







 本文详细介绍了从Word Embedding到GPT的转变,探讨了GPT的预训练过程及其优缺点,指出其单向语言模型限制了其在某些任务上的表现。接着,文章介绍了BERT的诞生,它通过双向语言模型和Transformer解决了GPT的局限,并在11个NLP任务中取得最佳效果。BERT的普适性和优秀性能使其成为NLP领域的里程碑,预训练与Fine-tuning的两阶段模型成为新标准。
本文详细介绍了从Word Embedding到GPT的转变,探讨了GPT的预训练过程及其优缺点,指出其单向语言模型限制了其在某些任务上的表现。接着,文章介绍了BERT的诞生,它通过双向语言模型和Transformer解决了GPT的局限,并在11个NLP任务中取得最佳效果。BERT的普适性和优秀性能使其成为NLP领域的里程碑,预训练与Fine-tuning的两阶段模型成为新标准。
从Word Embedding到GPT
- GPT是“Generative Pre-Training”的简称,从名字看其含义是指的生成式的预训练。GPT也采用两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过Fine-tuning的模式解决下游任务。
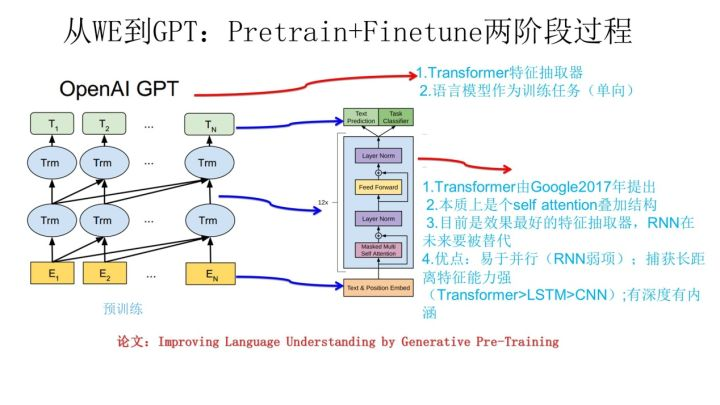
- 上图展示了GPT的预训练过程,其实和ELMO是类似的,主要不同在于两点:首先,特征抽取器不是用的RNN,而是用的Transformer,上面提到过它的特征抽取能力要强于RNN,这个选择很明显是很明智的;其次,GPT的预训练虽然仍然是以语言模型作为目标任务,但是采用的是单向的语言模型,所谓“单向”的含义是指:语言模型训练的任务目标是根据 单词的上下文去正确预测单词 , 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。ELMO在做语言模型预训练的时候,预测单词 同时使用了上文和下文,而GPT则只采用Context-before这个单词的上文来进行预测,而抛开了下文。