







🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
我们将逐步编写一个非常简单的类似 GPT-4o 的多模态架构,它可以处理文本、图像、视频和音频,并且能够根据文本提示生成图像。帮助你详细理解逐步实现的过程。
项目代码
以下是这个简单多模态模型将具备的功能:
- 像语言模型(LLM)一样用文本聊天(使用 Transformer)
- 用图像、视频和音频聊天(使用 Transformer + ResNet)
- 根据文本提示生成图像(使用 Transformer + ResNet + 特征方法)
简单的 GPT-4o 架构
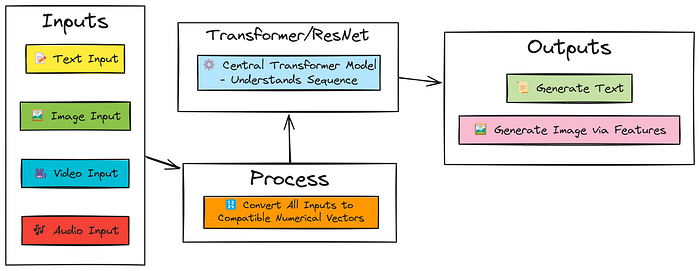
Tiny GPT-4o 架构
下文我们将实现以下内容:
- 从头开始编写了自己的 BPE 分词器。这让我们能够将文本分解成模型可以处理的小片段。
- 接着,我们构建了一个基本的文本模型(类似 GPT 的模型),使用 “爱丽丝梦游仙境” 的文本教它如何根据前面的单词预测下一个单词,这样它就能自己写出一些新的文本了。
- 然后,我们让模型变得多才多艺!我们把之前训练好的文本模型和 ResNet(一个图像识别模型)结合起来,让模型能够 “看到” 我们的简单彩色形状图像,并回答关于它们的问题,比如告诉我们要描述的颜色。
- 我们还规划了如何处理视频和音频。方法类似:把视频帧或音频波形转换成数字,给它们加上特殊的
<VID>或<AUD>标记,然后把它们混入输入序列。 - 最后,我们把方向反过来,尝试从文本提示生成图像。我们没有让模型直接画出像素(那太难了!),而是训练它根据文本(比如 “a blue square”)预测图像的 特征向量。然后,我们只要找出我们已知图像(红色正方形、蓝色正方形、绿色圆形)中哪个的特征向量和模型预测的最接近,就把它显示出来!
准备工作
我们将使用一些库,所以先导入它们。
# PyTorch 核心库,用于构建模型、张量和训练
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
# 图像处理和计算机视觉
import torchvision
import torchvision.transforms as transforms
from PIL import Image, ImageDraw # 用于创建/处理虚拟图像
# 标准 Python 库
import re # 用于正则表达式(在 BPE 单词拆分中使用)
import collections # 用于数据结构(如 Counter,在 BPE 频率计数中使用)
import math # 用于数学函数(在位置编码中使用)
import os # 用于与操作系统交互(文件路径、目录)
# 数值 Python(概念上用于音频波形生成)
import numpy as np
第一步是创建一个分词器,让我们开始编写代码吧。
BPE 分词是什么
在创建多模态语言模型或任何 NLP 任务中,分词是第一步,即将原始文本分解为更小的单元,称为标记(tokens)。
这些标记是机器学习模型处理的基本构建块(例如,单词、标点符号)。
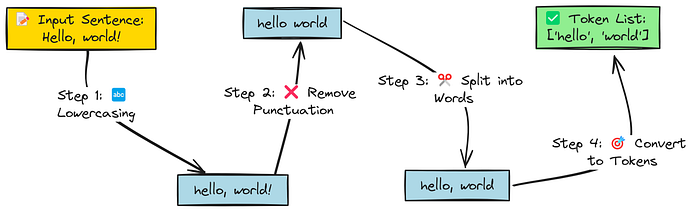
最简单的分词过程
最简单的分词方式是将文本转换为小写,移除标点符号,然后将文本拆分为单词列表。
然而,这种方法有一个缺点。如果将每个独特的单词都视为一个标记,词汇表的大小可能会变得过大,尤其是在包含许多单词变体的语料库中(例如,“run”、“runs”、“running”、“ran”、“runner”)。这会显著增加内存和计算需求。
与简单的基于单词的分词不同,BPE(Byte Pair Encoding,字节对编码) 是一种子词(subword)分词技术,它有助于控制词汇表大小,同时有效地处理罕见单词。
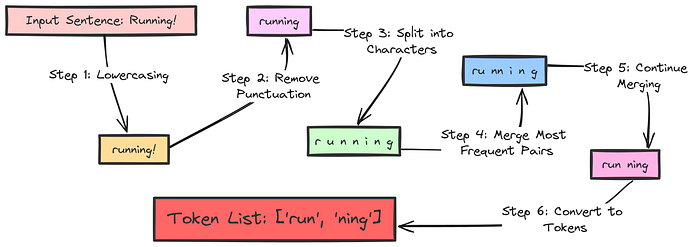
BPE 解释
