







简单说一下哈 —— 咱们打算训练一个单层 Transformer 加上稀疏自编码器的小型百万参数大型语言模型(LLM),然后去调试它的思考过程,看看这个 LLM 的思考和人类思考到底有多像。
LLMs 是怎么思考的呢?
开源 LLM 出现之后,研究的方法就变得简单啦,那就是去读它们的架构,因为每个 LLM 都是由神经元组成的嘛。要研究它们,就得弄清楚对于某个特定输入,哪些神经元会被激活。比如说,用户问了一句:“声音的定义是什么呀?”那就可以看看为了回答这个问题,哪些神经元被激活了,这样就能窥探到 LLM 的思考过程啦。
为了回答这个问题,咱们就来训练一个单层 Transformer,这个 Transformer 是基于稀疏自编码器的 LLM,至少能让它说话的时候语法和标点符号都用得对。训练好之后,就可以开始探索它的内部架构,看看对于某些输入文本,哪些神经元会被激活。说不定还能发现一些挺有意思的见解呢。咱们会复制 Anthropic 最新的研究成果,这样就能更清楚地看到 LLM 背后到底是怎么思考的啦。
到底是什么问题呀?
研究 LLMs 是怎么工作的主要问题就是,一个单独的神经元代表多种功能,也就是说,一个神经元可能会在 “对数学方程、诗歌、JSON 代码片段以及跨多种语言的‘尤里卡!’都做出反应”。这就叫 多义性,想象一下,要是用 10 亿参数的 LLMs,那里面有很多神经元都被激活了,而且每个神经元都对应着混合的信息。这可真的让人很难看清思考到底是怎么发生的。
最近研究人员提出了一个技术,不是去看每一个单独的神经元,而是去看那些能捕捉特定概念的神经元的线性组合,这就叫 单义性,而这种技术就叫做 稀疏字典学习。
神经网络快速回顾
神经网络你可能已经很熟悉啦,不过咱还是快速复习一下基础知识吧。对于计算机来说,语言模型不过就是一组矩阵,按照特定的方式相乘相加而已。但是人类更抽象地看待它们,把它们当作由人工神经元组成的网络。它们通常看起来是这样的:
那两列绿色的圆圈就是所谓的“层”。当输入信号从左到右穿过网络的时候,这些层会产生 “激活”,咱们可以把这些激活想象成向量。这些激活向量就代表着模型基于输入的 “思考”,也展示了咱们想要理解的神经元。
准备训练数据
咱们的训练数据集必须得多样化,包含来自不同领域的信息,而 The Pile 就是个不错的选择。虽说它有 825 GB 那么大,但咱就只用其中的 5% 好啦。先来下载数据集,看看它是怎么工作的。我打算下载 HuggingFace 上可用的版本。
# 下载验证数据集
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/val.jsonl.zst# 下载训练数据集的第一部分
!wget https://huggingface.co/datasets/monology/pile-uncopyrighted/resolve/main/train/00.jsonl.zst
下载得花点时间,不过你也可以把训练数据集限制在只用一个文件,比如 00.jsonl.zst,而不是三个。它已经分成了训练集、验证集和测试集啦。下载完之后,记得把文件正确地放在各自的目录里哦。
import os
import shutil
import glob# 定义目录结构
train_dir = "data/train"
val_dir = "data/val"# 如果目录不存在就创建
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)# 把所有训练文件(比如 00.jsonl.zst、01.jsonl.zst 等等)都移动到对应的目录里
train_files = glob.glob("*.jsonl.zst")
for file in train_files:
if file.startswith("val"):
# 移动验证文件
dest = os.path.join(val_dir, file)
else:
# 移动训练文件
dest = os.path.join(train_dir, file)
shutil.move(file, dest)
咱们的数据集是 .jsonl.zst 格式的,这是一种常用来存储大型数据集的压缩文件格式。它把 JSON Lines(.jsonl,每一行都是一个有效的 JSON 对象)和 Zstandard(.zst)压缩结合在了一起。咱们来读取一下刚刚下载的文件的一个样本,看看它长啥样。
in_file = "data/val/val.jsonl.zst" # 验证文件的路径with zstd.open(in_file, 'r') as in_f:
for i, line in tqdm(enumerate(in_f)): # 读取前 5 行
data = json.loads(line)
print(f"Line {i}: {data}") # 打印原始数据供检查
if i == 2:
break
#### 输出结果 ####
Line: 0
{
"text": "Effect of sleep quality ... epilepsy.",
"meta": {
"pile_set_name": "PubMed Abstracts"