这个选择现在看不是个太好的选择,原因很简单,它没有把单词的下文融合进来,这限制了其在更多应用场景的效果,比如阅读理解这种任务,在做任务的时候是可以允许同时看到上文和下文一起做决策的。如果预训练时候不把单词的下文嵌入到Word Embedding中,是很吃亏的。
- Transformer的学习见下篇介绍。RNN一直受困于其并行计算能力,这是因为它本身结构的序列性依赖导致的;CNN在NLP里一直没有形成主流,CNN的最大优点是易于做并行计算,所以速度快,但是在捕获NLP的序列关系尤其是长距离特征方面天然有缺陷,不是做不到而是做不好
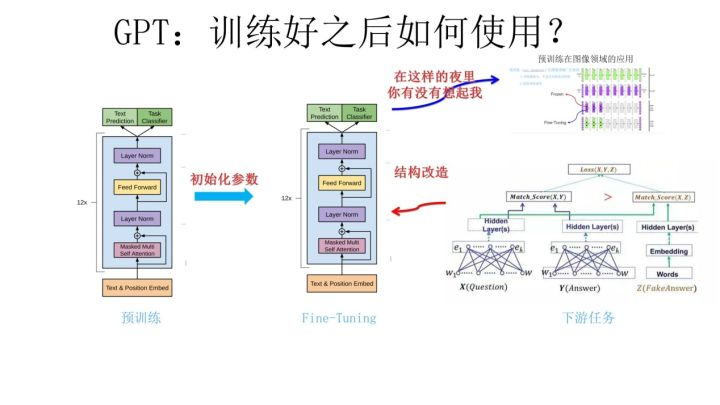
- 上图展示了GPT在第二阶段如何使用。首先,对于不同的下游任务来说,本来你可以任意设计自己的网络结构,现在不行了,你要向GPT的网络结构看齐,把任务的网络结构改造成和GPT的网络结构是一样的。然后,在做下游任务的时候,利用第一步预训练好的参数初始化GPT的网络结构,这样通过预训练学到的语言学知识就被引入到你手头的任务里来了,这是个非常好的事情。再次,你可以用手头的任务去训练这个网络,对网络参数进行Fine-tuning,使得这个网络更适合解决手头的问题。
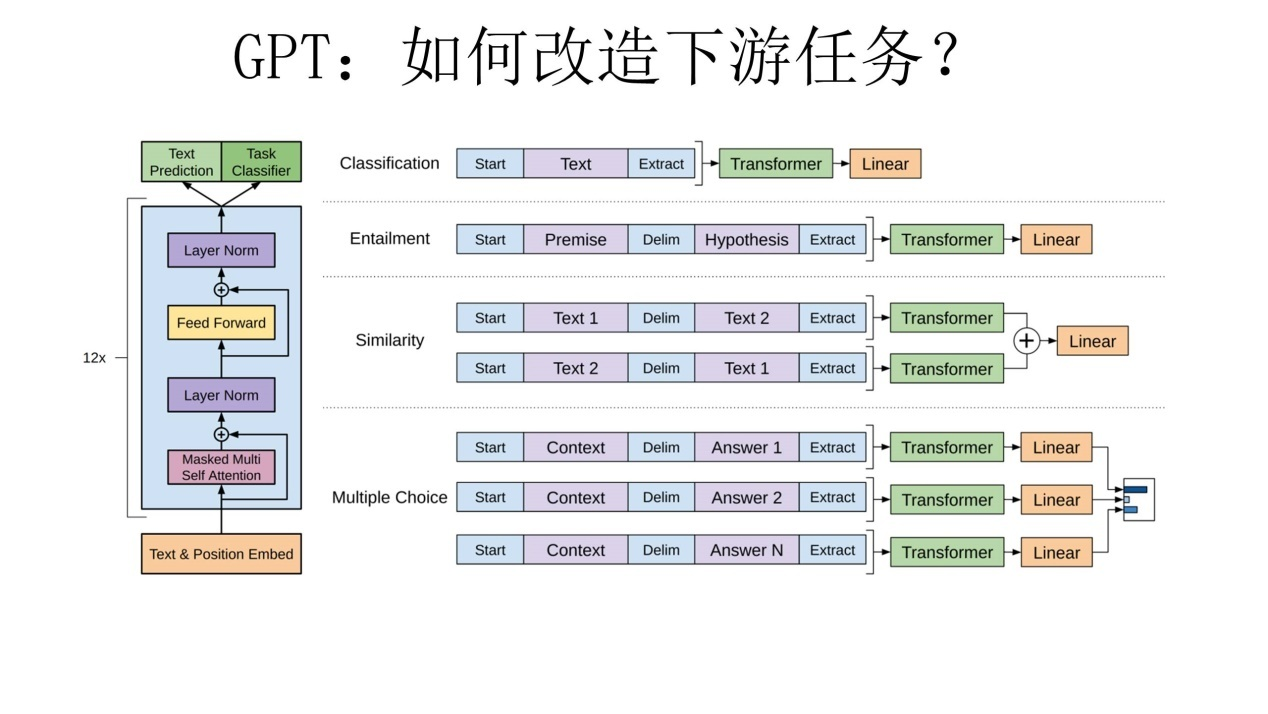
- PT论文给了一个改造施工图如上,其实也很简单:对于分类问题,不用怎么动,加上一个起始和终结符号即可;对于句子关系判断问题,比如Entailment,两个句子中间再加个分隔符即可;对文本相似性判断问题,把两个句子顺序颠倒下做出两个输入即可,这是为了告诉模型句子顺序不重要;对于多项选择问题,则多路输入,每一路把文章和答案选项拼接作为输入即可。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1598
1598

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