在 BPE 中,最初将输入句子拆分为单个字符。然后,将频繁相邻的字符对合并为新的子词。这个过程会一直持续,直到达到所需的词汇表大小。
因此,常见的子词部分会被重复使用,模型可以通过将从未遇到过的单词拆分为更小的、已知的子词单元来处理它们。
GPT-4 使用 BPE 作为其分词组件。现在我们已经对 BPE 进行了高层次的概述,让我们开始编写代码。
编写 BPE 分词器代码
我们将使用刘易斯·卡罗尔的《爱丽丝梦游仙境》中的一个小片段作为训练 BPE 分词器的数据。
使用更大、更多样化的语料库可以得到更通用的分词器,但这个较小的示例让我们更容易追踪整个过程。
# 定义用于训练 BPE 分词器的原始文本语料库
corpus_raw = """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain would be worth the trouble of getting up and
picking the daisies, when suddenly a White Rabbit with pink eyes ran
close by her.
"""
接下来,我们需要将整个语料库转换为小写,以确保在频率计数和合并过程中,相同单词的不同大小写形式(例如,“Alice” 和 “alice”)被视为同一个单元。
# 将原始语料库转换为小写
corpus_lower = corpus_raw.lower()
现在我们已经将语料库转换为小写。
接下来,我们需要将文本拆分为其基本组成部分。虽然 BPE 是基于子词的,但它通常从单词级别开始(包括标点符号)。
# 定义用于拆分单词和标点的正则表达式
split_pattern = r'\w+|[^\s\w]+'
# 使用正则表达式将小写的语料库拆分为初始的标记列表
initial_word_list = re.findall(split_pattern, corpus_lower)
print(f"语料库被拆分为 {
len(initial_word_list)} 个初始单词/标记。")
# 显示前三个标记
print(f"前三个初始标记:{
initial_word_list[:3]}")
#### 输出结果 ####
语料库被拆分为 127 个初始单词/标记。
前三个初始标记:['alice', 'was', 'beginning']
我们的语料库被拆分为 127 个标记,你可以看到语料库的前三个标记。让我们了解一下代码中发生了什么。
我们使用正则表达式 r'\w+|[^\s\w]+' 通过 re.findall:
\w+:匹配一个或多个字母数字字符(字母、数字和下划线)。这可以捕获标准单词。|:作为 OR 运算符。[^\s\w]+:匹配一个或多个既不是空白字符(\s)也不是单词字符(\w)的字符。这可以捕获标点符号,如逗号、句号、冒号、引号、括号等,将它们作为单独的标记。
结果是一个字符串列表,其中每个字符串是一个单词或标点符号。
BPE 的核心原则是合并 最频繁 的对。因此,我们需要知道每个独特初始单词/标记在语料库中出现的频率。collections.Counter 可以高效地创建一个类似字典的对象,将每个独特项(单词/标记)映射到其计数。
# 使用 collections.Counter 统计 initial_word_list 中各项的频率
word_frequencies = collections.Counter(initial_word_list)
# 显示频率最高的 3 个标记及其计数
print("频率最高的 3 个标记:")
for token, count in word_frequencies.most_common(3):
print(f" '{
token}': {
count}")
#### 输出结果 ####
频率最高的 3 个标记:
the: 7
of: 5
her: 5
频率最高的标记是 “the”,在我们的小语料库中出现了 7 次。
BPE 训练基于符号序列。我们需要将独特单词/标记列表转换为这种格式。对于每个独特单词/标记:
-
将其拆分为单独字符的列表。
-