}
}
Line: 1
{
"text": "LLMops a new GitHub Repository ...",
"meta": {
"pile_set_name": "Github"
}
}
接下来,咱们得对数据集进行编码(也就是分词)。咱们的目标是让 LLM 至少能输出正确的单词。为了做到这一点,咱们得用一个已经有的分词器。咱们会用 OpenAI 的开源分词器 tiktoken,用 r50k_base 分词器,也就是 ChatGPT(GPT-3)模型用的那个,来对数据集进行分词。
咱们得创建一个函数来避免重复劳动,因为咱们要对训练集和验证集都进行分词。
def process_files(input_dir, output_file):
"""
处理指定输入目录中的所有 .zst 文件,并将编码后的 token 保存到 HDF5 文件中。参数:
input_dir (str): 包含输入 .zst 文件的目录。
output_file (str): 输出 HDF5 文件的路径。
""" with h5py.File(output_file, 'w') as out_f: # 在 HDF5 文件中创建一个可扩展的数据集,名为 'tokens'
dataset = out_f.create_dataset('tokens', (0,), maxshape=(None,), dtype='i')
start_index = 0 # 遍历输入目录中的所有 .zst 文件
for filename in sorted(os.listdir(input_dir)):
if filename.endswith(".jsonl.zst"):
in_file = os.path.join(input_dir, filename)
print(f"正在处理:{in_file}") # 打开 .zst 文件进行读取
with zstd.open(in_file, 'r') as in_f: # 遍历压缩文件中的每一行
for line in tqdm(in_f, desc=f"正在处理 {filename}"):
# 将行加载为 JSON
data = json.loads(line) # 在文本末尾添加结束文本标记并进行编码
text = data['text'] + "<|endoftext|>"
encoded = enc.encode(text, allowed_special={'<|endoftext|>'})
encoded_len = len(encoded) # 计算新 token 的结束索引
end_index = start_index + encoded_len # 扩展数据集大小并存储编码后的 token
dataset.resize(dataset.shape[0] + encoded_len, axis=0)
dataset[start_index:end_index] = encoded # 更新下一批 token 的开始索引
start_index = end_index
这个函数有两个重要点需要注意哦:
- 咱们把分词后的数据存储在 HDF5 文件里,这样在训练模型的时候就能更快速地访问数据啦。
- 添加
<|endoftext|>标记是为了标记每个文本序列的结束,告诉模型它已经到达了一个有意义的上下文的结尾,这有助于生成连贯的输出哦。
现在就可以简单地用下面的代码对训练集和验证集进行编码啦:
# 定义分词数据输出目录
out_train_file = "data/train/pile_train.h5"
out_val_file = "data/val/pile_dev.h5"# 加载(GPT-3/GPT-2 模型)的分词器
enc = tiktoken.get_encoding('r50k_base')# 处理训练数据
process_files(train_dir, out_train_file)# 处理验证数据
process_files(val_dir, out_val_file)
咱们来看看分词后的数据样本吧:
with h5py.File(out_val_file, 'r') as file: # 访问 'tokens' 数据集
tokens_dataset = file['tokens'] # 打印数据集的 dtype
print(f"'tokens' 数据集的 dtype:{tokens_dataset.dtype}") # 加载并打印数据集的前几个元素
print("‘tokens’ 数据集的前几个元素:")
print(tokens_dataset[:10]) # 前 10 个 token#### 输出结果 ####
Dtype of 'tokens' dataset: int32
First few elements of the 'tokens' dataset:
[ 2725 6557 83 23105 157 119 229 77 5846 2429]
单层 Transformer 概述
现代语言模型几乎总是使用某种 Transformer 架构的变体。虽说没必要深入探究 Transformer 是怎么工作的,但咱还是简单了解一下大概吧:
