵌入。在TransE中,关系类被表征为翻译嵌入式表征。如果实体对存在,则头实体与之对应的关系向量之和和尾实体尽可能相同。
三、相关工作与主要贡献
知识表示的相关工作包括:
(1)距离模型的结构表示(SE)。
结构表示中,每个实体用
k
k
k 维向量表示,头实体和尾实体分别为
h
,
t
h,t
h,t,关系
l
l
l 定义两个
k
∗
k
k*k
k∗k 维的方阵
L
1
,
L
2
L_1,L_2
L1,L2 ,因此则有目标函数
f
l
(
h
,
t
)
=
∣
h
L
1
−
t
L
2
∣
f_l(h,t)=|hL_1-tL_2|
fl(h,t)=∣hL1−tL2∣ ,目标则是当两个实体属于同一个三元组时,则两个向量
h
L
1
,
t
L
2
hL_1,tL_2
hL1,tL2 相近。
(2)神经张量网络(NTN):
神经张量网络则是在不同维度下将头尾实体向量联系起来,其定义一个得分函数:
s
(
h
,
l
,
t
)
=
h
T
L
t
+
l
1
T
h
+
l
2
T
t
s(h,l,t)=h^TLt+l_1^Th+l_2^Tt
s(h,l,t)=hTLt+l1Th+l2Tt
其中 L L L 为 k ∗ k k*k k∗k 维方阵, l 1 , l 2 l_1,l_2 l1,l2 为 k k k 维向量。这种得分函数包括三个部分之和,第一个部分 h T L t h^TLt hTLt 是一个双线性模型(LFM),其可以很好的描述两个实体之间的语义关系,且减少计算量。通常 L L L 被设计为一种对角矩阵(可以设计为单位矩阵,因为单位矩阵也是对角矩阵);后两个部分则是对两个实体的向量乘积,其中 l 1 = − l 2 l_1=-l_2 l1=−l2(可以理解为两个实体的差值)
四、算法模型详解(TransE)
给定一个训练集 S S S ,三元组表示为 ( h , l , t ) (h,l,t) (h,l,t) ,其中 h , t ∈ E h,t\in E h,t∈E, l ∈ L l\in L l∈L ,实体和关系的嵌入维度设为 k k k ,我们希望 h + l h+l h+l 与 t t t 能够尽可能的“相似”,因此定义一个能量函数:
d ( h + l , t ) = [ ( h + l ) − t ] 2 = ∣ ∣ h ∣ ∣ 2 2 + ∣ ∣ l ∣ ∣ 2 2 + ∣ ∣ t ∣ ∣ 2 2 − 2 ( h T t + l T ( t − h ) ) d(h+l,t)=[(h+l)-t]^2=||h||_2^2 + ||l||_2^2 + ||t||_2^2 - 2(h^Tt + l^T(t-h)) d(h+l,t)=[(h+l)−t]2=∣∣h∣∣22+∣∣l∣∣22+∣∣t∣∣22−2(hTt+lT(t−h))