在该列表末尾追加一个特殊的单词结束符号(我们使用
</w>)。这个</w>标记至关重要:-
它防止 BPE 在不同单词之间合并字符。例如,“apples” 末尾的 “s” 不应与 “and” 开头的 “a” 合并。
-
它还允许算法将常见的单词结尾作为独立的子词单元进行学习(例如,“ing”、“ed”、“s”)。
-
我们将这种映射(原始单词 -> 字符列表 + 单词结束符号)存储在一个字典中。
# 定义特殊的单词结束符号 "</w>"
end_of_word_symbol = '</w>'
# 创建一个字典,用于存储语料库的初始表示形式
# 键:原始独特单词/标记,值:字符列表 + 单词结束符号
initial_corpus_representation = {
}
# 遍历频率计数器识别的独特单词/标记
for word in word_frequencies:
# 将单词字符串拆分为字符列表
char_list = list(word)
# 在列表末尾追加单词结束符号
char_list.append(end_of_word_symbol)
# 将该列表存储到字典中,原始单词作为键
initial_corpus_representation[word] = char_list
那么,让我们打印出 “beginning” 和 “.” 的表示形式。
# 显示一个样本单词的表示形式
example_word = 'beginning'
if example_word in initial_corpus_representation:
print(f"'{
example_word}' 的表示形式:{
initial_corpus_representation[example_word]}")
example_punct = '.'
if example_punct in initial_corpus_representation:
print(f"'{
example_punct}' 的表示形式:{
initial_corpus_representation[example_punct]}")
#### 输出结果 ####
创建了初始语料库表示形式,包含 86 个独特单词/标记。
'beginning' 的表示形式:['b', 'e', 'g', 'i', 'n', 'n', 'i', 'n', 'g', '</w>']
'.' 的表示形式:['.', '</w>']
BPE 算法从语料库的初始表示形式中所有单独符号开始构建词汇表。
这包括原始文本中的所有独特字符 加上 我们添加的特殊 </w> 符号。使用 Python set 自动处理唯一性 —— 多次添加现有字符不会产生任何效果。
# 初始化一个空集合,用于存储独特的初始符号(词汇表)
initial_vocabulary = set()
# 遍历语料库的初始表示形式中的字符列表
for word in initial_corpus_representation:
# 获取当前单词的符号列表
symbols_list = initial_corpus_representation[word]
# 将该符号列表中的符号添加到词汇表集合中
# `update` 方法会将可迭代对象(如列表)中的所有元素添加到集合中
initial_vocabulary.update(symbols_list)
# 虽然 update 应该已经添加了 '</w>',但为了确保,我们可以显式添加它
# initial_vocabulary.add(end_of_word_symbol)
print(f"初始词汇表创建完成,包含 {
len(initial_vocabulary)} 个独特符号。")
# 可选:显示初始词汇表符号的排序列表
print(f"初始词汇表符号:{
sorted(list(initial_vocabulary))}")
#### 输出结果 ####
初始词汇表创建完成,包含 31 个独特符号。
初始词汇表符号:["'", '(', ')', ',', '-', '.', ':', '</w>', ...]