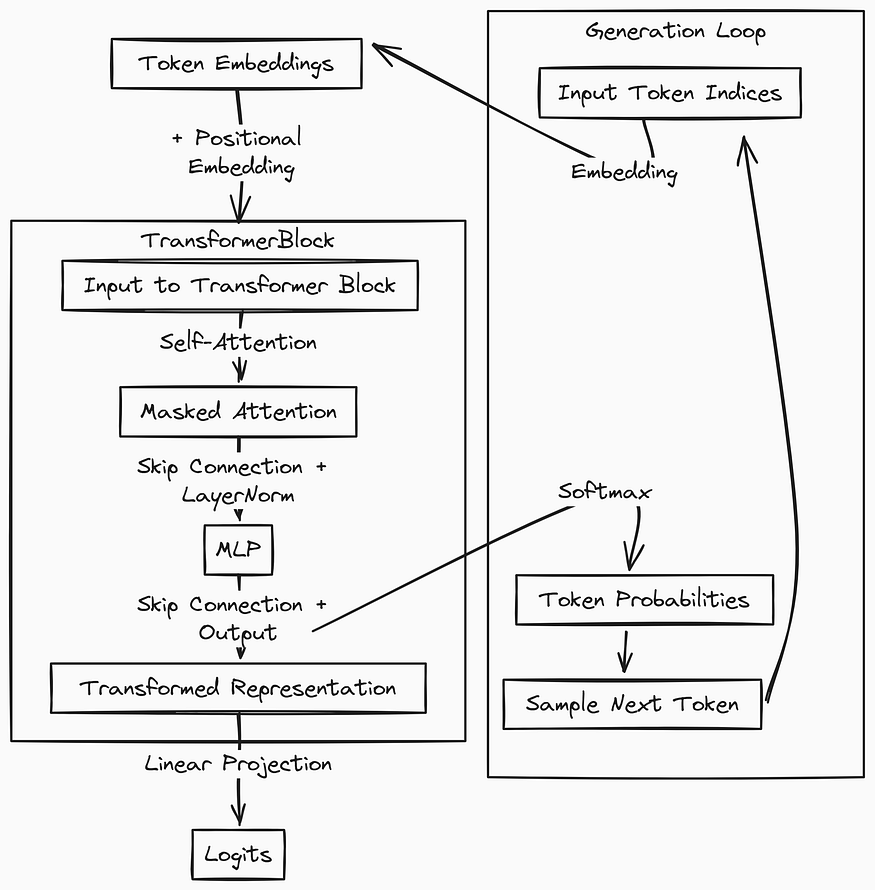
Transformer 架构
对于语言模型来说,Transformer 接收一串文本(编码为 token)作为输入,然后输出每个可能的下一个 token 的概率。Transformer 由多个 Transformer 块组成,最后是一个全连接层。通常情况下,Transformer 有很多这样的块堆叠在一起,但这次研究用的网络只有一块,为了简单起见,这就是 “咱们还搞不懂的最简单的语言模型”。
在 Transformer 块里面,你会找到自注意力头和一个叫做多层感知器(MLP)的组件。你可以这样理解这两个组件:注意力头决定模型应该关注输入的哪些部分,而 MLP 则进行实际的处理或者说“思考”。MLP 本身是一个简单的前馈神经网络,有一个输入(注意力头的输出)、一个隐藏层和一个输出。
这个隐藏层扮演着一个挺有意思的的角色哦,为了简单起见,咱们就关注它,忽略模型的其他部分吧。每次把一串文本输入到 Transformer 里的时候,隐藏层的激活作为向量,就是能告诉我们 LLMs 是怎么思考的答案啦。往后,咱们可以称这些为 “MLP 激活向量” 或者简单地说 “激活向量”。
MLP(多层感知器)
MLP 是 Transformer 前馈网络的关键部分哦。它能帮助模型学习数据中复杂的关系。MLP 有两个主要部分:
- 一个隐藏层,它会增加输入的大小(通常是原来的 4 倍),并且应用 ReLU 激活函数。
- 一个最终层,它会把大小再减回到原来的维度。
这种结构有助于完善注意力机制所学到的数据表示。n_embed 参数定义了输入的大小。
class MLP(nn.Module):
def __init__(self, n_embed):
super().__init__()
# 定义一个简单的 MLP,包含两个线性层和一个 ReLU 激活函数
self.net = nn.Sequential(
nn.Linear(n_embed, 4 * n_embed), # 第一层将嵌入大小扩展 4 倍
nn.ReLU(), # ReLU 激活引入非线性
nn.Linear(4 * n_embed, n_embed) # 第二层将大小减回嵌入大小
) def forward(self, x):
# 将输入传递通过 MLP 网络
return self.net(x)
- 首先定义了一个
Sequential网络,包含两个Linear层。 - 第一层将输入大小(
n_embed)扩展到4 * n_embed,为更复杂的转换留出空间。 ReLU激活函数引入非线性,帮助模型捕捉复杂模式。- 第二个
Linear层将大小再减回n_embed,确保输出与 Transformer 兼容。
注意力机制
注意力头专注于输入序列的相关部分。重要的参数包括:
- n_embed:定义了输入到注意力机制的大小。
- context_length:帮助创建一个因果掩码,确保模型只关注过去的 token。
注意力头使用无偏置的线性层来计算键、查询和值。使用下三角矩阵进行因果掩码,确保模型不会关注未来的 token。
class Attention(nn.Module):
def __init__(self, n_embed, context_length):
super().__init__()
# 定义一个线性层来计算查询、键和值矩阵
self.qkv = nn.Linear(n_embed, n_embed * 3, bias=False) # 创建一个三角矩阵用于因果掩码,防止关注未来的 token
self.tril = torch.tril(torch.ones(context_length, context_length)) def forward(self, x):
B, T, C = x.shape # B = 批量大小,T = 序列长度,C = 嵌入大小
# 将 qkv 线性层的输出分成查询、键和值
q, k, v = self.qkv(x).chunk(3, dim=-1) # 使用查询和键的点积计算注意力分数
attn = (q @ k.transpose(-2, -1)) / C**0.5 # 应用因果掩码,防止关注序列中未来的位置
attn = attn.masked_fill(self.tril[:T, :T] == 0, float('-inf')) # 应用 softmax 将注意力分数转换为概率,然后对值进行加权
return (F.softmax(attn, dim=-1) @ v)
qkv是一个单独的线性层,产生三个不同的矩阵:查询(q)、键(k)和值(v)。q和k的点积创建了注意力分数,这些分数通过C**0.5进行缩放。- 因果掩码(
tril)确保我们不会关注未来的 token(对于自回归任务很重要)。 - 应用
softmax将分数转换为概率,然后使用这些概率对值(v)进行加权。
Transformer 块
Transformer 块是注意力层和 MLP 层的组合,用 LayerNorm 和残差连接包裹起来,以帮助稳定训练。既然咱们这次不针对多头注意力,所以也就没必要用 n_block 参数来定义需要多少个块啦!