可知这是一个单纯的欧氏距离,即两个目标向量对应坐标距离。
为了训练实体对嵌入和关系嵌入,需要引入负样本。因此我们的目标是尽可能对正样本中最小化
d
(
h
+
l
,
t
)
d(h+l,t)
d(h+l,t) ,负样本中则尽可能最大化
d
(
h
′
+
l
,
t
′
)
d(h'+l,t')
d(h′+l,t′) ,其中
h
′
,
t
′
h',t'
h′,t′ 表示不属于某个三元组的实体。,因此可以得出基于间距排序标准目标优化函数:
L = ∑ ( h , l , t ) ∈ S ∑ ( h ′ , l , t ′ ) ∈ S ( h , l , t ) ′ [ γ + d ( h + l , t ) − d ( h ′ + l , t ′ ) ] + L=\sum_{(h,l,t)\in S}\sum_{(h',l,t')\in S'_{(h,l,t)}}[\gamma + d(h+l,t)-d(h'+l,t')]_+ L=(h,l,t)∈S∑(h′,l,t′)∈S(h,l,t)′∑[γ+d(h+l,t)−d(h′+l,t′)]+
其中 [ x ] + [x]_+ [x]+ 表示 x x x 中正例的部分, γ > 0 \gamma >0 γ>0表示距离因子。 S ( h , l , t ) ′ = { ( h ′ , l , t ) ∣ h ′ ∈ E } ∪ { ( h , l , t ′ ) ∣ t ′ ∈ E } S'_{(h,l,t)}=\{(h',l,t)|h'\in E\}\cup\{(h,l,t')|t'\in E\} S(h,l,t)′={(h′,l,t)∣h′∈E}∪{(h,l,t′)∣t′∈E} 。
具体的实现算法如图所示:

(1)首先使用正态分布初始化参数,初始化关系表征向量和实体向量,并分别进行归一化;
(2)循环每一个epoch,从所有样本中划分batch形成
S
b
a
t
c
h
S_{batch}
Sbatch,初始化
T
b
a
t
c
h
T_{batch}
Tbatch 用于保存正样本和负样本;
(3)循环
S
b
a
t
c
h
S_{batch}
Sbatch 中每一个样本,并随机进行负采样生成对应的负样本,并累加到
T
b
a
t
c
h
T_{batch}
Tbatch 中;
(4)使用随机梯度下降训练目标函数,并调整三个向量;
五、实验及分析
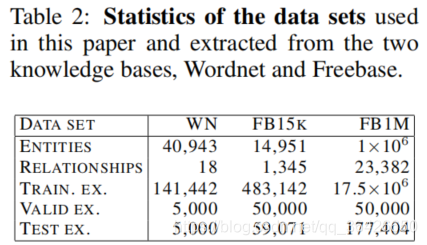