所以,我们的小语料库总共有 31 个独特符号,我打印了一些出来给你看看。
现在,进入 BPE 的核心学习阶段。我们将迭代地找到当前语料库表示形式中 最频繁的相邻符号对,并将它们合并为一个新的单一符号(子词)。
这个过程构建了子词词汇表和有序的合并规则列表。
在开始循环之前,我们需要:
num_merges:定义合并操作的次数,控制最终词汇表的大小。较大的值可以捕获更复杂的子词。learned_merges:一个字典,用于存储合并规则,键为符号对元组,值为合并优先级。current_corpus_split:保存在合并过程中修改的语料库状态的副本,初始化为原始语料库表示形式的副本。current_vocab:保存增长中的词汇表,初始化为原始词汇表的副本。
# 定义期望的合并操作次数
# 这决定了要在初始字符词汇表中添加多少个新的子词标记
num_merges = 75 # 在这个例子中,我们使用 75 次合并
# 初始化一个空字典,用于存储学习到的合并规则
# 格式:{ (symbol1, symbol2): 合并优先级索引 }
learned_merges = {
}
# 创建语料库表示形式的工作副本,以便在训练过程中进行修改
current_corpus_split = initial_corpus_representation.copy()
# 创建词汇表的工作副本,以便在训练过程中进行修改
current_vocab = initial_vocabulary.copy()
print(f"训练状态初始化完成。目标合并次数:{
num_merges}")
print(f"初始词汇表大小:{
len(current_vocab)}")
#### 输出结果 ####
训练状态初始化完成。目标合并次数:75
初始词汇表大小:31
现在,我们将迭代 num_merges 次。在循环内部,我们执行 BPE 的核心步骤:统计对、找到最佳对、存储规则、创建新符号、更新语料库表示形式和更新词汇表。
# 开始主循环,迭代指定的合并次数
print(f"\n--- 开始 BPE 训练循环 ({
num_merges} 次迭代) ---")
for i in range(num_merges):
print(f"\n第 {
i + 1}/{
num_merges} 次迭代")
# 统计符号对的频率
pair_counts = collections.Counter()
for word, freq in word_frequencies.items():
symbols = current_corpus_split[word]
for j in range(len(symbols) - 1):
pair = (symbols[j], symbols[j+1])
pair_counts[pair] += freq
if not pair_counts:
print("没有更多可合并的对了。提前停止。")
break
# 找到最佳对
best_pair = max(pair_counts, key=pair_counts.get)
print(f"找到最佳对:{
best_pair},频率为 {
pair_counts[best_pair]}")
# 存储合并规则
learned_merges[best_pair] = i
# 创建新符号
new_symbol = "".join(best_pair)
# 更新语料库表示形式
next_corpus_split = {
}
for word in current_corpus_split:
old_symbols = current_corpus_split[word]
new_symbols = []
k = 0
while k < len(old_symbols):
if k < len(old_symbols) - 1 and (old_symbols[k], old_symbols[k+1]) == best_pair:
new_symbols.append(new_symbol)
k += 2
else:
new_symbols.append(old_symbols[k])
k += 1
next_corpus_split[word] = new_symbols
current_corpus_split = next_corpus_split
# 更新词汇表
current_vocab.add(new_symbol)
# 最终输出
print(f"\n--- BPE 训练循环完成,共进行了 {
i + 1} 次迭代 ---")
final_vocabulary = current_vocab
final_learned_merges = learned_merges
final_corpus_representation = current_corpus_split
当我们开始 BPE 的训练循环时,它将运行 75 次迭代,因为我们设置了合并次数为 75。让我们看看其中一次迭代的输出是什么样的:
#### 输出结果(单次迭代) ####
--- 开始 BPE 训练循环 (75 次迭代) ---
第 1/75 次迭代
第 2.3 步:计算符号对的统计信息...
计算了 156 个独特对的频率。
第 2.4 步:检查是否存在对...
找到了对,继续训练。
第 2.5 步:找到最频繁的对...
找到最佳对:('e', '</w>'),频率为 21
第 2.6 步:存储合并规则(优先级:0)...
已存储:('e', '</w>') -> 优先级 0
第 2.7 步:从最佳对创建新符号...
创建了新符号:'e</w>'
第 2.8 步:更新语料库表示形式...
已更新所有单词的语料库表示形式。
第 2.9 步:更新词汇表...