class TransformerBlock(nn.Module):
def __init__(self, n_embed, context_length):
super().__init__()
# 初始化注意力机制
self.attn = Attention(n_embed, context_length) # 初始化 MLP 组件
self.mlp = MLP(n_embed) # 用于训练稳定性的层归一化
self.ln = nn.LayerNorm(n_embed) def forward(self, x):
# 应用 LayerNorm 和注意力,然后加上残差连接
x = x + self.attn(self.ln(x)) # 应用 LayerNorm 和 MLP,再加上另一个残差连接
return x + self.mlp(self.ln(x))
LayerNorm在应用转换之前对输入进行归一化。- 首先应用注意力机制,其输出通过残差连接加回到输入。
- 然后,应用 MLP 并加上另一个残差连接。
- 这些步骤有助于稳定训练并实现更好的特征学习。
训练单层模型
现在咱们已经有了所有组件,就可以开始训练啦,不过在那之前,咱们得把 token 嵌入和位置嵌入与 Transformer 块结合起来,用于序列到序列的任务。
class Transformer(nn.Module):
def __init__(self, n_embed, context_length, vocab_size):
super().__init__()
# 用于 token 表示的嵌入
self.embed = nn.Embedding(vocab_size, n_embed) # 用于位置编码的嵌入
self.pos_embed = nn.Embedding(context_length, n_embed) # 定义 Transformer 块(多头注意力 + MLP 层)
self.block = TransformerBlock(n_embed, context_length) # 最终的线性层,将隐藏状态映射到词汇大小,用于 token 预测
self.lm_head = nn.Linear(n_embed, vocab_size) # 注册位置索引缓冲区,以便在生成过程中进行一致的索引
self.register_buffer('pos_idxs', torch.arange(context_length)) def forward(self, idx):
# 获取输入 token 及其位置的嵌入
x = self.embed(idx) + self.pos_embed(self.pos_idxs[:idx.shape[1]]) # 将嵌入的输入传递通过 Transformer 块
x = self.block(x) # 将输出传递通过语言模型头部进行 token 预测
return self.lm_head(x) def generate(self, idx, max_new_tokens):
# 逐个生成新 token,直到达到 max_new_tokens
for _ in range(max_new_tokens):
# 获取序列中最后一个 token 的 logits
logits = self(idx)[:, -1, :] # 通过将 softmax 应用于 logits 来随机抽样下一个 token
idx_next = torch.multinomial(F.softmax(logits, dim=-1), 1) # 将预测的 token 添加到输入序列中
idx = torch.cat((idx, idx_next), dim=1) # 返回生成的 token 序列
return idx
现在咱们已经构建了最简单的 Transformer 模型,接下来,咱们需要定义训练配置。
# 定义词汇表大小和 Transformer 配置
VOCAB_SIZE = 50304 # 词汇表中唯一 token 的数量
BLOCK_SIZE = 512 # 模型的最大序列长度
N_EMBED = 2048 # 嵌入空间的维度
N_HEAD = 16 # 每个 Transformer 块中的注意力头数量# 训练参数
BATCH_SIZE = 64
MAX_ITER = 100 # 为了快速示例,减少迭代次数
LEARNING_RATE = 3e-4
DEVICE = 'cpu' # 或者 'cuda',如果你有 GPU 的话# 训练和开发数据集的路径
TRAIN_PATH = "data/train/pile_val.h5" # 训练数据集的文件路径
DEV_PATH = "data/val/pile_val.h5" # 验证数据集的文件路径
接下来,咱们来编写一个简单的训练循环,开始训练咱们的单层 Transformer 模型,看看它对于调试有没有用哦。
# 从 HDF5 文件中加载训练数据
train_data = h5py.File(TRAIN_PATH, 'r')['tokens']# 获取训练或验证的批次数据的函数
def get_batch(split):
# 为了简单起见,训练和验证都使用相同的数据(`train_data`)
data = train_data
# 随机选择每个序列在批次中的起始索引
ix = torch.randint(0, data.shape[0] - BLOCK_SIZE, (BATCH_SIZE,))
# 为批次中的每个元素创建输入(x)和目标(y)序列
x = torch.stack([torch.tensor(data[i:i+BLOCK_SIZE], dtype=torch.long) for i in ix])
y = torch.stack([torch.tensor(data[i+1:i+BLOCK_SIZE+1], dtype=torch.long) for i in ix])
# 将输入和目标批次移动到设备(GPU/CPU)
x, y = x.to(DEVICE), y.to(DEVICE)
return x, y# 初始化 Transformer 模型、优化器和损失函数
model = Transformer(N_EMBED, CONTEXT_LENGTH, VOCAB_SIZE).to(DEVICE) # 定义模型
optimizer = torch.optim.AdamW(model.parameters(), lr=LEARNING_RATE) # AdamW 优化器
loss_fn = nn.CrossEntropyLoss() # 用于训练的交叉熵损失# 训练循环
for iter in tqdm(range(MAX_ITER)): # 在指定的迭代次数内进行迭代
# 获取一批训练数据
xb, yb = get_batch('train') # 执行模型的前向传播以获取 logits(预测值)
logits = model(xb) # 重塑 logits 以匹配损失计算所需的形状
B, T, C = logits.shape # B:批量大小,T:序列长度,C:词汇表大小
logits = logits.view(B*T, C) # 展平批量和时间维度
yb = yb.view(B*T) # 展平目标标签 # 通过比较 logits 和目标标签计算损失
loss = loss_fn(logits, yb) # 将优化器的梯度清零
optimizer.zero_grad() # 执行反向传播以计算梯度
loss.backward() # 使用优化器更新模型参数
optimizer.step() # 每 10 次迭代打印一次损失
if iter % 10 == 0:
print(f"迭代 {iter}:损失 {loss.item():.4f}")# 将训练好的模型保存到文件中
MODEL_SAVE_PATH = "one_layer_transformer_short.pth" # 定义模型保存路径
torch.save(model.state_dict(), MODEL_SAVE_PATH) # 保存模型的状态字典(权重)
print(f"模型已保存至 {MODEL_SAVE_PATH}")print("训练完成。") # 表明训练已经完成
它将开始咱们的训练,并且每 10 次迭代打印一次损失:
迭代 0:损失 0.1511241
迭代 1:损失 0.1412412
迭代 2:损失 0.1401021
...