实验在两个数据集上分别完成,分别为WordNet和FreeBase。数据集情况如图所示:
评价指标:测试集中的头实体被移除,轮流换为字典中的任意一个实体,因此首先计算错误三元组的得分并升序保存得分;其次保存正确的实体得分。整个过程重复,同时去掉尾实体而不是头实体。我们报告预测排名和hits@10的平均值,即排名前10位的正确实体的占比,随后移除所有的错误元组,不管是出现在训练集和验证集或者测试集中的,这保证了所有的错误元组不属于数据集。
(1)链接预测(link precision)
论文中并没有详细说明链接预测的具体操作,实质上链接预测可以分为实体预测和关系预测。
(1)实体预测:给定已知的头实体(或尾实体)以及关系类,预测对应的尾实体(或头实体);
(2)关系预测:给定已知的头实体和尾实体,预测对应的关系。
作者首先完成的是实体预测。如下图表示不同数据集上各个模型的预测效果:
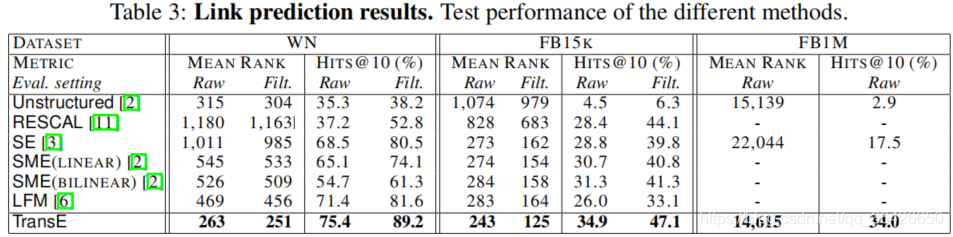
该图表示在测试集上,给定已知的实体和关系,预测另一个实体,经过升序排序后取最高的前10个三元组,并计算正确的占比,实验表明TransE效果最好。
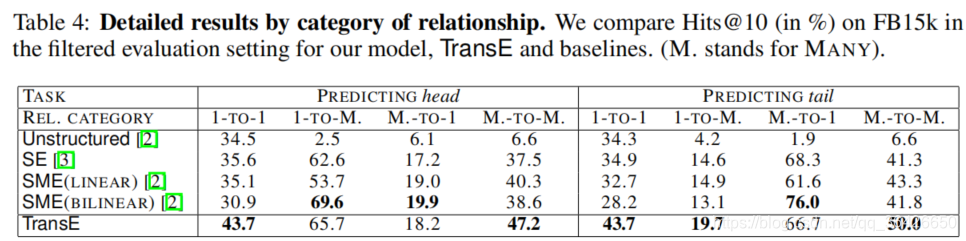
随后作者划分了四种类型的关系,分别为一对一、一对多、多对一、多对多,实验方法与前面相同,只是将测试集划分的更细,模型效果如下:
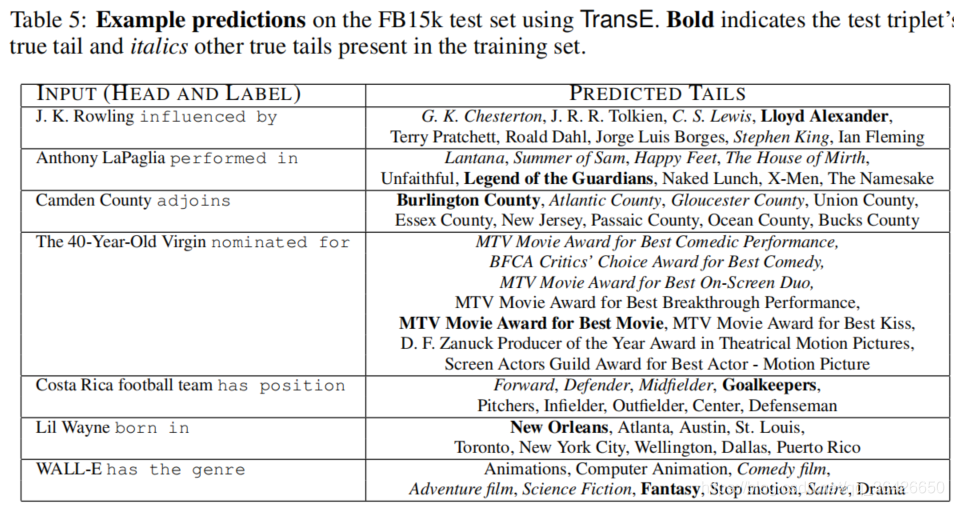
作者给出预测的样例,即给定头实体和关系类,从词典中预测尾实体:
最后,作者完成了根据少量的样本预测新关系:
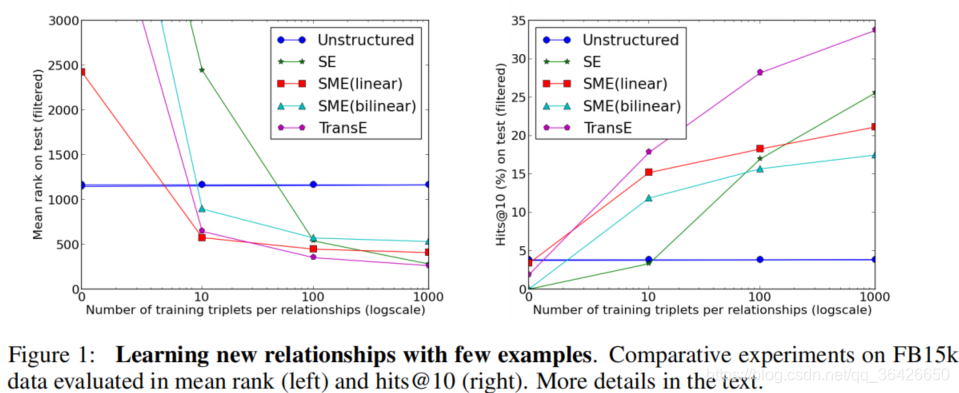
其中左图表示测试集中平均排名,右图表示Hits@top10中正确的比例。可以发现当训练集越大,TransE的平均排名下降的最快,而top10占比上升的最快,且对应结果均为最优。
六、论文总结与评价
论文结论原文,如图:

作者提出的模型简洁,且计算量小,可以支持链接预测、对大量数据集进行处理。不过也存在一系列问题:模型过于简单也是其弊端,不能够很好的处理更复杂的知识网络,换句话说是不能够有效充分的捕捉实体对间语义关系。
作者另外提出未来可以和文本结合学习,并提出一种使用TransE框架完成关系抽取任务的想法。
博客记录着学习的脚步,分享着最新的技术,非常感谢您的阅读,本博客将不断进行更新,希望能够给您在技术上带来帮助。


















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