将 'e</w>' 添加到词汇表中。当前大小:32
在我们的训练中,每次迭代都涉及相同的步骤,例如计算对的频率、找到最佳对等,就像我们之前看到的那些步骤一样。
让我们看看我们的语料库的词汇表大小。
print(f"最终词汇表大小:{
len(final_vocabulary)} 个标记")
#### 输出结果 ####
最终词汇表大小:106 个标记
现在我们的 BPE 训练已经完成啦!很有用的是,看看训练语料库中的特定单词在经过所有合并操作后的表示形式。
# 列出一些我们希望看到有趣分词的单词
example_words_to_inspect = ['beginning', 'conversations', 'sister', 'pictures', 'reading', 'alice']
for word in example_words_to_inspect:
if word in final_corpus_representation:
print(f" '{
word}': {
final_corpus_representation[word]}")
else:
print(f" '{
word}': 未在原始语料库中找到(如果从语料库中选择,不应发生这种情况)。")
好的,我将继续翻译剩余的内容,确保完整性和准确性。以下是翻译后的剩余部分:
---
#### 输出结果 ####
最终单词示例的表示形式:
'beginning': ['b', 'e', 'g', 'in', 'n', 'ing</w>']
'conversations': ['conversati', 'on', 's</w>']
'sister': ['sister</w>']
'pictures': ['pictures</w>']
'reading': ['re', 'ad', 'ing</w>']
'alice': ['alice</w>']
这展示了根据学习到的 BPE 规则,已知单词的最终标记序列。
但我们还需要一个样本句子或文本,该文本在训练期间 BPE 模型可能没有见过,以展示其对新输入的分词能力,可能包含原始语料库中未出现的单词或变体。
```python
# 定义一个新的文本字符串,用于使用学习到的 BPE 规则进行分词
# 这个文本包含训练中见过的单词('alice', 'pictures')
# 以及可能未见过的单词或变体('tiresome', 'thought')
new_text_to_tokenize = "Alice thought reading was tiresome without pictures."
当我们对未见过的文本执行相同的训练循环时,我们得到了以下分词数据:
print(f"原始输入文本:'{
new_text_to_tokenize}'")
print(f"分词输出({
len(tokenized_output)} 个标记):{
tokenized_output}")
#### 输出结果 ####
原始输入文本:'Alice thought reading was tiresome without pictures.'
分词输出(21 个标记):['alice</w>', 'thou', 'g', 'h',
't</w>', 're', 'ad', 'ing</w>',
'was</w>', 'ti', 're', 's', 'o', 'm',
'e</w>', 'wi', 'thou', 't</w>',
'pictures</w>', '.', '</w>']
啊,终于,我们完成了 BPE 分词器的整个过程。现在,我们的文本已经表示为子词标记的序列。
但仅仅有标记还不够,我们需要一个能够理解这些序列中的模式和关系的模型,以便生成有意义的文本。
接下来,我们需要构建一个文本生成的语言模型(LLM),由于 GPT-4 基于 Transformer 架构,我们将采用相同的方法。
这种架构在论文 “Attention Is All You Need” 中被首次提出。有许多 Transformer 模型的实现,我们将一边编写代码,一边理解理论,以便掌握 Transformer 模型的核心逻辑。
仅解码器的 Transformer
我们的目标是构建一个语言模型,能够根据前面的标记预测序列中的下一个标记。通过反复预测并追加标记,模型可以生成新的文本。我们将专注于一个 仅解码器的 Transformer,类似于 GPT 这类模型。
为了简化 Transformer 架构本身的演示,我们将切换回 字符级分词。
这意味着原始语料库中的每个独特字符都将是一个单独的标记。
虽然 BPE 通常更强大,但字符级分词可以保持词汇表较小,并且让我们专注于模型的机制。
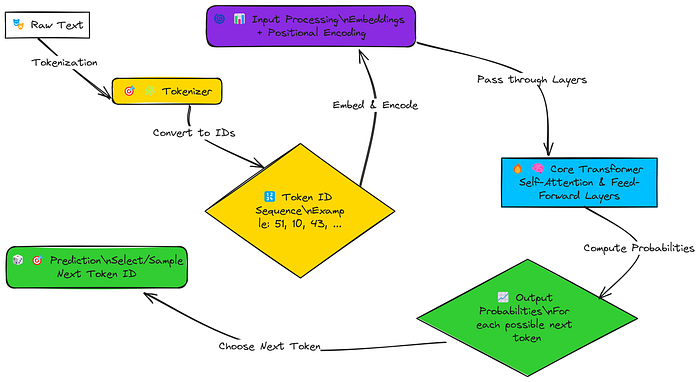
简化版 LLM 创建流程
因此,我们的 Transformer 模型的工作流程如下:
- 文本转标记:将输入文本分解为更小的部分(标记)。