生成文本
一旦训练完成 100 个 epoch,咱们就可以看看咱们训练好的模型的输出,看看它对于正确的标点和语法生成有没有用。
# 定义模型路径、输入文本以及其他参数
model_path ='one_layer_transformer_short.pth'
input_text = "|<end_of_text >|"
max_new_tokens = 50
device = 'cuda' # 或者 'cpu'# 加载模型检查点
checkpoint = torch.load(model_path, map_location=torch.device(device))#使用配置文件中的配置初始化模型
model =Transformer( n_head=config['n_head'], n_embed=config['n_embed'],
context_length=config['context_length'], vocab_size=config['vocab_size'],)
model.load_state_dict(checkpoint['model_state_dict'])
model.eval().to(device)# 加载分词器
enc =tiktoken.get_encoding("r50k_base")# 对输入文本进行编码
start_ids =enc.encode_ordinary(input_text)
context = torch.tensor(start_ids,dtype=torch.long, device=device).unsqueeze(0)# 生成过程
withtorch.no_grad():
generated_tokens = model.generate(context,
max_new_tokens=max_new_tokens)[0].tolist()# 对生成的 token 进行解码
output_text = enc.decode(generated_tokens)# 输出生成的文本
print(output_text)
★ "Twisted Roads in Sunset Drive"("I’m aware my partner
heads out next week for business" 的一个变体)山谷的宁静低语,被 Montgomery 观察着。
跨越美洲,各种机构(参考欧洲模式)John Robinson 深入探究了这些转变,如今他的反思正在影响更广阔的格局。
领导者的思绪尚未被完全捕捉。
输出的内容没啥意义,不过咱们感兴趣的是它的语法和标点,而且它在这方面表现得还不错,足够咱们进行下一步啦。
神经元分布
现在,为了大致了解一下咱们训练好的模型中的神经元行为,咱们可以看看神经元密度直方图。
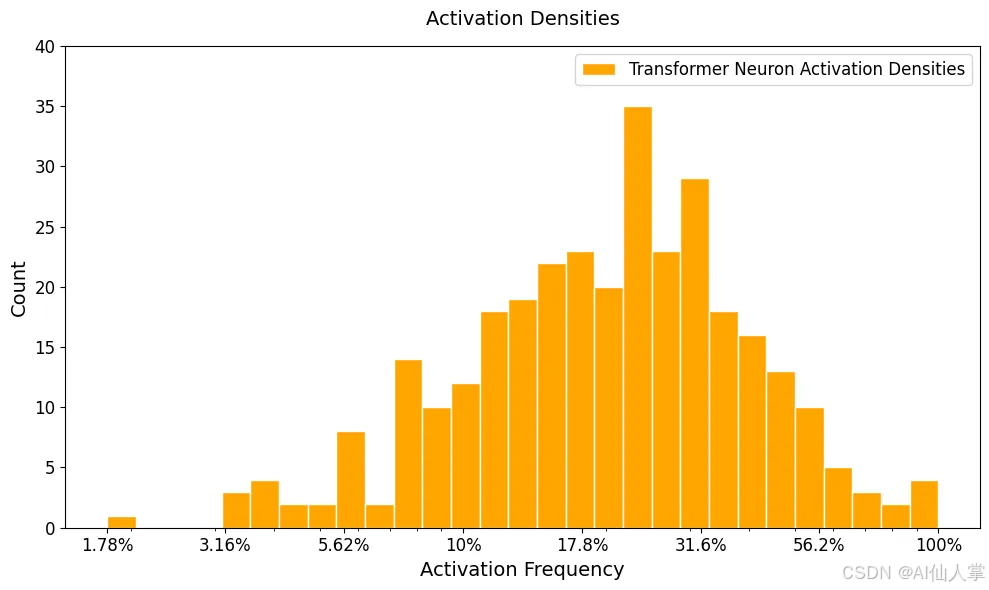
这个直方图展示了当给定来自数据集的输入时,神经元激活的频率。咱们随机采样了很多输入,检查了激活情况,并且记录了每个神经元被激活(也就是有非零激活值)的频率。直方图显示了在所有输入中,每个神经元被激活的比例。
从图中可以看出,大多数神经元的激活频率超过 10%,而且大约有一半的神经元激活频率超过 25%。这对于可解释性来说可不是好事,因为这表明这些神经元要么是为了非常宽泛的想法而激活,要么是为了多个概念。为了更好地进行解释,咱们希望神经元能够对特定的、狭窄的概念做出反应,这意味着咱们需要让它们的激活更加稀疏和 稀疏。
稀疏自编码器
为了让激活变得稀疏,咱们使用稀疏自编码器。这是一个与 Transformer 一起训练的独立网络。自编码器接收 MLP 激活向量,对其进行编码,然后尝试重建它。咱们在隐藏层中强制执行稀疏性,以便对 MLP 激活进行解释。

它的原理如下:
- 自编码器有一个单独的隐藏层。
- 输入和输出的形状与激活向量相同。
- 中间层的大小是固定的(例如,1024 个特征),足够小以高效训练,但又足够大以捕捉有用的特征。
- 为了强制执行稀疏性,在训练过程中向损失函数添加 L1 惩罚(激活值的绝对值之和),除了均方误差(MSE)损失之外。这通过将小激活值推向零来鼓励激活变得稀疏。
稀疏字典学习
Anthropic 的研究人员在训练过程中加入了 稀疏字典学习与自编码器,这进一步促进了稀疏性。它的原理如下:
- 强制解码器权重矩阵的每一行具有单位 L2 范数和零均值。这确保了每个激活方向都是不同的(就像一个“字典”)。
- MLP 激活向量被表示为这些字典条目的线性组合,其中每个隐藏层激活是一个字典条目的系数。
在训练过程中:
- 解码器权重被归一化为零均值,这有助于自编码器学习高效的稀疏表示。
- 最终的损失包括编码表示的 L1 范数,这控制了学习到的特征的稀疏性。咱们可以通过一个超参数来调整稀疏性水平。
接下来,咱们来编写稀疏自编码器以及字典学习的代码,然后就可以检查神经元分布,看看它有没有变得更好啦。
class SparseAutoencoder(nn.Module):
def __init__(self, n_features, n_embed):
super().__init__() # 编码器:一个全连接层,将输入转换到编码空间。
# 输入大小为 n_embed * 4,输出大小为 n_features。
self.encoder = nn.Linear(n_embed * 4, n_features) # 解码器:一个全连接层,从编码中重建原始输入。
# 输入大小为 n_features,输出大小为 n_embed * 4。
self.decoder = nn.Linear(n_features, n_embed * 4) # ReLU 激活函数,在编码后应用。
self.relu = nn.ReLU() def encode(self, x_in):
# 在编码过程中,从输入中减去解码器的偏差以进行归一化。
x = x_in - self.decoder.bias # 应用编码器(线性变换后跟 ReLU 激活)。
f = self.relu(self.encoder(x)) return f def forward(self, x_in, compute_loss=False): # 对输入进行编码以获得特征表示。
f= self.encode(x_in) # 对特征表示进行解码,将其还原回输入空间
x = self.decoder(f) # 如果 compute_loss 为 True,则计算重建损失和正则化损失
if compute_loss:
# 计算重建输入和原始输入之间的均方误差损失
recon_loss = F.mse_loss(x, x_in) # 正则化损失:对编码后的特征施加 L1 惩罚(稀疏性正则化)
reg_loss = f.abs().sum(dim=-1).mean()
else:
# 如果 compute_loss 为 False,则返回 None 作为两种损失
recon_loss = None
reg_loss = None return x, recon_loss, reg_loss def normalize_decoder_weights(self): with torch.no_grad():
# 对解码器层的权重进行归一化,使其在特征维度(维度 1)上具有单位范数
self.decoder.weight.data = nn.functional.normalize(self.decoder.weight.data, p=2, dim=1)
encode 函数在应用编码器和 ReLU 激活之前,先减去解码器的偏差。forward 函数运行解码器,并计算两种类型的损失:重建损失和正则化损失。
normalize_decoder_weights 函数确保解码器的权重具有单位范数和零均值。
训练循环
对于训练循环,Anthropic 使用了一个大型数据集,其中包含了通过将大部分 The Pile 数据通过 Transformer 并保存激活值所生成的 MLP 激活向量。这些向量占用的空间相当大(因为每个 token 占用 4 个字节,而一个 512 元素的 FP16 向量占用 1024 个字节)。由于存储限制,咱们需要在自编码器的训练过程中以批量的方式进行计算。
# 遍历训练步骤的次数
for _ in range(num_training_steps):
# 从批量迭代器中获取一批输入(xb),忽略标签
xb, _ = next(batch*iterator) # 禁用梯度计算,因为咱们只是使用模型进行嵌入生成(不进行训练)
with torch.no_grad(): # 获取输入批次的嵌入(MLP 激活向量)来自模型
x_embedding, * = model.forward_embedding(xb) # 将优化器的梯度清零,为反向传播做准备