- 标记转数字:将每个标记转换为唯一的数字(ID)。
- 添加意义和位置:将这些数字转换为有意义的向量(嵌入),并添加位置信息,以便模型知道单词的顺序。
- 核心处理:Transformer 的主要层使用 “自注意力” 分析所有单词之间的关系。
- 猜测下一个单词:计算词汇表中每个单词成为下一个单词的概率。
- 选择最佳猜测:根据这些概率选择最有可能的单词(或采样一个)作为输出。
我们将使用之前的 “爱丽丝梦游仙境” 语料库。
# 定义用于训练的原始文本语料库
corpus_raw = """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain would be worth the trouble of getting up and
picking the daisies, when suddenly a White Rabbit with pink eyes ran
close by her.
"""
现在,让我们创建我们的字符词汇表及其映射。
# 找出原始语料库中的所有独特字符
chars = sorted(list(set(corpus_raw)))
vocab_size = len(chars)
# 创建字符到整数的映射(编码)
char_to_int = {
ch:i for i,ch in enumerate(chars) }
# 创建整数到字符的映射(解码)
int_to_char = {
i:ch for i,ch in enumerate(chars) }
print(f"创建了字符词汇表,大小为:{
vocab_size}")
print(f"词汇表:{
''.join(chars)}")
#### 输出结果 ####
创建了字符词汇表,大小为:36
词汇表:
'(),-.:?ARSWabcdefghiklmnoprstuvwy
有了这些映射,我们将整个文本语料库转换为一个数字序列(标记 ID)。
# 将整个语料库编码为一个整数 ID 列表
encoded_corpus = [char_to_int[ch] for ch in corpus_raw]
# 将列表转换为 PyTorch 张量
full_data_sequence = torch.tensor(encoded_corpus, dtype=torch.long)
print(f"将语料库编码为张量,形状为:{
full_data_sequence.shape}")
#### 输出结果 ####
将语料库编码为张量,形状为:torch.Size([593])
输出告诉我们,我们的模型只需要学习大约 36 个独特的字符(包括空格、标点符号等)。
这就是我们的 vocab_size,第二行显示了确切包含哪些字符。
有了这些映射,我们将整个文本语料库转换为一个数字序列(标记 ID)。
# 将整个语料库编码为一个整数 ID 列表
encoded_corpus = [char_to_int[ch] for ch in corpus_raw]
# 将列表转换为 PyTorch 张量
full_data_sequence = torch.tensor(encoded_corpus, dtype=torch.long)
print(f"将语料库编码为张量,形状为:{
full_data_sequence.shape}")
### 输出结果 ####
将语料库编码为张量,形状为:torch.Size([593])
这确认了我们的 593 个字符的文本现在被表示为一个单一的 PyTorch 张量(一个长度为 593 的数字列表),准备好供模型使用。
在构建模型之前,我们需要设置一些配置值,即超参数。这些控制 Transformer 的大小和行为。
# 定义模型超参数(使用计算出的 vocab_size)
# vocab_size = vocab_size # 已经定义过了
d_model = 64 # 嵌入维度(每个标记的向量大小)
n_heads = 4 # 注意力头的数量(并行注意力计算)
n_layers = 3 # 堆叠在一起的 Transformer 块的数量
d_ff = d_model * 4 # 前馈网络中的隐藏维度
block_size = 32 # 模型一次看到的最大序列长度
# dropout_rate = 0.1 # 为了简化,省略了 dropout
# 定义训练超参数
learning_rate = 3e-4
batch_size = 16 # 训练期间并行处理的序列数量
epochs = 5000 # 训练迭代次数
eval_interval = 500 # 打印损失的频率
# 设备配置
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 确保 d_model 能被 n_heads 整除
assert d_model % n_heads == 0, "d_model 必须能被 n_heads 整除"