optimizer.zero_grad() # 将嵌入通过自编码器,并计算重建损失和正则化损失
outputs, recon_loss, reg_loss = autoencoder(x_embedding, compute_loss=True) # 应用正则化项,并使用一个缩放因子(lambda_reg)
reg_loss = lambda_reg \* reg_loss # 总损失是重建损失和正则化惩罚的组合
loss = recon_loss + reg_loss # 执行反向传播以计算梯度
loss.backward() # 使用优化器更新模型的权重
optimizer.step() # 在每个训练步骤后对解码器权重进行归一化
autoencoder.normalize_decoder_weights()
在循环结束时,咱们使用 normalize_decoder_weights。
一旦有了训练好的 Transformer,咱们就可以运行这个训练循环,教自编码器如何创建 Transformer 的 MLP 激活的稀疏表示。然后,对于一个新的 tokenized 输入,咱们可以像这样操作:
# 获取咱们训练好的 LLM 的特征
features = autoencoder.encode(transformer.forward_embedding(tokens))
现在,features 将会包含 tokenized 文本的稀疏表示。如果一切顺利的话,features 中的元素应该很容易解释,并且具有明确的含义。
密度直方图
为了确保特征真正稀疏,咱们需要比较 MLP 激活和自编码器的特征激活的密度直方图。这些直方图展示了特征或神经元在输入样本上被激活的频率。通过比较它们,咱们可以验证自编码器是否创建了稀疏特征。
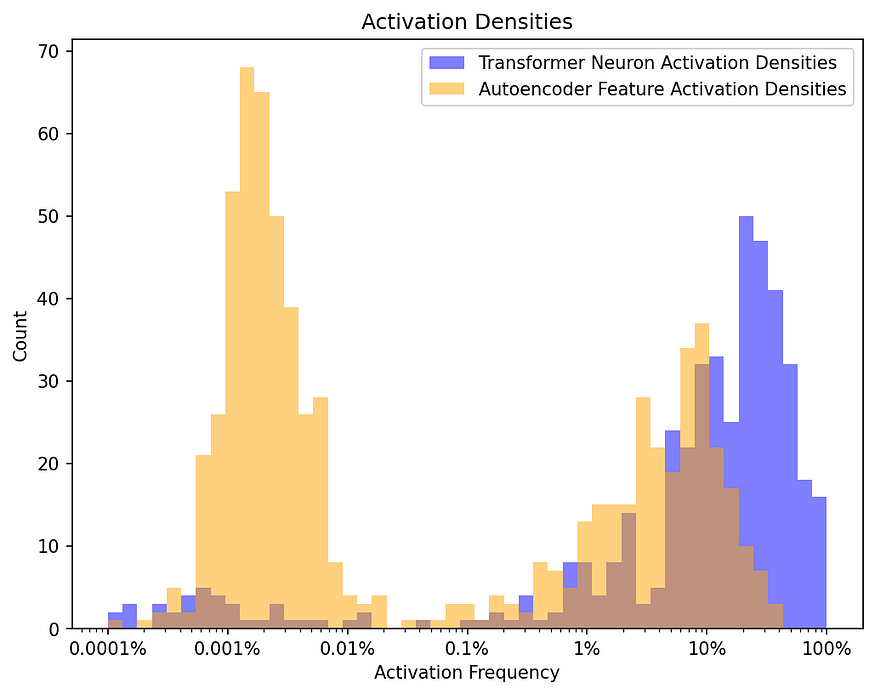
密度直方图(由 Fareed Khan 创建)
自编码器的特征(以浅黄色显示)比 Transformer 神经元(以蓝色显示)被激活的可能性要小得多。这个图是用对数刻度绘制的,意味着每个向左的刻度代表激活可能性减少了 90%。然而,你会注意到,仍然有相当数量的特征被激活的频率超过 10%,这并不理想。这发生是因为在增加稀疏性和避免从不激活的特征(死亡特征)之间需要保持平衡。左侧的大峰值表明有一组特征激活得非常不频繁,Anthropic 的作者们将其称为 “超低密度簇”。
现在,咱们可以为新的输入生成特征向量,并检查这些特征是否真正可解释。
结果与分析
总共有 576 个特征,比自编码器隐藏层中的神经元数量要少。这是因为研究人员识别出了一个 “超低密度簇”,这些特征激活得非常稀少,并且似乎没有有意义的解释。我发现了类似激活值非常低的特征,在特征密度直方图中以最左侧的峰值表示。这些低激活特征对损失的贡献不大,所以我选择将它们从我的分析中排除,以保持清晰。
在排除了激活频率低于每 10K 个 token 一次的特征之后,我最终得到了略多于一半的特征,这仍然比 Transformer 的输入神经元要多,这正是咱们的目标。
特征 169:非英语激活
当西班牙语、法语和葡萄牙语的后缀出现时,这个特征会被激活,这是特定于语言的,并不是任何用这些语言写的文本都会触发它。
这表明某些神经元会针对西班牙语、法语和葡萄牙语的特定词尾激活,而不是任何这些语言的文本。这意味着模型能够识别语言模式,比如词尾,并且以不同的方式处理它们,暗示它理解不同语言中的词的部分,而不仅仅是整个词。
特征 224:高度敏感
当出现十六进制或 base64 等字母数字字符串时,尤其是在技术上下文中,这个特征会被触发。
这表明这个神经元对字母数字模式非常敏感,特别是十六进制和 base64 字符串,这些通常出现在编码、加密和数字标识符中。这表明模型不仅仅是在读取字符,而是在检测结构化数据,几乎就像是在文本中寻找隐藏的代码,这种能力对于技术语言处理来说可能至关重要。
特征 76:可能性
这个特征能够检测到像“could”“might”或“must”这样的情态动词,这些词表示可能性或必要性。
这表明这个神经元能够检测到像“could”这样的情态动词,它们表达可能性或必要性。这意味着模型不仅仅理解单词,还理解单词背后的细微含义,帮助它解释句子中的不确定性以及义务。
特征 44:数学
当出现破折号时,尤其是在减法或否定的上下文中(例如“not good”或“5–3”),这个特征会被激活。
这表明这个神经元会在破折号出现时亮起,尤其是在它表示减法或否定的时候,比如在数学方程中或者像“not good”这样的短语中。这表明模型不仅仅看到的是一个破折号 —— 它能够识别出意义的转变,无论是分解数字还是改变句子的语气。
特征 991:医学
它能够检测到与细胞和分子生物学相关的 token,暗示它专注于特定领域的语言。
这表明这个神经元能够高度识别像“virus”(病毒)、“protein”(蛋白质)和“cell”(细胞)这样的细胞和分子生物学术语,暗示它对科学语言有很强的专注度。这表明模型能够识别并处理复杂的生物概念,使其非常适合理解生命科学领域的技术讨论。
特征 13:“un”
当出现带有“un”前缀的 token 时,例如“undo”(撤销)或“unhappy”(不开心),这个特征会被激活。
这表明这个神经元会针对带有“un”前缀的 token 激活,比如“undo”或“unhappy”。这表明模型对带有否定或反转含义的前缀很敏感,帮助它理解一个词带有否定或对立的含义。
特征 229:LaTeX
当出现 LaTeX 表达式中的 token 时,这个特征会被触发,这些表达式通常被美元符号包围,出现在数学或科学上下文中。
这表明这个神经元在遇到 LaTeX 表达式中的 token 时会变得活跃,比如“ x x x”或“ N N N”,这些通常出现在数学和科学领域。这意味着模型能够识别并理解复杂的公式,几乎就像是在解码数学和科学符号的语言 —— 帮助它轻松处理技术内容。
特征 211:“let”
当出现以“let”开头的数学函数声明中的闭合括号时,这个特征会被激活。
这表明这个神经元会在以“let”开头的数学函数声明(比如“Let f(x) = …”)中的闭合括号出现时激活。这表明模型能够精准地识别数学定义,帮助它识别并理解公式中的函数表达式及其结构。
特征 100:数学 LaTeX
当出现 LaTeX 表达式中的各种 token 时,尤其是使用开括号时,这个特征会被激活。它通常出现在涉及 LaTeX 格式的数学或科学上下文中。
这表明这个神经元会在 LaTeX 表达式中的 token 被激活,尤其是当使用像 { 和 [ 这样的开括号时,这些在数学和科学上下文中很常见。这表明模型能够识别 LaTeX 格式,帮助它识别和解释在技术文档中常见的复杂方程、表达式和引用。
特征 2:决策制定
这个特征比较难以解释。然而,它似乎会在与“说服性论点”或“决策制定”相关的上下文中激活。或许检查更长的上下文有助于明确其目的,或者可能这个特征本身就是难以完全理解的。自编码器的一些特征仍然很难完全弄清楚。
特征 3:逗号
当逗号出现在不同上下文中时,这个特征会被激活。它在文本中起到了结构化的作用,只要句子中出现逗号就会被激活。
特征 5:数学解释
这个特征在数学上下文中激活,尤其是在教学环境中,比如证明或考试题目中。它似乎专注于学术或技术讨论,特别是当讨论数学概念时。
结果说明了啥?
咱们给这个迷你 LLM 的“大脑”安了一个小小的“显微镜”,想看看它是怎么思考的。但一开始看到的不是整齐有序的想法,而是一片混乱,每个神经元似乎并不是只专注于一件事,而是同时在处理多个想法。这就叫 多义性,这使得整个系统感觉就像是试图通过同时聆听成千上万人的喊叫来理解一座城市一样。
为了从混乱中理出头绪,咱们使用了一种巧妙的技术,叫做稀疏自编码器,结果它还真管用!突然之间,一些神经元开始高度专注于某些特定的概念。
例如,有一个神经元只有在模型看到西班牙语后缀时才会亮起来,另一个对十六进制代码的反应特别具体,还有一个会在情态动词像“could”(可能)和“must”(必须)出现时被触发。甚至还有能够识别 LaTeX 数学表达式的神经元,而且,令人兴奋的是,有一个可能与检测“说服性论点”有关 —— 这是对抽象推理的一瞥!
有些发现仍然有点模糊不清,但这已经是一个令人兴奋的进步啦。咱们不再只是看到一个巨大的、神秘的数字矩阵,而是开始发现专门化的功能和模式,几乎就像是 LLM 为不同类型的知识配备了小小的“电路”。这次研究只是针对一个小型模型,但它证明了一件大事:理解LLMs的“思考”并非不可能。这是一个挑战,但咱们可以一步步来,一个神经元接一个神经元地去攻克。说不定,有了像稀疏字典学习这样的技术,咱们最终能绘制出整个LLM的“大脑”地图,揭开AI组织知识的惊人方式呢!



















 2159
2159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