d_k = d_model // n_heads # 每个头的键/查询/值的维度
print(f"超参数已定义:")
print(f" vocab_size: {
vocab_size}")
print(f" d_model: {
d_model}")
print(f" n_heads: {
n_heads}")
print(f" d_k (每个头的维度): {
d_k}")
print(f" n_layers: {
n_layers}")
print(f" d_ff: {
d_ff}")
print(f" block_size: {
block_size}")
print(f" learning_rate: {
learning_rate}")
print(f" batch_size: {
batch_size}")
print(f" epochs: {
epochs}")
print(f" 使用的设备:{
device}")
虽然 GPT-4 是一个闭源模型,我们无法获得其确切的参数值,但我们可以定义基本的参数值,以便轻松地进行复现。
#### 输出结果 ####
超参数已定义:
vocab_size: 36
d_model: 64
n_heads: 4
d_k (每个头的维度): 16
n_layers: 3
d_ff: 256
block_size: 32
learning_rate: 0.0003
batch_size: 16
epochs: 5000
使用的设备:cuda
我们看到了 vocab_size 为 36,嵌入维度 (d_model) 为 64,3 层,4 个注意力头,等等。它还确认了我们正在使用的设备(cuda 或 cpu),这会影响训练速度。
接下来,我们需要为模型创建输入和目标序列。模型通过预测下一个字符来学习。因此,我们需要创建输入序列 (x) 和对应的目标序列 (y),其中 y 仅仅是将 x 向右移动一个位置的序列。我们将在编码后的语料库中创建长度为 block_size 的重叠序列。
# 创建列表,用于保存所有可能的输入(x)和目标(y)序列
all_x = []
all_y = []
num_total_tokens = len(full_data_sequence)
for i in range(num_total_tokens - block_size):
x_chunk = full_data_sequence[i : i + block_size]
y_chunk = full_data_sequence[i + 1 : i + block_size + 1]
all_x.append(x_chunk)
all_y.append(y_chunk)
# 将列表堆叠成张量
train_x = torch.stack(all_x)
train_y = torch.stack(all_y)
num_sequences_available = train_x.shape[0]
print(f"创建了 {
num_sequences_available} 个重叠的输入/目标序列对。")
print(f"train_x 的形状:{
train_x.shape}")
print(f"train_y 的形状:{
train_y.shape}")
输出结果
创建了 561 个重叠的输入/目标序列对。
train_x 的形状:torch.Size([561, 32])
train_y 的形状:torch.Size([561, 32])
这告诉我们,从 593 个字符的文本中,我们可以提取出 561 个长度为 32(block_size)的重叠序列。
train_x 和 train_y 的形状 (561, 32) 确认了我们有 561 行(序列),每行有 32 个标记。
在训练过程中,我们将随机采样这些序列对。
现在,让我们初始化 Transformer 的构建块。
# 初始化标记嵌入表
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
print(f"初始化了标记嵌入表,词汇表大小:{
vocab_size},嵌入维度:{
d_model}。使用的设备:{
device}")
输出结果
初始化了标记嵌入表,词汇表大小:36,嵌入维度:64。使用的设备:cuda
接下来,我们需要为模型添加位置信息。由于 Transformer 本身并不知道标记的顺序(与 RNN 不同),我们需要引入位置编码。我们将使用固定频率的正弦和余弦波来实现这一点。
# 创建位置编码矩阵
print("正在创建位置编码矩阵...")
positional_encoding = torch.zeros 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4996
4996

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











